 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal-Local Temporal Representations For Video Person Re-Identification
Aug 27, 2019

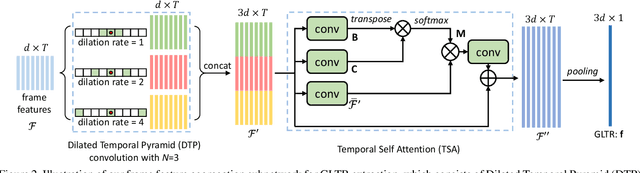
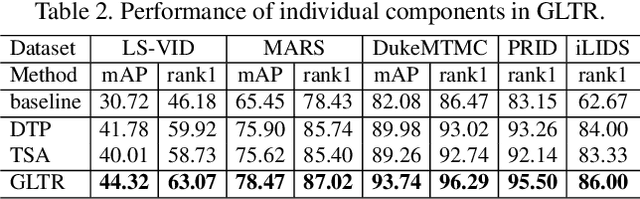
This paper proposes the Global-Local Temporal Representation (GLTR) to exploit the multi-scale temporal cues in video sequences for video person Re-Identification (ReID). GLTR is constructed by first modeling the short-term temporal cues among adjacent frames, then capturing the long-term relations among inconsecutive frames. Specifically, the short-term temporal cues are modeled by parallel dilated convolutions with different temporal dilation rates to represent the motion and appearance of pedestrian. The long-term relations are captured by a temporal self-attention model to alleviate the occlusions and noises in video sequences. The short and long-term temporal cues are aggregated as the final GLTR by a simple single-stream CNN. GLTR shows substantial superiority to existing features learned with body part cues or metric learning on four widely-used video ReID datasets. For instance, it achieves Rank-1 Accuracy of 87.02% on MARS dataset without re-ranking, better than current state-of-the art.
Towards Digital Retina in Smart Cities: A Model Generation, Utilization and Communication Paradigm
Jul 31, 2019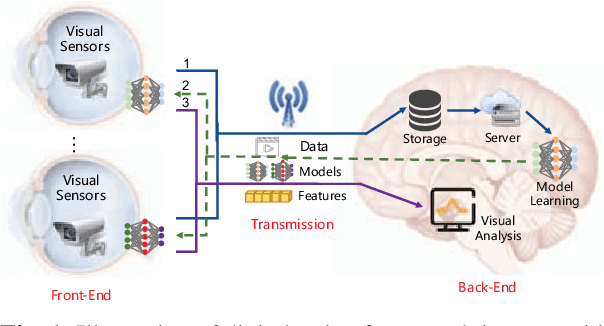
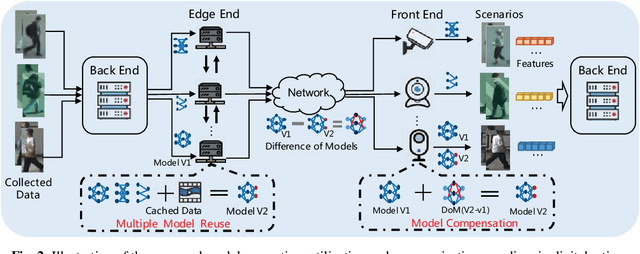
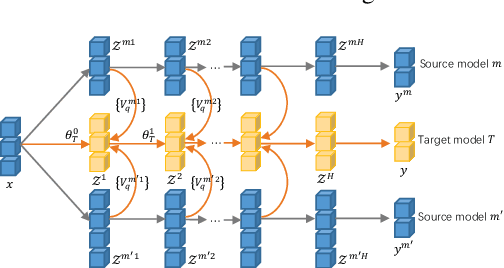
The digital retina in smart cities is to select what the City Eye tells the City Brain, and convert the acquired visual data from front-end visual sensors to features in an intelligent sensing manner. By deploying deep learning and/or handcrafted models in front-end devices, the compact features can be extracted and subsequently delivered to back-end cloud for search and advanced analytics. In this context, we propose a model generation, utilization, and communication paradigm, aiming to address a set of unique challenges for better artificial intelligence services in smart cities. In particular, we present an integrated multiple deep learning models reuse and prediction strategy, which greatly increases the feasibility of the digital retina in processing and analyzing the large-scale visual data in smart cities. The promise of the proposed paradigm is demonstrated through a set of experiments.
FedHealth: A Federated Transfer Learning Framework for Wearable Healthcare
Jul 22, 2019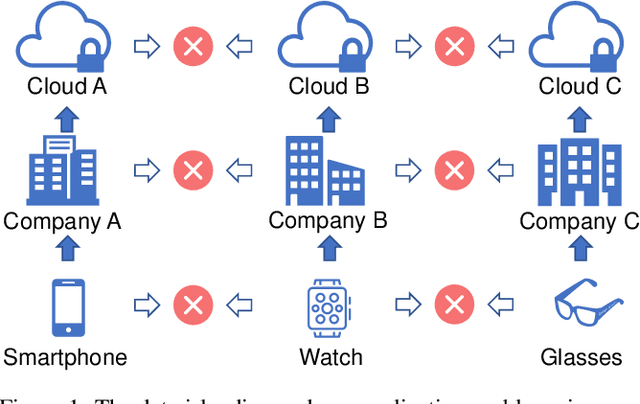

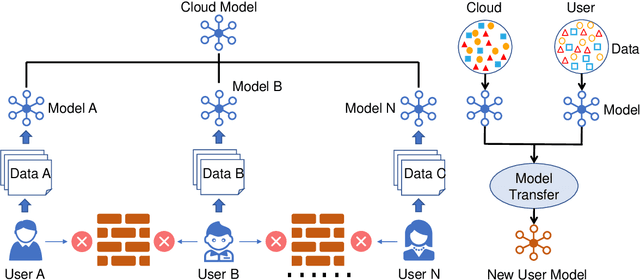
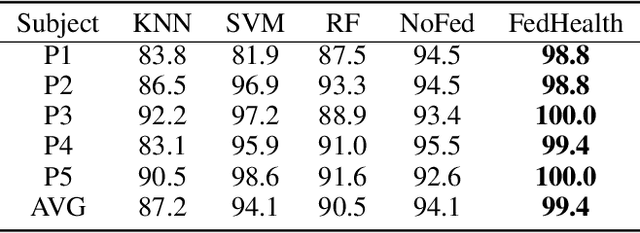
With the rapid development of computing technology, wearable devices such as smart phones and wristbands make it easy to get access to people's health information including activities, sleep, sports, etc. Smart healthcare achieves great success by training machine learning models on a large quantity of user data. However, there are two critical challenges. Firstly, user data often exists in the form of isolated islands, making it difficult to perform aggregation without compromising privacy security. Secondly, the models trained on the cloud fail on personalization. In this paper, we propose FedHealth, the first federated transfer learning framework for wearable healthcare to tackle these challenges. FedHealth performs data aggregation through federated learning, and then builds personalized models by transfer learning. It is able to achieve accurate and personalized healthcare without compromising privacy and security. Experiments demonstrate that FedHealth produces higher accuracy (5.3% improvement) for wearable activity recognition when compared to traditional methods. FedHealth is general and extensible and has the potential to be used in many healthcare applications.
Single Image Blind Deblurring Using Multi-Scale Latent Structure Prior
Jun 11, 2019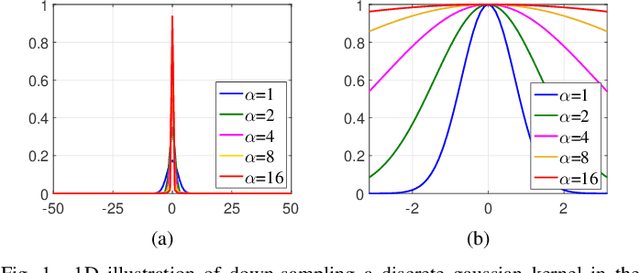
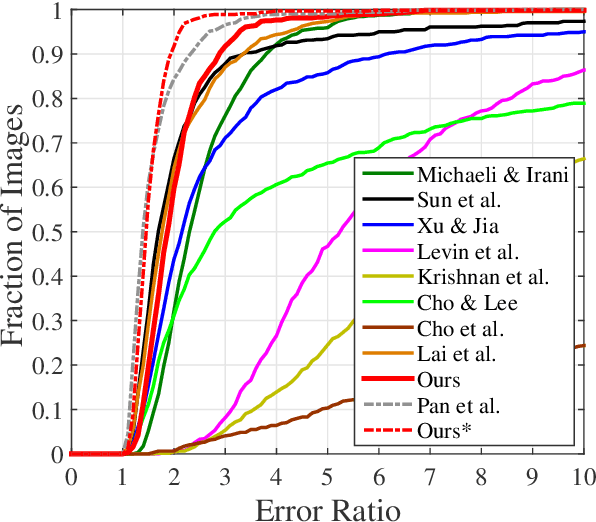


Blind image deblurring is a challenging problem in computer vision, which aims to restore both the blur kernel and the latent sharp image from only a blurry observation. Inspired by the prevalent self-example prior in image super-resolution, in this paper, we observe that a coarse enough image down-sampled from a blurry observation is approximately a low-resolution version of the latent sharp image. We prove this phenomenon theoretically and define the coarse enough image as a latent structure prior of the unknown sharp image. Starting from this prior, we propose to restore sharp images from the coarsest scale to the finest scale on a blurry image pyramid, and progressively update the prior image using the newly restored sharp image. These coarse-to-fine priors are referred to as \textit{Multi-Scale Latent Structures} (MSLS). Leveraging the MSLS prior, our algorithm comprises two phases: 1) we first preliminarily restore sharp images in the coarse scales; 2) we then apply a refinement process in the finest scale to obtain the final deblurred image. In each scale, to achieve lower computational complexity, we alternately perform a sharp image reconstruction with fast local self-example matching, an accelerated kernel estimation with error compensation, and a fast non-blind image deblurring, instead of computing any computationally expensive non-convex priors. We further extend the proposed algorithm to solve more challenging non-uniform blind image deblurring problem. Extensive experiments demonstrate that our algorithm achieves competitive results against the state-of-the-art methods with much faster running speed.
Masked Non-Autoregressive Image Captioning
Jun 03, 2019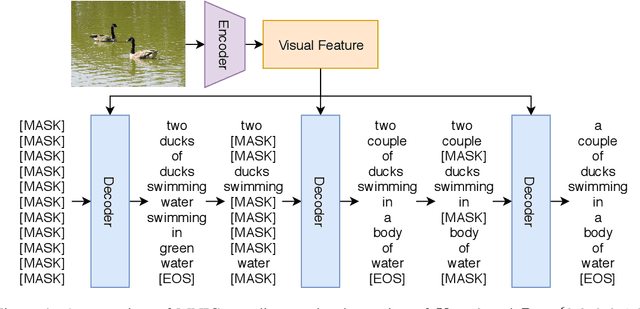
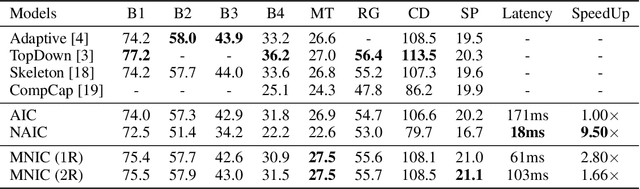
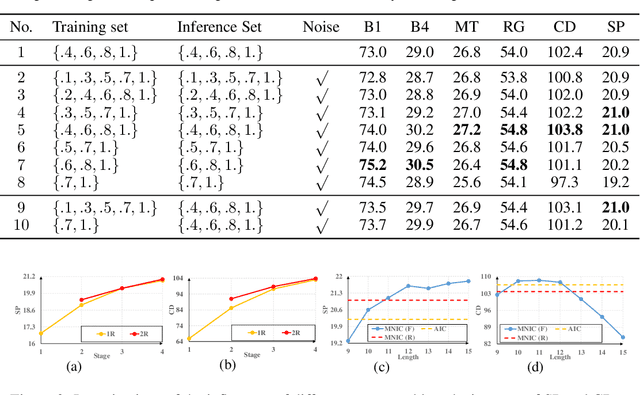
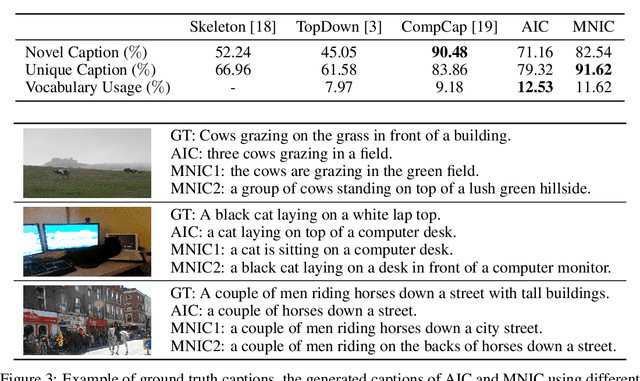
Existing captioning models often adopt the encoder-decoder architecture, where the decoder uses autoregressive decoding to generate captions, such that each token is generated sequentially given the preceding generated tokens. However, autoregressive decoding results in issues such as sequential error accumulation, slow generation, improper semantics and lack of diversity. Non-autoregressive decoding has been proposed to tackle slow generation for neural machine translation but suffers from multimodality problem due to the indirect modeling of the target distribution. In this paper, we propose masked non-autoregressive decoding to tackle the issues of both autoregressive decoding and non-autoregressive decoding. In masked non-autoregressive decoding, we mask several kinds of ratios of the input sequences during training, and generate captions parallelly in several stages from a totally masked sequence to a totally non-masked sequence in a compositional manner during inference. Experimentally our proposed model can preserve semantic content more effectively and can generate more diverse captions.
Self-critical n-step Training for Image Captioning
Apr 15, 2019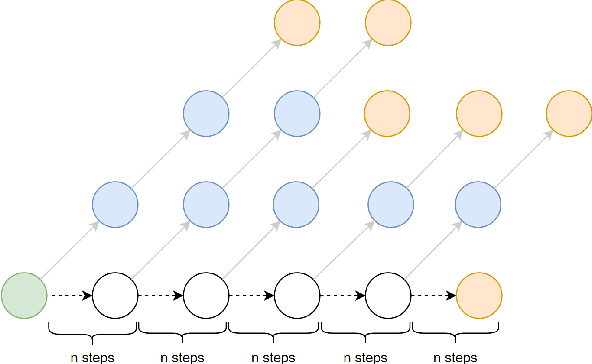
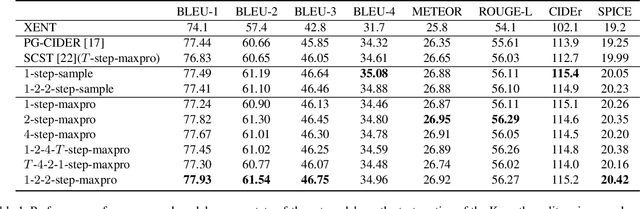
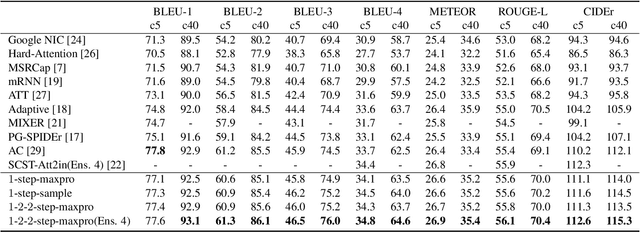

Existing methods for image captioning are usually trained by cross entropy loss, which leads to exposure bias and the inconsistency between the optimizing function and evaluation metrics. Recently it has been shown that these two issues can be addressed by incorporating techniques from reinforcement learning, where one of the popular techniques is the advantage actor-critic algorithm that calculates per-token advantage by estimating state value with a parametrized estimator at the cost of introducing estimation bias. In this paper, we estimate state value without using a parametrized value estimator. With the properties of image captioning, namely, the deterministic state transition function and the sparse reward, state value is equivalent to its preceding state-action value, and we reformulate advantage function by simply replacing the former with the latter. Moreover, the reformulated advantage is extended to n-step, which can generally increase the absolute value of the mean of reformulated advantage while lowering variance. Then two kinds of rollout are adopted to estimate state-action value, which we call self-critical n-step training. Empirically we find that our method can obtain better performance compared to the state-of-the-art methods that use the sequence level advantage and parametrized estimator respectively on the widely used MSCOCO benchmark.
Scalable Facial Image Compression with Deep Feature Reconstruction
Mar 14, 2019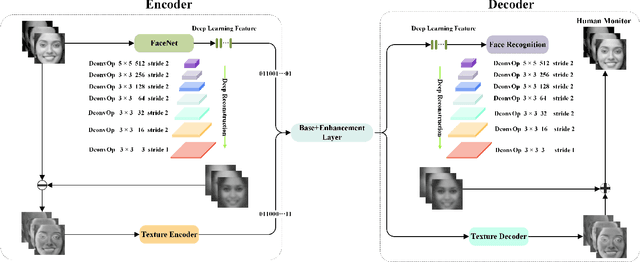
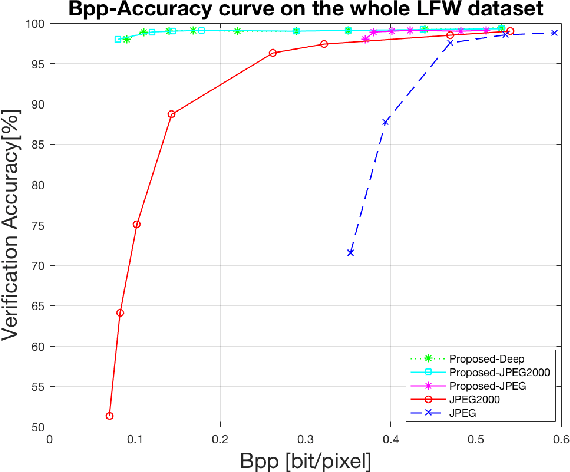


In this paper, we propose a scalable image compression scheme, including the base layer for feature representation and enhancement layer for texture representation. More specifically, the base layer is designed as the deep learning feature for analysis purpose, and it can also be converted to the fine structure with deep feature reconstruction. The enhancement layer, which serves to compress the residuals between the input image and the signals generated from the base layer, aims to faithfully reconstruct the input texture. The proposed scheme can feasibly inherit the advantages of both compress-then-analyze and analyze-then-compress schemes in surveillance applications. The performance of this framework is validated with facial images, and the conducted experiments provide useful evidences to show that the proposed framework can achieve better rate-accuracy and rate-distortion performance over conventional image compression schemes.
LVreID: Person Re-Identification with Long Sequence Videos
Oct 29, 2018

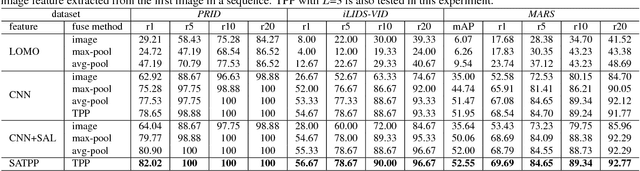
This paper mainly establishes a large-scale Long sequence Video database for person re-IDentification (LVreID). Different from existing datasets, LVreID presents many important new features. (1) long sequences: the average sequence length is 200 frames, which convey more abundant cues like pose and viewpoint changes that can be explored for feature learning. (2) complex lighting, scene, and background variations: it is captured by 15 cameras located in both indoor and outdoor scenes in 12 time slots. (3) currently the largest size: it contains 3,772 identities and about 3 million bounding boxes. Those unique features in LVreID define a more challenging and realistic person ReID task. Spatial Aligned Temporal Pyramid Pooling (SATPP) network is proposed as a baseline algorithm to leverage the rich visual-temporal cues in LVreID for feature learning. SATPP jointly handles the misalignment issues in detected bounding boxes and efficiently aggregates the discriminative cues embedded in sequential video frames. Extensive experiments show feature extracted by SATPP outperforms several widely used video features. Our experiments also prove the ReID accuracy increases substantially along with longer sequence length. This demonstrates the advantage and necessity of using longer video sequences for person ReID.
Attention Driven Person Re-identification
Oct 13, 2018

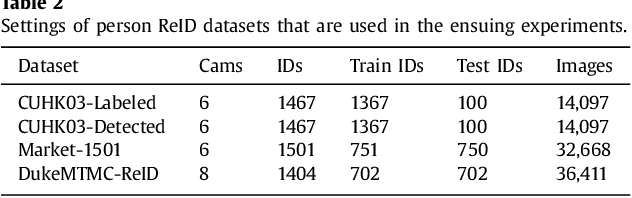
Person re-identification (ReID) is a challenging task due to arbitrary human pose variations, background clutters, etc. It has been studied extensively in recent years, but the multifarious local and global features are still not fully exploited by either ignoring the interplay between whole-body images and body-part images or missing in-depth examination of specific body-part images. In this paper, we propose a novel attention-driven multi-branch network that learns robust and discriminative human representation from global whole-body images and local body-part images simultaneously. Within each branch, an intra-attention network is designed to search for informative and discriminative regions within the whole-body or body-part images, where attention is elegantly decomposed into spatial-wise attention and channel-wise attention for effective and efficient learning. In addition, a novel inter-attention module is designed which fuses the output of intra-attention networks adaptively for optimal person ReID. The proposed technique has been evaluated over three widely used datasets CUHK03, Market-1501 and DukeMTMC-ReID, and experiments demonstrate its superior robustness and effectiveness as compared with the state of the arts.
Computed Tomography Image Enhancement using 3D Convolutional Neural Network
Jul 18, 2018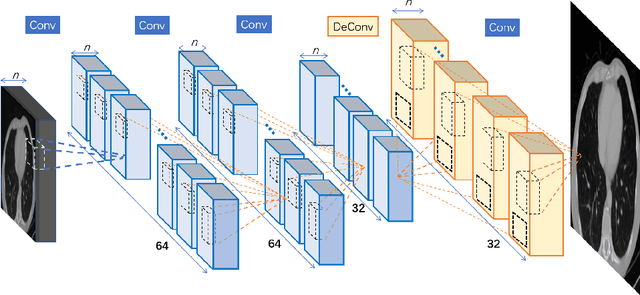
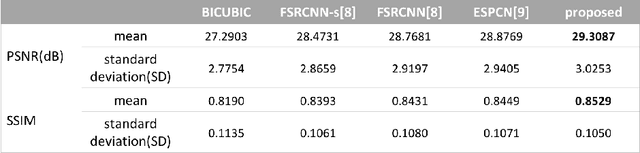
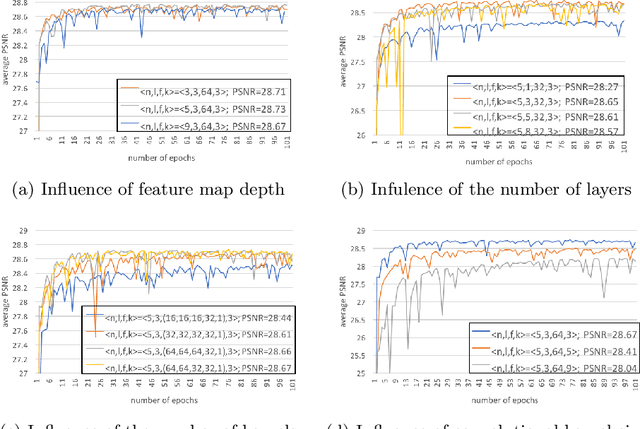
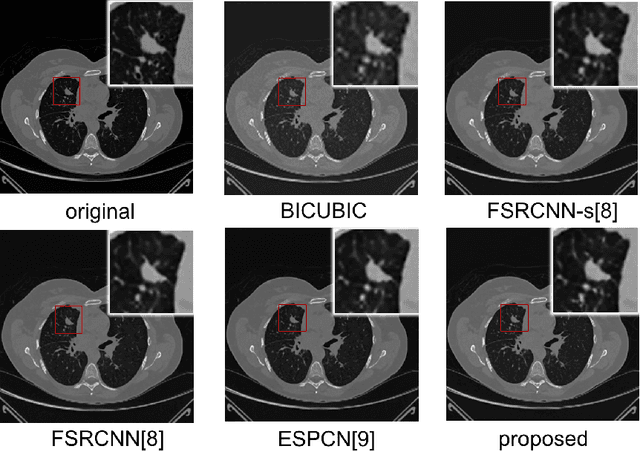
Computed tomography (CT) is increasingly being used for cancer screening, such as early detection of lung cancer. However, CT studies have varying pixel spacing due to differences in acquisition parameters. Thick slice CTs have lower resolution, hindering tasks such as nodule characterization during computer-aided detection due to partial volume effect. In this study, we propose a novel 3D enhancement convolutional neural network (3DECNN) to improve the spatial resolution of CT studies that were acquired using lower resolution/slice thicknesses to higher resolutions. Using a subset of the LIDC dataset consisting of 20,672 CT slices from 100 scans, we simulated lower resolution/thick section scans then attempted to reconstruct the original images using our 3DECNN network. A significant improvement in PSNR (29.3087dB vs. 28.8769dB, p-value < 2.2e-16) and SSIM (0.8529dB vs. 0.8449dB, p-value < 2.2e-16) compared to other state-of-art deep learning methods is observed.