 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Boosted Regression for MR to CT Synthesis
Aug 22, 2018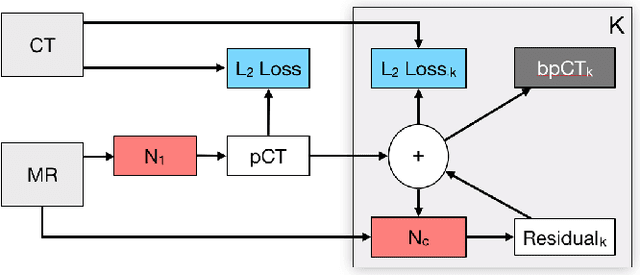

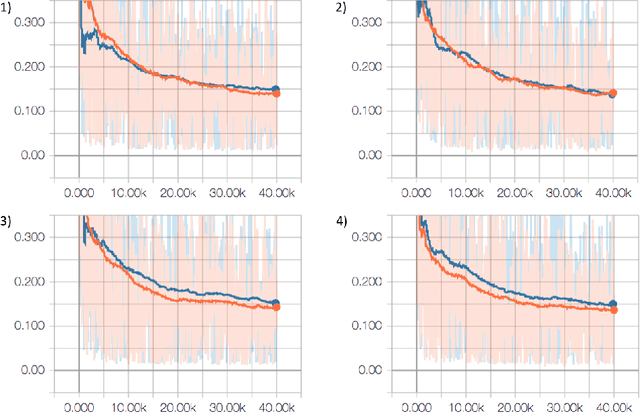
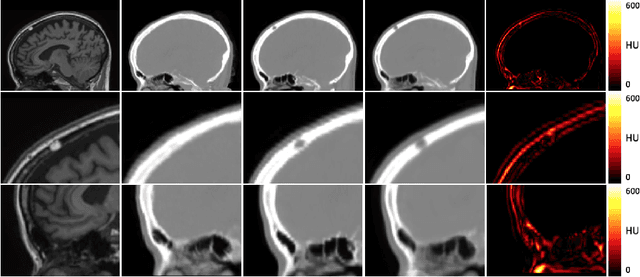
Attenuation correction is an essential requirement of positron emission tomography (PET) image reconstruction to allow for accurate quantification. However, attenuation correction is particularly challenging for PET-MRI as neither PET nor magnetic resonance imaging (MRI) can directly image tissue attenuation properties. MRI-based computed tomography (CT) synthesis has been proposed as an alternative to physics based and segmentation-based approaches that assign a population-based tissue density value in order to generate an attenuation map. We propose a novel deep fully convolutional neural network that generates synthetic CTs in a recursive manner by gradually reducing the residuals of the previous network, increasing the overall accuracy and generalisability, while keeping the number of trainable parameters within reasonable limits. The model is trained on a database of 20 pre-acquired MRI/CT pairs and a four-fold random bootstrapped validation with a 80:20 split is performed. Quantitative results show that the proposed framework outperforms a state-of-the-art atlas-based approach decreasing the Mean Absolute Error (MAE) from 131HU to 68HU for the synthetic CTs and reducing the PET reconstruction error from 14.3% to 7.2%.
Aleatoric uncertainty estimation with test-time augmentation for medical image segmentation with convolutional neural networks
Jul 20, 2018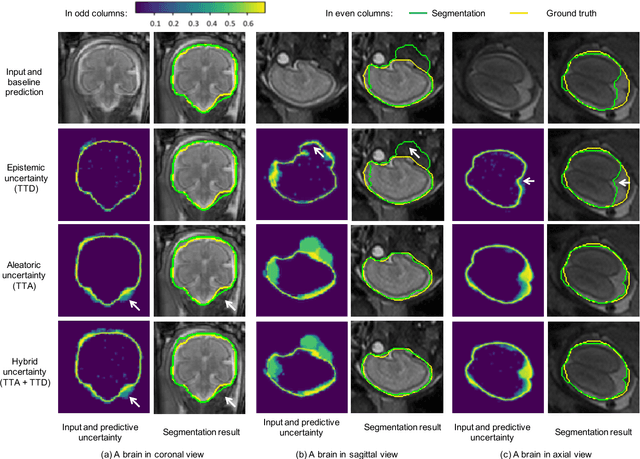
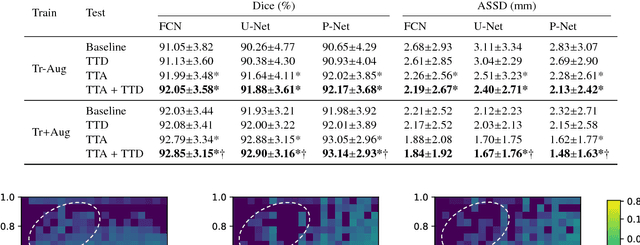
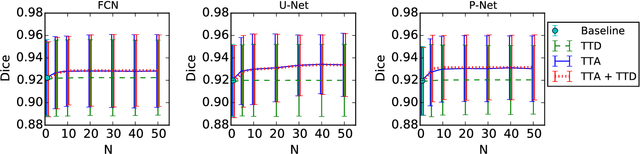
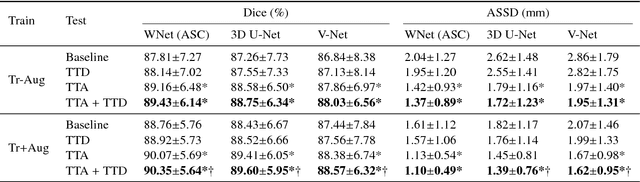
Despite the state-of-the-art performance for medical image segmentation, deep convolutional neural networks (CNNs) have rarely provided uncertainty estimations regarding their segmentation outputs, e.g., model (epistemic) and image-based (aleatoric) uncertainties. In this work, we analyze these different types of uncertainties for CNN-based 2D and 3D medical image segmentation tasks. We additionally propose a test-time augmentation-based aleatoric uncertainty to analyze the effect of different transformations of the input image on the segmentation output. Test-time augmentation has been previously used to improve segmentation accuracy, yet not been formulated in a consistent mathematical framework. Hence, we also propose a theoretical formulation of test-time augmentation, where a distribution of the prediction is estimated by Monte Carlo simulation with prior distributions of parameters in an image acquisition model that involves image transformations and noise. We compare and combine our proposed aleatoric uncertainty with model uncertainty. Experiments with segmentation of fetal brains and brain tumors from 2D and 3D Magnetic Resonance Images (MRI) showed that 1) the test-time augmentation-based aleatoric uncertainty provides a better uncertainty estimation than calculating the test-time dropout-based model uncertainty alone and helps to reduce overconfident incorrect predictions, and 2) our test-time augmentation outperforms a single-prediction baseline and dropout-based multiple predictions.
Weakly-Supervised Convolutional Neural Networks for Multimodal Image Registration
Jul 09, 2018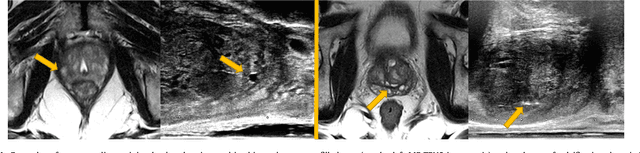
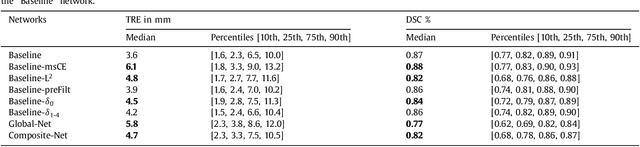
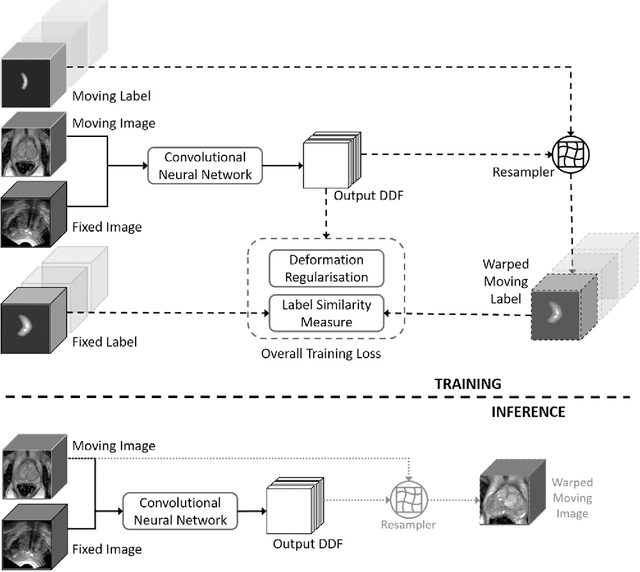
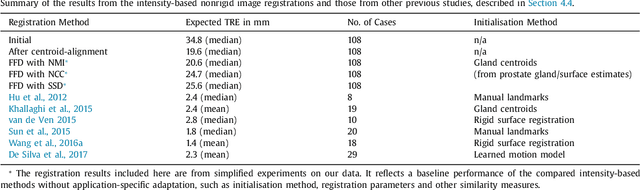
One of the fundamental challenges in supervised learning for multimodal image registration is the lack of ground-truth for voxel-level spatial correspondence. This work describes a method to infer voxel-level transformation from higher-level correspondence information contained in anatomical labels. We argue that such labels are more reliable and practical to obtain for reference sets of image pairs than voxel-level correspondence. Typical anatomical labels of interest may include solid organs, vessels, ducts, structure boundaries and other subject-specific ad hoc landmarks. The proposed end-to-end convolutional neural network approach aims to predict displacement fields to align multiple labelled corresponding structures for individual image pairs during the training, while only unlabelled image pairs are used as the network input for inference. We highlight the versatility of the proposed strategy, for training, utilising diverse types of anatomical labels, which need not to be identifiable over all training image pairs. At inference, the resulting 3D deformable image registration algorithm runs in real-time and is fully-automated without requiring any anatomical labels or initialisation. Several network architecture variants are compared for registering T2-weighted magnetic resonance images and 3D transrectal ultrasound images from prostate cancer patients. A median target registration error of 3.6 mm on landmark centroids and a median Dice of 0.87 on prostate glands are achieved from cross-validation experiments, in which 108 pairs of multimodal images from 76 patients were tested with high-quality anatomical labels.
Uncertainty in multitask learning: joint representations for probabilistic MR-only radiotherapy planning
Jun 18, 2018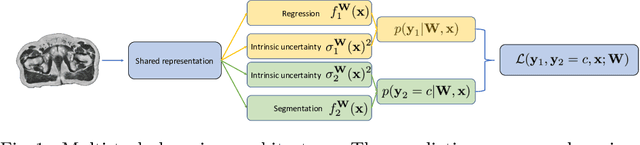
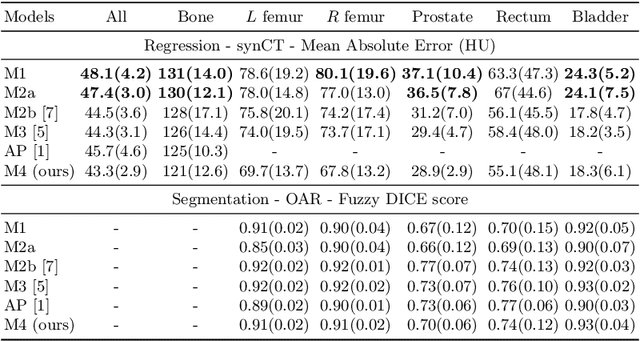
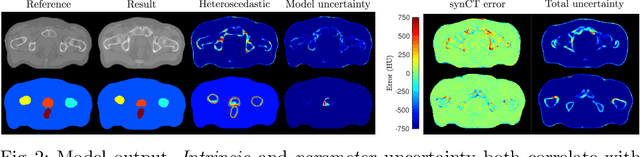
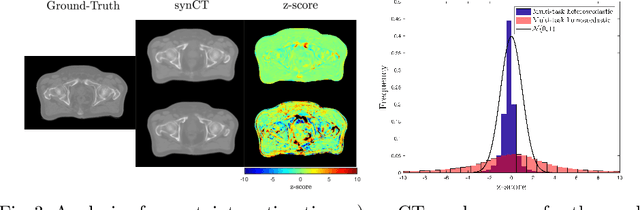
Multi-task neural network architectures provide a mechanism that jointly integrates information from distinct sources. It is ideal in the context of MR-only radiotherapy planning as it can jointly regress a synthetic CT (synCT) scan and segment organs-at-risk (OAR) from MRI. We propose a probabilistic multi-task network that estimates: 1) intrinsic uncertainty through a heteroscedastic noise model for spatially-adaptive task loss weighting and 2) parameter uncertainty through approximate Bayesian inference. This allows sampling of multiple segmentations and synCTs that share their network representation. We test our model on prostate cancer scans and show that it produces more accurate and consistent synCTs with a better estimation in the variance of the errors, state of the art results in OAR segmentation and a methodology for quality assurance in radiotherapy treatment planning.
Interpretable Fully Convolutional Classification of Intrapapillary Capillary Loops for Real-Time Detection of Early Squamous Neoplasia
May 02, 2018
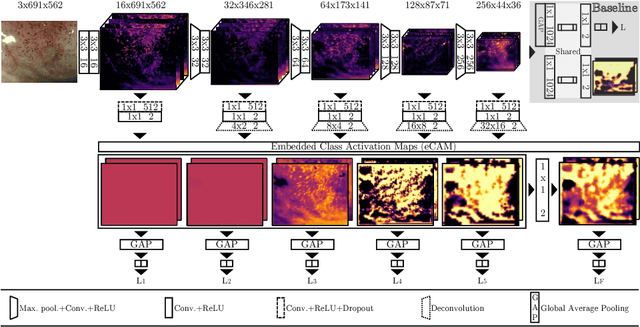
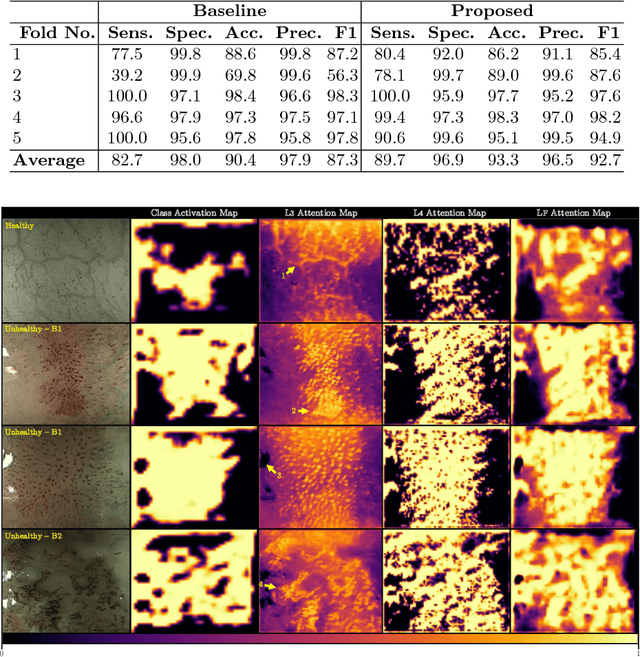
In this work, we have concentrated our efforts on the interpretability of classification results coming from a fully convolutional neural network. Motivated by the classification of oesophageal tissue for real-time detection of early squamous neoplasia, the most frequent kind of oesophageal cancer in Asia, we present a new dataset and a novel deep learning method that by means of deep supervision and a newly introduced concept, the embedded Class Activation Map (eCAM), focuses on the interpretability of results as a design constraint of a convolutional network. We present a new approach to visualise attention that aims to give some insights on those areas of the oesophageal tissue that lead a network to conclude that the images belong to a particular class and compare them with those visual features employed by clinicians to produce a clinical diagnosis. In comparison to a baseline method which does not feature deep supervision but provides attention by grafting Class Activation Maps, we improve the F1-score from 87.3% to 92.7% and provide more detailed attention maps.
NiftyNet: a deep-learning platform for medical imaging
Oct 16, 2017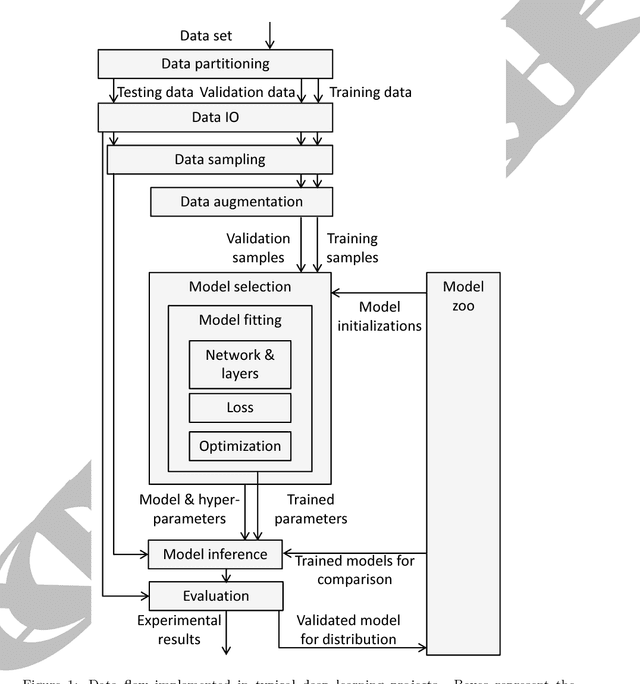
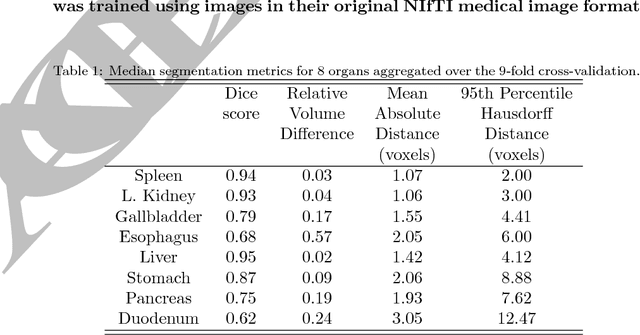
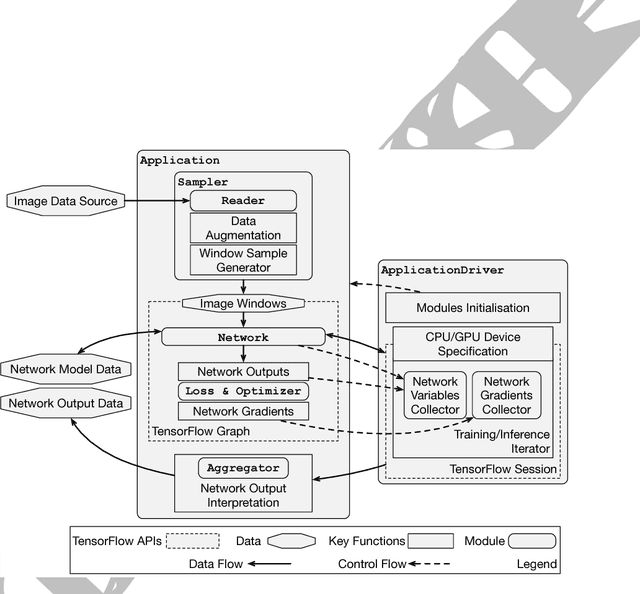
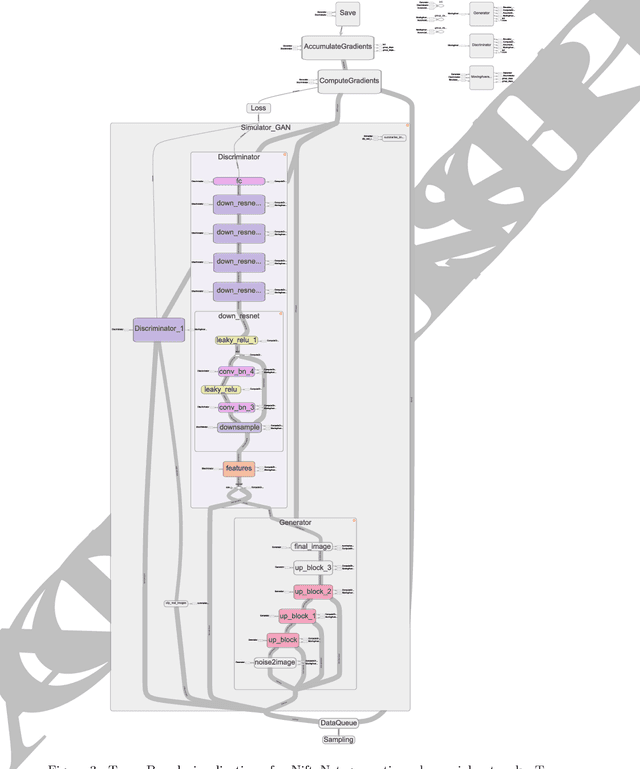
Medical image analysis and computer-assisted intervention problems are increasingly being addressed with deep-learning-based solutions. Established deep-learning platforms are flexible but do not provide specific functionality for medical image analysis and adapting them for this application requires substantial implementation effort. Thus, there has been substantial duplication of effort and incompatible infrastructure developed across many research groups. This work presents the open-source NiftyNet platform for deep learning in medical imaging. The ambition of NiftyNet is to accelerate and simplify the development of these solutions, and to provide a common mechanism for disseminating research outputs for the community to use, adapt and build upon. NiftyNet provides a modular deep-learning pipeline for a range of medical imaging applications including segmentation, regression, image generation and representation learning applications. Components of the NiftyNet pipeline including data loading, data augmentation, network architectures, loss functions and evaluation metrics are tailored to, and take advantage of, the idiosyncracies of medical image analysis and computer-assisted intervention. NiftyNet is built on TensorFlow and supports TensorBoard visualization of 2D and 3D images and computational graphs by default. We present 3 illustrative medical image analysis applications built using NiftyNet: (1) segmentation of multiple abdominal organs from computed tomography; (2) image regression to predict computed tomography attenuation maps from brain magnetic resonance images; and (3) generation of simulated ultrasound images for specified anatomical poses. NiftyNet enables researchers to rapidly develop and distribute deep learning solutions for segmentation, regression, image generation and representation learning applications, or extend the platform to new applications.
Interactive Medical Image Segmentation using Deep Learning with Image-specific Fine-tuning
Oct 11, 2017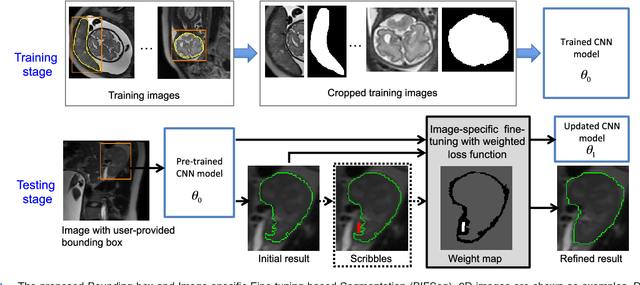
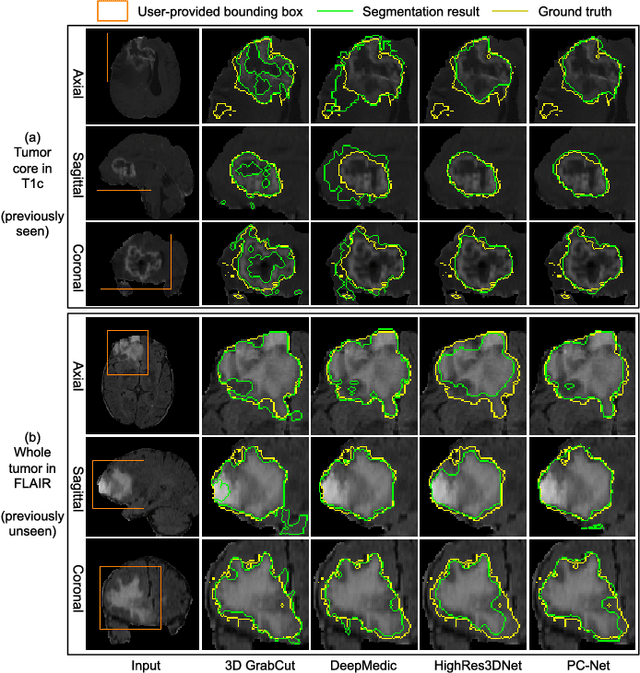
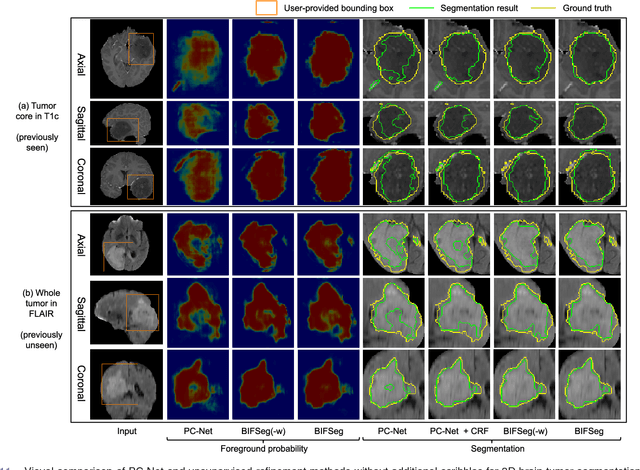
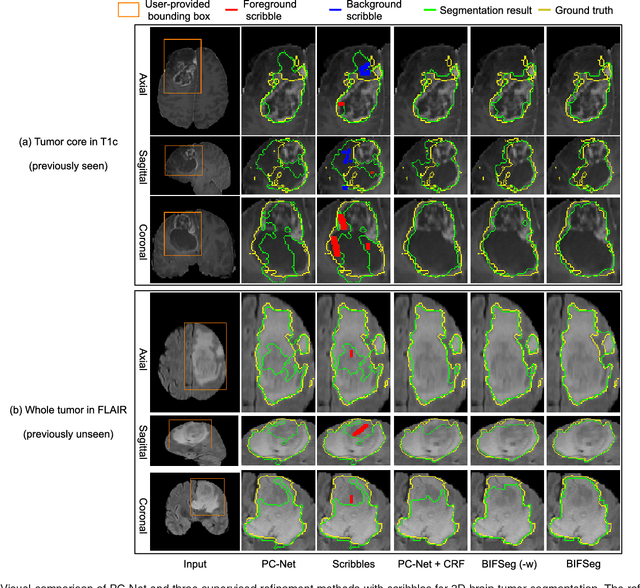
Convolutional neural networks (CNNs) have achieved state-of-the-art performance for automatic medical image segmentation. However, they have not demonstrated sufficiently accurate and robust results for clinical use. In addition, they are limited by the lack of image-specific adaptation and the lack of generalizability to previously unseen object classes. To address these problems, we propose a novel deep learning-based framework for interactive segmentation by incorporating CNNs into a bounding box and scribble-based segmentation pipeline. We propose image-specific fine-tuning to make a CNN model adaptive to a specific test image, which can be either unsupervised (without additional user interactions) or supervised (with additional scribbles). We also propose a weighted loss function considering network and interaction-based uncertainty for the fine-tuning. We applied this framework to two applications: 2D segmentation of multiple organs from fetal MR slices, where only two types of these organs were annotated for training; and 3D segmentation of brain tumor core (excluding edema) and whole brain tumor (including edema) from different MR sequences, where only tumor cores in one MR sequence were annotated for training. Experimental results show that 1) our model is more robust to segment previously unseen objects than state-of-the-art CNNs; 2) image-specific fine-tuning with the proposed weighted loss function significantly improves segmentation accuracy; and 3) our method leads to accurate results with fewer user interactions and less user time than traditional interactive segmentation methods.
DeepIGeoS: A Deep Interactive Geodesic Framework for Medical Image Segmentation
Sep 19, 2017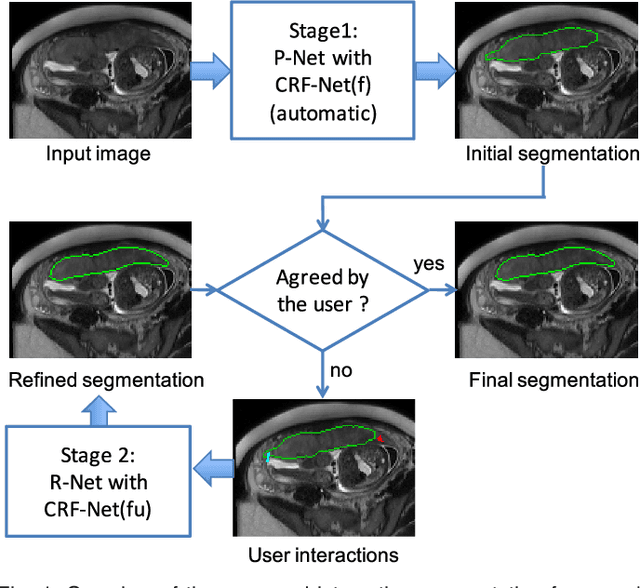
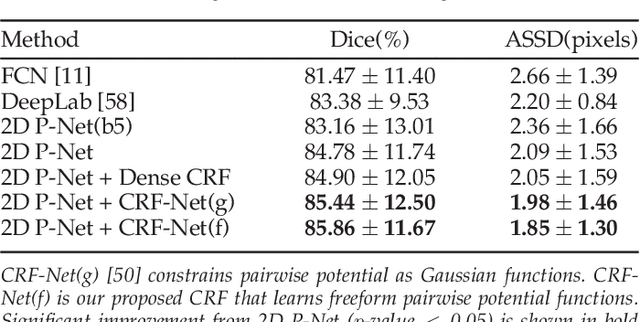
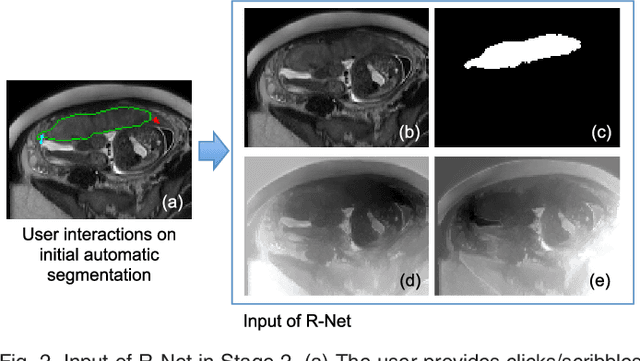
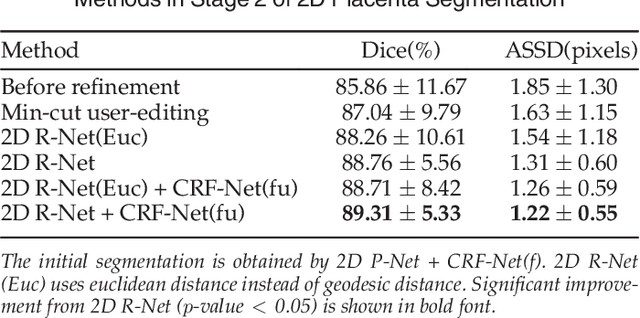
Accurate medical image segmentation is essential for diagnosis, surgical planning and many other applications. Convolutional Neural Networks (CNNs) have become the state-of-the-art automatic segmentation methods. However, fully automatic results may still need to be refined to become accurate and robust enough for clinical use. We propose a deep learning-based interactive segmentation method to improve the results obtained by an automatic CNN and to reduce user interactions during refinement for higher accuracy. We use one CNN to obtain an initial automatic segmentation, on which user interactions are added to indicate mis-segmentations. Another CNN takes as input the user interactions with the initial segmentation and gives a refined result. We propose to combine user interactions with CNNs through geodesic distance transforms, and propose a resolution-preserving network that gives a better dense prediction. In addition, we integrate user interactions as hard constraints into a back-propagatable Conditional Random Field. We validated the proposed framework in the context of 2D placenta segmentation from fetal MRI and 3D brain tumor segmentation from FLAIR images. Experimental results show our method achieves a large improvement from automatic CNNs, and obtains comparable and even higher accuracy with fewer user interventions and less time compared with traditional interactive methods.
Generalised Wasserstein Dice Score for Imbalanced Multi-class Segmentation using Holistic Convolutional Networks
Aug 29, 2017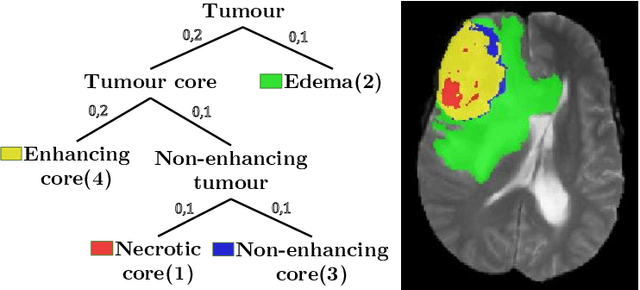
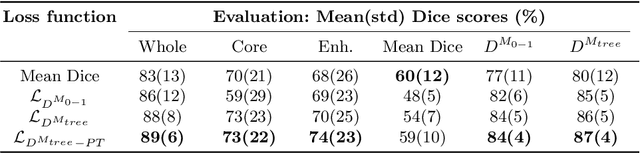
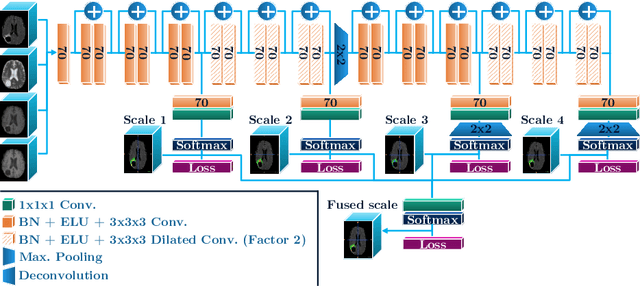
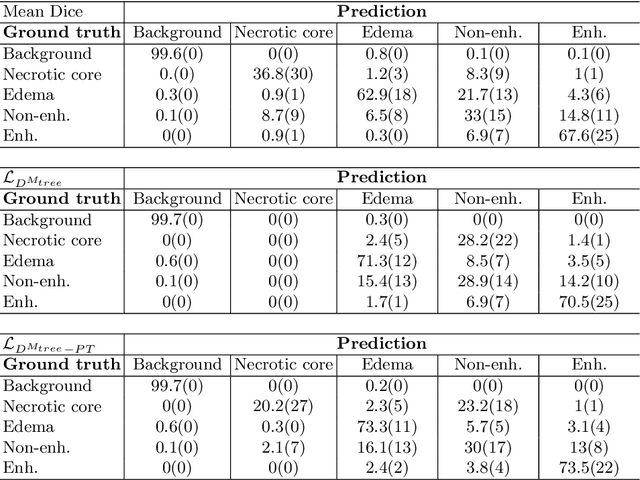
The Dice score is widely used for binary segmentation due to its robustness to class imbalance. Soft generalisations of the Dice score allow it to be used as a loss function for training convolutional neural networks (CNN). Although CNNs trained using mean-class Dice score achieve state-of-the-art results on multi-class segmentation, this loss function does neither take advantage of inter-class relationships nor multi-scale information. We argue that an improved loss function should balance misclassifications to favour predictions that are semantically meaningful. This paper investigates these issues in the context of multi-class brain tumour segmentation. Our contribution is threefold. 1) We propose a semantically-informed generalisation of the Dice score for multi-class segmentation based on the Wasserstein distance on the probabilistic label space. 2) We propose a holistic CNN that embeds spatial information at multiple scales with deep supervision. 3) We show that the joint use of holistic CNNs and generalised Wasserstein Dice scores achieves segmentations that are more semantically meaningful for brain tumour segmentation.
Generalised Dice overlap as a deep learning loss function for highly unbalanced segmentations
Jul 14, 2017
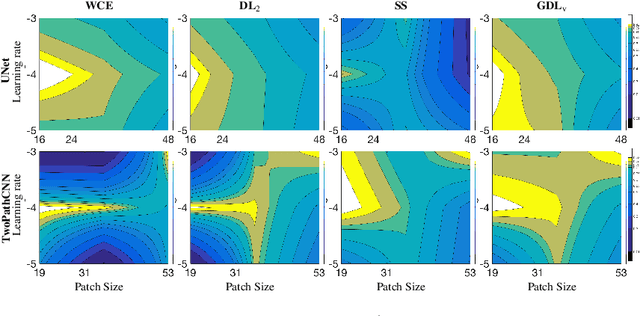
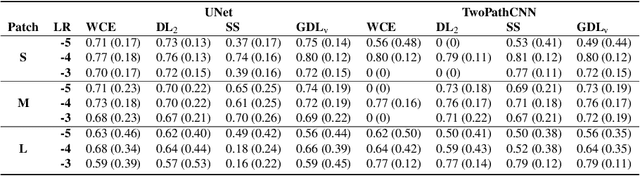
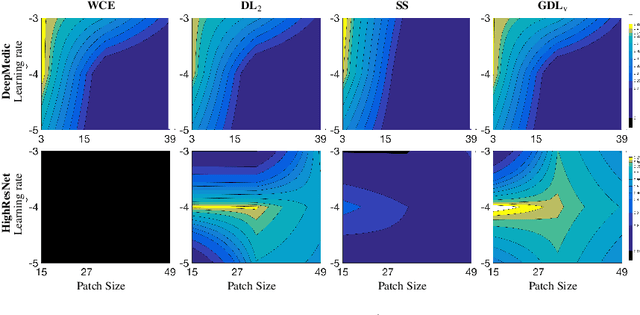
Deep-learning has proved in recent years to be a powerful tool for image analysis and is now widely used to segment both 2D and 3D medical images. Deep-learning segmentation frameworks rely not only on the choice of network architecture but also on the choice of loss function. When the segmentation process targets rare observations, a severe class imbalance is likely to occur between candidate labels, thus resulting in sub-optimal performance. In order to mitigate this issue, strategies such as the weighted cross-entropy function, the sensitivity function or the Dice loss function, have been proposed. In this work, we investigate the behavior of these loss functions and their sensitivity to learning rate tuning in the presence of different rates of label imbalance across 2D and 3D segmentation tasks. We also propose to use the class re-balancing properties of the Generalized Dice overlap, a known metric for segmentation assessment, as a robust and accurate deep-learning loss function for unbalanced tasks.