 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature-based Transferable Disruption Prediction for future tokamaks using domain adaptation
Sep 11, 2023



The high acquisition cost and the significant demand for disruptive discharges for data-driven disruption prediction models in future tokamaks pose an inherent contradiction in disruption prediction research. In this paper, we demonstrated a novel approach to predict disruption in a future tokamak only using a few discharges based on a domain adaptation algorithm called CORAL. It is the first attempt at applying domain adaptation in the disruption prediction task. In this paper, this disruption prediction approach aligns a few data from the future tokamak (target domain) and a large amount of data from the existing tokamak (source domain) to train a machine learning model in the existing tokamak. To simulate the existing and future tokamak case, we selected J-TEXT as the existing tokamak and EAST as the future tokamak. To simulate the lack of disruptive data in future tokamak, we only selected 100 non-disruptive discharges and 10 disruptive discharges from EAST as the target domain training data. We have improved CORAL to make it more suitable for the disruption prediction task, called supervised CORAL. Compared to the model trained by mixing data from the two tokamaks, the supervised CORAL model can enhance the disruption prediction performance for future tokamaks (AUC value from 0.764 to 0.890). Through interpretable analysis, we discovered that using the supervised CORAL enables the transformation of data distribution to be more similar to future tokamak. An assessment method for evaluating whether a model has learned a trend of similar features is designed based on SHAP analysis. It demonstrates that the supervised CORAL model exhibits more similarities to the model trained on large data sizes of EAST. FTDP provides a light, interpretable, and few-data-required way by aligning features to predict disruption using small data sizes from the future tokamak.
Disruption Precursor Onset Time Study Based on Semi-supervised Anomaly Detection
Mar 27, 2023



The full understanding of plasma disruption in tokamaks is currently lacking, and data-driven methods are extensively used for disruption prediction. However, most existing data-driven disruption predictors employ supervised learning techniques, which require labeled training data. The manual labeling of disruption precursors is a tedious and challenging task, as some precursors are difficult to accurately identify, limiting the potential of machine learning models. To address this issue, commonly used labeling methods assume that the precursor onset occurs at a fixed time before the disruption, which may not be consistent for different types of disruptions or even the same type of disruption, due to the different speeds at which plasma instabilities escalate. This leads to mislabeled samples and suboptimal performance of the supervised learning predictor. In this paper, we present a disruption prediction method based on anomaly detection that overcomes the drawbacks of unbalanced positive and negative data samples and inaccurately labeled disruption precursor samples. We demonstrate the effectiveness and reliability of anomaly detection predictors based on different algorithms on J-TEXT and EAST to evaluate the reliability of the precursor onset time inferred by the anomaly detection predictor. The precursor onset times inferred by these predictors reveal that the labeling methods have room for improvement as the onset times of different shots are not necessarily the same. Finally, we optimize precursor labeling using the onset times inferred by the anomaly detection predictor and test the optimized labels on supervised learning disruption predictors. The results on J-TEXT and EAST show that the models trained on the optimized labels outperform those trained on fixed onset time labels.
Transferable Cross-Tokamak Disruption Prediction with Deep Hybrid Neural Network Feature Extractor
Aug 20, 2022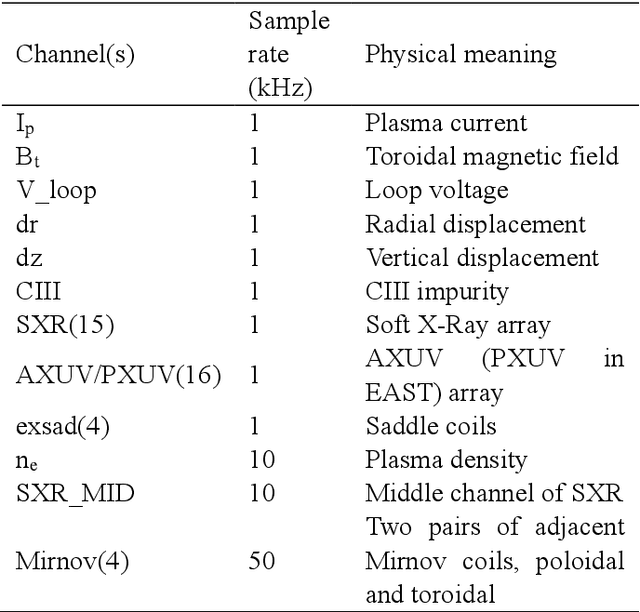

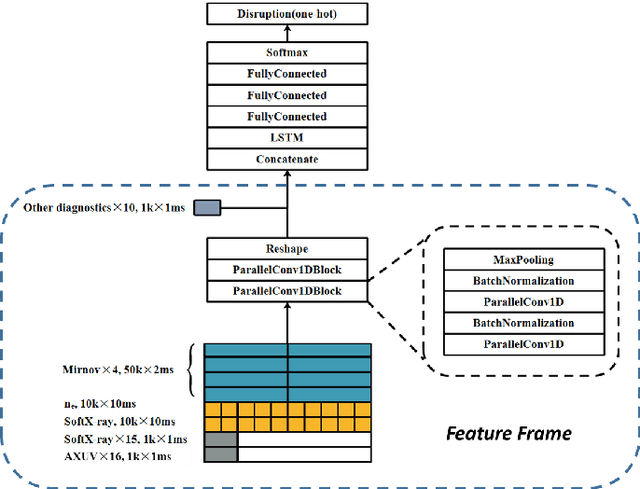
Predicting disruptions across different tokamaks is a great obstacle to overcome. Future tokamaks can hardly tolerate disruptions at high performance discharge. Few disruption discharges at high performance can hardly compose an abundant training set, which makes it difficult for current data-driven methods to obtain an acceptable result. A machine learning method capable of transferring a disruption prediction model trained on one tokamak to another is required to solve the problem. The key is a disruption prediction model containing a feature extractor that is able to extract common disruption precursor traces in tokamak diagnostic data, and a transferable disruption classifier. Based on the concerns above, the paper first presents a deep fusion feature extractor designed specifically for extracting disruption precursor features from common diagnostics on tokamaks according to currently known precursors of disruption, providing a promising foundation for transferable models. The fusion feature extractor is proved by comparing with manual feature extraction on J-TEXT. Based on the feature extractor trained on J-TEXT, the disruption prediction model was transferred to EAST data with mere 20 discharges from EAST experiment. The performance is comparable with a model trained with 1896 discharges from EAST. From the comparison among other model training scenarios, transfer learning showed its potential in predicting disruptions across different tokamaks.