 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Further Study of Unsupervised Pre-training for Transformer Based Speech Recognition
Jun 23, 2020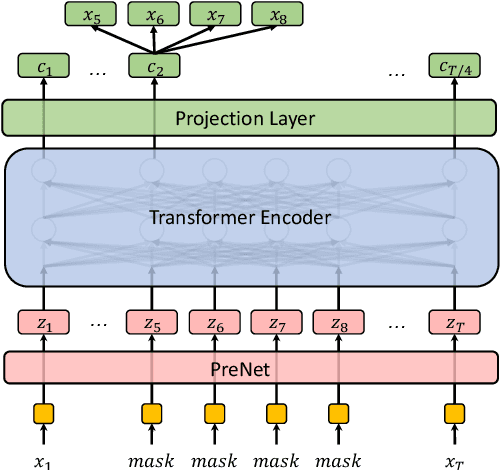

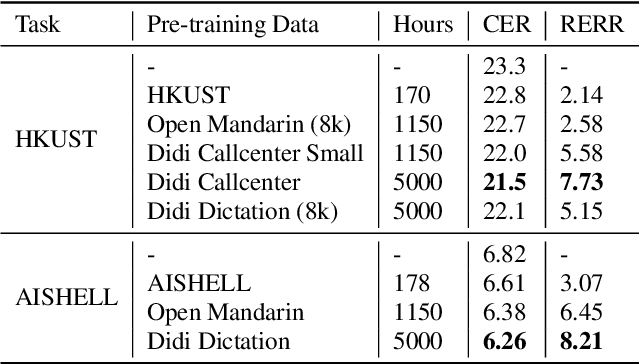
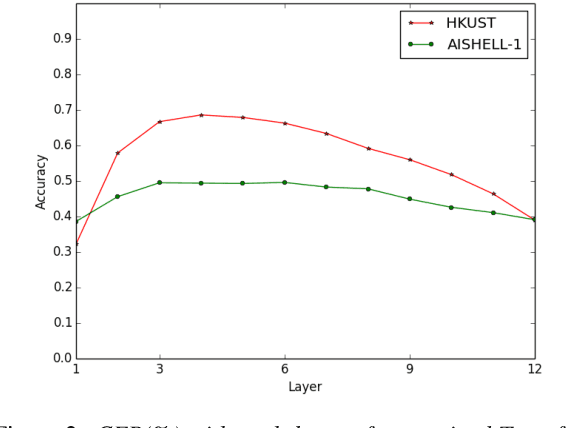
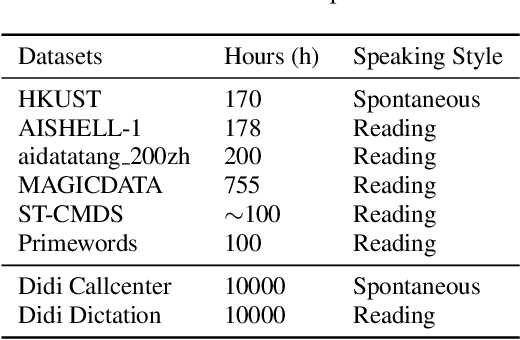
Building a good speech recognition system usually requires large amounts of transcribed data, which is expensive to collect. To tackle this problem, many unsupervised pre-training methods have been proposed. Among these methods, Masked Predictive Coding achieved significant improvements on various speech recognition datasets with BERT-like Masked Reconstruction loss and Transformer backbone. However, many aspects of MPC have not been fully investigated. In this paper, we conduct a further study on MPC and focus on three important aspects: the effect of pre-training data speaking style, its extension on streaming model, and how to better transfer learned knowledge from pre-training stage to downstream tasks. Experiments reveled that pre-training data with matching speaking style is more useful on downstream recognition tasks. A unified training objective with APC and MPC provided 8.46% relative error reduction on streaming model trained on HKUST. Also, the combination of target data adaption and layer-wise discriminative training helped the knowledge transfer of MPC, which achieved 3.99% relative error reduction on AISHELL over a strong baseline.
A Reinforced Generation of Adversarial Samples for Neural Machine Translation
Nov 09, 2019
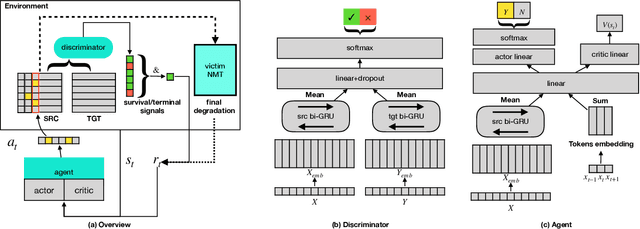

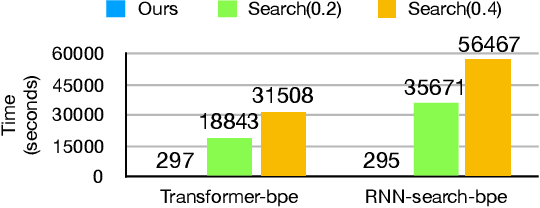
Neural machine translation systems tend to fail on less de-cent inputs despite its great efficacy, which may greatly harm the credibility of these systems. Fathoming how and when neural-based systems fail in such cases is critical for industrial maintenance. Instead of collecting and analyzing bad cases using limited handcrafted error features, here we investigate this issue by generating adversarial samples via a new paradigm based on reinforcement learning. Our paradigm could expose pitfalls for a given performance metric, e.g.BLEU, and could target any given neural machine translation architecture. We conduct experiments of adversarial attacks on two mainstream neural machine translation architectures, RNN-search and Transformer. The results show that our method efficiently produces stable attacks with meaning-preserving adversarial samples. We also present a qualitative and quantitative analysis for the preference pattern of the attack, showing its capability of pitfall exposure.
Improving Transformer-based Speech Recognition Using Unsupervised Pre-training
Oct 31, 2019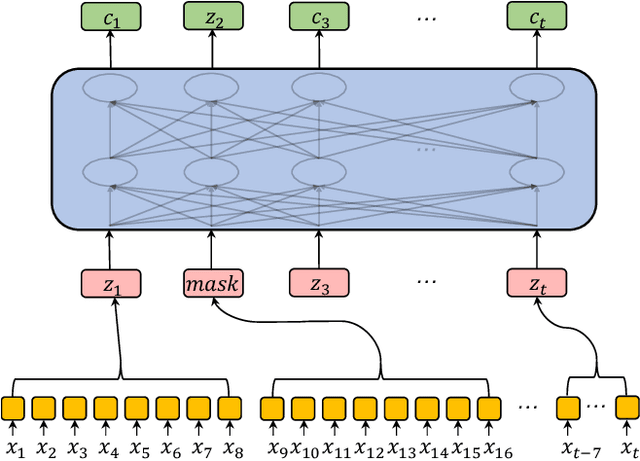
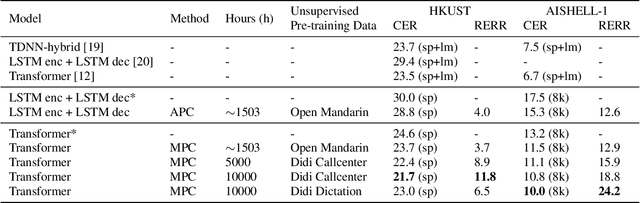
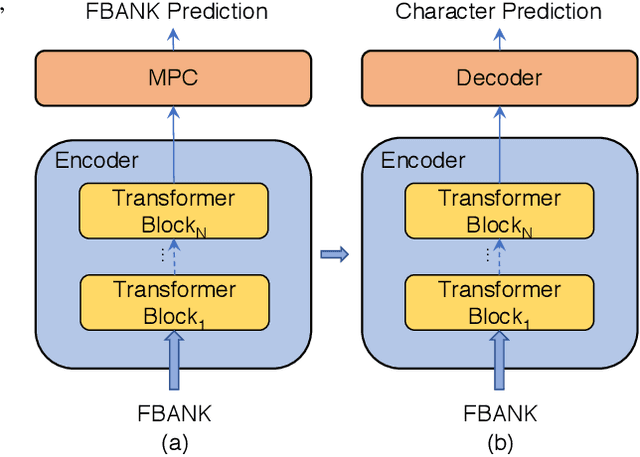
Speech recognition technologies are gaining enormous popularity in various industrial applications. However, building a good speech recognition system usually requires large amounts of transcribed data, which is expensive to collect. To tackle this problem, an unsupervised pre-training method called Masked Predictive Coding is proposed, which can be applied for unsupervised pre-training with Transformer based model. Experiments on HKUST show that using the same training data, we can achieve CER 23.3%, exceeding the best end-to-end model by over 0.2% absolute CER. With more pre-training data, we can further reduce the CER to 21.0%, or a 11.8% relative CER reduction over baseline.
TCT: A Cross-supervised Learning Method for Multimodal Sequence Representation
Oct 23, 2019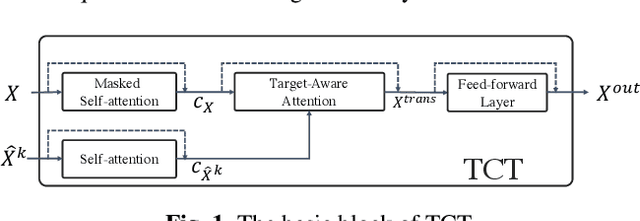
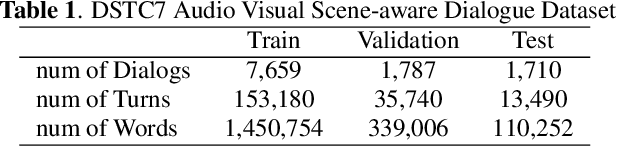
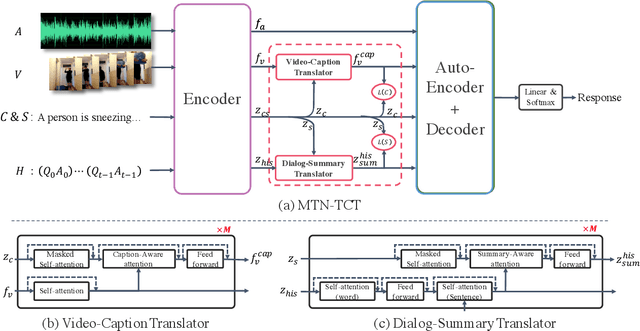
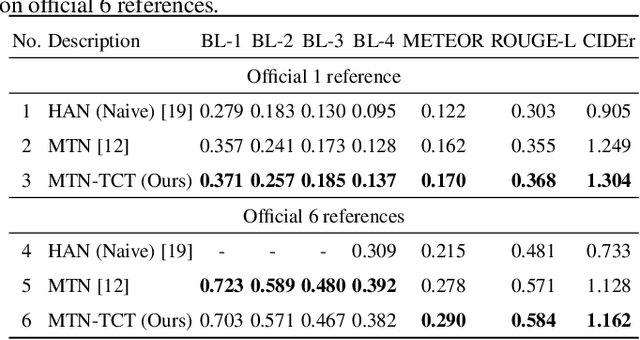
Multimodalities provide promising performance than unimodality in most tasks. However, learning the semantic of the representations from multimodalities efficiently is extremely challenging. To tackle this, we propose the Transformer based Cross-modal Translator (TCT) to learn unimodal sequence representations by translating from other related multimodal sequences on a supervised learning method. Combined TCT with Multimodal Transformer Network (MTN), we evaluate MTN-TCT on the video-grounded dialogue which uses multimodality. The proposed method reports new state-of-the-art performance on video-grounded dialogue which indicates representations learned by TCT are more semantics compared to directly use unimodality.
Cross-task pre-training for acoustic scene classification
Oct 22, 2019
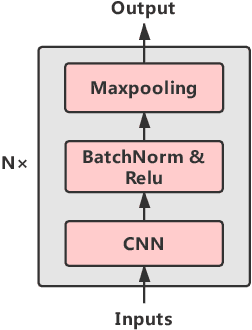
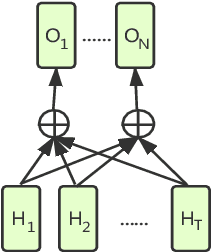
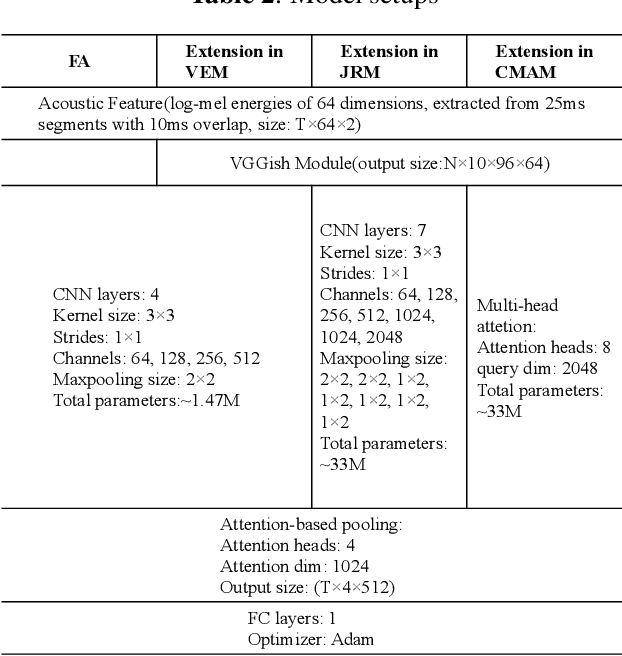
Acoustic scene classification(ASC) and acoustic event detection(AED) are different but related tasks. Acoustic scenes can be shaped by occurred acoustic events which can provide useful information in training ASC tasks. However, most of the datasets are provided without either the acoustic event or scene labels. Therefore, We explored cross-task pre-training mechanism to utilize acoustic event information extracted from the pre-trained model to optimize the ASC task. We present three cross-task pre-training architectures and evaluated them in feature-based and fine-tuning strategies on two datasets respectively: TAU Urban Acoustic Scenes 2019 dataset and TUT Acoustic Scenes 2017 dataset. Results have shown that cross-task pre-training mechanism can significantly improve the performance of ASC tasks and the performance of our best model improved relatively 9.5% in the TAU Urban Acoustic Scenes 2019 dataset, and also improved 10% in the TUT Acoustic Scenes 2017 dataset compared with the official baseline.
The Field-of-View Constraint of Markers for Mobile Robot with Pan-Tilt Camera
Sep 24, 2019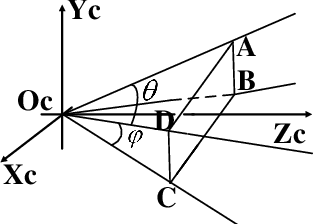
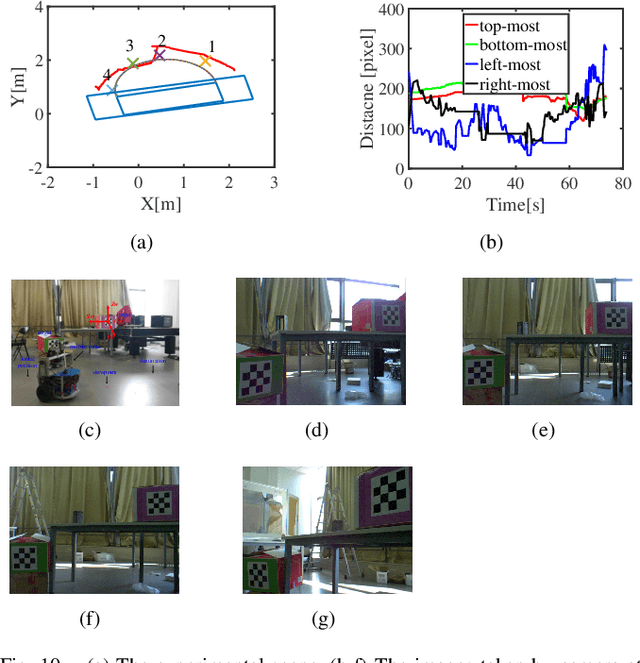
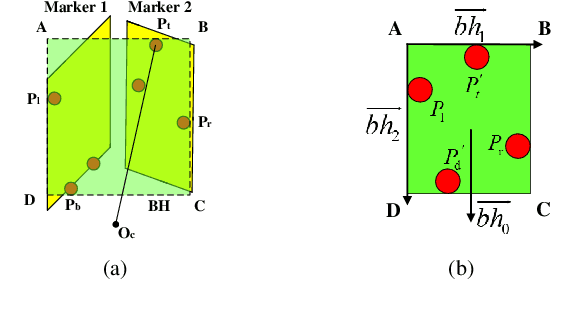
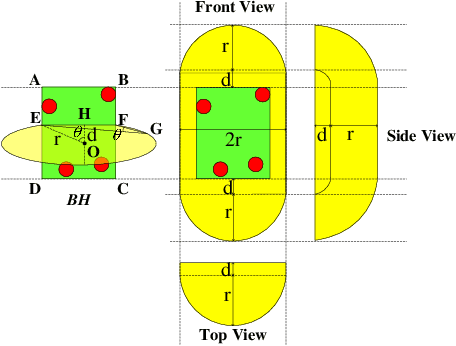
In the field of navigation and visual servo, it is common to calculate relative pose by feature points on markers, so keeping markers in camera's view is an important problem. In this paper, we propose a novel approach to calculate field-of-view (FOV) constraint of markers for camera. Our method can make the camera maintain the visibility of all feature points during the motion of mobile robot. According to the angular aperture of camera, the mobile robot can obtain the FOV constraint region where the camera cannot keep all feature points in an image. Based on the FOV constraint region, the mobile robot can be guided to move from the initial position to destination. Finally simulations and experiments are conducted based on a mobile robot equipped with a pan-tilt camera, which validates the effectiveness of the method to obtain the FOV constraints.
EPOSIT: An Absolute Pose Estimation Method for Pinhole and Fish-Eye Cameras
Sep 19, 2019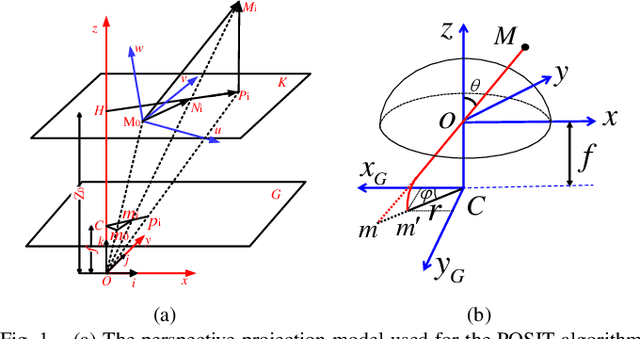
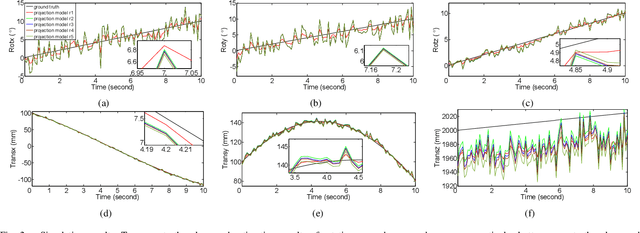
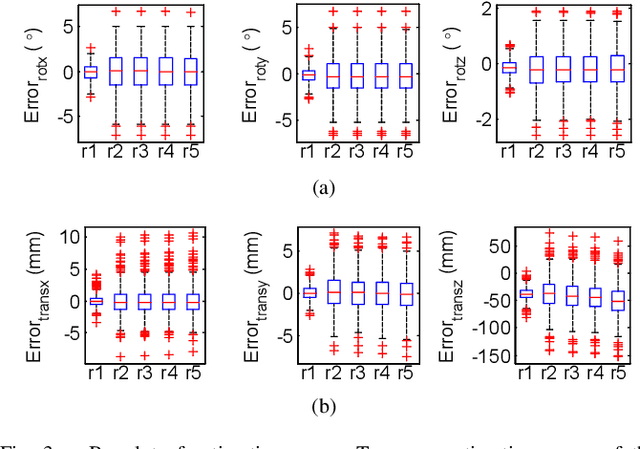
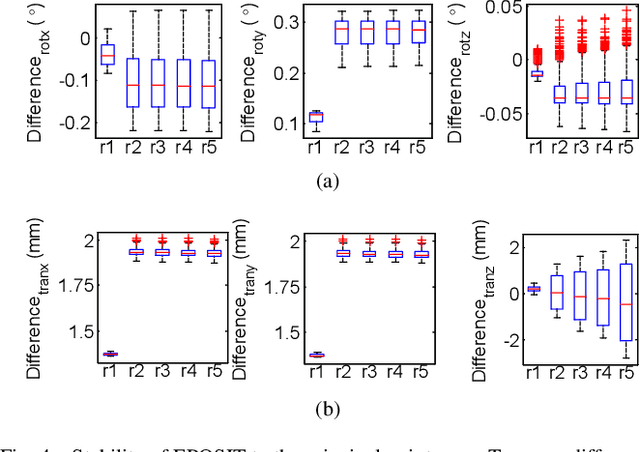
This paper presents a generic 6DOF camera pose estimation method, which can be used for both the pinhole camera and the fish-eye camera. Different from existing methods, relative positions of 3D points rather than absolute coordinates in the world coordinate system are employed in our method, and it has a unique solution. The application scope of POSIT (Pose from Orthography and Scaling with Iteration) algorithm is generalized to fish-eye cameras by combining with the radially symmetric projection model. The image point relationship between the pinhole camera and the fish-eye camera is derived based on their projection model. The general pose expression which fits for different cameras can be acquired by four noncoplanar object points and their corresponding image points. Accurate estimation results are calculated iteratively. Experimental results on synthetic and real data show that the pose estimation results of our method are more stable and accurate than state-of-the-art methods. The source code is available at https://github.com/k032131/EPOSIT.
Human Following for Wheeled Robot with Monocular Pan-tilt Camera
Sep 13, 2019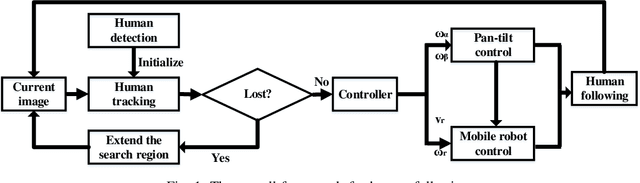
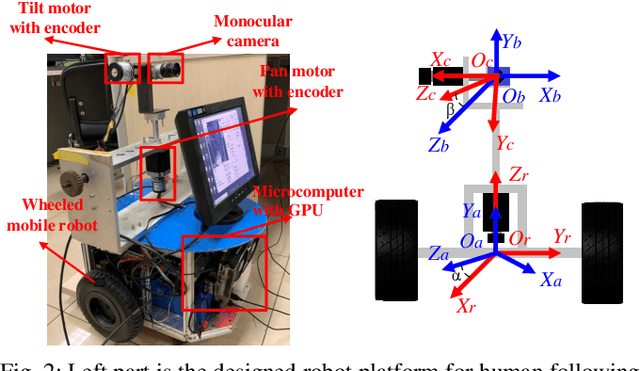
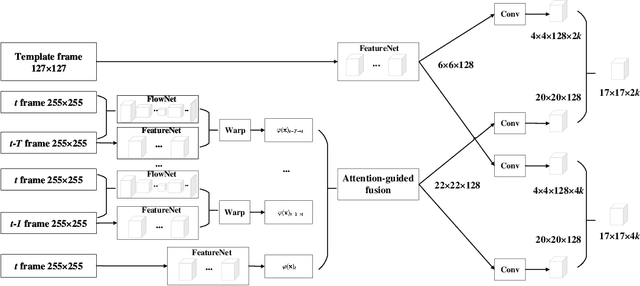

Human following on mobile robots has witnessed significant advances due to its potentials for real-world applications. Currently most human following systems are equipped with depth sensors to obtain distance information between human and robot, which suffer from the perception requirements and noises. In this paper, we design a wheeled mobile robot system with monocular pan-tilt camera to follow human, which can stay the target in the field of view and keep following simultaneously. The system consists of fast human detector, real-time and accurate visual tracker, and unified controller for mobile robot and pan-tilt camera. In visual tracking algorithm, both Siamese networks and optical flow information are exploited to locate and regress human simultaneously. In order in perform following with a monocular camera, the constraint of human height is introduced to design the controller. In experiments, human following are conducted and analysed in simulations and a real robot platform, which demonstrate the effectiveness and robustness of the overall system.
High Performance Visual Object Tracking with Unified Convolutional Networks
Aug 26, 2019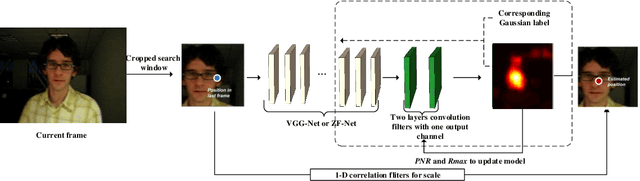
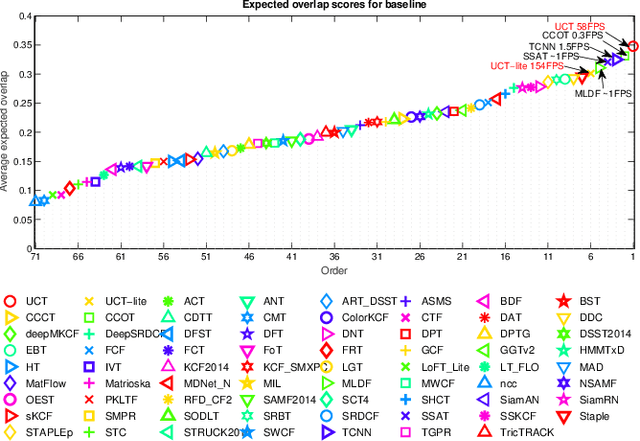
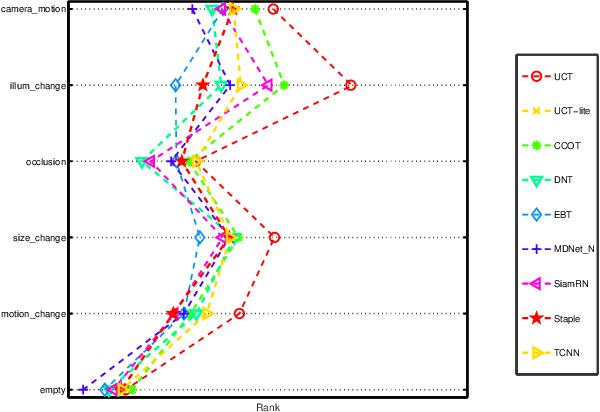
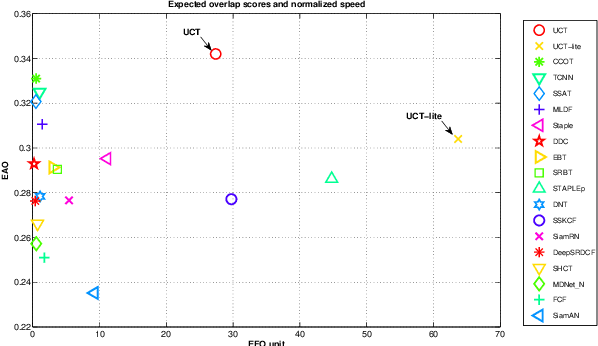
Convolutional neural networks (CNN) based tracking approaches have shown favorable performance in recent benchmarks. Nonetheless, the chosen CNN features are always pre-trained in different tasks and individual components in tracking systems are learned separately, thus the achieved tracking performance may be suboptimal. Besides, most of these trackers are not designed towards real-time applications because of their time-consuming feature extraction and complex optimization details. In this paper, we propose an end-to-end framework to learn the convolutional features and perform the tracking process simultaneously, namely, a unified convolutional tracker (UCT). Specifically, the UCT treats feature extractor and tracking process both as convolution operation and trains them jointly, which enables learned CNN features are tightly coupled with tracking process. During online tracking, an efficient model updating method is proposed by introducing peak-versus-noise ratio (PNR) criterion, and scale changes are handled efficiently by incorporating a scale branch into network. Experiments are performed on four challenging tracking datasets: OTB2013, OTB2015, VOT2015 and VOT2016. Our method achieves leading performance on these benchmarks while maintaining beyond real-time speed.
Camera Pose Correction in SLAM Based on Bias Values of Map Points
Aug 24, 2019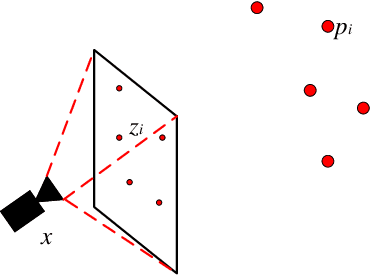
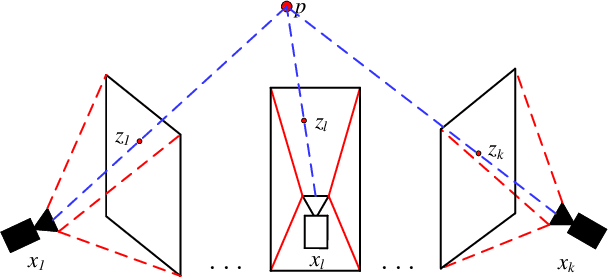
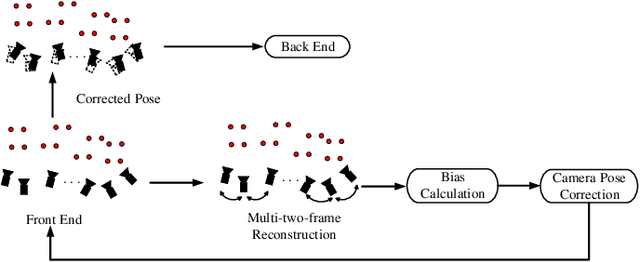
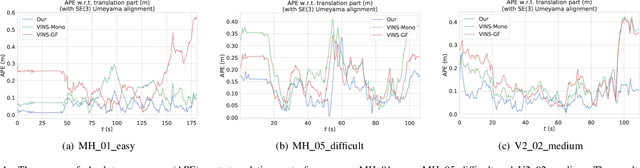
Accurate camera pose estimation result is essential for visual SLAM (VSLAM). This paper presents a novel pose correction method to improve the accuracy of the VSLAM system. Firstly, the relationship between the camera pose estimation error and bias values of map points is derived based on the optimized function in VSLAM. Secondly, the bias value of the map point is calculated by a statistical method. Finally, the camera pose estimation error is compensated according to the first derived relationship. After the pose correction, procedures of the original system, such as the bundle adjustment (BA) optimization, can be executed as before. Compared with existing methods, our algorithm is compact and effective and can be easily generalized to different VSLAM systems. Additionally, the robustness to system noise of our method is better than feature selection methods, due to all original system information is preserved in our algorithm while only a subset is employed in the latter. Experimental results on benchmark datasets show that our approach leads to considerable improvements over state-of-the-art algorithms for absolute pose estimation.