 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeeping Minimal Experience to Achieve Efficient Interpretable Policy Distillation
Mar 02, 2022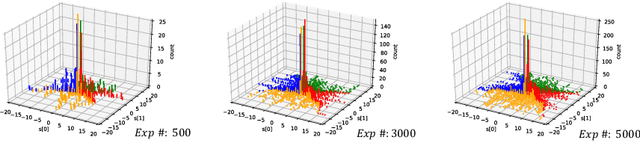

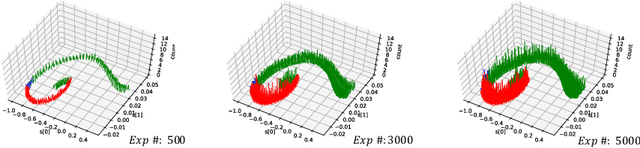
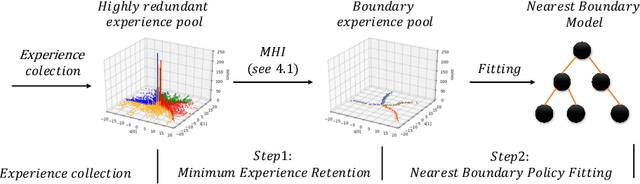
Although deep reinforcement learning has become a universal solution for complex control tasks, its real-world applicability is still limited because lacking security guarantees for policies. To address this problem, we propose Boundary Characterization via the Minimum Experience Retention (BCMER), an end-to-end Interpretable Policy Distillation (IPD) framework. Unlike previous IPD approaches, BCMER distinguishes the importance of experiences and keeps a minimal but critical experience pool with almost no loss of policy similarity. Specifically, the proposed BCMER contains two basic steps. Firstly, we propose a novel multidimensional hyperspheres intersection (MHI) approach to divide experience points into boundary points and internal points, and reserve the crucial boundary points. Secondly, we develop a nearest-neighbor-based model to generate robust and interpretable decision rules based on the boundary points. Extensive experiments show that the proposed BCMER is able to reduce the amount of experience to 1.4%~19.1% (when the count of the naive experiences is 10k) and maintain high IPD performance. In general, the proposed BCMER is more suitable for the experience storage limited regime because it discovers the critical experience and eliminates redundant experience.
Autonomous Aerial Delivery Vehicles, a Survey of Techniques on how Aerial Package Delivery is Achieved
Oct 06, 2021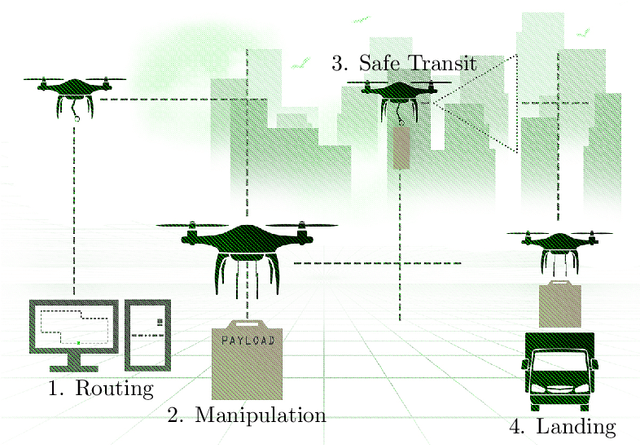


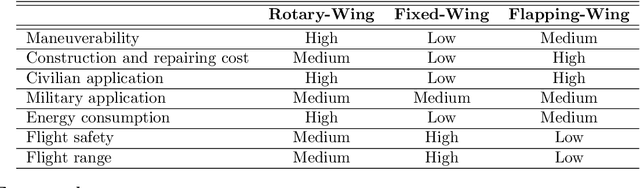
Autonomous aerial delivery vehicles have gained significant interest in the last decade. This has been enabled by technological advancements in aerial manipulators and novel grippers with enhanced force to weight ratios. Furthermore, improved control schemes and vehicle dynamics are better able to model the payload and improved perception algorithms to detect key features within the unmanned aerial vehicle's (UAV) environment. In this survey, a systematic review of the technological advancements and open research problems of autonomous aerial delivery vehicles is conducted. First, various types of manipulators and grippers are discussed in detail, along with dynamic modelling and control methods. Then, landing on static and dynamic platforms is discussed. Subsequently, risks such as weather conditions, state estimation and collision avoidance to ensure safe transit is considered. Finally, delivery UAV routing is investigated which categorises the topic into two areas: drone operations and drone-truck collaborative operations.
LibFewShot: A Comprehensive Library for Few-shot Learning
Sep 10, 2021
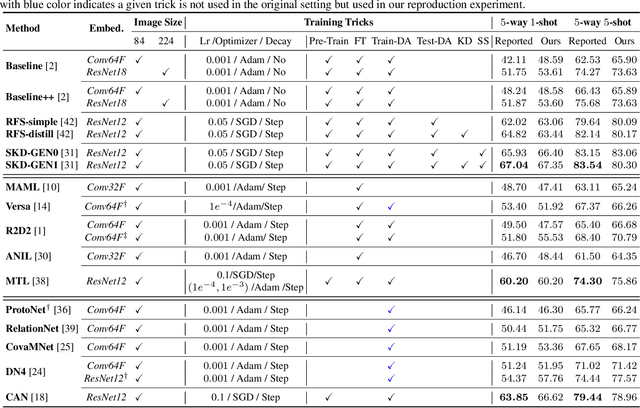
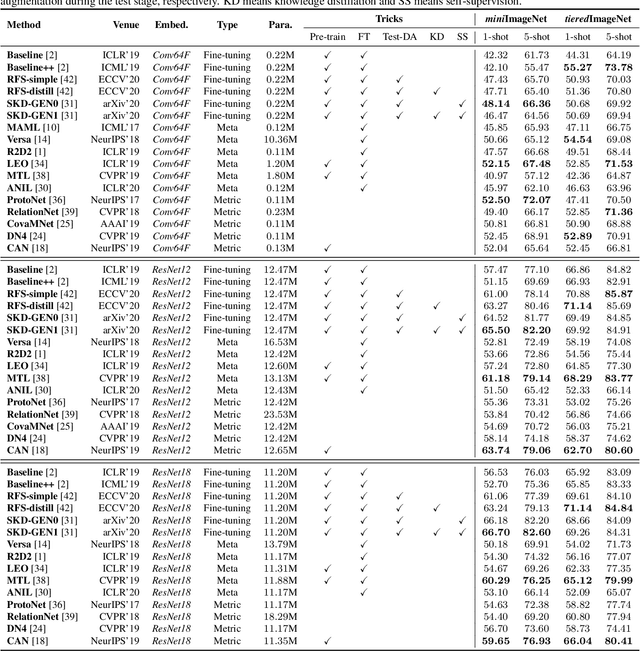
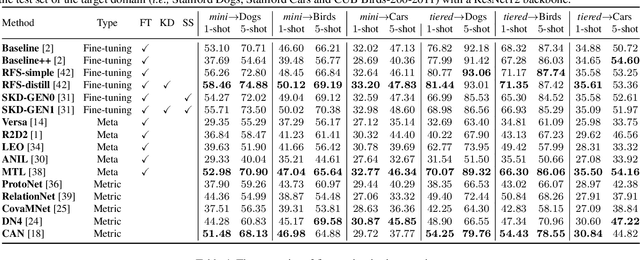
Few-shot learning, especially few-shot image classification, has received increasing attention and witnessed significant advances in recent years. Some recent studies implicitly show that many generic techniques or ``tricks'', such as data augmentation, pre-training, knowledge distillation, and self-supervision, may greatly boost the performance of a few-shot learning method. Moreover, different works may employ different software platforms, different training schedules, different backbone architectures and even different input image sizes, making fair comparisons difficult and practitioners struggle with reproducibility. To address these situations, we propose a comprehensive library for few-shot learning (LibFewShot) by re-implementing seventeen state-of-the-art few-shot learning methods in a unified framework with the same single codebase in PyTorch. Furthermore, based on LibFewShot, we provide comprehensive evaluations on multiple benchmark datasets with multiple backbone architectures to evaluate common pitfalls and effects of different training tricks. In addition, given the recent doubts on the necessity of meta- or episodic-training mechanism, our evaluation results show that such kind of mechanism is still necessary especially when combined with pre-training. We hope our work can not only lower the barriers for beginners to work on few-shot learning but also remove the effects of the nontrivial tricks to facilitate intrinsic research on few-shot learning. The source code is available from https://github.com/RL-VIG/LibFewShot.
Triplet is All You Need with Random Mappings for Unsupervised Visual Representation Learning
Jul 22, 2021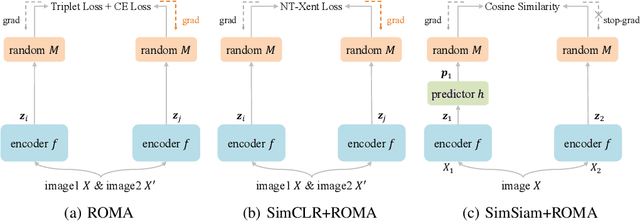
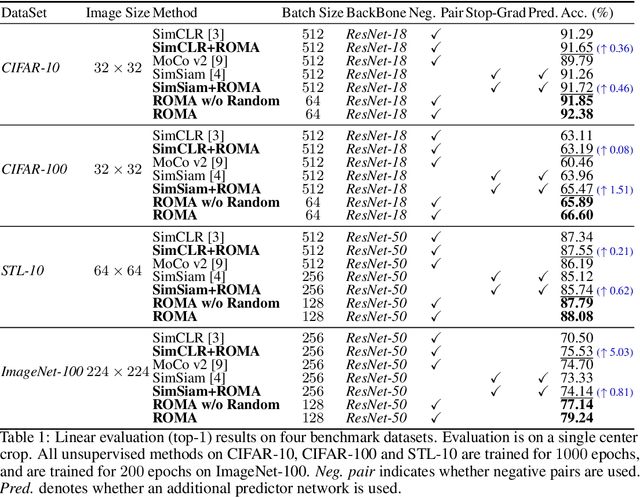
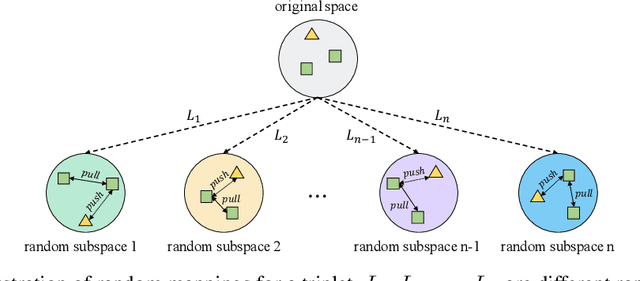

Contrastive self-supervised learning (SSL) has achieved great success in unsupervised visual representation learning by maximizing the similarity between two augmented views of the same image (positive pairs) and simultaneously contrasting other different images (negative pairs). However, this type of methods, such as SimCLR and MoCo, relies heavily on a large number of negative pairs and thus requires either large batches or memory banks. In contrast, some recent non-contrastive SSL methods, such as BYOL and SimSiam, attempt to discard negative pairs by introducing asymmetry and show remarkable performance. Unfortunately, to avoid collapsed solutions caused by not using negative pairs, these methods require sophisticated asymmetry designs. In this paper, we argue that negative pairs are still necessary but one is sufficient, i.e., triplet is all you need. A simple triplet-based loss can achieve surprisingly good performance without requiring large batches or asymmetry. Moreover, we observe that unsupervised visual representation learning can gain significantly from randomness. Based on this observation, we propose a simple plug-in RandOm MApping (ROMA) strategy by randomly mapping samples into other spaces and enforcing these randomly projected samples to satisfy the same correlation requirement. The proposed ROMA strategy not only achieves the state-of-the-art performance in conjunction with the triplet-based loss, but also can further effectively boost other SSL methods.
CariMe: Unpaired Caricature Generation with Multiple Exaggerations
Oct 01, 2020



Caricature generation aims to translate real photos into caricatures with artistic styles and shape exaggerations while maintaining the identity of the subject. Different from the generic image-to-image translation, drawing a caricature automatically is a more challenging task due to the existence of various spacial deformations. Previous caricature generation methods are obsessed with predicting definite image warping from a given photo while ignoring the intrinsic representation and distribution for exaggerations in caricatures. This limits their ability on diverse exaggeration generation. In this paper, we generalize the caricature generation problem from instance-level warping prediction to distribution-level deformation modeling. Based on this assumption, we present the first exploration for unpaired CARIcature generation with Multiple Exaggerations (CariMe). Technically, we propose a Multi-exaggeration Warper network to learn the distribution-level mapping from photo to facial exaggerations. This makes it possible to generate diverse and reasonable exaggerations from randomly sampled warp codes given one input photo. To better represent the facial exaggeration and produce fine-grained warping, a deformation-field-based warping method is also proposed, which helps us to capture more detailed exaggerations than other point-based warping methods. Experiments and two perceptual studies prove the superiority of our method comparing with other state-of-the-art methods, showing the improvement of our work on caricature generation.
Embedded Deep Bilinear Interactive Information and Selective Fusion for Multi-view Learning
Jul 13, 2020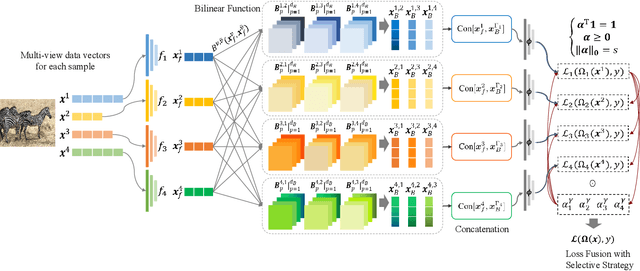
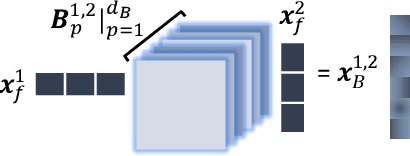
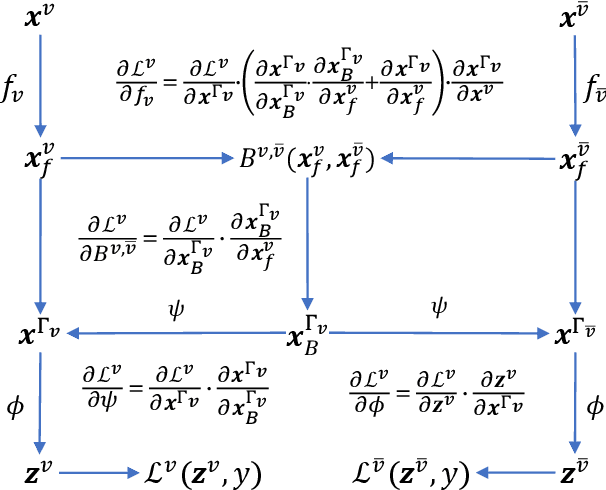
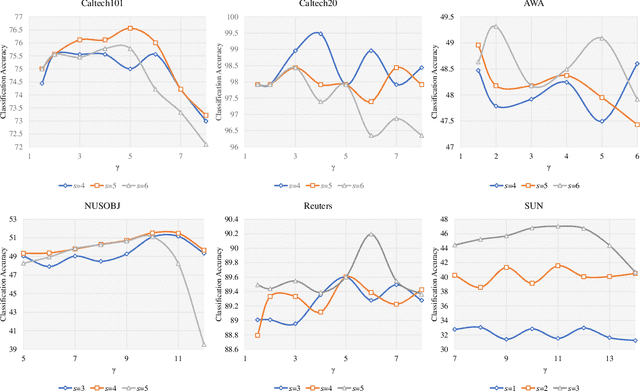
As a concrete application of multi-view learning, multi-view classification improves the traditional classification methods significantly by integrating various views optimally. Although most of the previous efforts have been demonstrated the superiority of multi-view learning, it can be further improved by comprehensively embedding more powerful cross-view interactive information and a more reliable multi-view fusion strategy in intensive studies. To fulfill this goal, we propose a novel multi-view learning framework to make the multi-view classification better aimed at the above-mentioned two aspects. That is, we seamlessly embed various intra-view information, cross-view multi-dimension bilinear interactive information, and a new view ensemble mechanism into a unified framework to make a decision via the optimization. In particular, we train different deep neural networks to learn various intra-view representations, and then dynamically learn multi-dimension bilinear interactive information from different bilinear similarities via the bilinear function between views. After that, we adaptively fuse the representations of multiple views by flexibly tuning the parameters of the view-weight, which not only avoids the trivial solution of weight but also provides a new way to select a few discriminative views that are beneficial to make a decision for the multi-view classification. Extensive experiments on six publicly available datasets demonstrate the effectiveness of the proposed method.
Manifold Alignment for Semantically Aligned Style Transfer
May 21, 2020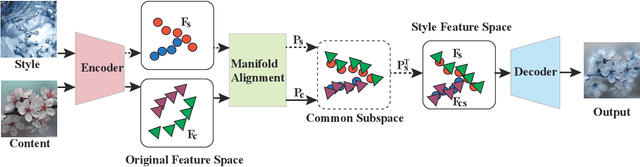
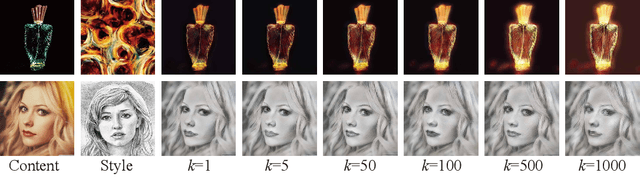
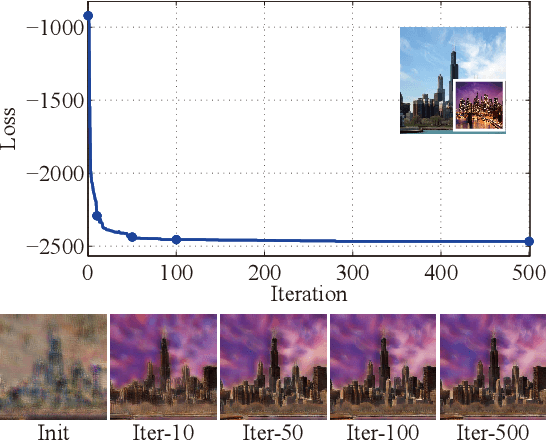

Given a content image and a style image, the goal of style transfer is to synthesize an output image by transferring the target style to the content image. Currently, most of the methods address the problem with global style transfer, assuming styles can be represented by global statistics, such as Gram matrices or covariance matrices. In this paper, we make a different assumption that local semantically aligned (or similar) regions between the content and style images should share similar style patterns. Based on this assumption, content features and style features are seen as two sets of manifolds and a manifold alignment based style transfer (MAST) method is proposed. MAST is a subspace learning method which learns a common subspace of the content and style features. In the common subspace, content and style features with larger feature similarity or the same semantic meaning are forced to be close. The learned projection matrices are added with orthogonality constraints so that the mapping can be bidirectional, which allows us to project the content features into the common subspace, and then into the original style space. By using a pre-trained decoder, promising stylized images are obtained. The method is further extended to allow users to specify corresponding semantic regions between content and style images or using semantic segmentation maps as guidance. Extensive experiments show the proposed MAST achieves appealing results in style transfer.
Alleviating the Incompatibility between Cross Entropy Loss and Episode Training for Few-shot Skin Disease Classification
Apr 21, 2020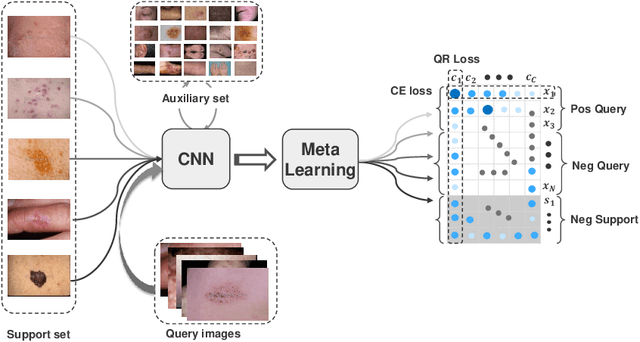
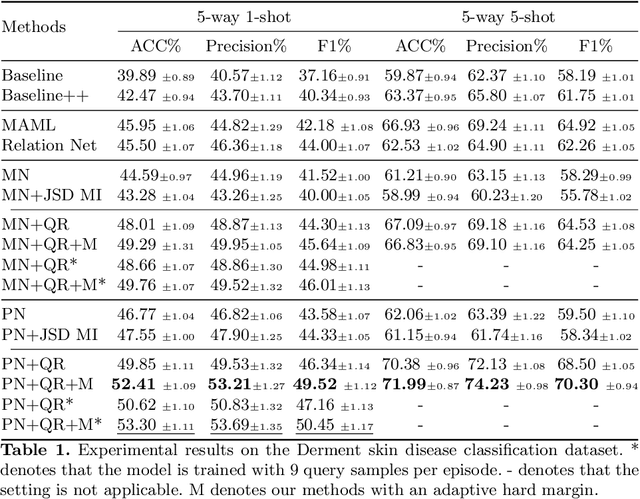

Skin disease classification from images is crucial to dermatological diagnosis. However, identifying skin lesions involves a variety of aspects in terms of size, color, shape, and texture. To make matters worse, many categories only contain very few samples, posing great challenges to conventional machine learning algorithms and even human experts. Inspired by the recent success of Few-Shot Learning (FSL) in natural image classification, we propose to apply FSL to skin disease identification to address the extreme scarcity of training sample problem. However, directly applying FSL to this task does not work well in practice, and we find that the problem can be largely attributed to the incompatibility between Cross Entropy (CE) and episode training, which are both commonly used in FSL. Based on a detailed analysis, we propose the Query-Relative (QR) loss, which proves superior to CE under episode training and is closely related to recently proposed mutual information estimation. Moreover, we further strengthen the proposed QR loss with a novel adaptive hard margin strategy. Comprehensive experiments validate the effectiveness of the proposed FSL scheme and the possibility to diagnosis rare skin disease with a few labeled samples.
RGBD-Dog: Predicting Canine Pose from RGBD Sensors
Apr 16, 2020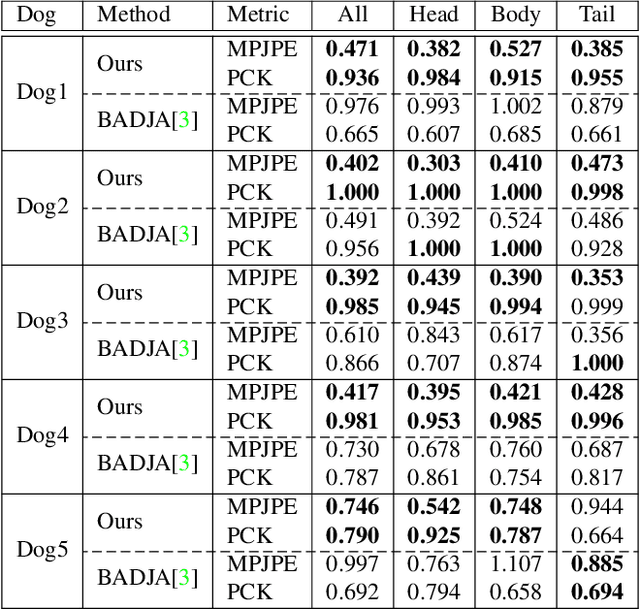
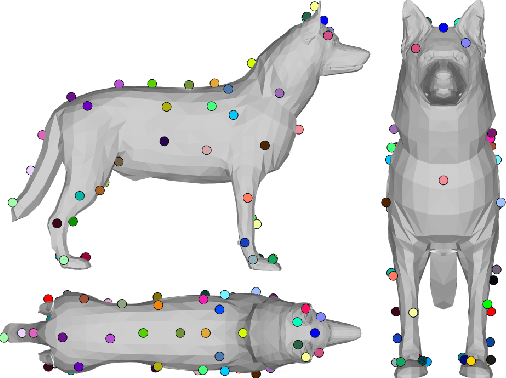
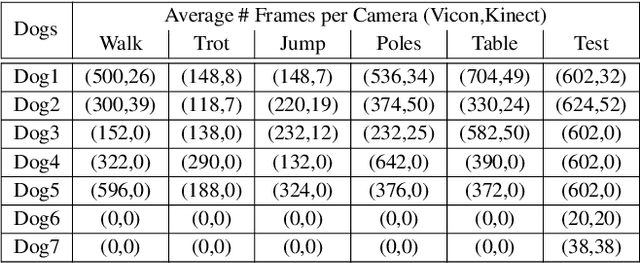
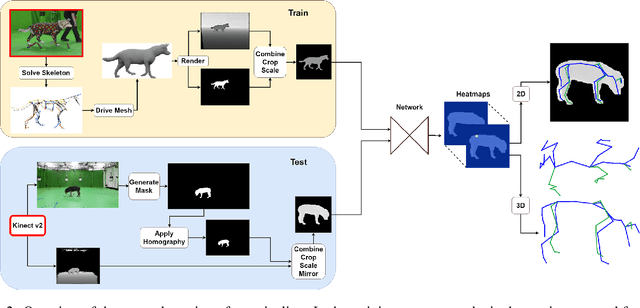
The automatic extraction of animal \reb{3D} pose from images without markers is of interest in a range of scientific fields. Most work to date predicts animal pose from RGB images, based on 2D labelling of joint positions. However, due to the difficult nature of obtaining training data, no ground truth dataset of 3D animal motion is available to quantitatively evaluate these approaches. In addition, a lack of 3D animal pose data also makes it difficult to train 3D pose-prediction methods in a similar manner to the popular field of body-pose prediction. In our work, we focus on the problem of 3D canine pose estimation from RGBD images, recording a diverse range of dog breeds with several Microsoft Kinect v2s, simultaneously obtaining the 3D ground truth skeleton via a motion capture system. We generate a dataset of synthetic RGBD images from this data. A stacked hourglass network is trained to predict 3D joint locations, which is then constrained using prior models of shape and pose. We evaluate our model on both synthetic and real RGBD images and compare our results to previously published work fitting canine models to images. Finally, despite our training set consisting only of dog data, visual inspection implies that our network can produce good predictions for images of other quadrupeds -- e.g. horses or cats -- when their pose is similar to that contained in our training set.
Unsupervised Few-shot Learning via Distribution Shift-based Augmentation
Apr 13, 2020
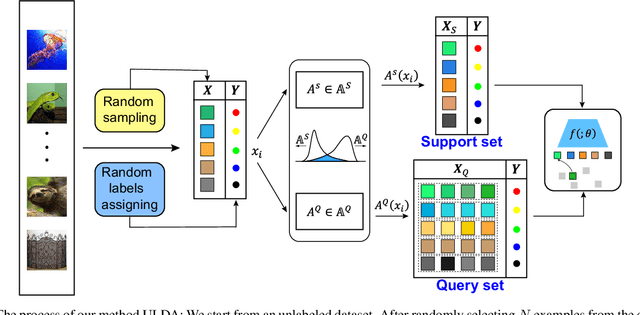

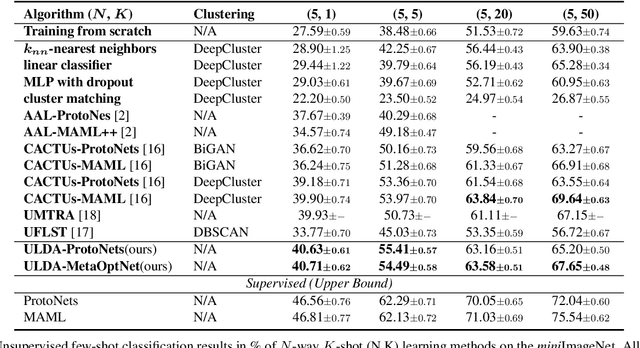
Few-shot learning aims to learn a new concept when only a few training examples are available, which has been extensively explored in recent years. However, most of the current works heavily rely on a large-scale labeled auxiliary set to train their models in an episodic-training paradigm. Such a kind of supervised setting basically limits the widespread use of few-shot learning algorithms, especially in real-world applications. Instead, in this paper, we develop a novel framework called \emph{Unsupervised Few-shot Learning via Distribution Shift-based Data Augmentation} (ULDA), which pays attention to the distribution diversity inside each constructed pretext few-shot task when using data augmentation. Importantly, we highlight the value and importance of the distribution diversity in the augmentation-based pretext few-shot tasks. In ULDA, we systemically investigate the effects of different augmentation techniques and propose to strengthen the distribution diversity (or difference) between the query set and support set in each few-shot task, by augmenting these two sets separately (i.e. shifting). In this way, even incorporated with simple augmentation techniques (e.g. random crop, color jittering, or rotation), our ULDA can produce a significant improvement. In the experiments, few-shot models learned by ULDA can achieve superior generalization performance and obtain state-of-the-art results in a variety of established few-shot learning tasks on \emph{mini}ImageNet and \emph{tiered}ImageNet. %The code will be released soon. The source code is available in \textcolor{blue}{\emph{https://github.com/WonderSeven/ULDA}}.