 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly Detection of Particle Orbit in Accelerator using LSTM Deep Learning Technology
Jan 28, 2024A stable, reliable, and controllable orbit lock system is crucial to an electron (or ion) accelerator because the beam orbit and beam energy instability strongly affect the quality of the beam delivered to experimental halls. Currently, when the orbit lock system fails operators must manually intervene. This paper develops a Machine Learning based fault detection methodology to identify orbit lock anomalies and notify accelerator operations staff of the off-normal behavior. Our method is unsupervised, so it does not require labeled data. It uses Long-Short Memory Networks (LSTM) Auto Encoder to capture normal patterns and predict future values of monitoring sensors in the orbit lock system. Anomalies are detected when the prediction error exceeds a threshold. We conducted experiments using monitoring data from Jefferson Lab's Continuous Electron Beam Accelerator Facility (CEBAF). The results are promising: the percentage of real anomalies identified by our solution is 68.6%-89.3% using monitoring data of a single component in the orbit lock control system. The accuracy can be as high as 82%.
Online estimation of the inverse of the Hessian for stochastic optimization with application to universal stochastic Newton algorithms
Jan 15, 2024This paper addresses second-order stochastic optimization for estimating the minimizer of a convex function written as an expectation. A direct recursive estimation technique for the inverse Hessian matrix using a Robbins-Monro procedure is introduced. This approach enables to drastically reduces computational complexity. Above all, it allows to develop universal stochastic Newton methods and investigate the asymptotic efficiency of the proposed approach. This work so expands the application scope of secondorder algorithms in stochastic optimization.
TinyLlama: An Open-Source Small Language Model
Jan 04, 2024



We present TinyLlama, a compact 1.1B language model pretrained on around 1 trillion tokens for approximately 3 epochs. Building on the architecture and tokenizer of Llama 2, TinyLlama leverages various advances contributed by the open-source community (e.g., FlashAttention), achieving better computational efficiency. Despite its relatively small size, TinyLlama demonstrates remarkable performance in a series of downstream tasks. It significantly outperforms existing open-source language models with comparable sizes. Our model checkpoints and code are publicly available on GitHub at https://github.com/jzhang38/TinyLlama.
Tell2Design: A Dataset for Language-Guided Floor Plan Generation
Nov 27, 2023We consider the task of generating designs directly from natural language descriptions, and consider floor plan generation as the initial research area. Language conditional generative models have recently been very successful in generating high-quality artistic images. However, designs must satisfy different constraints that are not present in generating artistic images, particularly spatial and relational constraints. We make multiple contributions to initiate research on this task. First, we introduce a novel dataset, \textit{Tell2Design} (T2D), which contains more than $80k$ floor plan designs associated with natural language instructions. Second, we propose a Sequence-to-Sequence model that can serve as a strong baseline for future research. Third, we benchmark this task with several text-conditional image generation models. We conclude by conducting human evaluations on the generated samples and providing an analysis of human performance. We hope our contributions will propel the research on language-guided design generation forward.
Disentangling the Potential Impacts of Papers into Diffusion, Conformity, and Contribution Values
Nov 15, 2023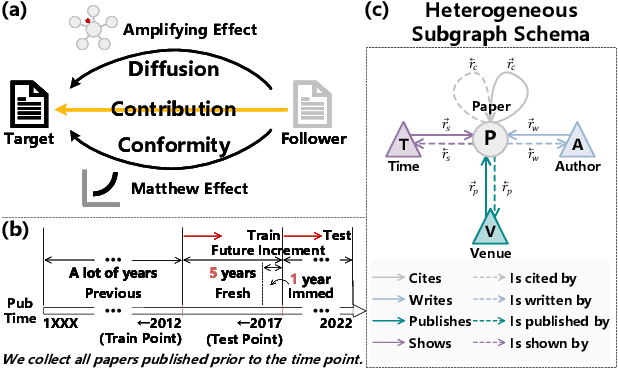
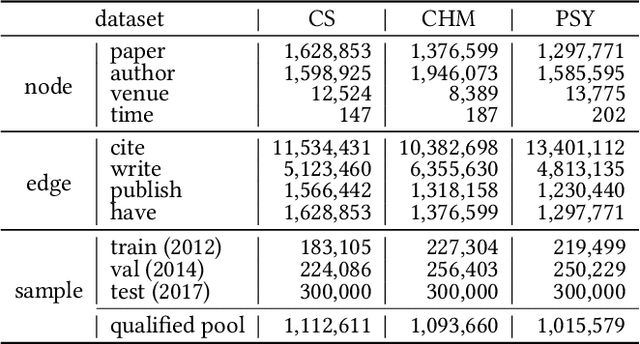
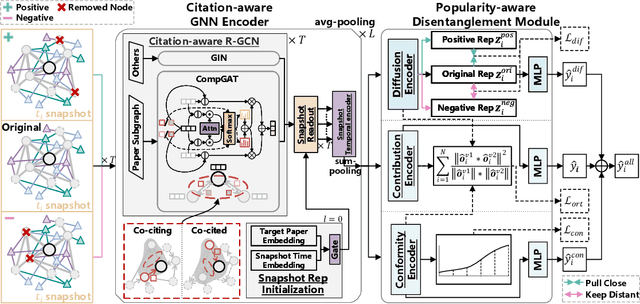
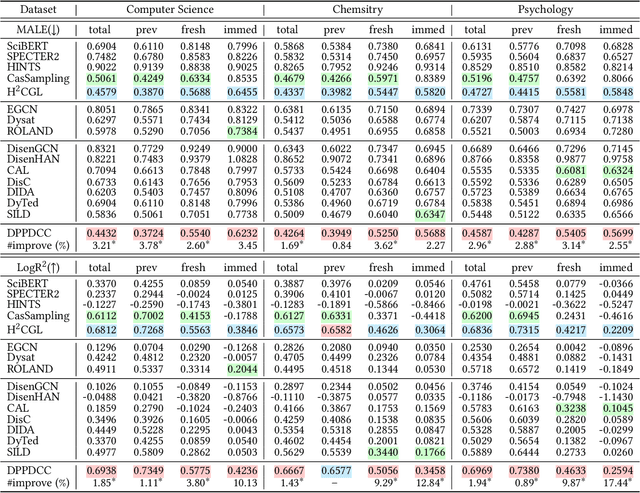
The potential impact of an academic paper is determined by various factors, including its popularity and contribution. Existing models usually estimate original citation counts based on static graphs and fail to differentiate values from nuanced perspectives. In this study, we propose a novel graph neural network to Disentangle the Potential impacts of Papers into Diffusion, Conformity, and Contribution values (called DPPDCC). Given a target paper, DPPDCC encodes temporal and structural features within the constructed dynamic heterogeneous graph. Particularly, to capture the knowledge flow, we emphasize the importance of comparative and co-cited/citing information between papers and aggregate snapshots evolutionarily. To unravel popularity, we contrast augmented graphs to extract the essence of diffusion and predict the accumulated citation binning to model conformity. We further apply orthogonal constraints to encourage distinct modeling of each perspective and preserve the inherent value of contribution. To evaluate models' generalization for papers published at various times, we reformulate the problem by partitioning data based on specific time points to mirror real-world conditions. Extensive experimental results on three datasets demonstrate that DPPDCC significantly outperforms baselines for previously, freshly, and immediately published papers. Further analyses confirm its robust capabilities. We will make our datasets and codes publicly available.
Unraveling Feature Extraction Mechanisms in Neural Networks
Oct 26, 2023



The underlying mechanism of neural networks in capturing precise knowledge has been the subject of consistent research efforts. In this work, we propose a theoretical approach based on Neural Tangent Kernels (NTKs) to investigate such mechanisms. Specifically, considering the infinite network width, we hypothesize the learning dynamics of target models may intuitively unravel the features they acquire from training data, deepening our insights into their internal mechanisms. We apply our approach to several fundamental models and reveal how these models leverage statistical features during gradient descent and how they are integrated into final decisions. We also discovered that the choice of activation function can affect feature extraction. For instance, the use of the \textit{ReLU} activation function could potentially introduce a bias in features, providing a plausible explanation for its replacement with alternative functions in recent pre-trained language models. Additionally, we find that while self-attention and CNN models may exhibit limitations in learning n-grams, multiplication-based models seem to excel in this area. We verify these theoretical findings through experiments and find that they can be applied to analyze language modeling tasks, which can be regarded as a special variant of classification. Our contributions offer insights into the roles and capacities of fundamental components within large language models, thereby aiding the broader understanding of these complex systems.
Tuna: Instruction Tuning using Feedback from Large Language Models
Oct 20, 2023Instruction tuning of open-source large language models (LLMs) like LLaMA, using direct outputs from more powerful LLMs such as Instruct-GPT and GPT-4, has proven to be a cost-effective way to align model behaviors with human preferences. However, the instruction-tuned model has only seen one response per instruction, lacking the knowledge of potentially better responses. In this paper, we propose finetuning an instruction-tuned LLM using our novel \textit{probabilistic ranking} and \textit{contextual ranking} approaches to increase the likelihood of generating better responses. Probabilistic ranking enables the instruction-tuned model to inherit the relative rankings of high-quality and low-quality responses from the teacher LLM. On the other hand, learning with contextual ranking allows the model to refine its own response distribution using the contextual understanding ability of stronger LLMs. Furthermore, we apply probabilistic ranking and contextual ranking sequentially to the instruction-tuned LLM. The resulting model, which we call \textbf{Tuna}, consistently improves the performance on Super Natural Instructions (119 test tasks), LMentry (25 test tasks), Vicuna QA, and can even obtain better results than several strong reinforcement learning baselines. Our code and data are available at \url{ https://github.com/microsoft/LMOps}.
Know Where to Go: Make LLM a Relevant, Responsible, and Trustworthy Searcher
Oct 19, 2023The advent of Large Language Models (LLMs) has shown the potential to improve relevance and provide direct answers in web searches. However, challenges arise in validating the reliability of generated results and the credibility of contributing sources, due to the limitations of traditional information retrieval algorithms and the LLM hallucination problem. Aiming to create a "PageRank" for the LLM era, we strive to transform LLM into a relevant, responsible, and trustworthy searcher. We propose a novel generative retrieval framework leveraging the knowledge of LLMs to foster a direct link between queries and online sources. This framework consists of three core modules: Generator, Validator, and Optimizer, each focusing on generating trustworthy online sources, verifying source reliability, and refining unreliable sources, respectively. Extensive experiments and evaluations highlight our method's superior relevance, responsibility, and trustfulness against various SOTA methods.
Decomposed Prompt Tuning via Low-Rank Reparameterization
Oct 16, 2023



While prompt tuning approaches have achieved competitive performance with high efficiency, we observe that they invariably employ the same initialization process, wherein the soft prompt is either randomly initialized or derived from an existing embedding vocabulary. In contrast to these conventional methods, this study aims to investigate an alternative way to derive soft prompt. Our empirical studies show that the soft prompt typically exhibits a low intrinsic rank characteristic. With such observations, we propose decomposed prompt tuning, a novel approach that utilizes low-rank matrices to initialize the soft prompt. Through the low-rank reparameterization, our method significantly reduces the number of trainable parameters while maintaining effectiveness. Experimental results on the SuperGLUE benchmark in both high-resource and low-resource scenarios demonstrate the effectiveness of the proposed method.
Create and Find Flatness: Building Flat Training Spaces in Advance for Continual Learning
Sep 20, 2023Catastrophic forgetting remains a critical challenge in the field of continual learning, where neural networks struggle to retain prior knowledge while assimilating new information. Most existing studies emphasize mitigating this issue only when encountering new tasks, overlooking the significance of the pre-task phase. Therefore, we shift the attention to the current task learning stage, presenting a novel framework, C&F (Create and Find Flatness), which builds a flat training space for each task in advance. Specifically, during the learning of the current task, our framework adaptively creates a flat region around the minimum in the loss landscape. Subsequently, it finds the parameters' importance to the current task based on their flatness degrees. When adapting the model to a new task, constraints are applied according to the flatness and a flat space is simultaneously prepared for the impending task. We theoretically demonstrate the consistency between the created and found flatness. In this manner, our framework not only accommodates ample parameter space for learning new tasks but also preserves the preceding knowledge of earlier tasks. Experimental results exhibit C&F's state-of-the-art performance as a standalone continual learning approach and its efficacy as a framework incorporating other methods. Our work is available at https://github.com/Eric8932/Create-and-Find-Flatness.