 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Surprising Difficulty of Search in Model-Based Reinforcement Learning
Jan 29, 2026This paper investigates search in model-based reinforcement learning (RL). Conventional wisdom holds that long-term predictions and compounding errors are the primary obstacles for model-based RL. We challenge this view, showing that search is not a plug-and-play replacement for a learned policy. Surprisingly, we find that search can harm performance even when the model is highly accurate. Instead, we show that mitigating distribution shift matters more than improving model or value function accuracy. Building on this insight, we identify key techniques for enabling effective search, achieving state-of-the-art performance across multiple popular benchmark domains.
Seeing the Unseen: How EMoE Unveils Bias in Text-to-Image Diffusion Models
May 19, 2025Estimating uncertainty in text-to-image diffusion models is challenging because of their large parameter counts (often exceeding 100 million) and operation in complex, high-dimensional spaces with virtually infinite input possibilities. In this paper, we propose Epistemic Mixture of Experts (EMoE), a novel framework for efficiently estimating epistemic uncertainty in diffusion models. EMoE leverages pre-trained networks without requiring additional training, enabling direct uncertainty estimation from a prompt. We leverage a latent space within the diffusion process that captures epistemic uncertainty better than existing methods. Experimental results on the COCO dataset demonstrate EMoE's effectiveness, showing a strong correlation between uncertainty and image quality. Additionally, EMoE identifies under-sampled languages and regions with higher uncertainty, revealing hidden biases in the training set. This capability demonstrates the relevance of EMoE as a tool for addressing fairness and accountability in AI-generated content.
Generalizable Imitation Learning Through Pre-Trained Representations
Nov 15, 2023



In this paper we leverage self-supervised vision transformer models and their emergent semantic abilities to improve the generalization abilities of imitation learning policies. We introduce BC-ViT, an imitation learning algorithm that leverages rich DINO pre-trained Visual Transformer (ViT) patch-level embeddings to obtain better generalization when learning through demonstrations. Our learner sees the world by clustering appearance features into semantic concepts, forming stable keypoints that generalize across a wide range of appearance variations and object types. We show that this representation enables generalized behaviour by evaluating imitation learning across a diverse dataset of object manipulation tasks. Our method, data and evaluation approach are made available to facilitate further study of generalization in Imitation Learners.
Imitation Learning from Observation through Optimal Transport
Oct 02, 2023



Imitation Learning from Observation (ILfO) is a setting in which a learner tries to imitate the behavior of an expert, using only observational data and without the direct guidance of demonstrated actions. In this paper, we re-examine the use of optimal transport for IL, in which a reward is generated based on the Wasserstein distance between the state trajectories of the learner and expert. We show that existing methods can be simplified to generate a reward function without requiring learned models or adversarial learning. Unlike many other state-of-the-art methods, our approach can be integrated with any RL algorithm, and is amenable to ILfO. We demonstrate the effectiveness of this simple approach on a variety of continuous control tasks and find that it surpasses the state of the art in the IlfO setting, achieving expert-level performance across a range of evaluation domains even when observing only a single expert trajectory without actions.
For SALE: State-Action Representation Learning for Deep Reinforcement Learning
Jun 04, 2023



In the field of reinforcement learning (RL), representation learning is a proven tool for complex image-based tasks, but is often overlooked for environments with low-level states, such as physical control problems. This paper introduces SALE, a novel approach for learning embeddings that model the nuanced interaction between state and action, enabling effective representation learning from low-level states. We extensively study the design space of these embeddings and highlight important design considerations. We integrate SALE and an adaptation of checkpoints for RL into TD3 to form the TD7 algorithm, which significantly outperforms existing continuous control algorithms. On OpenAI gym benchmark tasks, TD7 has an average performance gain of 276.7% and 50.7% over TD3 at 300k and 5M time steps, respectively, and works in both the online and offline settings.
Self-Supervised Transformer Architecture for Change Detection in Radio Access Networks
Feb 03, 2023



Radio Access Networks (RANs) for telecommunications represent large agglomerations of interconnected hardware consisting of hundreds of thousands of transmitting devices (cells). Such networks undergo frequent and often heterogeneous changes caused by network operators, who are seeking to tune their system parameters for optimal performance. The effects of such changes are challenging to predict and will become even more so with the adoption of 5G/6G networks. Therefore, RAN monitoring is vital for network operators. We propose a self-supervised learning framework that leverages self-attention and self-distillation for this task. It works by detecting changes in Performance Measurement data, a collection of time-varying metrics which reflect a set of diverse measurements of the network performance at the cell level. Experimental results show that our approach outperforms the state of the art by 4% on a real-world based dataset consisting of about hundred thousands timeseries. It also has the merits of being scalable and generalizable. This allows it to provide deep insight into the specifics of mode of operation changes while relying minimally on expert knowledge.
IL-flOw: Imitation Learning from Observation using Normalizing Flows
May 19, 2022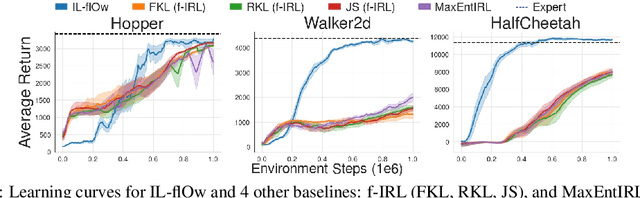
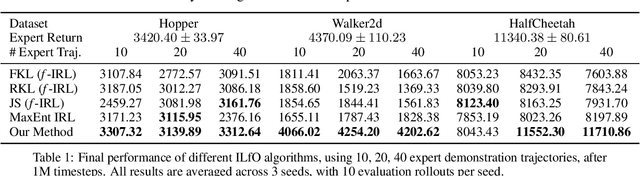
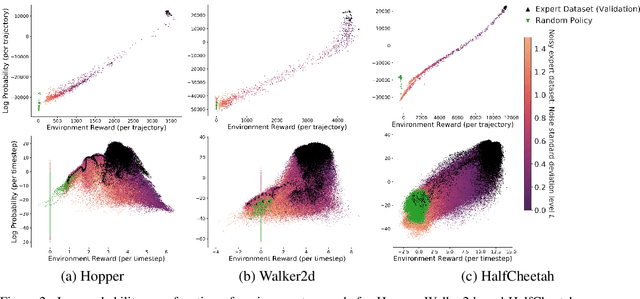
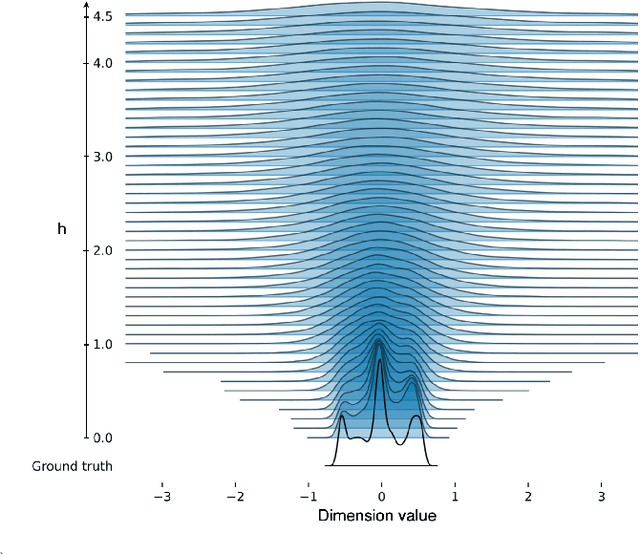
We present an algorithm for Inverse Reinforcement Learning (IRL) from expert state observations only. Our approach decouples reward modelling from policy learning, unlike state-of-the-art adversarial methods which require updating the reward model during policy search and are known to be unstable and difficult to optimize. Our method, IL-flOw, recovers the expert policy by modelling state-state transitions, by generating rewards using deep density estimators trained on the demonstration trajectories, avoiding the instability issues of adversarial methods. We demonstrate that using the state transition log-probability density as a reward signal for forward reinforcement learning translates to matching the trajectory distribution of the expert demonstrations, and experimentally show good recovery of the true reward signal as well as state of the art results for imitation from observation on locomotion and robotic continuous control tasks.
One-Shot Informed Robotic Visual Search in the Wild
Mar 22, 2020
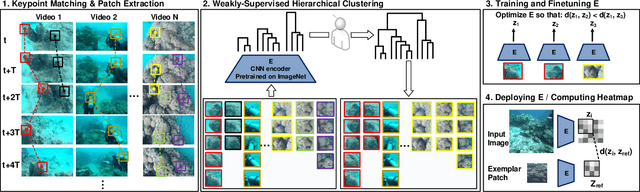


We consider the task of underwater robot navigation for the purpose of collecting scientifically-relevant video data for environmental monitoring. The majority of field robots that currently perform monitoring tasks in unstructured natural environments navigate via path-tracking a pre-specified sequence of waypoints. Although this navigation method is often necessary, it is limiting because the robot does not have a model of what the scientist deems to be relevant visual observations. Thus, the robot can neither visually search for particular types of objects, nor focus its attention on parts of the scene that might be more relevant than the pre-specified waypoints and viewpoints. In this paper we propose a method that enables informed visual navigation via a learned visual similarity operator that guides the robot's visual search towards parts of the scene that look like an exemplar image, which is given by the user as a high-level specification for data collection. We propose and evaluate a weakly-supervised video representation learning method that outperforms ImageNet embeddings for similarity tasks in the underwater domain. We also demonstrate the deployment of this similarity operator during informed visual navigation in collaborative environmental monitoring scenarios, in large-scale field trials, where the robot and a human scientist jointly search for relevant visual content.
OptionGAN: Learning Joint Reward-Policy Options using Generative Adversarial Inverse Reinforcement Learning
Nov 24, 2017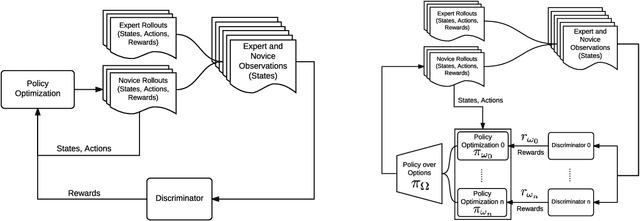

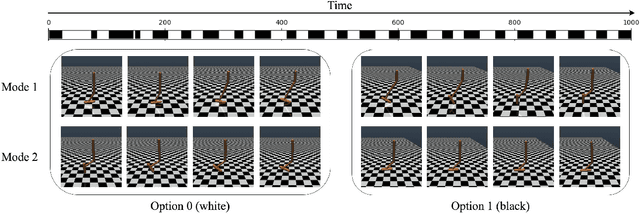
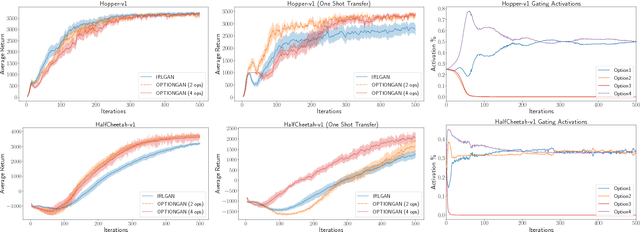
Reinforcement learning has shown promise in learning policies that can solve complex problems. However, manually specifying a good reward function can be difficult, especially for intricate tasks. Inverse reinforcement learning offers a useful paradigm to learn the underlying reward function directly from expert demonstrations. Yet in reality, the corpus of demonstrations may contain trajectories arising from a diverse set of underlying reward functions rather than a single one. Thus, in inverse reinforcement learning, it is useful to consider such a decomposition. The options framework in reinforcement learning is specifically designed to decompose policies in a similar light. We therefore extend the options framework and propose a method to simultaneously recover reward options in addition to policy options. We leverage adversarial methods to learn joint reward-policy options using only observed expert states. We show that this approach works well in both simple and complex continuous control tasks and shows significant performance increases in one-shot transfer learning.
Underwater Multi-Robot Convoying using Visual Tracking by Detection
Sep 25, 2017
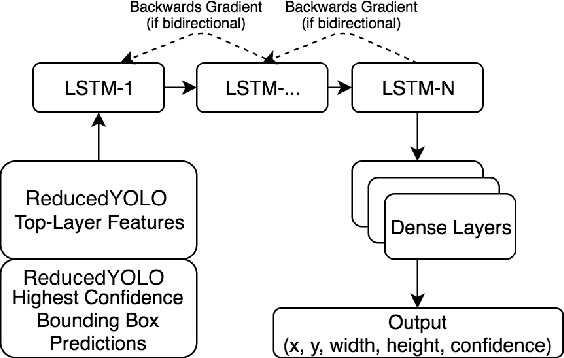
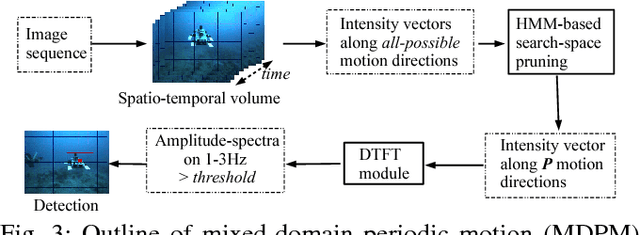
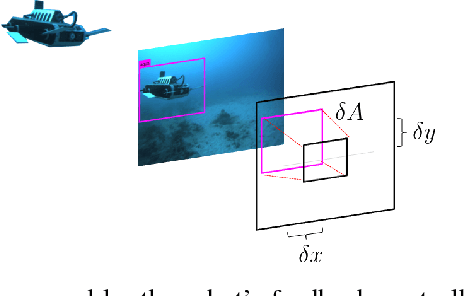
We present a robust multi-robot convoying approach that relies on visual detection of the leading agent, thus enabling target following in unstructured 3-D environments. Our method is based on the idea of tracking-by-detection, which interleaves efficient model-based object detection with temporal filtering of image-based bounding box estimation. This approach has the important advantage of mitigating tracking drift (i.e. drifting away from the target object), which is a common symptom of model-free trackers and is detrimental to sustained convoying in practice. To illustrate our solution, we collected extensive footage of an underwater robot in ocean settings, and hand-annotated its location in each frame. Based on this dataset, we present an empirical comparison of multiple tracker variants, including the use of several convolutional neural networks, both with and without recurrent connections, as well as frequency-based model-free trackers. We also demonstrate the practicality of this tracking-by-detection strategy in real-world scenarios by successfully controlling a legged underwater robot in five degrees of freedom to follow another robot's independent motion.