 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Schema-Guided Reason-while-Retrieve framework for Reasoning on Scene Graphs with Large-Language-Models (LLMs)
Feb 05, 2025



Scene graphs have emerged as a structured and serializable environment representation for grounded spatial reasoning with Large Language Models (LLMs). In this work, we propose SG-RwR, a Schema-Guided Retrieve-while-Reason framework for reasoning and planning with scene graphs. Our approach employs two cooperative, code-writing LLM agents: a (1) Reasoner for task planning and information queries generation, and a (2) Retriever for extracting corresponding graph information following the queries. Two agents collaborate iteratively, enabling sequential reasoning and adaptive attention to graph information. Unlike prior works, both agents are prompted only with the scene graph schema rather than the full graph data, which reduces the hallucination by limiting input tokens, and drives the Reasoner to generate reasoning trace abstractly.Following the trace, the Retriever programmatically query the scene graph data based on the schema understanding, allowing dynamic and global attention on the graph that enhances alignment between reasoning and retrieval. Through experiments in multiple simulation environments, we show that our framework surpasses existing LLM-based approaches in numerical Q\&A and planning tasks, and can benefit from task-level few-shot examples, even in the absence of agent-level demonstrations. Project code will be released.
GASP: Gaussian Avatars with Synthetic Priors
Dec 10, 2024



Gaussian Splatting has changed the game for real-time photo-realistic rendering. One of the most popular applications of Gaussian Splatting is to create animatable avatars, known as Gaussian Avatars. Recent works have pushed the boundaries of quality and rendering efficiency but suffer from two main limitations. Either they require expensive multi-camera rigs to produce avatars with free-view rendering, or they can be trained with a single camera but only rendered at high quality from this fixed viewpoint. An ideal model would be trained using a short monocular video or image from available hardware, such as a webcam, and rendered from any view. To this end, we propose GASP: Gaussian Avatars with Synthetic Priors. To overcome the limitations of existing datasets, we exploit the pixel-perfect nature of synthetic data to train a Gaussian Avatar prior. By fitting this prior model to a single photo or video and fine-tuning it, we get a high-quality Gaussian Avatar, which supports 360$^\circ$ rendering. Our prior is only required for fitting, not inference, enabling real-time application. Through our method, we obtain high-quality, animatable Avatars from limited data which can be animated and rendered at 70fps on commercial hardware. See our project page (https://microsoft.github.io/GASP/) for results.
TalkLoRA: Low-Rank Adaptation for Speech-Driven Animation
Aug 25, 2024Speech-driven facial animation is important for many applications including TV, film, video games, telecommunication and AR/VR. Recently, transformers have been shown to be extremely effective for this task. However, we identify two issues with the existing transformer-based models. Firstly, they are difficult to adapt to new personalised speaking styles and secondly, they are slow to run for long sentences due to the quadratic complexity of the transformer. We propose TalkLoRA to address both of these issues. TalkLoRA uses Low-Rank Adaptation to effectively and efficiently adapt to new speaking styles, even with limited data. It does this by training an adaptor with a small number of parameters for each subject. We also utilise a chunking strategy to reduce the complexity of the underlying transformer, allowing for long sentences at inference time. TalkLoRA can be applied to any transformer-based speech-driven animation method. We perform extensive experiments to show that TalkLoRA archives state-of-the-art style adaptation and that it allows for an order-of-complexity reduction in inference times without sacrificing quality. We also investigate and provide insights into the hyperparameter selection for LoRA fine-tuning of speech-driven facial animation models.
Identifying Optimal Launch Sites of High-Altitude Latex-Balloons using Bayesian Optimisation for the Task of Station-Keeping
Mar 16, 2024



Station-keeping tasks for high-altitude balloons show promise in areas such as ecological surveys, atmospheric analysis, and communication relays. However, identifying the optimal time and position to launch a latex high-altitude balloon is still a challenging and multifaceted problem. For example, tasks such as forest fire tracking place geometric constraints on the launch location of the balloon. Furthermore, identifying the most optimal location also heavily depends on atmospheric conditions. We first illustrate how reinforcement learning-based controllers, frequently used for station-keeping tasks, can exploit the environment. This exploitation can degrade performance on unseen weather patterns and affect station-keeping performance when identifying an optimal launch configuration. Valuing all states equally in the region, the agent exploits the region's geometry by flying near the edge, leading to risky behaviours. We propose a modification which compensates for this exploitation and finds this leads to, on average, higher steps within the target region on unseen data. Then, we illustrate how Bayesian Optimisation (BO) can identify the optimal launch location to perform station-keeping tasks, maximising the expected undiscounted return from a given rollout. We show BO can find this launch location in fewer steps compared to other optimisation methods. Results indicate that, surprisingly, the most optimal location to launch from is not commonly within the target region. Please find further information about our project at https://sites.google.com/view/bo-lauch-balloon/.
Dubbing for Everyone: Data-Efficient Visual Dubbing using Neural Rendering Priors
Jan 11, 2024



Visual dubbing is the process of generating lip motions of an actor in a video to synchronise with given audio. Recent advances have made progress towards this goal but have not been able to produce an approach suitable for mass adoption. Existing methods are split into either person-generic or person-specific models. Person-specific models produce results almost indistinguishable from reality but rely on long training times using large single-person datasets. Person-generic works have allowed for the visual dubbing of any video to any audio without further training, but these fail to capture the person-specific nuances and often suffer from visual artefacts. Our method, based on data-efficient neural rendering priors, overcomes the limitations of existing approaches. Our pipeline consists of learning a deferred neural rendering prior network and actor-specific adaptation using neural textures. This method allows for $\textbf{high-quality visual dubbing with just a few seconds of data}$, that enables video dubbing for any actor - from A-list celebrities to background actors. We show that we achieve state-of-the-art in terms of $\textbf{visual quality}$ and $\textbf{recognisability}$ both quantitatively, and qualitatively through two user studies. Our prior learning and adaptation method $\textbf{generalises to limited data}$ better and is more $\textbf{scalable}$ than existing person-specific models. Our experiments on real-world, limited data scenarios find that our model is preferred over all others. The project page may be found at https://dubbingforeveryone.github.io/
FACTS: Facial Animation Creation using the Transfer of Styles
Jul 18, 2023



The ability to accurately capture and express emotions is a critical aspect of creating believable characters in video games and other forms of entertainment. Traditionally, this animation has been achieved with artistic effort or performance capture, both requiring costs in time and labor. More recently, audio-driven models have seen success, however, these often lack expressiveness in areas not correlated to the audio signal. In this paper, we present a novel approach to facial animation by taking existing animations and allowing for the modification of style characteristics. Specifically, we explore the use of a StarGAN to enable the conversion of 3D facial animations into different emotions and person-specific styles. We are able to maintain the lip-sync of the animations with this method thanks to the use of a novel viseme-preserving loss.
Resource-Constrained Station-Keeping for Helium Balloons using Reinforcement Learning
Mar 02, 2023High altitude balloons have proved useful for ecological aerial surveys, atmospheric monitoring, and communication relays. However, due to weight and power constraints, there is a need to investigate alternate modes of propulsion to navigate in the stratosphere. Very recently, reinforcement learning has been proposed as a control scheme to maintain the balloon in the region of a fixed location, facilitated through diverse opposing wind-fields at different altitudes. Although air-pump based station keeping has been explored, there is no research on the control problem for venting and ballasting actuated balloons, which is commonly used as a low-cost alternative. We show how reinforcement learning can be used for this type of balloon. Specifically, we use the soft actor-critic algorithm, which on average is able to station-keep within 50\;km for 25\% of the flight, consistent with state-of-the-art. Furthermore, we show that the proposed controller effectively minimises the consumption of resources, thereby supporting long duration flights. We frame the controller as a continuous control reinforcement learning problem, which allows for a more diverse range of trajectories, as opposed to current state-of-the-art work, which uses discrete action spaces. Furthermore, through continuous control, we can make use of larger ascent rates which are not possible using air-pumps. The desired ascent-rate is decoupled into desired altitude and time-factor to provide a more transparent policy, compared to low-level control commands used in previous works. Finally, by applying the equations of motion, we establish appropriate thresholds for venting and ballasting to prevent the agent from exploiting the environment. More specifically, we ensure actions are physically feasible by enforcing constraints on venting and ballasting.
READ Avatars: Realistic Emotion-controllable Audio Driven Avatars
Mar 01, 2023We present READ Avatars, a 3D-based approach for generating 2D avatars that are driven by audio input with direct and granular control over the emotion. Previous methods are unable to achieve realistic animation due to the many-to-many nature of audio to expression mappings. We alleviate this issue by introducing an adversarial loss in the audio-to-expression generation process. This removes the smoothing effect of regression-based models and helps to improve the realism and expressiveness of the generated avatars. We note furthermore, that audio should be directly utilized when generating mouth interiors and that other 3D-based methods do not attempt this. We address this with audio-conditioned neural textures, which are resolution-independent. To evaluate the performance of our method, we perform quantitative and qualitative experiments, including a user study. We also propose a new metric for comparing how well an actor's emotion is reconstructed in the generated avatar. Our results show that our approach outperforms state of the art audio-driven avatar generation methods across several metrics. A demo video can be found at \url{https://youtu.be/QSyMl3vV0pA}
Parallel Reinforcement Learning Simulation for Visual Quadrotor Navigation
Sep 22, 2022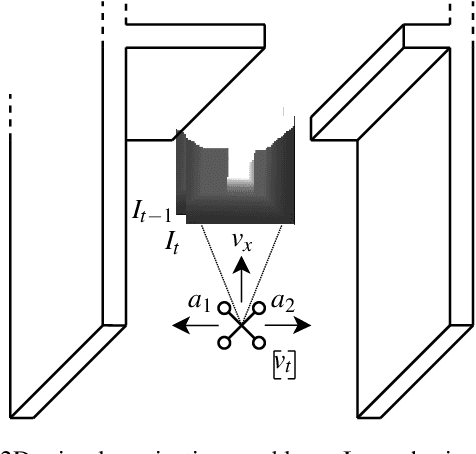
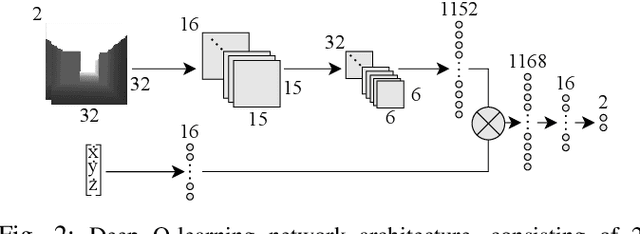

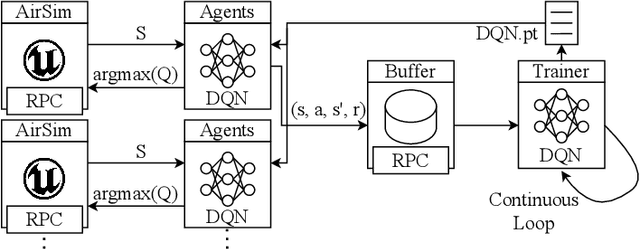
Reinforcement learning (RL) is an agent-based approach for teaching robots to navigate within the physical world. Gathering data for RL is known to be a laborious task, and real-world experiments can be risky. Simulators facilitate the collection of training data in a quicker and more cost-effective manner. However, RL frequently requires a significant number of simulation steps for an agent to become skilful at simple tasks. This is a prevalent issue within the field of RL-based visual quadrotor navigation where state dimensions are typically very large and dynamic models are complex. Furthermore, rendering images and obtaining physical properties of the agent can be computationally expensive. To solve this, we present a simulation framework, built on AirSim, which provides efficient parallel training. Building on this framework, Ape-X is modified to incorporate decentralised training of AirSim environments to make use of numerous networked computers. Through experiments we were able to achieve a reduction in training time from 3.9 hours to 11 minutes using the aforementioned framework and a total of 74 agents and two networked computers. Further details including a github repo and videos about our project, PRL4AirSim, can be found at https://sites.google.com/view/prl4airsim/home
Autonomous Aerial Delivery Vehicles, a Survey of Techniques on how Aerial Package Delivery is Achieved
Oct 06, 2021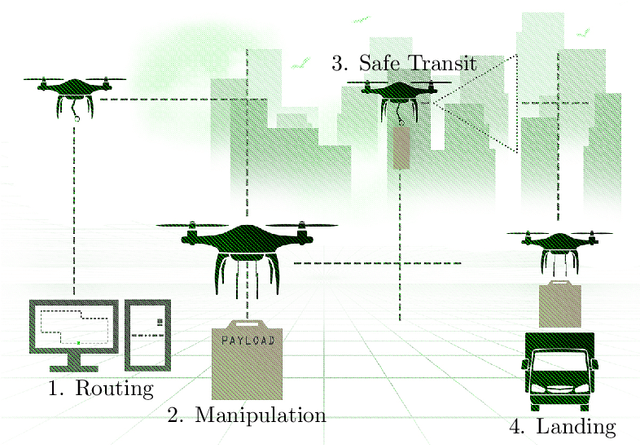


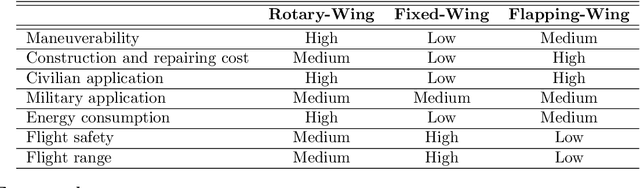
Autonomous aerial delivery vehicles have gained significant interest in the last decade. This has been enabled by technological advancements in aerial manipulators and novel grippers with enhanced force to weight ratios. Furthermore, improved control schemes and vehicle dynamics are better able to model the payload and improved perception algorithms to detect key features within the unmanned aerial vehicle's (UAV) environment. In this survey, a systematic review of the technological advancements and open research problems of autonomous aerial delivery vehicles is conducted. First, various types of manipulators and grippers are discussed in detail, along with dynamic modelling and control methods. Then, landing on static and dynamic platforms is discussed. Subsequently, risks such as weather conditions, state estimation and collision avoidance to ensure safe transit is considered. Finally, delivery UAV routing is investigated which categorises the topic into two areas: drone operations and drone-truck collaborative operations.