 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOphGLM: Training an Ophthalmology Large Language-and-Vision Assistant based on Instructions and Dialogue
Jun 22, 2023



Large multimodal language models (LMMs) have achieved significant success in general domains. However, due to the significant differences between medical images and text and general web content, the performance of LMMs in medical scenarios is limited. In ophthalmology, clinical diagnosis relies on multiple modalities of medical images, but unfortunately, multimodal ophthalmic large language models have not been explored to date. In this paper, we study and construct an ophthalmic large multimodal model. Firstly, we use fundus images as an entry point to build a disease assessment and diagnosis pipeline to achieve common ophthalmic disease diagnosis and lesion segmentation. Then, we establish a new ophthalmic multimodal instruction-following and dialogue fine-tuning dataset based on disease-related knowledge data and publicly available real-world medical dialogue. We introduce visual ability into the large language model to complete the ophthalmic large language and vision assistant (OphGLM). Our experimental results demonstrate that the OphGLM model performs exceptionally well, and it has the potential to revolutionize clinical applications in ophthalmology. The dataset, code, and models will be made publicly available at https://github.com/ML-AILab/OphGLM.
Machine Learning Force Fields with Data Cost Aware Training
Jun 05, 2023



Machine learning force fields (MLFF) have been proposed to accelerate molecular dynamics (MD) simulation, which finds widespread applications in chemistry and biomedical research. Even for the most data-efficient MLFFs, reaching chemical accuracy can require hundreds of frames of force and energy labels generated by expensive quantum mechanical algorithms, which may scale as $O(n^3)$ to $O(n^7)$, with $n$ proportional to the number of basis functions. To address this issue, we propose a multi-stage computational framework -- ASTEROID, which lowers the data cost of MLFFs by leveraging a combination of cheap inaccurate data and expensive accurate data. The motivation behind ASTEROID is that inaccurate data, though incurring large bias, can help capture the sophisticated structures of the underlying force field. Therefore, we first train a MLFF model on a large amount of inaccurate training data, employing a bias-aware loss function to prevent the model from overfitting tahe potential bias of this data. We then fine-tune the obtained model using a small amount of accurate training data, which preserves the knowledge learned from the inaccurate training data while significantly improving the model's accuracy. Moreover, we propose a variant of ASTEROID based on score matching for the setting where the inaccurate training data are unlabeled. Extensive experiments on MD datasets and downstream tasks validate the efficacy of ASTEROID. Our code and data are available at https://github.com/abukharin3/asteroid.
Learning Regularized Positional Encoding for Molecular Prediction
Nov 23, 2022



Machine learning has become a promising approach for molecular modeling. Positional quantities, such as interatomic distances and bond angles, play a crucial role in molecule physics. The existing works rely on careful manual design of their representation. To model the complex nonlinearity in predicting molecular properties in an more end-to-end approach, we propose to encode the positional quantities with a learnable embedding that is continuous and differentiable. A regularization technique is employed to encourage embedding smoothness along the physical dimension. We experiment with a variety of molecular property and force field prediction tasks. Improved performance is observed for three different model architectures after plugging in the proposed positional encoding method. In addition, the learned positional encoding allows easier physics-based interpretation. We observe that tasks of similar physics have the similar learned positional encoding.
Supervised Pretraining for Molecular Force Fields and Properties Prediction
Nov 23, 2022



Machine learning approaches have become popular for molecular modeling tasks, including molecular force fields and properties prediction. Traditional supervised learning methods suffer from scarcity of labeled data for particular tasks, motivating the use of large-scale dataset for other relevant tasks. We propose to pretrain neural networks on a dataset of 86 millions of molecules with atom charges and 3D geometries as inputs and molecular energies as labels. Experiments show that, compared to training from scratch, fine-tuning the pretrained model can significantly improve the performance for seven molecular property prediction tasks and two force field tasks. We also demonstrate that the learned representations from the pretrained model contain adequate information about molecular structures, by showing that linear probing of the representations can predict many molecular information including atom types, interatomic distances, class of molecular scaffolds, and existence of molecular fragments. Our results show that supervised pretraining is a promising research direction in molecular modeling
Learning to Simulate Unseen Physical Systems with Graph Neural Networks
Jan 28, 2022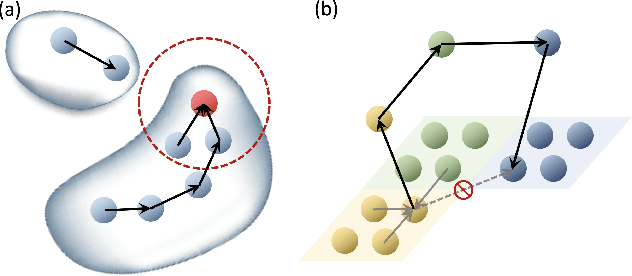
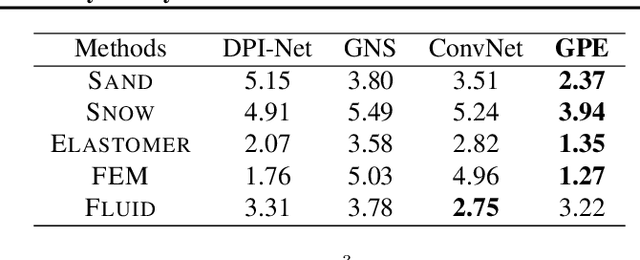
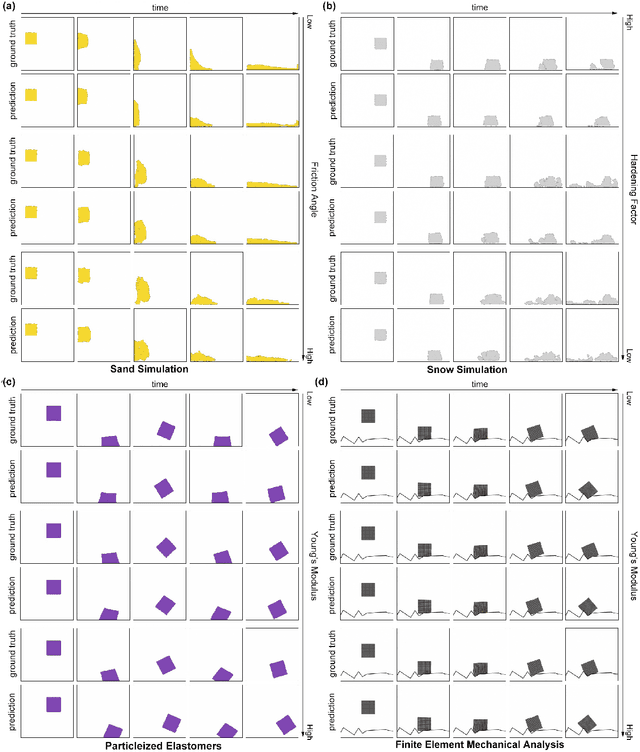
Simulation of the dynamics of physical systems is essential to the development of both science and engineering. Recently there is an increasing interest in learning to simulate the dynamics of physical systems using neural networks. However, existing approaches fail to generalize to physical substances not in the training set, such as liquids with different viscosities or elastomers with different elasticities. Here we present a machine learning method embedded with physical priors and material parameters, which we term as "Graph-based Physics Engine" (GPE), to efficiently model the physical dynamics of different substances in a wide variety of scenarios. We demonstrate that GPE can generalize to materials with different properties not seen in the training set and perform well from single-step predictions to multi-step roll-out simulations. In addition, introducing the law of momentum conservation in the model significantly improves the efficiency and stability of learning, allowing convergence to better models with fewer training steps.
Learning Large-Time-Step Molecular Dynamics with Graph Neural Networks
Dec 21, 2021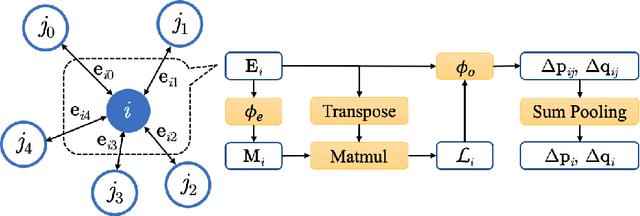

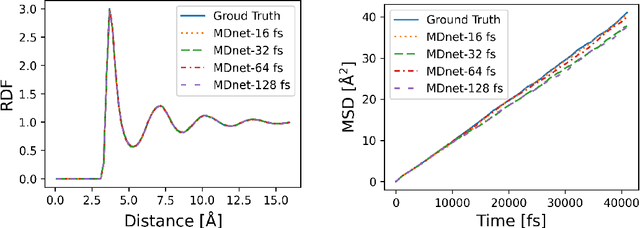
Molecular dynamics (MD) simulation predicts the trajectory of atoms by solving Newton's equation of motion with a numeric integrator. Due to physical constraints, the time step of the integrator need to be small to maintain sufficient precision. This limits the efficiency of simulation. To this end, we introduce a graph neural network (GNN) based model, MDNet, to predict the evolution of coordinates and momentum with large time steps. In addition, MDNet can easily scale to a larger system, due to its linear complexity with respect to the system size. We demonstrate the performance of MDNet on a 4000-atom system with large time steps, and show that MDNet can predict good equilibrium and transport properties, well aligned with standard MD simulations.
Defending against Reconstruction Attack in Vertical Federated Learning
Jul 21, 2021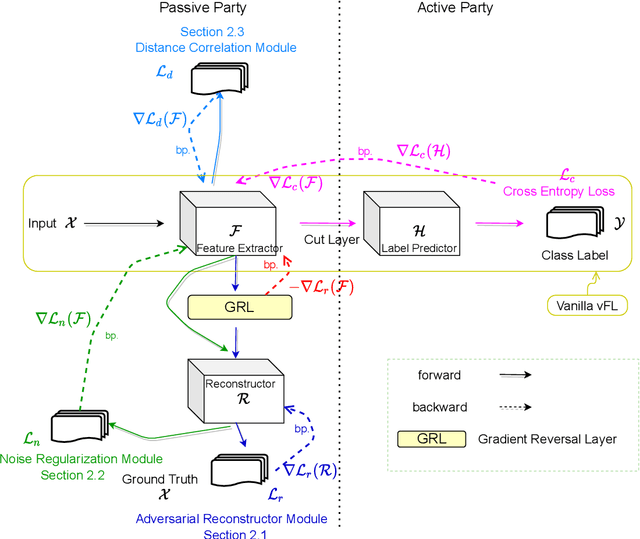
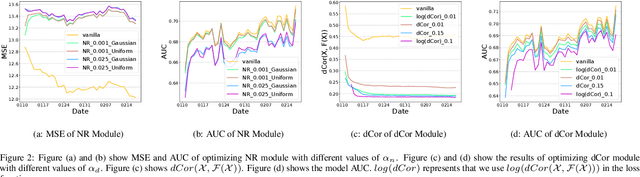
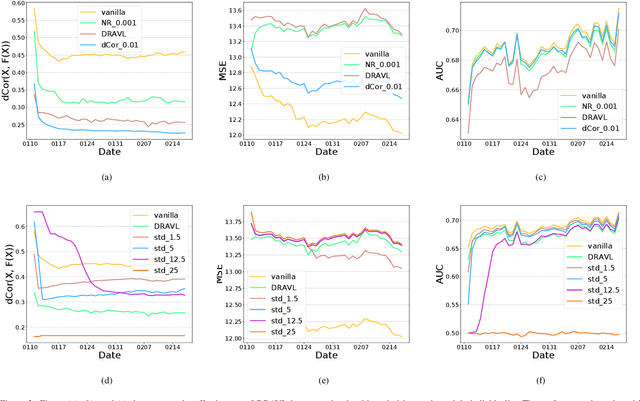
Recently researchers have studied input leakage problems in Federated Learning (FL) where a malicious party can reconstruct sensitive training inputs provided by users from shared gradient. It raises concerns about FL since input leakage contradicts the privacy-preserving intention of using FL. Despite a relatively rich literature on attacks and defenses of input reconstruction in Horizontal FL, input leakage and protection in vertical FL starts to draw researcher's attention recently. In this paper, we study how to defend against input leakage attacks in Vertical FL. We design an adversarial training-based framework that contains three modules: adversarial reconstruction, noise regularization, and distance correlation minimization. Those modules can not only be employed individually but also applied together since they are independent to each other. Through extensive experiments on a large-scale industrial online advertising dataset, we show our framework is effective in protecting input privacy while retaining the model utility.
Vertical Federated Learning without Revealing Intersection Membership
Jun 10, 2021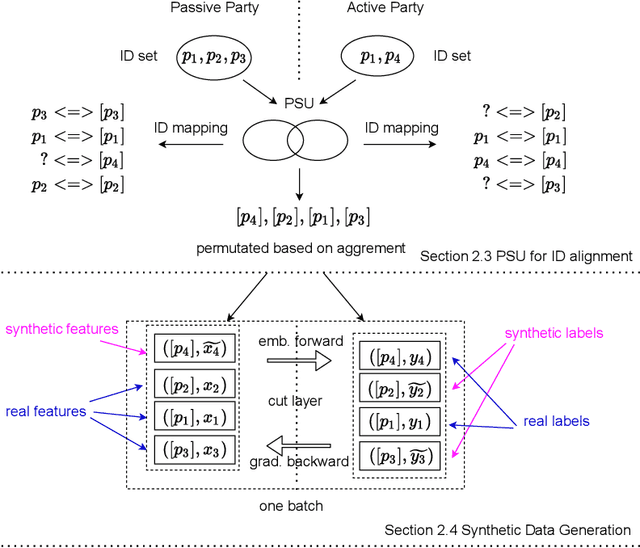

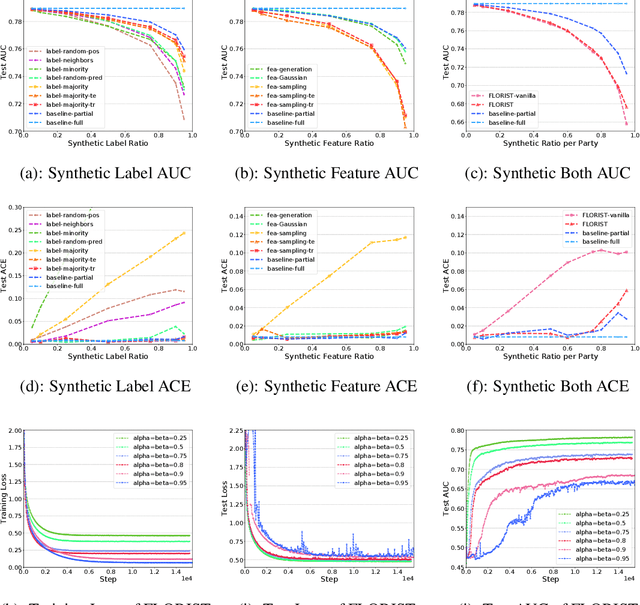

Vertical Federated Learning (vFL) allows multiple parties that own different attributes (e.g. features and labels) of the same data entity (e.g. a person) to jointly train a model. To prepare the training data, vFL needs to identify the common data entities shared by all parties. It is usually achieved by Private Set Intersection (PSI) which identifies the intersection of training samples from all parties by using personal identifiable information (e.g. email) as sample IDs to align data instances. As a result, PSI would make sample IDs of the intersection visible to all parties, and therefore each party can know that the data entities shown in the intersection also appear in the other parties, i.e. intersection membership. However, in many real-world privacy-sensitive organizations, e.g. banks and hospitals, revealing membership of their data entities is prohibited. In this paper, we propose a vFL framework based on Private Set Union (PSU) that allows each party to keep sensitive membership information to itself. Instead of identifying the intersection of all training samples, our PSU protocol generates the union of samples as training instances. In addition, we propose strategies to generate synthetic features and labels to handle samples that belong to the union but not the intersection. Through extensive experiments on two real-world datasets, we show our framework can protect the privacy of the intersection membership while maintaining the model utility.
One Backward from Ten Forward, Subsampling for Large-Scale Deep Learning
Apr 27, 2021
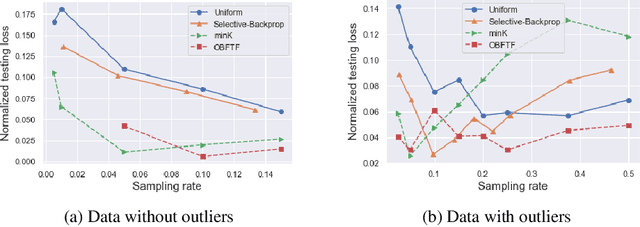

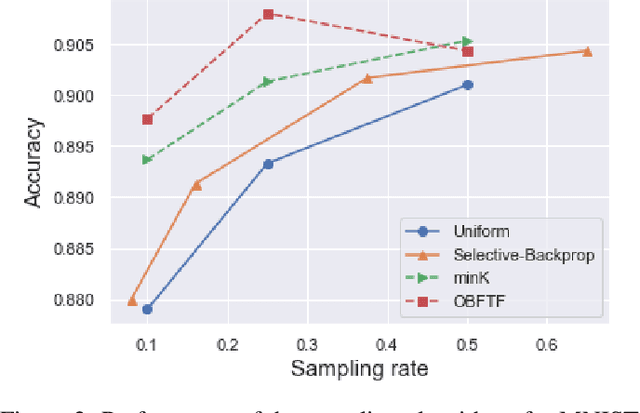
Deep learning models in large-scale machine learning systems are often continuously trained with enormous data from production environments. The sheer volume of streaming training data poses a significant challenge to real-time training subsystems and ad-hoc sampling is the standard practice. Our key insight is that these deployed ML systems continuously perform forward passes on data instances during inference, but ad-hoc sampling does not take advantage of this substantial computational effort. Therefore, we propose to record a constant amount of information per instance from these forward passes. The extra information measurably improves the selection of which data instances should participate in forward and backward passes. A novel optimization framework is proposed to analyze this problem and we provide an efficient approximation algorithm under the framework of Mini-batch gradient descent as a practical solution. We also demonstrate the effectiveness of our framework and algorithm on several large-scale classification and regression tasks, when compared with competitive baselines widely used in industry.
Label Leakage and Protection in Two-party Split Learning
Feb 17, 2021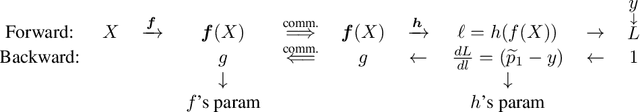
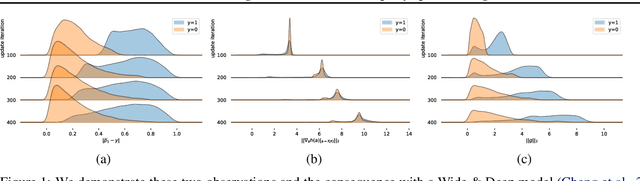
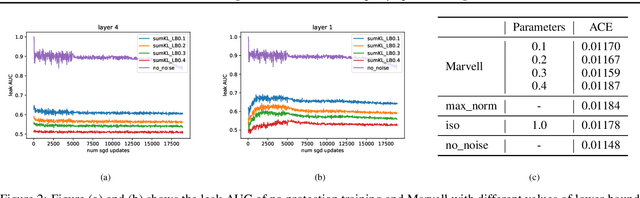
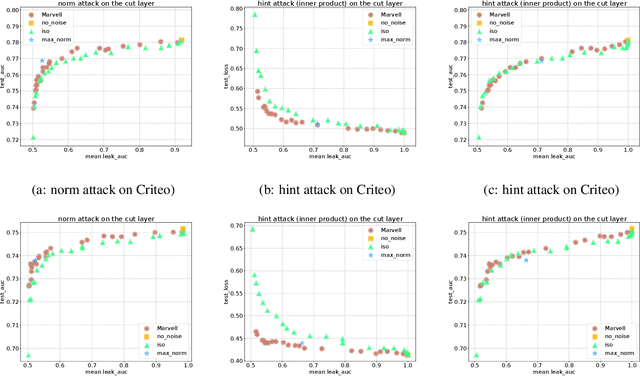
In vertical federated learning, two-party split learning has become an important topic and has found many applications in real business scenarios. However, how to prevent the participants' ground-truth labels from possible leakage is not well studied. In this paper, we consider answering this question in an imbalanced binary classification setting, a common case in online business applications. We first show that, norm attack, a simple method that uses the norm of the communicated gradients between the parties, can largely reveal the ground-truth labels from the participants. We then discuss several protection techniques to mitigate this issue. Among them, we have designed a principled approach that directly maximizes the worst-case error of label detection. This is proved to be more effective in countering norm attack and beyond. We experimentally demonstrate the competitiveness of our proposed method compared to several other baselines.