 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Survey and Taxonomy on Point Cloud Registration Based on Deep Learning
Apr 22, 2024



Point cloud registration (PCR) involves determining a rigid transformation that aligns one point cloud to another. Despite the plethora of outstanding deep learning (DL)-based registration methods proposed, comprehensive and systematic studies on DL-based PCR techniques are still lacking. In this paper, we present a comprehensive survey and taxonomy of recently proposed PCR methods. Firstly, we conduct a taxonomy of commonly utilized datasets and evaluation metrics. Secondly, we classify the existing research into two main categories: supervised and unsupervised registration, providing insights into the core concepts of various influential PCR models. Finally, we highlight open challenges and potential directions for future research. A curated collection of valuable resources is made available at https://github.com/yxzhang15/PCR.
Delving into the Trajectory Long-tail Distribution for Muti-object Tracking
Mar 07, 2024



Multiple Object Tracking (MOT) is a critical area within computer vision, with a broad spectrum of practical implementations. Current research has primarily focused on the development of tracking algorithms and enhancement of post-processing techniques. Yet, there has been a lack of thorough examination concerning the nature of tracking data it self. In this study, we pioneer an exploration into the distribution patterns of tracking data and identify a pronounced long-tail distribution issue within existing MOT datasets. We note a significant imbalance in the distribution of trajectory lengths across different pedestrians, a phenomenon we refer to as "pedestrians trajectory long-tail distribution". Addressing this challenge, we introduce a bespoke strategy designed to mitigate the effects of this skewed distribution. Specifically, we propose two data augmentation strategies, including Stationary Camera View Data Augmentation (SVA) and Dynamic Camera View Data Augmentation (DVA) , designed for viewpoint states and the Group Softmax (GS) module for Re-ID. SVA is to backtrack and predict the pedestrian trajectory of tail classes, and DVA is to use diffusion model to change the background of the scene. GS divides the pedestrians into unrelated groups and performs softmax operation on each group individually. Our proposed strategies can be integrated into numerous existing tracking systems, and extensive experimentation validates the efficacy of our method in reducing the influence of long-tail distribution on multi-object tracking performance. The code is available at https://github.com/chen-si-jia/Trajectory-Long-tail-Distribution-for-MOT.
PSDF: Prior-Driven Neural Implicit Surface Learning for Multi-view Reconstruction
Jan 23, 2024



Surface reconstruction has traditionally relied on the Multi-View Stereo (MVS)-based pipeline, which often suffers from noisy and incomplete geometry. This is due to that although MVS has been proven to be an effective way to recover the geometry of the scenes, especially for locally detailed areas with rich textures, it struggles to deal with areas with low texture and large variations of illumination where the photometric consistency is unreliable. Recently, Neural Implicit Surface Reconstruction (NISR) combines surface rendering and volume rendering techniques and bypasses the MVS as an intermediate step, which has emerged as a promising alternative to overcome the limitations of traditional pipelines. While NISR has shown impressive results on simple scenes, it remains challenging to recover delicate geometry from uncontrolled real-world scenes which is caused by its underconstrained optimization. To this end, the framework PSDF is proposed which resorts to external geometric priors from a pretrained MVS network and internal geometric priors inherent in the NISR model to facilitate high-quality neural implicit surface learning. Specifically, the visibility-aware feature consistency loss and depth prior-assisted sampling based on external geometric priors are introduced. These proposals provide powerfully geometric consistency constraints and aid in locating surface intersection points, thereby significantly improving the accuracy and delicate reconstruction of NISR. Meanwhile, the internal prior-guided importance rendering is presented to enhance the fidelity of the reconstructed surface mesh by mitigating the biased rendering issue in NISR. Extensive experiments on the Tanks and Temples dataset show that PSDF achieves state-of-the-art performance on complex uncontrolled scenes.
PR-NeuS: A Prior-based Residual Learning Paradigm for Fast Multi-view Neural Surface Reconstruction
Dec 18, 2023



Neural surfaces learning has shown impressive performance in multi-view surface reconstruction. However, most existing methods use large multilayer perceptrons (MLPs) to train their models from scratch, resulting in hours of training for a single scene. Recently, how to accelerate the neural surfaces learning has received a lot of attention and remains an open problem. In this work, we propose a prior-based residual learning paradigm for fast multi-view neural surface reconstruction. This paradigm consists of two optimization stages. In the first stage, we propose to leverage generalization models to generate a basis signed distance function (SDF) field. This initial field can be quickly obtained by fusing multiple local SDF fields produced by generalization models. This provides a coarse global geometry prior. Based on this prior, in the second stage, a fast residual learning strategy based on hash-encoding networks is proposed to encode an offset SDF field for the basis SDF field. Moreover, we introduce a prior-guided sampling scheme to help the residual learning stage converge better, and thus recover finer structures. With our designed paradigm, experimental results show that our method only takes about 3 minutes to reconstruct the surface of a single scene, while achieving competitive surface quality. Our code will be released upon publication.
DiffusionPCR: Diffusion Models for Robust Multi-Step Point Cloud Registration
Dec 05, 2023



Point Cloud Registration (PCR) estimates the relative rigid transformation between two point clouds. We propose formulating PCR as a denoising diffusion probabilistic process, mapping noisy transformations to the ground truth. However, using diffusion models for PCR has nontrivial challenges, such as adapting a generative model to a discriminative task and leveraging the estimated nonlinear transformation from the previous step. Instead of training a diffusion model to directly map pure noise to ground truth, we map the predictions of an off-the-shelf PCR model to ground truth. The predictions of off-the-shelf models are often imperfect, especially in challenging cases where the two points clouds have low overlap, and thus could be seen as noisy versions of the real rigid transformation. In addition, we transform the rotation matrix into a spherical linear space for interpolation between samples in the forward process, and convert rigid transformations into auxiliary information to implicitly exploit last-step estimations in the reverse process. As a result, conditioned on time step, the denoising model adapts to the increasing accuracy across steps and refines registrations. Our extensive experiments showcase the effectiveness of our DiffusionPCR, yielding state-of-the-art registration recall rates (95.3%/81.6%) on 3DMatch and 3DLoMatch. The code will be made public upon publication.
Merlin:Empowering Multimodal LLMs with Foresight Minds
Nov 30, 2023Humans possess the remarkable ability to foresee the future to a certain extent based on present observations, a skill we term as foresight minds. However, this capability remains largely under explored within existing Multimodal Large Language Models (MLLMs), hindering their capacity to learn the fundamental principles of how things operate and the intentions behind the observed subjects. To address this issue, we introduce the integration of future modeling into the existing learning frameworks of MLLMs. By utilizing the subject trajectory, a highly structured representation of a consecutive frame sequence, as a learning objective, we aim to bridge the gap between the past and the future. We propose two innovative methods to empower MLLMs with foresight minds, Foresight Pre-Training (FPT) and Foresight Instruction-Tuning (FIT), which are inspired by the modern learning paradigm of LLMs. Specifically, FPT jointly training various tasks centered on trajectories, enabling MLLMs to learn how to attend and predict entire trajectories from a given initial observation. Then, FIT requires MLLMs to first predict trajectories of related objects and then reason about potential future events based on them. Aided by FPT and FIT, we build a novel and unified MLLM named Merlin that supports multi-images input and analysis about potential actions of multiple objects for the future reasoning. Experimental results show Merlin powerful foresight minds with impressive performance on both future reasoning and visual comprehension tasks.
Point-NeuS: Point-Guided Neural Implicit Surface Reconstruction by Volume Rendering
Oct 12, 2023



Recently, learning neural implicit surface by volume rendering has been a promising way for multi-view reconstruction. However, limited accuracy and excessive time complexity remain bottlenecks that current methods urgently need to overcome. To address these challenges, we propose a new method called Point-NeuS, utilizing point-guided mechanisms to achieve accurate and efficient reconstruction. Point modeling is organically embedded into the volume rendering to enhance and regularize the representation of implicit surface. Specifically, to achieve precise point guidance and noise robustness, aleatoric uncertainty of the point cloud is modeled to capture the distribution of noise and estimate the reliability of points. Additionally, a Neural Projection module connecting points and images is introduced to add geometric constraints to the Signed Distance Function (SDF). To better compensate for geometric bias between volume rendering and point modeling, high-fidelity points are filtered into an Implicit Displacement Network to improve the representation of SDF. Benefiting from our effective point guidance, lightweight networks are employed to achieve an impressive 11x speedup compared to NeuS. Extensive experiments show that our method yields high-quality surfaces, especially for fine-grained details and smooth regions. Moreover, it exhibits strong robustness to both noisy and sparse data.
MOTRv3: Release-Fetch Supervision for End-to-End Multi-Object Tracking
May 23, 2023



Although end-to-end multi-object trackers like MOTR enjoy the merits of simplicity, they suffer from the conflict between detection and association seriously, resulting in unsatisfactory convergence dynamics. While MOTRv2 partly addresses this problem, it demands an additional detection network for assistance. In this work, we serve as the first to reveal that this conflict arises from the unfair label assignment between detect queries and track queries during training, where these detect queries recognize targets and track queries associate them. Based on this observation, we propose MOTRv3, which balances the label assignment process using the developed release-fetch supervision strategy. In this strategy, labels are first released for detection and gradually fetched back for association. Besides, another two strategies named pseudo label distillation and track group denoising are designed to further improve the supervision for detection and association. Without the assistance of an extra detection network during inference, MOTRv3 achieves impressive performance across diverse benchmarks, e.g., MOT17, DanceTrack.
Generalizing Multiple Object Tracking to Unseen Domains by Introducing Natural Language Representation
Dec 03, 2022



Although existing multi-object tracking (MOT) algorithms have obtained competitive performance on various benchmarks, almost all of them train and validate models on the same domain. The domain generalization problem of MOT is hardly studied. To bridge this gap, we first draw the observation that the high-level information contained in natural language is domain invariant to different tracking domains. Based on this observation, we propose to introduce natural language representation into visual MOT models for boosting the domain generalization ability. However, it is infeasible to label every tracking target with a textual description. To tackle this problem, we design two modules, namely visual context prompting (VCP) and visual-language mixing (VLM). Specifically, VCP generates visual prompts based on the input frames. VLM joints the information in the generated visual prompts and the textual prompts from a pre-defined Trackbook to obtain instance-level pseudo textual description, which is domain invariant to different tracking scenes. Through training models on MOT17 and validating them on MOT20, we observe that the pseudo textual descriptions generated by our proposed modules improve the generalization performance of query-based trackers by large margins.
Quality Matters: Embracing Quality Clues for Robust 3D Multi-Object Tracking
Aug 23, 2022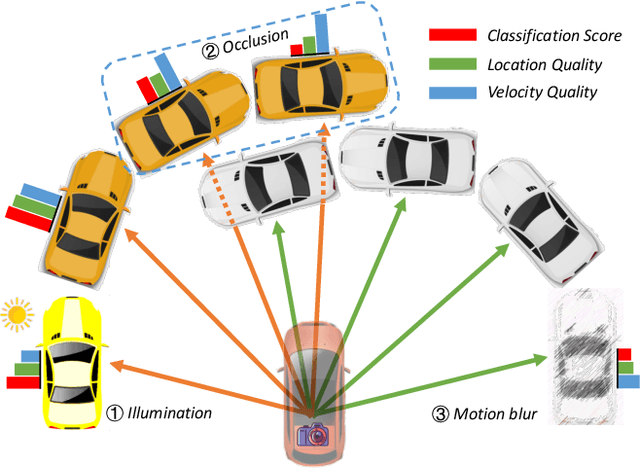
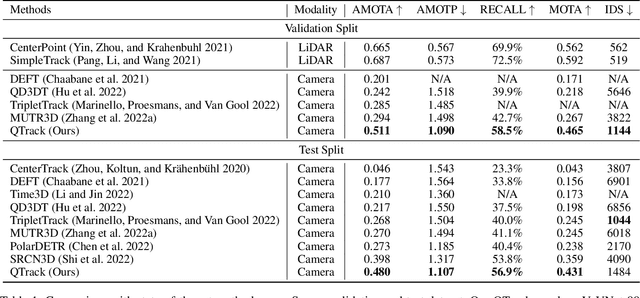
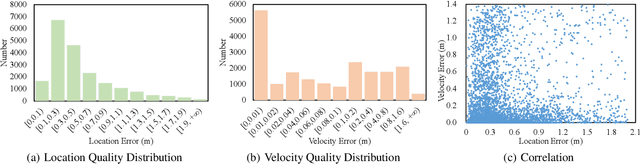

3D Multi-Object Tracking (MOT) has achieved tremendous achievement thanks to the rapid development of 3D object detection and 2D MOT. Recent advanced works generally employ a series of object attributes, e.g., position, size, velocity, and appearance, to provide the clues for the association in 3D MOT. However, these cues may not be reliable due to some visual noise, such as occlusion and blur, leading to tracking performance bottleneck. To reveal the dilemma, we conduct extensive empirical analysis to expose the key bottleneck of each clue and how they correlate with each other. The analysis results motivate us to efficiently absorb the merits among all cues, and adaptively produce an optimal tacking manner. Specifically, we present Location and Velocity Quality Learning, which efficiently guides the network to estimate the quality of predicted object attributes. Based on these quality estimations, we propose a quality-aware object association (QOA) strategy to leverage the quality score as an important reference factor for achieving robust association. Despite its simplicity, extensive experiments indicate that the proposed strategy significantly boosts tracking performance by 2.2% AMOTA and our method outperforms all existing state-of-the-art works on nuScenes by a large margin. Moreover, QTrack achieves 48.0% and 51.1% AMOTA tracking performance on the nuScenes validation and test sets, which significantly reduces the performance gap between pure camera and LiDAR based trackers.