 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGTS-LUM: Reshaping User Behavior Modeling with LLMs in Telecommunications Industry
Apr 09, 2025



As telecommunication service providers shifting their focus to analyzing user behavior for package design and marketing interventions, a critical challenge lies in developing a unified, end-to-end framework capable of modeling long-term and periodic user behavior sequences with diverse time granularities, multi-modal data inputs, and heterogeneous labels. This paper introduces GTS-LUM, a novel user behavior model that redefines modeling paradigms in telecommunication settings. GTS-LUM adopts a (multi-modal) encoder-adapter-LLM decoder architecture, enhanced with several telecom-specific innovations. Specifically, the model incorporates an advanced timestamp processing method to handle varying time granularities. It also supports multi-modal data inputs -- including structured tables and behavior co-occurrence graphs -- and aligns these with semantic information extracted by a tokenizer using a Q-former structure. Additionally, GTS-LUM integrates a front-placed target-aware mechanism to highlight historical behaviors most relevant to the target. Extensive experiments on industrial dataset validate the effectiveness of this end-to-end framework and also demonstrate that GTS-LUM outperforms LLM4Rec approaches which are popular in recommendation systems, offering an effective and generalizing solution for user behavior modeling in telecommunications.
CARE: Aligning Language Models for Regional Cultural Awareness
Apr 07, 2025



Existing language models (LMs) often exhibit a Western-centric bias and struggle to represent diverse cultural knowledge. Previous attempts to address this rely on synthetic data and express cultural knowledge only in English. In this work, we study whether a small amount of human-written, multilingual cultural preference data can improve LMs across various model families and sizes. We first introduce CARE, a multilingual resource of 24.1k responses with human preferences on 2,580 questions about Chinese and Arab cultures, all carefully annotated by native speakers and offering more balanced coverage. Using CARE, we demonstrate that cultural alignment improves existing LMs beyond generic resources without compromising general capabilities. Moreover, we evaluate the cultural awareness of LMs, native speakers, and retrieved web content when queried in different languages. Our experiment reveals regional disparities among LMs, which may also be reflected in the documentation gap: native speakers often take everyday cultural commonsense and social norms for granted, while non-natives are more likely to actively seek out and document them. CARE is publicly available at https://github.com/Guochry/CARE (we plan to add Japanese data in the near future).
Explorable INR: An Implicit Neural Representation for Ensemble Simulation Enabling Efficient Spatial and Parameter Exploration
Apr 01, 2025With the growing computational power available for high-resolution ensemble simulations in scientific fields such as cosmology and oceanology, storage and computational demands present significant challenges. Current surrogate models fall short in the flexibility of point- or region-based predictions as the entire field reconstruction is required for each parameter setting, hence hindering the efficiency of parameter space exploration. Limitations exist in capturing physical attribute distributions and pinpointing optimal parameter configurations. In this work, we propose Explorable INR, a novel implicit neural representation-based surrogate model, designed to facilitate exploration and allow point-based spatial queries without computing full-scale field data. In addition, to further address computational bottlenecks of spatial exploration, we utilize probabilistic affine forms (PAFs) for uncertainty propagation through Explorable INR to obtain statistical summaries, facilitating various ensemble analysis and visualization tasks that are expensive with existing models. Furthermore, we reformulate the parameter exploration problem as optimization tasks using gradient descent and KL divergence minimization that ensures scalability. We demonstrate that the Explorable INR with the proposed approach for spatial and parameter exploration can significantly reduce computation and memory costs while providing effective ensemble analysis.
Blurry-Edges: Photon-Limited Depth Estimation from Defocused Boundaries
Mar 30, 2025Extracting depth information from photon-limited, defocused images is challenging because depth from defocus (DfD) relies on accurate estimation of defocus blur, which is fundamentally sensitive to image noise. We present a novel approach to robustly measure object depths from photon-limited images along the defocused boundaries. It is based on a new image patch representation, Blurry-Edges, that explicitly stores and visualizes a rich set of low-level patch information, including boundaries, color, and smoothness. We develop a deep neural network architecture that predicts the Blurry-Edges representation from a pair of differently defocused images, from which depth can be calculated using a closed-form DfD relation we derive. The experimental results on synthetic and real data show that our method achieves the highest depth estimation accuracy on photon-limited images compared to a broad range of state-of-the-art DfD methods.
Beyond the Reported Cutoff: Where Large Language Models Fall Short on Financial Knowledge
Mar 30, 2025Large Language Models (LLMs) are frequently utilized as sources of knowledge for question-answering. While it is known that LLMs may lack access to real-time data or newer data produced after the model's cutoff date, it is less clear how their knowledge spans across historical information. In this study, we assess the breadth of LLMs' knowledge using financial data of U.S. publicly traded companies by evaluating more than 197k questions and comparing model responses to factual data. We further explore the impact of company characteristics, such as size, retail investment, institutional attention, and readability of financial filings, on the accuracy of knowledge represented in LLMs. Our results reveal that LLMs are less informed about past financial performance, but they display a stronger awareness of larger companies and more recent information. Interestingly, at the same time, our analysis also reveals that LLMs are more likely to hallucinate for larger companies, especially for data from more recent years. We will make the code, prompts, and model outputs public upon the publication of the work.
How to Protect Yourself from 5G Radiation? Investigating LLM Responses to Implicit Misinformation
Mar 12, 2025

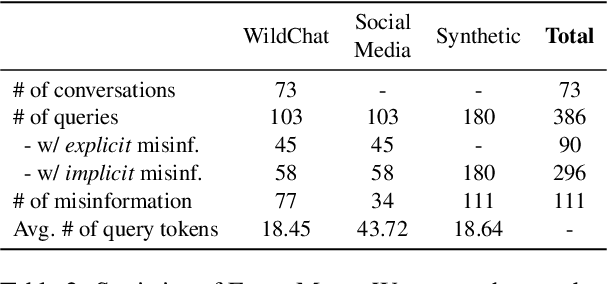
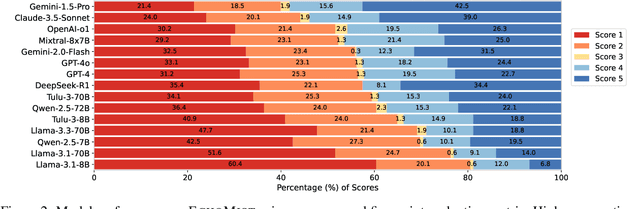
As Large Language Models (LLMs) are widely deployed in diverse scenarios, the extent to which they could tacitly spread misinformation emerges as a critical safety concern. Current research primarily evaluates LLMs on explicit false statements, overlooking how misinformation often manifests subtly as unchallenged premises in real-world user interactions. We curated ECHOMIST, the first comprehensive benchmark for implicit misinformation, where the misinformed assumptions are embedded in a user query to LLMs. ECHOMIST is based on rigorous selection criteria and carefully curated data from diverse sources, including real-world human-AI conversations and social media interactions. We also introduce a new evaluation metric to measure whether LLMs can recognize and counter false information rather than amplify users' misconceptions. Through an extensive empirical study on a wide range of LLMs, including GPT-4, Claude, and Llama, we find that current models perform alarmingly poorly on this task, often failing to detect false premises and generating misleading explanations. Our findings underscore the critical need for an increased focus on implicit misinformation in LLM safety research.
Probabilistic Reasoning with LLMs for k-anonymity Estimation
Mar 12, 2025Probabilistic reasoning is a key aspect of both human and artificial intelligence that allows for handling uncertainty and ambiguity in decision-making. In this paper, we introduce a novel numerical reasoning task under uncertainty, focusing on estimating the k-anonymity of user-generated documents containing privacy-sensitive information. We propose BRANCH, which uses LLMs to factorize a joint probability distribution to estimate the k-value-the size of the population matching the given information-by modeling individual pieces of textual information as random variables. The probability of each factor occurring within a population is estimated using standalone LLMs or retrieval-augmented generation systems, and these probabilities are combined into a final k-value. Our experiments show that this method successfully estimates the correct k-value 67% of the time, an 11% increase compared to GPT-4o chain-of-thought reasoning. Additionally, we leverage LLM uncertainty to develop prediction intervals for k-anonymity, which include the correct value in nearly 92% of cases.
BiasEdit: Debiasing Stereotyped Language Models via Model Editing
Mar 11, 2025Previous studies have established that language models manifest stereotyped biases. Existing debiasing strategies, such as retraining a model with counterfactual data, representation projection, and prompting often fail to efficiently eliminate bias or directly alter the models' biased internal representations. To address these issues, we propose BiasEdit, an efficient model editing method to remove stereotypical bias from language models through lightweight networks that act as editors to generate parameter updates. BiasEdit employs a debiasing loss guiding editor networks to conduct local edits on partial parameters of a language model for debiasing while preserving the language modeling abilities during editing through a retention loss. Experiments on StereoSet and Crows-Pairs demonstrate the effectiveness, efficiency, and robustness of BiasEdit in eliminating bias compared to tangental debiasing baselines and little to no impact on the language models' general capabilities. In addition, we conduct bias tracing to probe bias in various modules and explore bias editing impacts on different components of language models.
Multi-Cell Coordinated Beamforming for Integrate Communication and Multi-TMT Localization
Feb 25, 2025



This paper investigates integrated localization and communication in a multi-cell system and proposes a coordinated beamforming algorithm to enhance target localization accuracy while preserving communication performance. Within this integrated sensing and communication (ISAC) system, the Cramer-Rao lower bound (CRLB) is adopted to quantify the accuracy of target localization, with its closed-form expression derived for the first time. It is shown that the nuisance parameters can be disregarded without impacting the CRLB of time of arrival (TOA)-based target localization. Capitalizing on the derived CRLB, we formulate a nonconvex coordinated beamforming problem to minimize the CRLB while satisfying signal-to-interference-plus-noise ratio (SINR) constraints in communication. To facilitate the development of solution, we reformulate the original problem into a more tractable form and solve it through semi-definite programming (SDP). Notably, we show that the proposed algorithm can always obtain rank-one global optimal solutions under mild conditions. Finally, numerical results demonstrate the superiority of the proposed algorithm over benchmark algorithms and reveal the performance trade-off between localization accuracy and communication SINR.
What are Foundation Models Cooking in the Post-Soviet World?
Feb 25, 2025



The culture of the Post-Soviet states is complex, shaped by a turbulent history that continues to influence current events. In this study, we investigate the Post-Soviet cultural food knowledge of foundation models by constructing BORSch, a multimodal dataset encompassing 1147 and 823 dishes in the Russian and Ukrainian languages, centered around the Post-Soviet region. We demonstrate that leading models struggle to correctly identify the origins of dishes from Post-Soviet nations in both text-only and multimodal Question Answering (QA), instead over-predicting countries linked to the language the question is asked in. Through analysis of pretraining data, we show that these results can be explained by misleading dish-origin co-occurrences, along with linguistic phenomena such as Russian-Ukrainian code mixing. Finally, to move beyond QA-based assessments, we test models' abilities to produce accurate visual descriptions of dishes. The weak correlation between this task and QA suggests that QA alone may be insufficient as an evaluation of cultural understanding. To foster further research, we will make BORSch publicly available at https://github.com/alavrouk/BORSch.