 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCP-factorization for high dimensional tensor time series and double projection iterations
Jun 07, 2026We adopt the canonical polyadic (CP) decomposition to model high-dimensional tensor time series. Our primary goal is to identify and estimate the factor loadings in the CP decomposition. We propose a one-pass estimation procedure through standard eigen-analysis for a matrix constructed based on the serial dependence structure of the data. The asymptotic properties of the proposed estimator are established under a general setting as long as the factor loading vectors are linearly independent, allowing the factors to be correlated and the factor loading vectors to be not nearly orthogonal. The procedure adapts to the sparsity of the factor loading vectors, accommodates weak factors, and demonstrates strong performance across a wide range of scenarios. To further reduce estimation errors, we also introduce an iterative algorithm based on a novel double projection approach. We theoretically justify the improved convergence rate of the iterative estimator, and derive the associated limiting distribution. A consistent estimator of the asymptotic variance is also provided, which plays a key role in the related inference problems. All results are validated through extensive simulations and two real data applications.
PPC-MT: Parallel Point Cloud Completion with Mamba-Transformer Hybrid Architecture
Mar 01, 2026Existing point cloud completion methods struggle to balance high-quality reconstruction with computational efficiency. To address this, we propose PPC-MT, a novel parallel framework for point cloud completion leveraging a hybrid Mamba-Transformer architecture. Our approach introduces an innovative parallel completion strategy guided by Principal Component Analysis (PCA), which imposes a geometrically meaningful structure on unordered point clouds, transforming them into ordered sets and decomposing them into multiple subsets. These subsets are reconstructed in parallel using a multi-head reconstructor. This structured parallel synthesis paradigm significantly enhances the uniformity of point distribution and detail fidelity, while preserving computational efficiency. By integrating Mamba's linear complexity for efficient feature extraction during encoding with the Transformer's capability to model fine-grained multi-sequence relationships during decoding, PPC-MT effectively balances efficiency and reconstruction accuracy. Extensive quantitative and qualitative experiments on benchmark datasets, including PCN, ShapeNet-55/34, and KITTI, demonstrate that PPC-MT outperforms state-of-the-art methods across multiple metrics, validating the efficacy of our proposed framework.
Image Aesthetic Reasoning via HCM-GRPO: Empowering Compact Model for Superior Performance
Nov 13, 2025The performance of image generation has been significantly improved in recent years. However, the study of image screening is rare and its performance with Multimodal Large Language Models (MLLMs) is unsatisfactory due to the lack of data and the weak image aesthetic reasoning ability in MLLMs. In this work, we propose a complete solution to address these problems in terms of data and methodology. For data, we collect a comprehensive image screening dataset with over 128k samples, about 640k images. Each sample consists of an original image, four generated images. The dataset evaluates the image aesthetic reasoning ability under four aspects: appearance deformation, physical shadow, placement layout, and extension rationality. Regarding data annotation, we investigate multiple approaches, including purely manual, fully automated, and answer-driven annotations, to acquire high-quality chains of thought (CoT) data in the most cost-effective manner. Methodologically, we introduce a Hard Cases Mining (HCM) strategy with a Dynamic Proportional Accuracy (DPA) reward into the Group Relative Policy Optimization (GRPO) framework, called HCM-GRPO. This enhanced method demonstrates superior image aesthetic reasoning capabilities compared to the original GRPO. Our experimental results reveal that even state-of-the-art closed-source MLLMs, such as GPT4o and Qwen-VL-Max, exhibit performance akin to random guessing in image aesthetic reasoning. In contrast, by leveraging the HCM-GRPO, we are able to surpass the scores of both large-scale open-source and leading closed-source models with a much smaller model.
Multi-Granularity Mutual Refinement Network for Zero-Shot Learning
Nov 11, 2025Zero-shot learning (ZSL) aims to recognize unseen classes with zero samples by transferring semantic knowledge from seen classes. Current approaches typically correlate global visual features with semantic information (i.e., attributes) or align local visual region features with corresponding attributes to enhance visual-semantic interactions. Although effective, these methods often overlook the intrinsic interactions between local region features, which can further improve the acquisition of transferable and explicit visual features. In this paper, we propose a network named Multi-Granularity Mutual Refinement Network (Mg-MRN), which refine discriminative and transferable visual features by learning decoupled multi-granularity features and cross-granularity feature interactions. Specifically, we design a multi-granularity feature extraction module to learn region-level discriminative features through decoupled region feature mining. Then, a cross-granularity feature fusion module strengthens the inherent interactions between region features of varying granularities. This module enhances the discriminability of representations at each granularity level by integrating region representations from adjacent hierarchies, further improving ZSL recognition performance. Extensive experiments on three popular ZSL benchmark datasets demonstrate the superiority and competitiveness of our proposed Mg-MRN method. Our code is available at https://github.com/NingWang2049/Mg-MRN.
Image Aesthetic Reasoning: A New Benchmark for Medical Image Screening with MLLMs
May 29, 2025Multimodal Large Language Models (MLLMs) are of great application across many domains, such as multimodal understanding and generation. With the development of diffusion models (DM) and unified MLLMs, the performance of image generation has been significantly improved, however, the study of image screening is rare and its performance with MLLMs is unsatisfactory due to the lack of data and the week image aesthetic reasoning ability in MLLMs. In this work, we propose a complete solution to address these problems in terms of data and methodology. For data, we collect a comprehensive medical image screening dataset with 1500+ samples, each sample consists of a medical image, four generated images, and a multiple-choice answer. The dataset evaluates the aesthetic reasoning ability under four aspects: \textit{(1) Appearance Deformation, (2) Principles of Physical Lighting and Shadow, (3) Placement Layout, (4) Extension Rationality}. For methodology, we utilize long chains of thought (CoT) and Group Relative Policy Optimization with Dynamic Proportional Accuracy reward, called DPA-GRPO, to enhance the image aesthetic reasoning ability of MLLMs. Our experimental results reveal that even state-of-the-art closed-source MLLMs, such as GPT-4o and Qwen-VL-Max, exhibit performance akin to random guessing in image aesthetic reasoning. In contrast, by leveraging the reinforcement learning approach, we are able to surpass the score of both large-scale models and leading closed-source models using a much smaller model. We hope our attempt on medical image screening will serve as a regular configuration in image aesthetic reasoning in the future.
Flexible-weighted Chamfer Distance: Enhanced Objective Function for Point Cloud Completion
May 20, 2025



Chamfer Distance (CD) comprises two components that can evaluate the global distribution and local performance of generated point clouds, making it widely utilized as a similarity measure between generated and target point clouds in point cloud completion tasks. Additionally, CD's computational efficiency has led to its frequent application as an objective function for guiding point cloud generation. However, using CD directly as an objective function with fixed equal weights for its two components can often result in seemingly high overall performance (i.e., low CD score), while failing to achieve a good global distribution. This is typically reflected in high Earth Mover's Distance (EMD) and Decomposed Chamfer Distance (DCD) scores, alongside poor human assessments. To address this issue, we propose a Flexible-Weighted Chamfer Distance (FCD) to guide point cloud generation. FCD assigns a higher weight to the global distribution component of CD and incorporates a flexible weighting strategy to adjust the balance between the two components, aiming to improve global distribution while maintaining robust overall performance. Experimental results on two state-of-the-art networks demonstrate that our method achieves superior results across multiple evaluation metrics, including CD, EMD, DCD, and F-Score, as well as in human evaluations.
Stecformer: Spatio-temporal Encoding Cascaded Transformer for Multivariate Long-term Time Series Forecasting
May 25, 2023



Multivariate long-term time series forecasting is of great application across many domains, such as energy consumption and weather forecasting. With the development of transformer-based methods, the performance of multivariate long-term time series forecasting has been significantly improved, however, the study of spatial features extracting in transformer-based model is rare and the consistency of different prediction periods is unsatisfactory due to the large span. In this work, we propose a complete solution to address these problems in terms of feature extraction and target prediction. For extraction, we design an efficient spatio-temporal encoding extractor including a semi-adaptive graph to acquire sufficient spatio-temporal information. For prediction, we propose a Cascaded Decoding Predictor (CDP) to strengthen the correlation between different intervals, which can also be utilized as a generic component to improve the performance of transformer-based methods. The proposed method, termed as Spatio-temporal Encoding Cascaded Transformer (Stecformer), achieving a notable gap over the baseline model and is comparable with the state-of-the-art performance of transformer-based methods on five benchmark datasets. We hope our attempt will serve as a regular configuration in multivariate long-term time series forecasting in the future.
AxWin Transformer: A Context-Aware Vision Transformer Backbone with Axial Windows
May 02, 2023



Recently Transformer has shown good performance in several vision tasks due to its powerful modeling capabilities. To reduce the quadratic complexity caused by the attention, some outstanding work restricts attention to local regions or extends axial interactions. However, these methos often lack the interaction of local and global information, balancing coarse and fine-grained information. To address this problem, we propose AxWin Attention, which models context information in both local windows and axial views. Based on the AxWin Attention, we develop a context-aware vision transformer backbone, named AxWin Transformer, which outperforming the state-of-the-art methods in both classification and downstream segmentation and detection tasks.
PRSeg: A Lightweight Patch Rotate MLP Decoder for Semantic Segmentation
May 01, 2023



The lightweight MLP-based decoder has become increasingly promising for semantic segmentation. However, the channel-wise MLP cannot expand the receptive fields, lacking the context modeling capacity, which is critical to semantic segmentation. In this paper, we propose a parametric-free patch rotate operation to reorganize the pixels spatially. It first divides the feature map into multiple groups and then rotates the patches within each group. Based on the proposed patch rotate operation, we design a novel segmentation network, named PRSeg, which includes an off-the-shelf backbone and a lightweight Patch Rotate MLP decoder containing multiple Dynamic Patch Rotate Blocks (DPR-Blocks). In each DPR-Block, the fully connected layer is performed following a Patch Rotate Module (PRM) to exchange spatial information between pixels. Specifically, in PRM, the feature map is first split into the reserved part and rotated part along the channel dimension according to the predicted probability of the Dynamic Channel Selection Module (DCSM), and our proposed patch rotate operation is only performed on the rotated part. Extensive experiments on ADE20K, Cityscapes and COCO-Stuff 10K datasets prove the effectiveness of our approach. We expect that our PRSeg can promote the development of MLP-based decoder in semantic segmentation.
HiFuse: Hierarchical Multi-Scale Feature Fusion Network for Medical Image Classification
Sep 21, 2022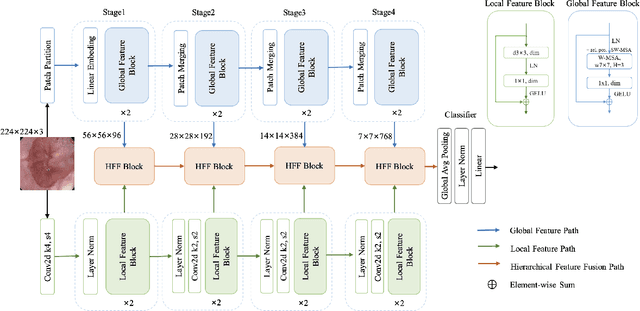
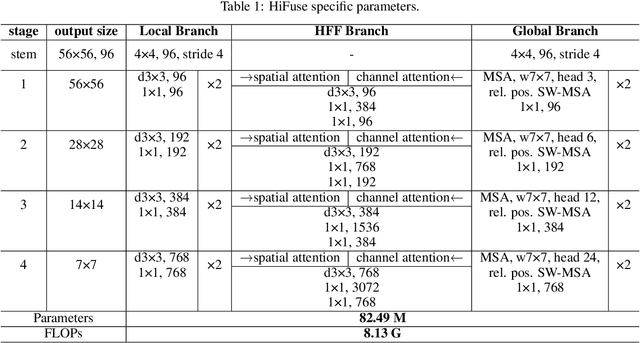
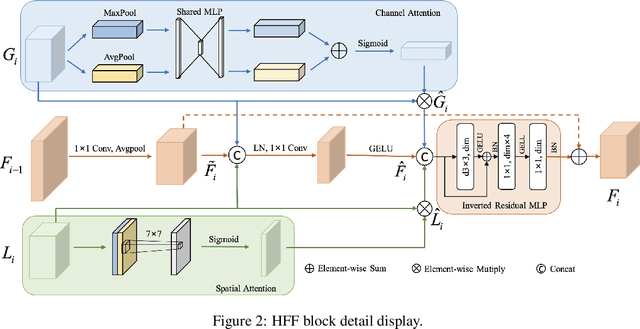
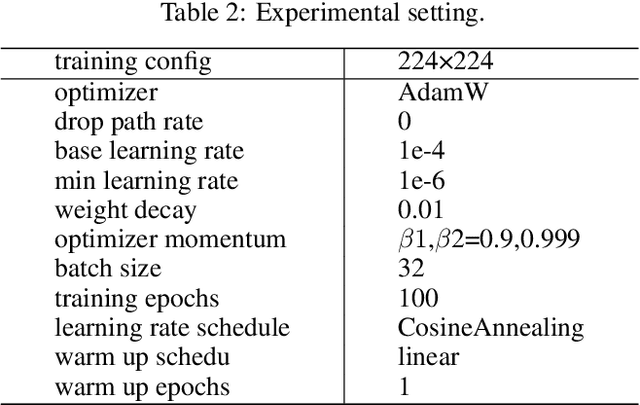
Medical image classification has developed rapidly under the impetus of the convolutional neural network (CNN). Due to the fixed size of the receptive field of the convolution kernel, it is difficult to capture the global features of medical images. Although the self-attention-based Transformer can model long-range dependencies, it has high computational complexity and lacks local inductive bias. Much research has demonstrated that global and local features are crucial for image classification. However, medical images have a lot of noisy, scattered features, intra-class variation, and inter-class similarities. This paper proposes a three-branch hierarchical multi-scale feature fusion network structure termed as HiFuse for medical image classification as a new method. It can fuse the advantages of Transformer and CNN from multi-scale hierarchies without destroying the respective modeling so as to improve the classification accuracy of various medical images. A parallel hierarchy of local and global feature blocks is designed to efficiently extract local features and global representations at various semantic scales, with the flexibility to model at different scales and linear computational complexity relevant to image size. Moreover, an adaptive hierarchical feature fusion block (HFF block) is designed to utilize the features obtained at different hierarchical levels comprehensively. The HFF block contains spatial attention, channel attention, residual inverted MLP, and shortcut to adaptively fuse semantic information between various scale features of each branch. The accuracy of our proposed model on the ISIC2018 dataset is 7.6% higher than baseline, 21.5% on the Covid-19 dataset, and 10.4% on the Kvasir dataset. Compared with other advanced models, the HiFuse model performs the best. Our code is open-source and available from https://github.com/huoxiangzuo/HiFuse.