 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlausible May Not Be Faithful: Probing Object Hallucination in Vision-Language Pre-training
Oct 14, 2022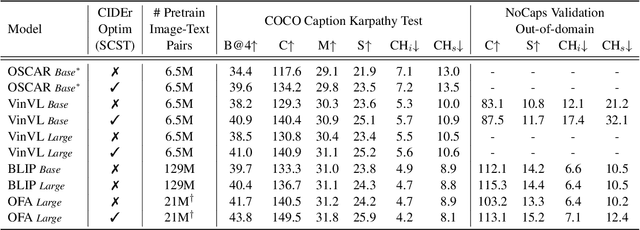

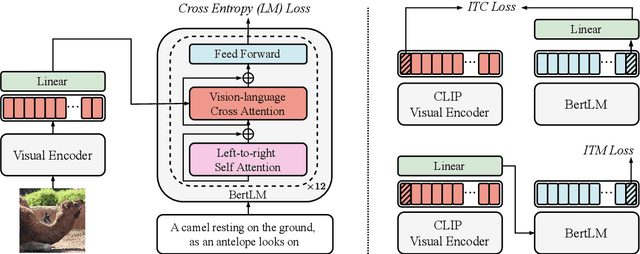
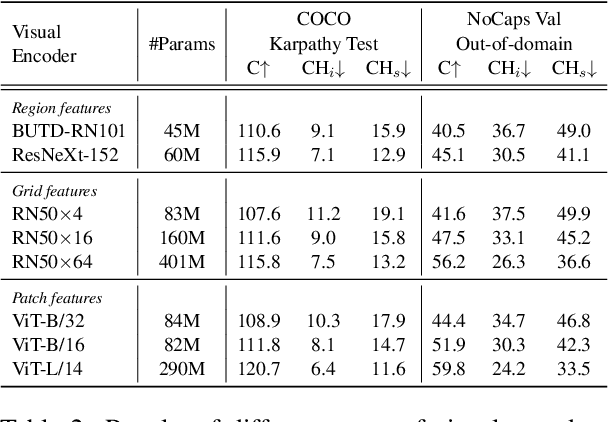
Large-scale vision-language pre-trained (VLP) models are prone to hallucinate non-existent visual objects when generating text based on visual information. In this paper, we exhaustively probe the object hallucination problem from three aspects. First, we examine various state-of-the-art VLP models, showing that models achieving better scores on standard metrics(e.g., BLEU-4, CIDEr) could hallucinate objects more frequently. Second, we investigate how different types of visual features in VLP influence hallucination, including region-based, grid-based, and patch-based. Surprisingly, we find that patch-based features perform the best and smaller patch resolution yields a non-trivial reduction in object hallucination. Third, we decouple various VLP objectives and demonstrate their effectiveness in alleviating object hallucination. Based on that, we propose a new pre-training loss, object masked language modeling, to further reduce object hallucination. We evaluate models on both COCO (in-domain) and NoCaps (out-of-domain) datasets with our improved CHAIR metric. Furthermore, we investigate the effects of various text decoding strategies and image augmentation methods on object hallucination.
Kaggle Competition: Cantonese Audio-Visual Speech Recognition for In-car Commands
Jul 06, 2022
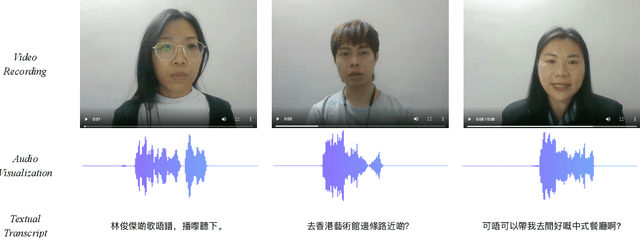
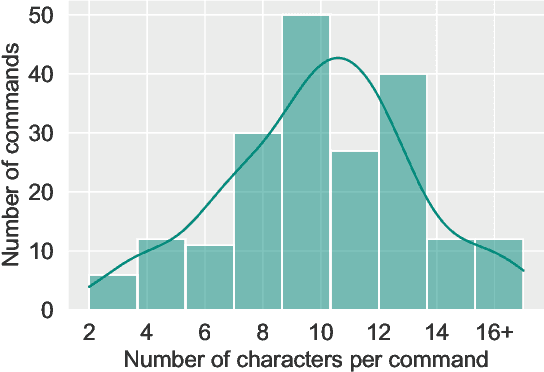

With the rise of deep learning and intelligent vehicles, the smart assistant has become an essential in-car component to facilitate driving and provide extra functionalities. In-car smart assistants should be able to process general as well as car-related commands and perform corresponding actions, which eases driving and improves safety. However, in this research field, most datasets are in major languages, such as English and Chinese. There is a huge data scarcity issue for low-resource languages, hindering the development of research and applications for broader communities. Therefore, it is crucial to have more benchmarks to raise awareness and motivate the research in low-resource languages. To mitigate this problem, we collect a new dataset, namely Cantonese In-car Audio-Visual Speech Recognition (CI-AVSR), for in-car speech recognition in the Cantonese language with video and audio data. Together with it, we propose Cantonese Audio-Visual Speech Recognition for In-car Commands as a new challenge for the community to tackle low-resource speech recognition under in-car scenarios.
Enabling Multimodal Generation on CLIP via Vision-Language Knowledge Distillation
Mar 30, 2022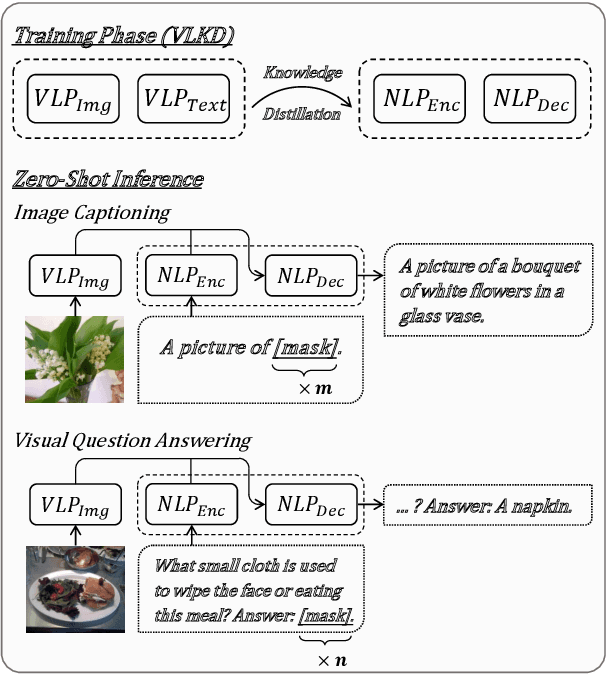
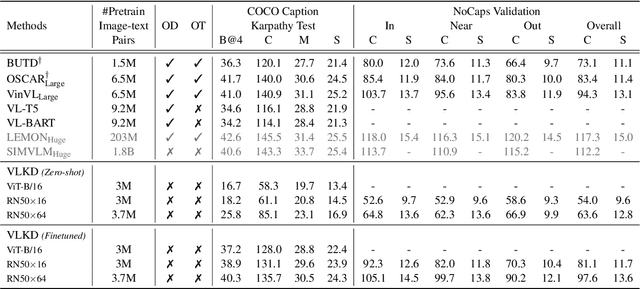
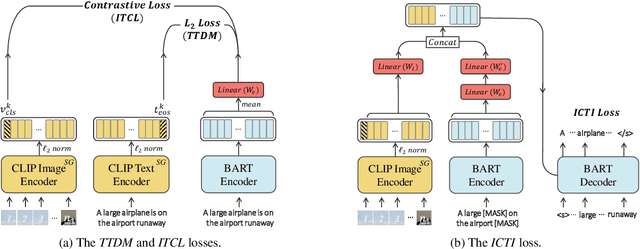
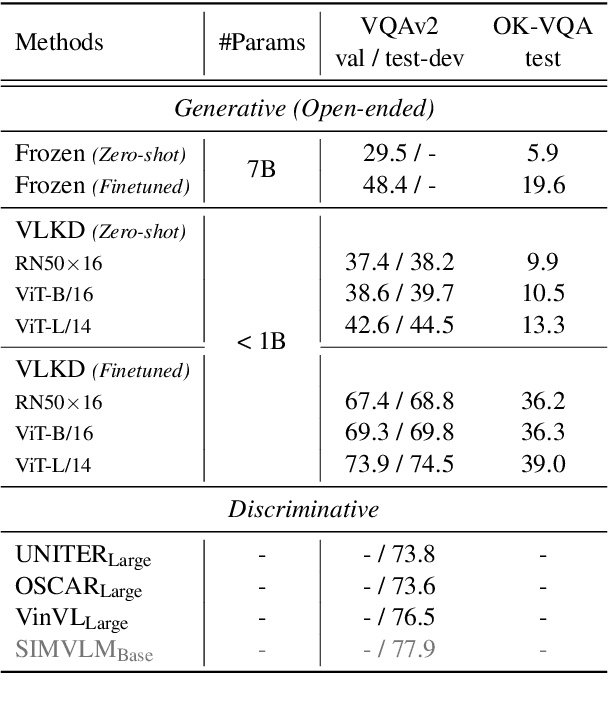
The recent large-scale vision-language pre-training (VLP) of dual-stream architectures (e.g., CLIP) with a tremendous amount of image-text pair data, has shown its superiority on various multimodal alignment tasks. Despite its success, the resulting models are not capable of multimodal generative tasks due to the weak text encoder. To tackle this problem, we propose to augment the dual-stream VLP model with a textual pre-trained language model (PLM) via vision-language knowledge distillation (VLKD), enabling the capability for multimodal generation. VLKD is pretty data- and computation-efficient compared to the pre-training from scratch. Experimental results show that the resulting model has strong zero-shot performance on multimodal generation tasks, such as open-ended visual question answering and image captioning. For example, it achieves 44.5% zero-shot accuracy on the VQAv2 dataset, surpassing the previous state-of-the-art zero-shot model with $7\times$ fewer parameters. Furthermore, the original textual language understanding and generation ability of the PLM is maintained after VLKD, which makes our model versatile for both multimodal and unimodal tasks.
Automatic Speech Recognition Datasets in Cantonese: A Survey and New Dataset
Jan 17, 2022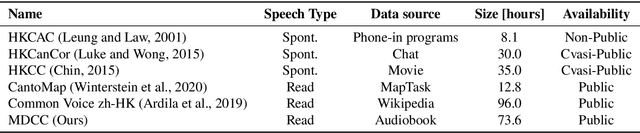
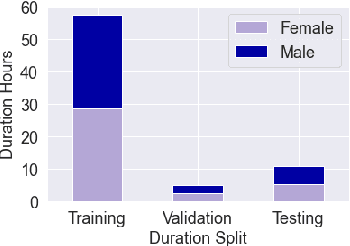
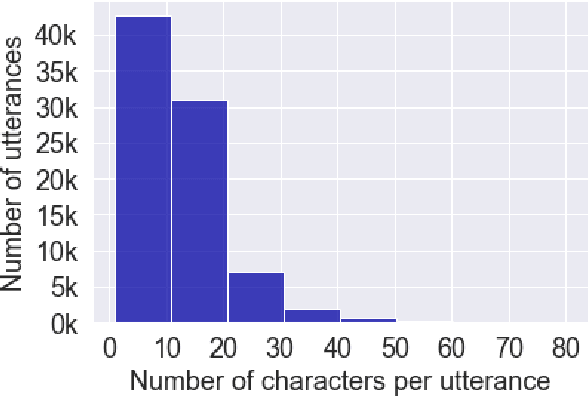
Automatic speech recognition (ASR) on low resource languages improves the access of linguistic minorities to technological advantages provided by artificial intelligence (AI). In this paper, we address the problem of data scarcity for the Hong Kong Cantonese language by creating a new Cantonese dataset. Our dataset, Multi-Domain Cantonese Corpus (MDCC), consists of 73.6 hours of clean read speech paired with transcripts, collected from Cantonese audiobooks from Hong Kong. It comprises philosophy, politics, education, culture, lifestyle and family domains, covering a wide range of topics. We also review all existing Cantonese datasets and analyze them according to their speech type, data source, total size and availability. We further conduct experiments with Fairseq S2T Transformer, a state-of-the-art ASR model, on the biggest existing dataset, Common Voice zh-HK, and our proposed MDCC, and the results show the effectiveness of our dataset. In addition, we create a powerful and robust Cantonese ASR model by applying multi-dataset learning on MDCC and Common Voice zh-HK.
CI-AVSR: A Cantonese Audio-Visual Speech Dataset for In-car Command Recognition
Jan 11, 2022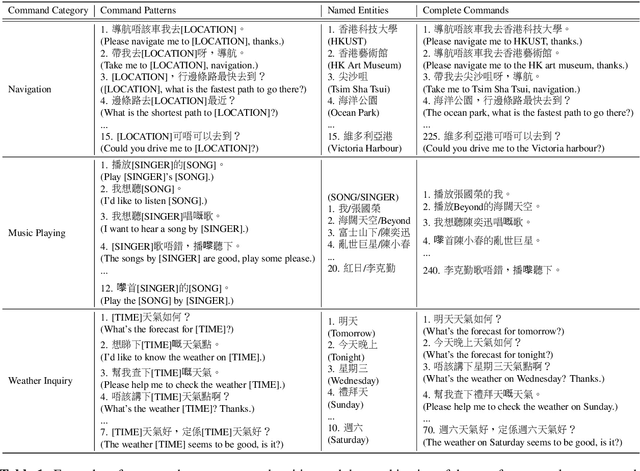
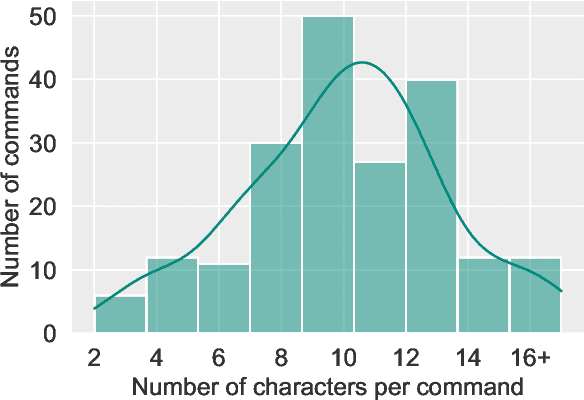
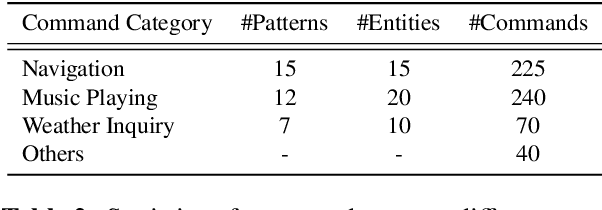
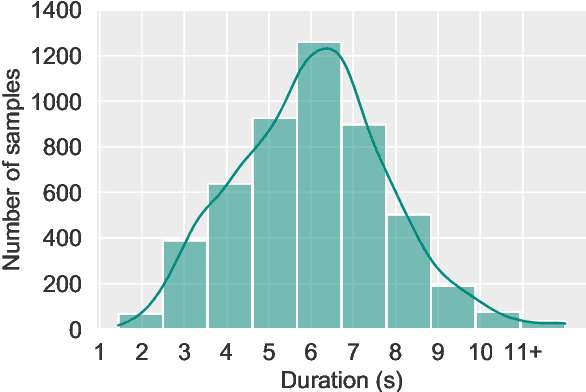
With the rise of deep learning and intelligent vehicle, the smart assistant has become an essential in-car component to facilitate driving and provide extra functionalities. In-car smart assistants should be able to process general as well as car-related commands and perform corresponding actions, which eases driving and improves safety. However, there is a data scarcity issue for low resource languages, hindering the development of research and applications. In this paper, we introduce a new dataset, Cantonese In-car Audio-Visual Speech Recognition (CI-AVSR), for in-car command recognition in the Cantonese language with both video and audio data. It consists of 4,984 samples (8.3 hours) of 200 in-car commands recorded by 30 native Cantonese speakers. Furthermore, we augment our dataset using common in-car background noises to simulate real environments, producing a dataset 10 times larger than the collected one. We provide detailed statistics of both the clean and the augmented versions of our dataset. Moreover, we implement two multimodal baselines to demonstrate the validity of CI-AVSR. Experiment results show that leveraging the visual signal improves the overall performance of the model. Although our best model can achieve a considerable quality on the clean test set, the speech recognition quality on the noisy data is still inferior and remains as an extremely challenging task for real in-car speech recognition systems. The dataset and code will be released at https://github.com/HLTCHKUST/CI-AVSR.
ASCEND: A Spontaneous Chinese-English Dataset for Code-switching in Multi-turn Conversation
Jan 07, 2022

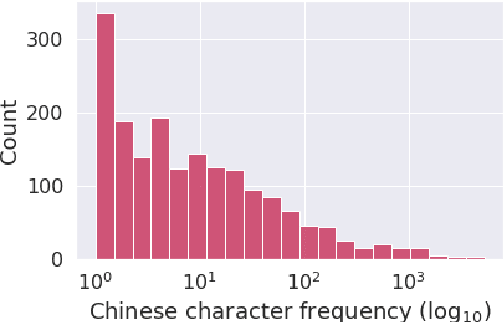
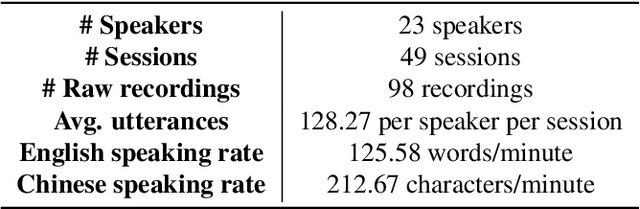
Code-switching is a speech phenomenon when a speaker switches language during a conversation. Despite the spontaneous nature of code-switching in conversational spoken language, most existing works collect code-switching data through read speech instead of spontaneous speech. ASCEND (A Spontaneous Chinese-English Dataset) introduces a high-quality resource of spontaneous multi-turn conversational dialogue Chinese-English code-switching corpus collected in Hong Kong. We report ASCEND's design and procedure of collecting the speech data, including the annotations in this work. ASCEND includes 23 bilinguals that are fluent in both Chinese and English and consists of 10.62 hours clean speech corpus. We also conduct a baseline experiment using pre-trained wav2vec 2.0 models, achieving the best performance of 22.69% character error rate and 27.05% mixed error rate.
Vision Guided Generative Pre-trained Language Models for Multimodal Abstractive Summarization
Oct 01, 2021
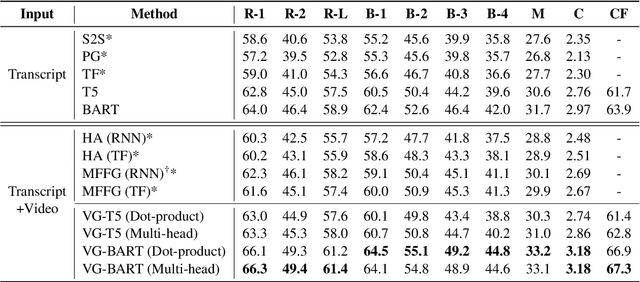
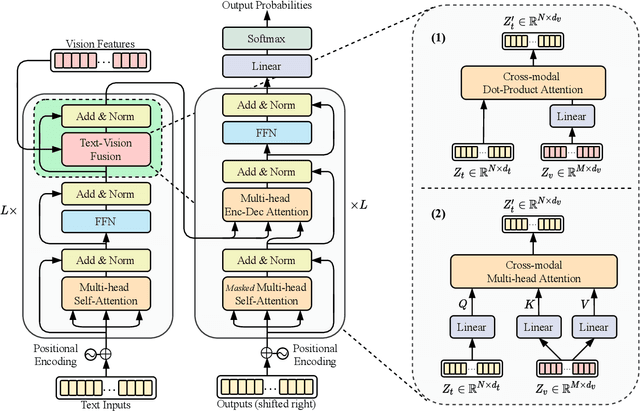

Multimodal abstractive summarization (MAS) models that summarize videos (vision modality) and their corresponding transcripts (text modality) are able to extract the essential information from massive multimodal data on the Internet. Recently, large-scale generative pre-trained language models (GPLMs) have been shown to be effective in text generation tasks. However, existing MAS models cannot leverage GPLMs' powerful generation ability. To fill this research gap, we aim to study two research questions: 1) how to inject visual information into GPLMs without hurting their generation ability; and 2) where is the optimal place in GPLMs to inject the visual information? In this paper, we present a simple yet effective method to construct vision guided (VG) GPLMs for the MAS task using attention-based add-on layers to incorporate visual information while maintaining their original text generation ability. Results show that our best model significantly surpasses the prior state-of-the-art model by 5.7 ROUGE-1, 5.3 ROUGE-2, and 5.1 ROUGE-L scores on the How2 dataset, and our visual guidance method contributes 83.6% of the overall improvement. Furthermore, we conduct thorough ablation studies to analyze the effectiveness of various modality fusion methods and fusion locations.
Greenformer: Factorization Toolkit for Efficient Deep Neural Networks
Sep 14, 2021

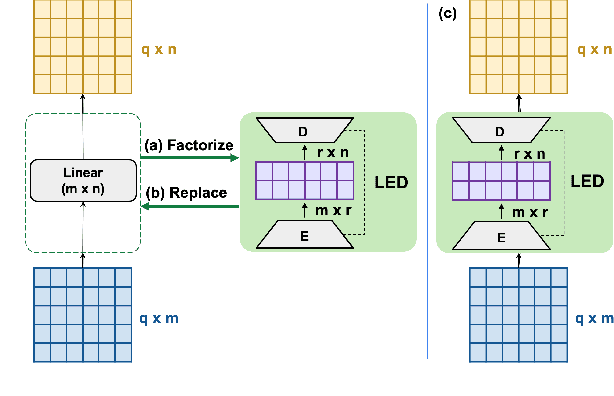
While the recent advances in deep neural networks (DNN) bring remarkable success, the computational cost also increases considerably. In this paper, we introduce Greenformer, a toolkit to accelerate the computation of neural networks through matrix factorization while maintaining performance. Greenformer can be easily applied with a single line of code to any DNN model. Our experimental results show that Greenformer is effective for a wide range of scenarios. We provide the showcase of Greenformer at https://samuelcahyawijaya.github.io/greenformer-demo/.
Weakly-supervised Multi-task Learning for Multimodal Affect Recognition
Apr 23, 2021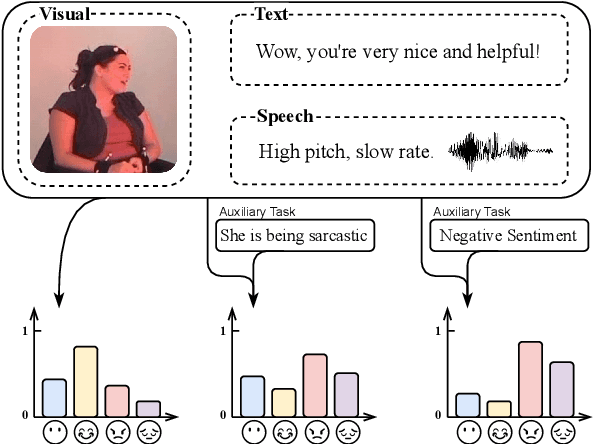
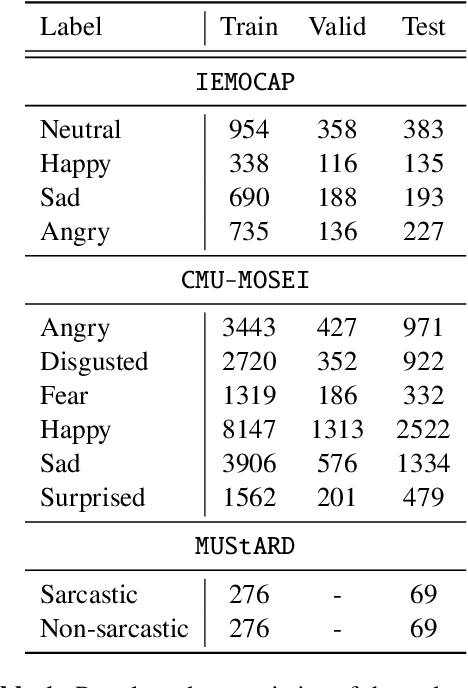
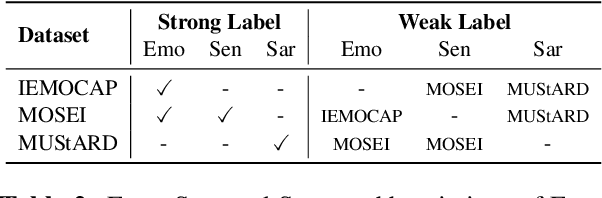
Multimodal affect recognition constitutes an important aspect for enhancing interpersonal relationships in human-computer interaction. However, relevant data is hard to come by and notably costly to annotate, which poses a challenging barrier to build robust multimodal affect recognition systems. Models trained on these relatively small datasets tend to overfit and the improvement gained by using complex state-of-the-art models is marginal compared to simple baselines. Meanwhile, there are many different multimodal affect recognition datasets, though each may be small. In this paper, we propose to leverage these datasets using weakly-supervised multi-task learning to improve the generalization performance on each of them. Specifically, we explore three multimodal affect recognition tasks: 1) emotion recognition; 2) sentiment analysis; and 3) sarcasm recognition. Our experimental results show that multi-tasking can benefit all these tasks, achieving an improvement up to 2.9% accuracy and 3.3% F1-score. Furthermore, our method also helps to improve the stability of model performance. In addition, our analysis suggests that weak supervision can provide a comparable contribution to strong supervision if the tasks are highly correlated.
Multimodal End-to-End Sparse Model for Emotion Recognition
Mar 27, 2021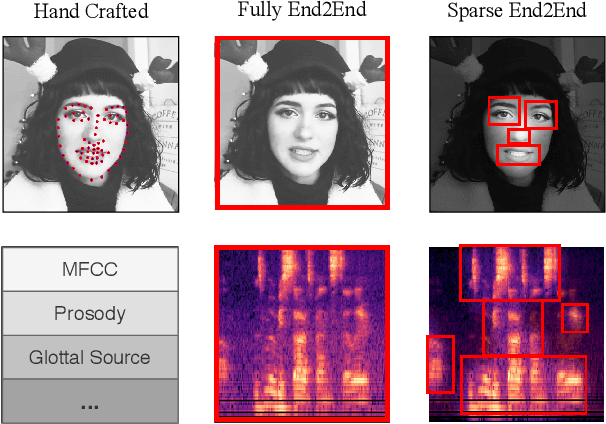
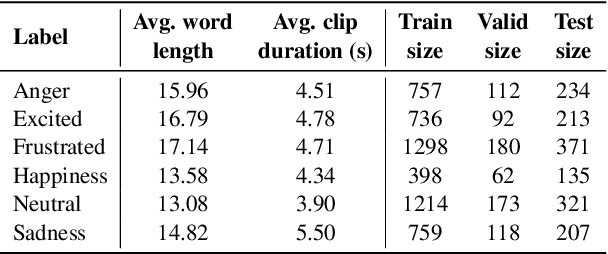
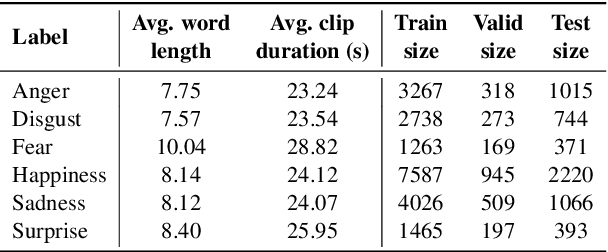
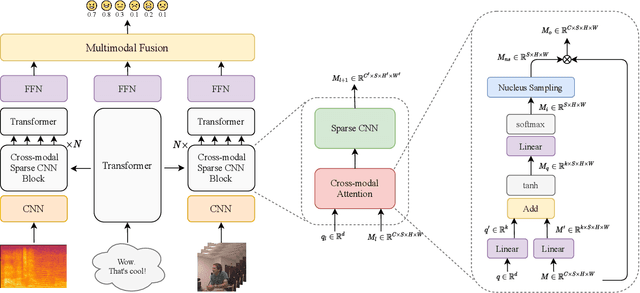
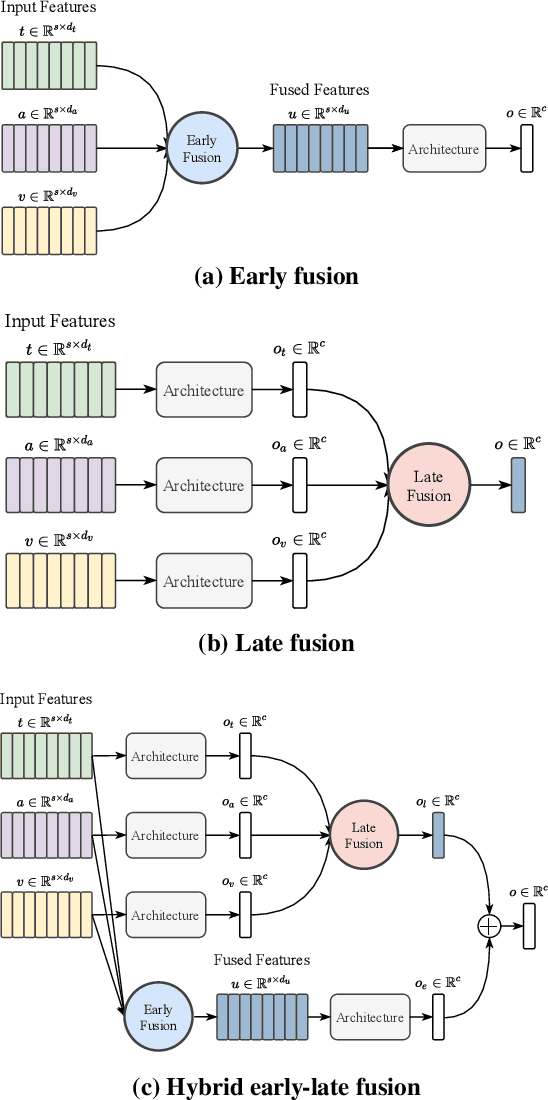
Existing works on multimodal affective computing tasks, such as emotion recognition, generally adopt a two-phase pipeline, first extracting feature representations for each single modality with hand-crafted algorithms and then performing end-to-end learning with the extracted features. However, the extracted features are fixed and cannot be further fine-tuned on different target tasks, and manually finding feature extraction algorithms does not generalize or scale well to different tasks, which can lead to sub-optimal performance. In this paper, we develop a fully end-to-end model that connects the two phases and optimizes them jointly. In addition, we restructure the current datasets to enable the fully end-to-end training. Furthermore, to reduce the computational overhead brought by the end-to-end model, we introduce a sparse cross-modal attention mechanism for the feature extraction. Experimental results show that our fully end-to-end model significantly surpasses the current state-of-the-art models based on the two-phase pipeline. Moreover, by adding the sparse cross-modal attention, our model can maintain performance with around half the computation in the feature extraction part.