 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMITATE: Clinical Prior Guided Hierarchical Vision-Language Pre-training
Oct 11, 2023



In the field of medical Vision-Language Pre-training (VLP), significant efforts have been devoted to deriving text and image features from both clinical reports and associated medical images. However, most existing methods may have overlooked the opportunity in leveraging the inherent hierarchical structure of clinical reports, which are generally split into `findings' for descriptive content and `impressions' for conclusive observation. Instead of utilizing this rich, structured format, current medical VLP approaches often simplify the report into either a unified entity or fragmented tokens. In this work, we propose a novel clinical prior guided VLP framework named IMITATE to learn the structure information from medical reports with hierarchical vision-language alignment. The framework derives multi-level visual features from the chest X-ray (CXR) images and separately aligns these features with the descriptive and the conclusive text encoded in the hierarchical medical report. Furthermore, a new clinical-informed contrastive loss is introduced for cross-modal learning, which accounts for clinical prior knowledge in formulating sample correlations in contrastive learning. The proposed model, IMITATE, outperforms baseline VLP methods across six different datasets, spanning five medical imaging downstream tasks. Comprehensive experimental results highlight the advantages of integrating the hierarchical structure of medical reports for vision-language alignment.
Utilizing Synthetic Data for Medical Vision-Language Pre-training: Bypassing the Need for Real Images
Oct 10, 2023



Medical Vision-Language Pre-training (VLP) learns representations jointly from medical images and paired radiology reports. It typically requires large-scale paired image-text datasets to achieve effective pre-training for both the image encoder and text encoder. The advent of text-guided generative models raises a compelling question: Can VLP be implemented solely with synthetic images generated from genuine radiology reports, thereby mitigating the need for extensively pairing and curating image-text datasets? In this work, we scrutinize this very question by examining the feasibility and effectiveness of employing synthetic images for medical VLP. We replace real medical images with their synthetic equivalents, generated from authentic medical reports. Utilizing three state-of-the-art VLP algorithms, we exclusively train on these synthetic samples. Our empirical evaluation across three subsequent tasks, namely image classification, semantic segmentation and object detection, reveals that the performance achieved through synthetic data is on par with or even exceeds that obtained with real images. As a pioneering contribution to this domain, we introduce a large-scale synthetic medical image dataset, paired with anonymized real radiology reports. This alleviates the need of sharing medical images, which are not easy to curate and share in practice. The code and the dataset will be made publicly available upon paper acceptance.
T1/T2 relaxation temporal modelling from accelerated acquisitions using a Latent Transformer
Sep 28, 2023Quantitative cardiac magnetic resonance T1 and T2 mapping enable myocardial tissue characterisation but the lengthy scan times restrict their widespread clinical application. We propose a deep learning method that incorporates a time dependency Latent Transformer module to model relationships between parameterised time frames for improved reconstruction from undersampled data. The module, implemented as a multi-resolution sequence-to-sequence transformer, is integrated into an encoder-decoder architecture to leverage the inherent temporal correlations in relaxation processes. The presented results for accelerated T1 and T2 mapping show the model recovers maps with higher fidelity by explicit incorporation of time dynamics. This work demonstrates the importance of temporal modelling for artifact-free reconstruction in quantitative MRI.
DeepMesh: Mesh-based Cardiac Motion Tracking using Deep Learning
Sep 25, 2023



3D motion estimation from cine cardiac magnetic resonance (CMR) images is important for the assessment of cardiac function and the diagnosis of cardiovascular diseases. Current state-of-the art methods focus on estimating dense pixel-/voxel-wise motion fields in image space, which ignores the fact that motion estimation is only relevant and useful within the anatomical objects of interest, e.g., the heart. In this work, we model the heart as a 3D mesh consisting of epi- and endocardial surfaces. We propose a novel learning framework, DeepMesh, which propagates a template heart mesh to a subject space and estimates the 3D motion of the heart mesh from CMR images for individual subjects. In DeepMesh, the heart mesh of the end-diastolic frame of an individual subject is first reconstructed from the template mesh. Mesh-based 3D motion fields with respect to the end-diastolic frame are then estimated from 2D short- and long-axis CMR images. By developing a differentiable mesh-to-image rasterizer, DeepMesh is able to leverage 2D shape information from multiple anatomical views for 3D mesh reconstruction and mesh motion estimation. The proposed method estimates vertex-wise displacement and thus maintains vertex correspondences between time frames, which is important for the quantitative assessment of cardiac function across different subjects and populations. We evaluate DeepMesh on CMR images acquired from the UK Biobank. We focus on 3D motion estimation of the left ventricle in this work. Experimental results show that the proposed method quantitatively and qualitatively outperforms other image-based and mesh-based cardiac motion tracking methods.
CMRxRecon: An open cardiac MRI dataset for the competition of accelerated image reconstruction
Sep 19, 2023



Cardiac magnetic resonance imaging (CMR) has emerged as a valuable diagnostic tool for cardiac diseases. However, a limitation of CMR is its slow imaging speed, which causes patient discomfort and introduces artifacts in the images. There has been growing interest in deep learning-based CMR imaging algorithms that can reconstruct high-quality images from highly under-sampled k-space data. However, the development of deep learning methods requires large training datasets, which have not been publicly available for CMR. To address this gap, we released a dataset that includes multi-contrast, multi-view, multi-slice and multi-coil CMR imaging data from 300 subjects. Imaging studies include cardiac cine and mapping sequences. Manual segmentations of the myocardium and chambers of all the subjects are also provided within the dataset. Scripts of state-of-the-art reconstruction algorithms were also provided as a point of reference. Our aim is to facilitate the advancement of state-of-the-art CMR image reconstruction by introducing standardized evaluation criteria and making the dataset freely accessible to the research community. Researchers can access the dataset at https://www.synapse.org/#!Synapse:syn51471091/wiki/.
LesionMix: A Lesion-Level Data Augmentation Method for Medical Image Segmentation
Aug 17, 2023



Data augmentation has become a de facto component of deep learning-based medical image segmentation methods. Most data augmentation techniques used in medical imaging focus on spatial and intensity transformations to improve the diversity of training images. They are often designed at the image level, augmenting the full image, and do not pay attention to specific abnormalities within the image. Here, we present LesionMix, a novel and simple lesion-aware data augmentation method. It performs augmentation at the lesion level, increasing the diversity of lesion shape, location, intensity and load distribution, and allowing both lesion populating and inpainting. Experiments on different modalities and different lesion datasets, including four brain MR lesion datasets and one liver CT lesion dataset, demonstrate that LesionMix achieves promising performance in lesion image segmentation, outperforming several recent Mix-based data augmentation methods. The code will be released at https://github.com/dogabasaran/lesionmix.
Hierarchical Uncertainty Estimation for Medical Image Segmentation Networks
Aug 16, 2023



Learning a medical image segmentation model is an inherently ambiguous task, as uncertainties exist in both images (noise) and manual annotations (human errors and bias) used for model training. To build a trustworthy image segmentation model, it is important to not just evaluate its performance but also estimate the uncertainty of the model prediction. Most state-of-the-art image segmentation networks adopt a hierarchical encoder architecture, extracting image features at multiple resolution levels from fine to coarse. In this work, we leverage this hierarchical image representation and propose a simple yet effective method for estimating uncertainties at multiple levels. The multi-level uncertainties are modelled via the skip-connection module and then sampled to generate an uncertainty map for the predicted image segmentation. We demonstrate that a deep learning segmentation network such as U-net, when implemented with such hierarchical uncertainty estimation module, can achieve a high segmentation performance, while at the same time provide meaningful uncertainty maps that can be used for out-of-distribution detection.
M-FLAG: Medical Vision-Language Pre-training with Frozen Language Models and Latent Space Geometry Optimization
Jul 19, 2023



Medical vision-language models enable co-learning and integrating features from medical imaging and clinical text. However, these models are not easy to train and the latent representation space can be complex. Here we propose a novel way for pre-training and regularising medical vision-language models. The proposed method, named Medical vision-language pre-training with Frozen language models and Latent spAce Geometry optimization (M-FLAG), leverages a frozen language model for training stability and efficiency and introduces a novel orthogonality loss to harmonize the latent space geometry. We demonstrate the potential of the pre-trained model on three downstream tasks: medical image classification, segmentation, and object detection. Extensive experiments across five public datasets demonstrate that M-FLAG significantly outperforms existing medical vision-language pre-training approaches and reduces the number of parameters by 78\%. Notably, M-FLAG achieves outstanding performance on the segmentation task while using only 1\% of the RSNA dataset, even outperforming ImageNet pre-trained models that have been fine-tuned using 100\% of the data.
CHeart: A Conditional Spatio-Temporal Generative Model for Cardiac Anatomy
Jan 30, 2023Two key questions in cardiac image analysis are to assess the anatomy and motion of the heart from images; and to understand how they are associated with non-imaging clinical factors such as gender, age and diseases. While the first question can often be addressed by image segmentation and motion tracking algorithms, our capability to model and to answer the second question is still limited. In this work, we propose a novel conditional generative model to describe the 4D spatio-temporal anatomy of the heart and its interaction with non-imaging clinical factors. The clinical factors are integrated as the conditions of the generative modelling, which allows us to investigate how these factors influence the cardiac anatomy. We evaluate the model performance in mainly two tasks, anatomical sequence completion and sequence generation. The model achieves a high performance in anatomical sequence completion, comparable to or outperforming other state-of-the-art generative models. In terms of sequence generation, given clinical conditions, the model can generate realistic synthetic 4D sequential anatomies that share similar distributions with the real data.
The Extreme Cardiac MRI Analysis Challenge under Respiratory Motion (CMRxMotion)
Oct 12, 2022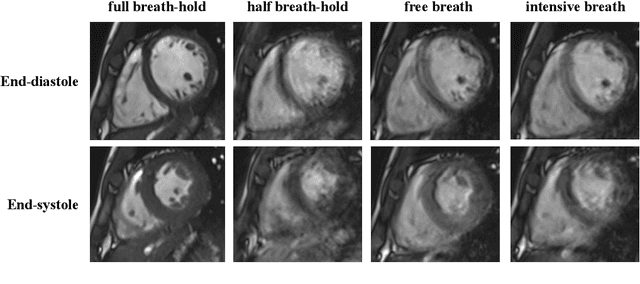
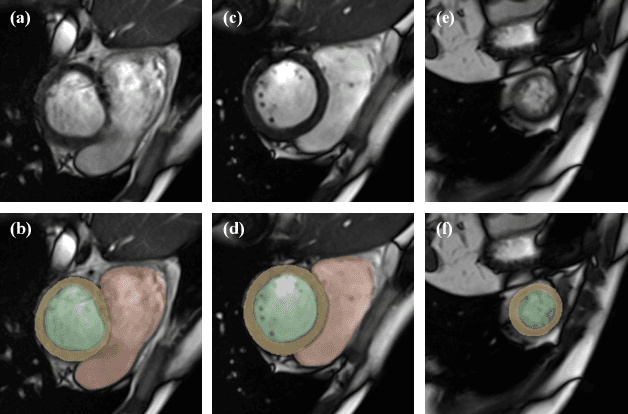

The quality of cardiac magnetic resonance (CMR) imaging is susceptible to respiratory motion artifacts. The model robustness of automated segmentation techniques in face of real-world respiratory motion artifacts is unclear. This manuscript describes the design of extreme cardiac MRI analysis challenge under respiratory motion (CMRxMotion Challenge). The challenge aims to establish a public benchmark dataset to assess the effects of respiratory motion on image quality and examine the robustness of segmentation models. The challenge recruited 40 healthy volunteers to perform different breath-hold behaviors during one imaging visit, obtaining paired cine imaging with artifacts. Radiologists assessed the image quality and annotated the level of respiratory motion artifacts. For those images with diagnostic quality, radiologists further segmented the left ventricle, left ventricle myocardium and right ventricle. The images of training set (20 volunteers) along with the annotations are released to the challenge participants, to develop an automated image quality assessment model (Task 1) and an automated segmentation model (Task 2). The images of validation set (5 volunteers) are released to the challenge participants but the annotations are withheld for online evaluation of submitted predictions. Both the images and annotations of the test set (15 volunteers) were withheld and only used for offline evaluation of submitted containerized dockers. The image quality assessment task is quantitatively evaluated by the Cohen's kappa statistics and the segmentation task is evaluated by the Dice scores and Hausdorff distances.