 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAC: Hash-grid Assisted Context for 3D Gaussian Splatting Compression
Mar 21, 2024



3D Gaussian Splatting (3DGS) has emerged as a promising framework for novel view synthesis, boasting rapid rendering speed with high fidelity. However, the substantial Gaussians and their associated attributes necessitate effective compression techniques. Nevertheless, the sparse and unorganized nature of the point cloud of Gaussians (or anchors in our paper) presents challenges for compression. To address this, we make use of the relations between the unorganized anchors and the structured hash grid, leveraging their mutual information for context modeling, and propose a Hash-grid Assisted Context (HAC) framework for highly compact 3DGS representation. Our approach introduces a binary hash grid to establish continuous spatial consistencies, allowing us to unveil the inherent spatial relations of anchors through a carefully designed context model. To facilitate entropy coding, we utilize Gaussian distributions to accurately estimate the probability of each quantized attribute, where an adaptive quantization module is proposed to enable high-precision quantization of these attributes for improved fidelity restoration. Additionally, we incorporate an adaptive masking strategy to eliminate invalid Gaussians and anchors. Importantly, our work is the pioneer to explore context-based compression for 3DGS representation, resulting in a remarkable size reduction of over $75\times$ compared to vanilla 3DGS, while simultaneously improving fidelity, and achieving over $11\times$ size reduction over SOTA 3DGS compression approach Scaffold-GS. Our code is available here: https://github.com/YihangChen-ee/HAC
Collaborative Weakly Supervised Video Correlation Learning for Procedure-Aware Instructional Video Analysis
Dec 18, 2023



Video Correlation Learning (VCL), which aims to analyze the relationships between videos, has been widely studied and applied in various general video tasks. However, applying VCL to instructional videos is still quite challenging due to their intrinsic procedural temporal structure. Specifically, procedural knowledge is critical for accurate correlation analyses on instructional videos. Nevertheless, current procedure-learning methods heavily rely on step-level annotations, which are costly and not scalable. To address this problem, we introduce a weakly supervised framework called Collaborative Procedure Alignment (CPA) for procedure-aware correlation learning on instructional videos. Our framework comprises two core modules: collaborative step mining and frame-to-step alignment. The collaborative step mining module enables simultaneous and consistent step segmentation for paired videos, leveraging the semantic and temporal similarity between frames. Based on the identified steps, the frame-to-step alignment module performs alignment between the frames and steps across videos. The alignment result serves as a measurement of the correlation distance between two videos. We instantiate our framework in two distinct instructional video tasks: sequence verification and action quality assessment. Extensive experiments validate the effectiveness of our approach in providing accurate and interpretable correlation analyses for instructional videos.
Density Matters: Improved Core-set for Active Domain Adaptive Segmentation
Dec 15, 2023



Active domain adaptation has emerged as a solution to balance the expensive annotation cost and the performance of trained models in semantic segmentation. However, existing works usually ignore the correlation between selected samples and its local context in feature space, which leads to inferior usage of annotation budgets. In this work, we revisit the theoretical bound of the classical Core-set method and identify that the performance is closely related to the local sample distribution around selected samples. To estimate the density of local samples efficiently, we introduce a local proxy estimator with Dynamic Masked Convolution and develop a Density-aware Greedy algorithm to optimize the bound. Extensive experiments demonstrate the superiority of our approach. Moreover, with very few labels, our scheme achieves comparable performance to the fully supervised counterpart.
BasisFormer: Attention-based Time Series Forecasting with Learnable and Interpretable Basis
Oct 31, 2023



Bases have become an integral part of modern deep learning-based models for time series forecasting due to their ability to act as feature extractors or future references. To be effective, a basis must be tailored to the specific set of time series data and exhibit distinct correlation with each time series within the set. However, current state-of-the-art methods are limited in their ability to satisfy both of these requirements simultaneously. To address this challenge, we propose BasisFormer, an end-to-end time series forecasting architecture that leverages learnable and interpretable bases. This architecture comprises three components: First, we acquire bases through adaptive self-supervised learning, which treats the historical and future sections of the time series as two distinct views and employs contrastive learning. Next, we design a Coef module that calculates the similarity coefficients between the time series and bases in the historical view via bidirectional cross-attention. Finally, we present a Forecast module that selects and consolidates the bases in the future view based on the similarity coefficients, resulting in accurate future predictions. Through extensive experiments on six datasets, we demonstrate that BasisFormer outperforms previous state-of-the-art methods by 11.04\% and 15.78\% respectively for univariate and multivariate forecasting tasks. Code is available at: \url{https://github.com/nzl5116190/Basisformer}
Few-shot Action Recognition via Intra- and Inter-Video Information Maximization
May 10, 2023



Current few-shot action recognition involves two primary sources of information for classification:(1) intra-video information, determined by frame content within a single video clip, and (2) inter-video information, measured by relationships (e.g., feature similarity) among videos. However, existing methods inadequately exploit these two information sources. In terms of intra-video information, current sampling operations for input videos may omit critical action information, reducing the utilization efficiency of video data. For the inter-video information, the action misalignment among videos makes it challenging to calculate precise relationships. Moreover, how to jointly consider both inter- and intra-video information remains under-explored for few-shot action recognition. To this end, we propose a novel framework, Video Information Maximization (VIM), for few-shot video action recognition. VIM is equipped with an adaptive spatial-temporal video sampler and a spatiotemporal action alignment model to maximize intra- and inter-video information, respectively. The video sampler adaptively selects important frames and amplifies critical spatial regions for each input video based on the task at hand. This preserves and emphasizes informative parts of video clips while eliminating interference at the data level. The alignment model performs temporal and spatial action alignment sequentially at the feature level, leading to more precise measurements of inter-video similarity. Finally, These goals are facilitated by incorporating additional loss terms based on mutual information measurement. Consequently, VIM acts to maximize the distinctiveness of video information from limited video data. Extensive experimental results on public datasets for few-shot action recognition demonstrate the effectiveness and benefits of our framework.
Spatio-Temporal Point Process for Multiple Object Tracking
Feb 05, 2023



Multiple Object Tracking (MOT) focuses on modeling the relationship of detected objects among consecutive frames and merge them into different trajectories. MOT remains a challenging task as noisy and confusing detection results often hinder the final performance. Furthermore, most existing research are focusing on improving detection algorithms and association strategies. As such, we propose a novel framework that can effectively predict and mask-out the noisy and confusing detection results before associating the objects into trajectories. In particular, we formulate such "bad" detection results as a sequence of events and adopt the spatio-temporal point process}to model such events. Traditionally, the occurrence rate in a point process is characterized by an explicitly defined intensity function, which depends on the prior knowledge of some specific tasks. Thus, designing a proper model is expensive and time-consuming, with also limited ability to generalize well. To tackle this problem, we adopt the convolutional recurrent neural network (conv-RNN) to instantiate the point process, where its intensity function is automatically modeled by the training data. Furthermore, we show that our method captures both temporal and spatial evolution, which is essential in modeling events for MOT. Experimental results demonstrate notable improvements in addressing noisy and confusing detection results in MOT datasets. An improved state-of-the-art performance is achieved by incorporating our baseline MOT algorithm with the spatio-temporal point process model.
Low-Rank Winograd Transformation for 3D Convolutional Neural Networks
Jan 26, 2023This paper focuses on Winograd transformation in 3D convolutional neural networks (CNNs) that are more over-parameterized compared with the 2D version. The over-increasing Winograd parameters not only exacerbate training complexity but also barricade the practical speedups due simply to the volume of element-wise products in the Winograd domain. We attempt to reduce trainable parameters by introducing a low-rank Winograd transformation, a novel training paradigm that decouples the original large tensor into two less storage-required trainable tensors, leading to a significant complexity reduction. Built upon our low-rank Winograd transformation, we take one step ahead by proposing a low-rank oriented sparse granularity that measures column-wise parameter importance. By simply involving the non-zero columns in the element-wise product, our sparse granularity is empowered with the ability to produce a very regular sparse pattern to acquire effectual Winograd speedups. To better understand the efficacy of our method, we perform extensive experiments on 3D CNNs. Results manifest that our low-rank Winograd transformation well outperforms the vanilla Winograd transformation. We also show that our proposed low-rank oriented sparse granularity permits practical Winograd acceleration compared with the vanilla counterpart.
The 1st-place Solution for ECCV 2022 Multiple People Tracking in Group Dance Challenge
Oct 27, 2022We present our 1st place solution to the Group Dance Multiple People Tracking Challenge. Based on MOTR: End-to-End Multiple-Object Tracking with Transformer, we explore: 1) detect queries as anchors, 2) tracking as query denoising, 3) joint training on pseudo video clips generated from CrowdHuman dataset, and 4) using the YOLOX detection proposals for the anchor initialization of detect queries. Our method achieves 73.4% HOTA on the DanceTrack test set, surpassing the second-place solution by +6.8% HOTA.
Task-adaptive Spatial-Temporal Video Sampler for Few-shot Action Recognition
Aug 03, 2022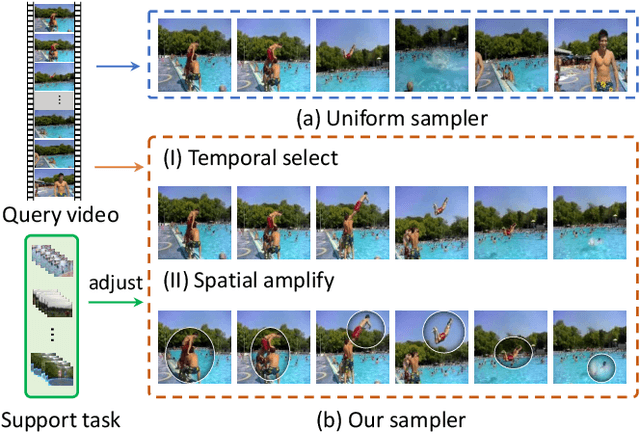
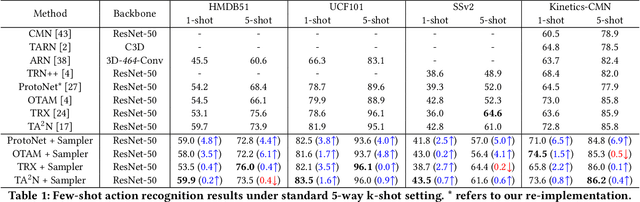
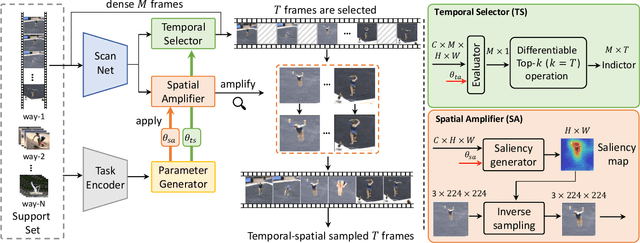
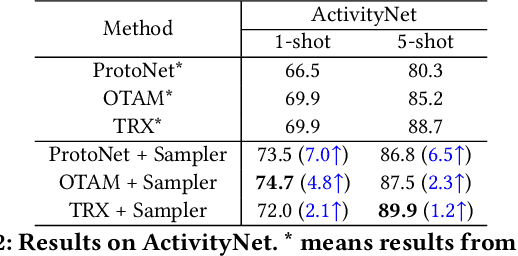
A primary challenge faced in few-shot action recognition is inadequate video data for training. To address this issue, current methods in this field mainly focus on devising algorithms at the feature level while little attention is paid to processing input video data. Moreover, existing frame sampling strategies may omit critical action information in temporal and spatial dimensions, which further impacts video utilization efficiency. In this paper, we propose a novel video frame sampler for few-shot action recognition to address this issue, where task-specific spatial-temporal frame sampling is achieved via a temporal selector (TS) and a spatial amplifier (SA). Specifically, our sampler first scans the whole video at a small computational cost to obtain a global perception of video frames. The TS plays its role in selecting top-T frames that contribute most significantly and subsequently. The SA emphasizes the discriminative information of each frame by amplifying critical regions with the guidance of saliency maps. We further adopt task-adaptive learning to dynamically adjust the sampling strategy according to the episode task at hand. Both the implementations of TS and SA are differentiable for end-to-end optimization, facilitating seamless integration of our proposed sampler with most few-shot action recognition methods. Extensive experiments show a significant boost in the performances on various benchmarks including long-term videos.
FRIH: Fine-grained Region-aware Image Harmonization
May 13, 2022

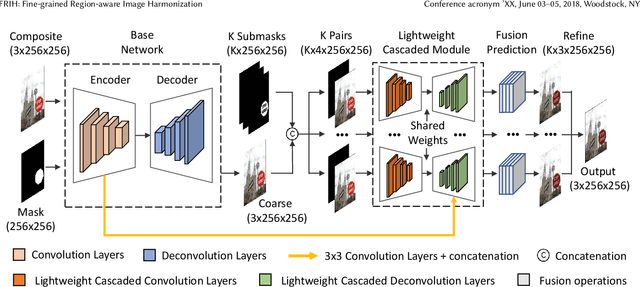
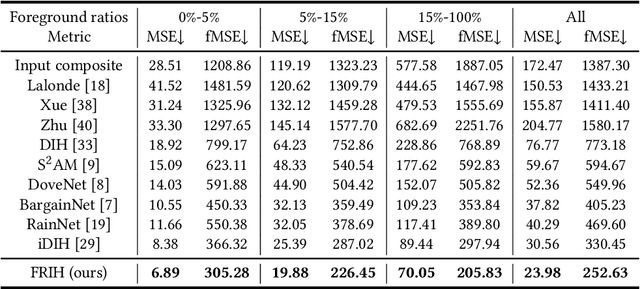
Image harmonization aims to generate a more realistic appearance of foreground and background for a composite image. Existing methods perform the same harmonization process for the whole foreground. However, the implanted foreground always contains different appearance patterns. All the existing solutions ignore the difference of each color block and losing some specific details. Therefore, we propose a novel global-local two stages framework for Fine-grained Region-aware Image Harmonization (FRIH), which is trained end-to-end. In the first stage, the whole input foreground mask is used to make a global coarse-grained harmonization. In the second stage, we adaptively cluster the input foreground mask into several submasks by the corresponding pixel RGB values in the composite image. Each submask and the coarsely adjusted image are concatenated respectively and fed into a lightweight cascaded module, adjusting the global harmonization performance according to the region-aware local feature. Moreover, we further designed a fusion prediction module by fusing features from all the cascaded decoder layers together to generate the final result, which could utilize the different degrees of harmonization results comprehensively. Without bells and whistles, our FRIH algorithm achieves the best performance on iHarmony4 dataset (PSNR is 38.19 dB) with a lightweight model. The parameters for our model are only 11.98 M, far below the existing methods.