 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Approximation of the Shapley Values Based on Order-of-Addition Experimental Designs
Sep 16, 2023Shapley value is originally a concept in econometrics to fairly distribute both gains and costs to players in a coalition game. In the recent decades, its application has been extended to other areas such as marketing, engineering and machine learning. For example, it produces reasonable solutions for problems in sensitivity analysis, local model explanation towards the interpretable machine learning, node importance in social network, attribution models, etc. However, its heavy computational burden has been long recognized but rarely investigated. Specifically, in a $d$-player coalition game, calculating a Shapley value requires the evaluation of $d!$ or $2^d$ marginal contribution values, depending on whether we are taking the permutation or combination formulation of the Shapley value. Hence it becomes infeasible to calculate the Shapley value when $d$ is reasonably large. A common remedy is to take a random sample of the permutations to surrogate for the complete list of permutations. We find an advanced sampling scheme can be designed to yield much more accurate estimation of the Shapley value than the simple random sampling (SRS). Our sampling scheme is based on combinatorial structures in the field of design of experiments (DOE), particularly the order-of-addition experimental designs for the study of how the orderings of components would affect the output. We show that the obtained estimates are unbiased, and can sometimes deterministically recover the original Shapley value. Both theoretical and simulations results show that our DOE-based sampling scheme outperforms SRS in terms of estimation accuracy. Surprisingly, it is also slightly faster than SRS. Lastly, real data analysis is conducted for the C. elegans nervous system and the 9/11 terrorist network.
Feature-based Transferable Disruption Prediction for future tokamaks using domain adaptation
Sep 11, 2023



The high acquisition cost and the significant demand for disruptive discharges for data-driven disruption prediction models in future tokamaks pose an inherent contradiction in disruption prediction research. In this paper, we demonstrated a novel approach to predict disruption in a future tokamak only using a few discharges based on a domain adaptation algorithm called CORAL. It is the first attempt at applying domain adaptation in the disruption prediction task. In this paper, this disruption prediction approach aligns a few data from the future tokamak (target domain) and a large amount of data from the existing tokamak (source domain) to train a machine learning model in the existing tokamak. To simulate the existing and future tokamak case, we selected J-TEXT as the existing tokamak and EAST as the future tokamak. To simulate the lack of disruptive data in future tokamak, we only selected 100 non-disruptive discharges and 10 disruptive discharges from EAST as the target domain training data. We have improved CORAL to make it more suitable for the disruption prediction task, called supervised CORAL. Compared to the model trained by mixing data from the two tokamaks, the supervised CORAL model can enhance the disruption prediction performance for future tokamaks (AUC value from 0.764 to 0.890). Through interpretable analysis, we discovered that using the supervised CORAL enables the transformation of data distribution to be more similar to future tokamak. An assessment method for evaluating whether a model has learned a trend of similar features is designed based on SHAP analysis. It demonstrates that the supervised CORAL model exhibits more similarities to the model trained on large data sizes of EAST. FTDP provides a light, interpretable, and few-data-required way by aligning features to predict disruption using small data sizes from the future tokamak.
SAR2EO: A High-resolution Image Translation Framework with Denoising Enhancement
Apr 08, 2023



Synthetic Aperture Radar (SAR) to electro-optical (EO) image translation is a fundamental task in remote sensing that can enrich the dataset by fusing information from different sources. Recently, many methods have been proposed to tackle this task, but they are still difficult to complete the conversion from low-resolution images to high-resolution images. Thus, we propose a framework, SAR2EO, aiming at addressing this challenge. Firstly, to generate high-quality EO images, we adopt the coarse-to-fine generator, multi-scale discriminators, and improved adversarial loss in the pix2pixHD model to increase the synthesis quality. Secondly, we introduce a denoising module to remove the noise in SAR images, which helps to suppress the noise while preserving the structural information of the images. To validate the effectiveness of the proposed framework, we conduct experiments on the dataset of the Multi-modal Aerial View Imagery Challenge (MAVIC), which consists of large-scale SAR and EO image pairs. The experimental results demonstrate the superiority of our proposed framework, and we win the first place in the MAVIC held in CVPR PBVS 2023.
Disruption Precursor Onset Time Study Based on Semi-supervised Anomaly Detection
Mar 27, 2023



The full understanding of plasma disruption in tokamaks is currently lacking, and data-driven methods are extensively used for disruption prediction. However, most existing data-driven disruption predictors employ supervised learning techniques, which require labeled training data. The manual labeling of disruption precursors is a tedious and challenging task, as some precursors are difficult to accurately identify, limiting the potential of machine learning models. To address this issue, commonly used labeling methods assume that the precursor onset occurs at a fixed time before the disruption, which may not be consistent for different types of disruptions or even the same type of disruption, due to the different speeds at which plasma instabilities escalate. This leads to mislabeled samples and suboptimal performance of the supervised learning predictor. In this paper, we present a disruption prediction method based on anomaly detection that overcomes the drawbacks of unbalanced positive and negative data samples and inaccurately labeled disruption precursor samples. We demonstrate the effectiveness and reliability of anomaly detection predictors based on different algorithms on J-TEXT and EAST to evaluate the reliability of the precursor onset time inferred by the anomaly detection predictor. The precursor onset times inferred by these predictors reveal that the labeling methods have room for improvement as the onset times of different shots are not necessarily the same. Finally, we optimize precursor labeling using the onset times inferred by the anomaly detection predictor and test the optimized labels on supervised learning disruption predictors. The results on J-TEXT and EAST show that the models trained on the optimized labels outperform those trained on fixed onset time labels.
C3SASR: Cheap Causal Convolutions for Self-Attentive Sequential Recommendation
Nov 10, 2022Sequential Recommendation is a prominent topic in current research, which uses user behavior sequence as an input to predict future behavior. By assessing the correlation strength of historical behavior through the dot product, the model based on the self-attention mechanism can capture the long-term preference of the sequence. However, it has two limitations. On the one hand, it does not effectively utilize the items' local context information when determining the attention and creating the sequence representation. On the other hand, the convolution and linear layers often contain redundant information, which limits the ability to encode sequences. In this paper, we propose a self-attentive sequential recommendation model based on cheap causal convolution. It utilizes causal convolutions to capture items' local information for calculating attention and generating sequence embedding. It also uses cheap convolutions to improve the representations by lightweight structure. We evaluate the effectiveness of the proposed model in terms of both accurate and calibrated sequential recommendation. Experiments on benchmark datasets show that the proposed model can perform better in single- and multi-objective recommendation scenarios.
IDP-PGFE: An Interpretable Disruption Predictor based on Physics-Guided Feature Extraction
Aug 28, 2022
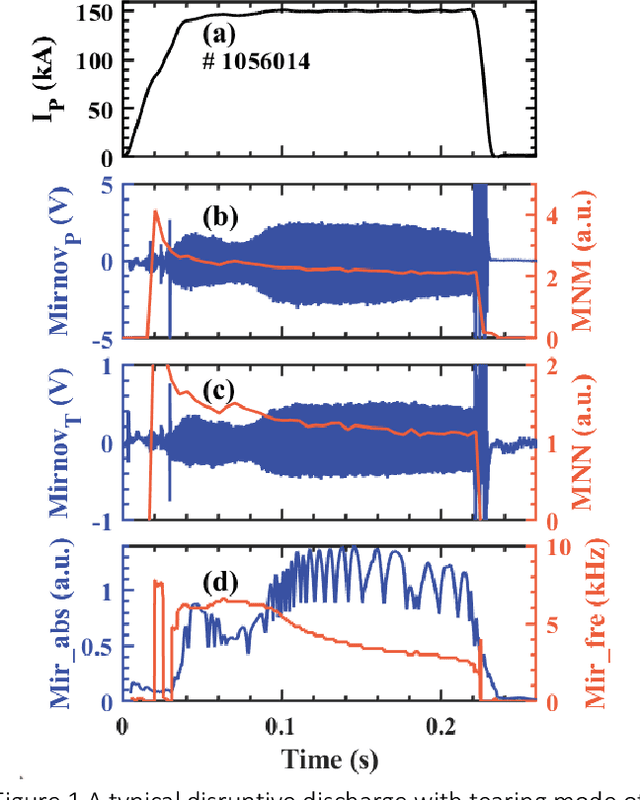
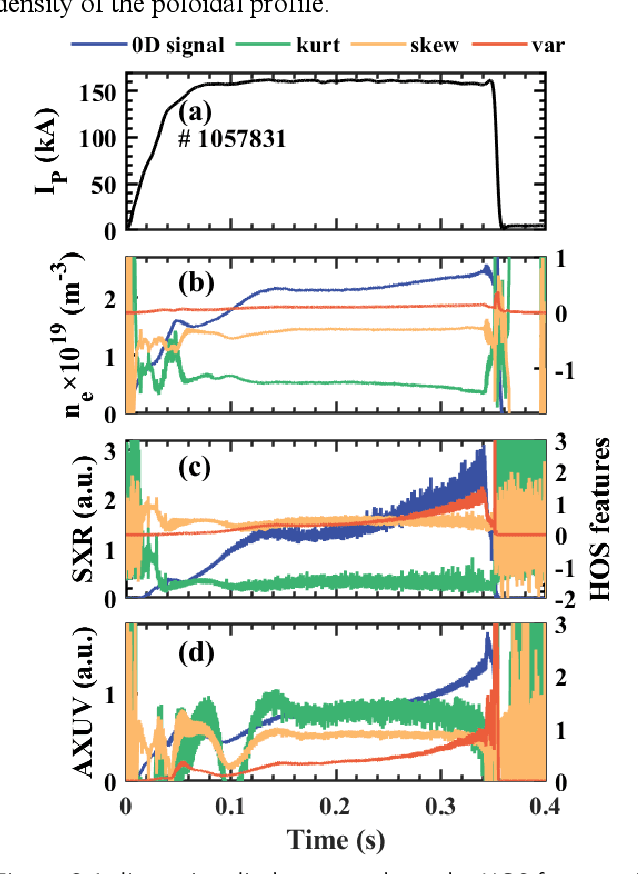

Disruption prediction has made rapid progress in recent years, especially in machine learning (ML)-based methods. Understanding why a predictor makes a certain prediction can be as crucial as the prediction's accuracy for future tokamak disruption predictors. The purpose of most disruption predictors is accuracy or cross-machine capability. However, if a disruption prediction model can be interpreted, it can tell why certain samples are classified as disruption precursors. This allows us to tell the types of incoming disruption and gives us insight into the mechanism of disruption. This paper designs a disruption predictor called Interpretable Disruption Predictor based On Physics-guided feature extraction (IDP-PGFE) on J-TEXT. The prediction performance of the model is effectively improved by extracting physics-guided features. A high-performance model is required to ensure the validity of the interpretation results. The interpretability study of IDP-PGFE provides an understanding of J-TEXT disruption and is generally consistent with existing comprehension of disruption. IDP-PGFE has been applied to the disruption due to continuously increasing density towards density limit experiments on J-TEXT. The time evolution of the PGFE features contribution demonstrates that the application of ECRH triggers radiation-caused disruption, which lowers the density at disruption. While the application of RMP indeed raises the density limit in J-TEXT. The interpretability study guides intuition on the physical mechanisms of density limit disruption that RMPs affect not only the MHD instabilities but also the radiation profile, which delays density limit disruption.
Transferable Cross-Tokamak Disruption Prediction with Deep Hybrid Neural Network Feature Extractor
Aug 20, 2022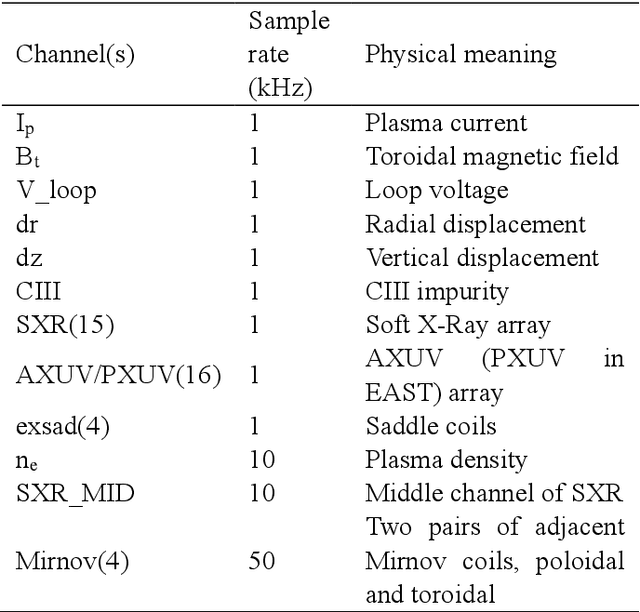
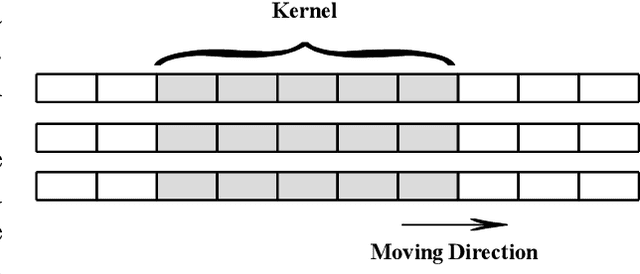

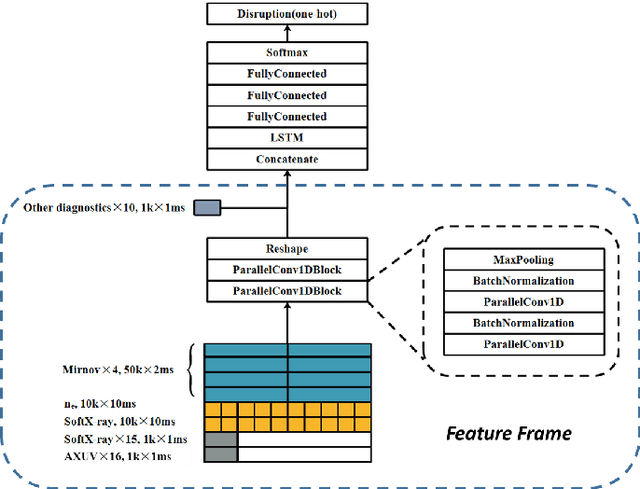
Predicting disruptions across different tokamaks is a great obstacle to overcome. Future tokamaks can hardly tolerate disruptions at high performance discharge. Few disruption discharges at high performance can hardly compose an abundant training set, which makes it difficult for current data-driven methods to obtain an acceptable result. A machine learning method capable of transferring a disruption prediction model trained on one tokamak to another is required to solve the problem. The key is a disruption prediction model containing a feature extractor that is able to extract common disruption precursor traces in tokamak diagnostic data, and a transferable disruption classifier. Based on the concerns above, the paper first presents a deep fusion feature extractor designed specifically for extracting disruption precursor features from common diagnostics on tokamaks according to currently known precursors of disruption, providing a promising foundation for transferable models. The fusion feature extractor is proved by comparing with manual feature extraction on J-TEXT. Based on the feature extractor trained on J-TEXT, the disruption prediction model was transferred to EAST data with mere 20 discharges from EAST experiment. The performance is comparable with a model trained with 1896 discharges from EAST. From the comparison among other model training scenarios, transfer learning showed its potential in predicting disruptions across different tokamaks.
DACSR: Dual-Aggregation End-to-End Calibrated Sequential Recommendation
Apr 29, 2022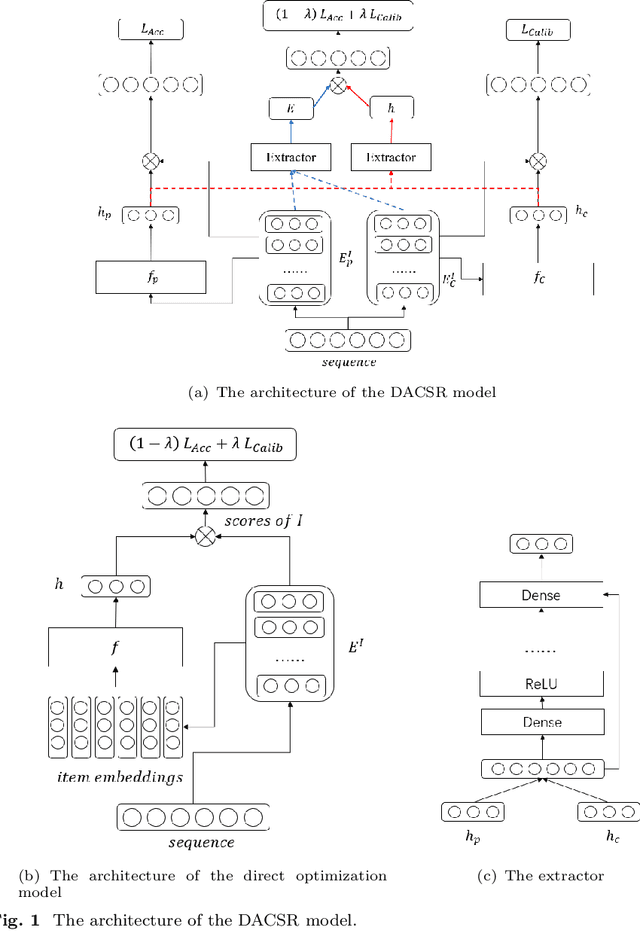
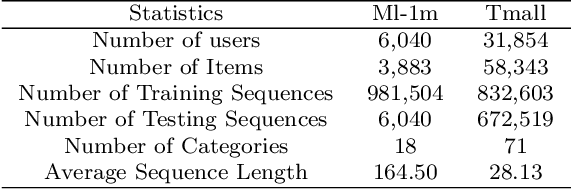
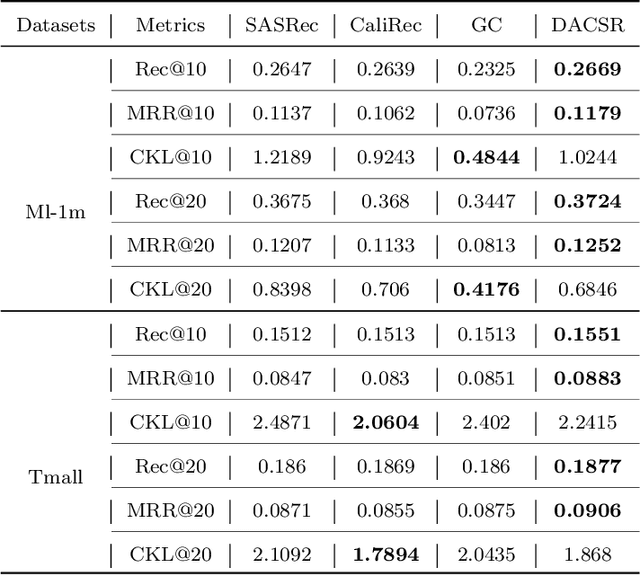
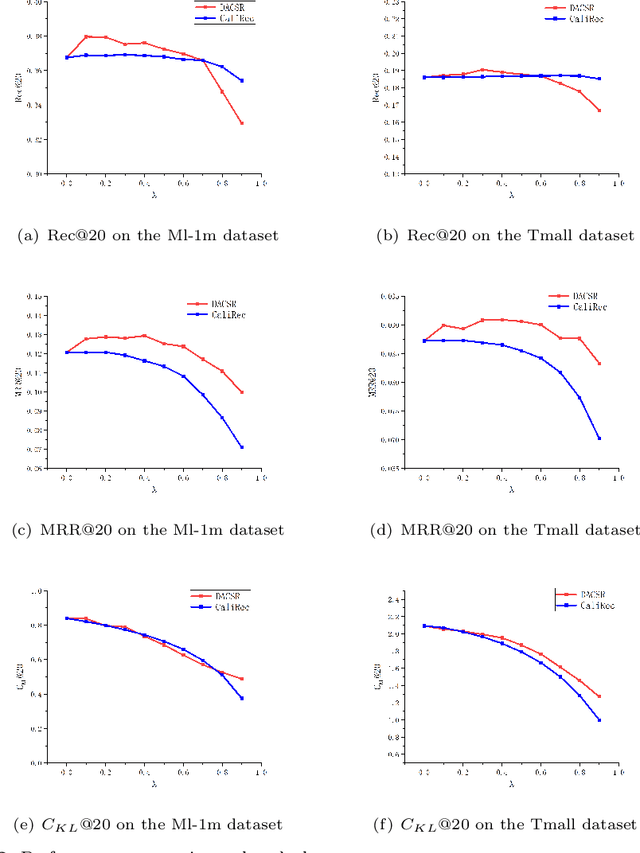
Recent years have witnessed the progress of sequential recommendation in accurately predicting users' future behaviors. However, only persuading accuracy leads to the risk of filter bubbles where recommenders only focus on users' main interest areas. Different from other studies which improve diversity or coverage, we investigate the calibration in sequential recommendation. However, existing calibrated methods followed a post-processing paradigm, which costs more computation time and sacrifices the recommendation accuracy. To this end, we propose an end-to-end framework to provide both accurate and calibrated recommendations. We propose a loss function to measure the divergence of distributions between recommendation lists and historical behaviors for sequential recommendation framework. In addition, we design a dual-aggregation model which extracts information from two individual sequence encoders with different objectives to further improve the recommendation. Experiments on two benchmark datasets demonstrate the effectiveness and efficiency of our model.
Long-Tail Session-based Recommendation from Calibration
Jan 02, 2022
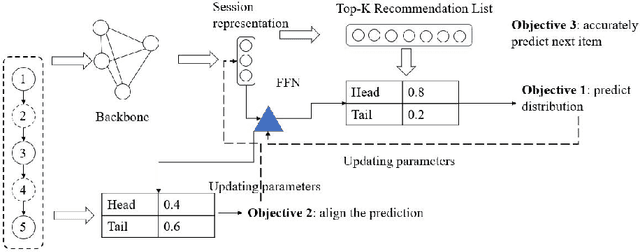
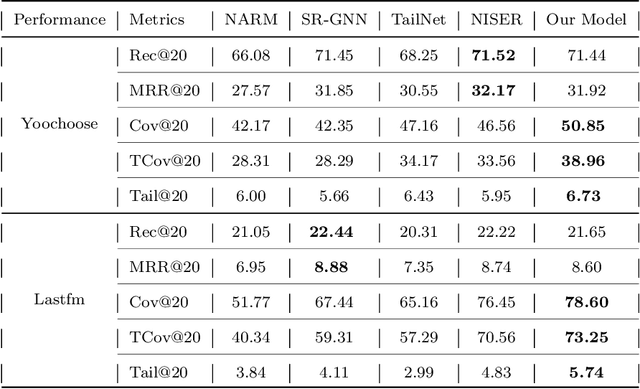
Accurate prediction in session-based recommendation has achieved progress, but skewed recommendation list caused by popularity bias is rarely investigated. Existing models on mitigating the popularity bias try to reduce the over-concentration on popular items but ignore the users' different preferences towards tail items. To this end, we incorporate calibration to mitigate the popularity bias in session-based recommendation. We propose a calibration module that can predict the distribution of the recommendation list and calibrate the recommendation list to the ongoing session. Meanwhile, a separate training and prediction strategy is applied to deal with the imbalance problem. Experiments on benchmark datasets show that our model can both achieve the competitive accuracy of recommendation and provide more tail items.
Subject-independent Human Pose Image Construction with Commodity Wi-Fi
Dec 22, 2020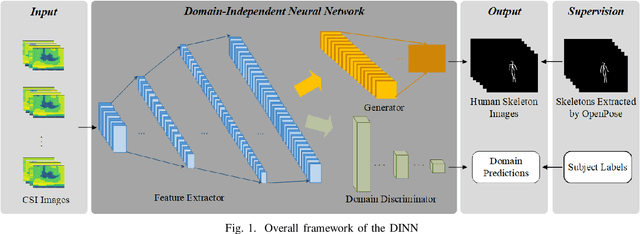

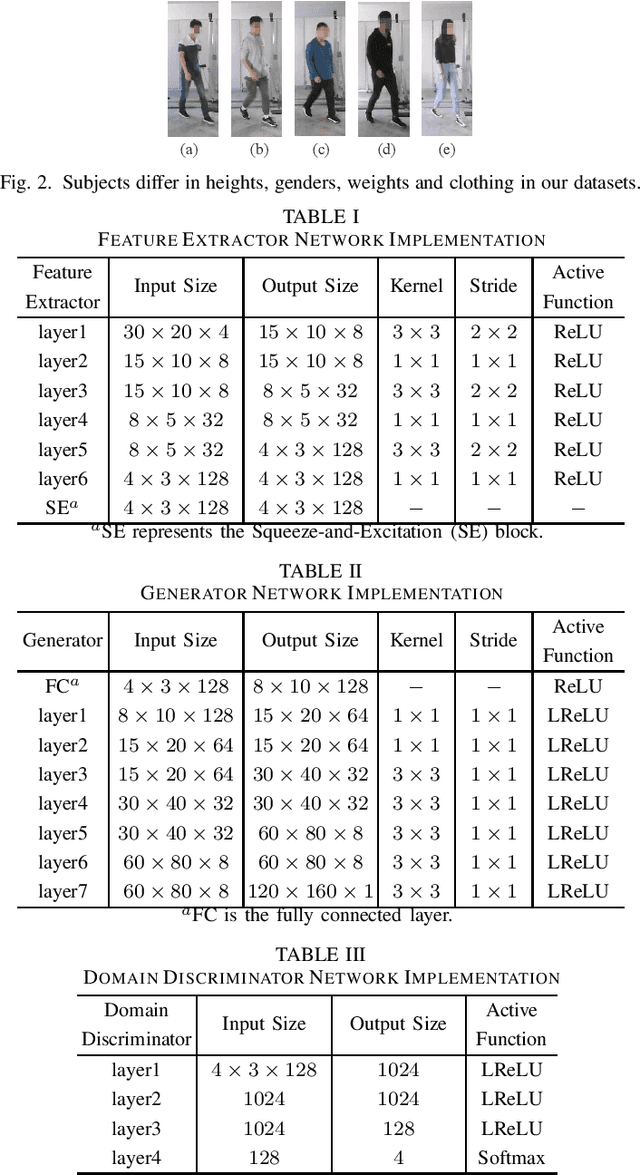
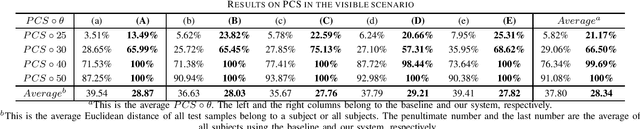
Recently, commodity Wi-Fi devices have been shown to be able to construct human pose images, i.e., human skeletons, as fine-grained as cameras. Existing papers achieve good results when constructing the images of subjects who are in the prior training samples. However, the performance drops when it comes to new subjects, i.e., the subjects who are not in the training samples. This paper focuses on solving the subject-generalization problem in human pose image construction. To this end, we define the subject as the domain. Then we design a Domain-Independent Neural Network (DINN) to extract subject-independent features and convert them into fine-grained human pose images. We also propose a novel training method to train the DINN and it has no re-training overhead comparing with the domain-adversarial approach. We build a prototype system and experimental results demonstrate that our system can construct fine-grained human pose images of new subjects with commodity Wi-Fi in both the visible and through-wall scenarios, which shows the effectiveness and the subject-generalization ability of our model.