 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKiloBot: A Programming Language for Deploying Perception-Guided Industrial Manipulators at Scale
Sep 05, 2024We would like industrial robots to handle unstructured environments with cameras and perception pipelines. In contrast to traditional industrial robots that replay offline-crafted trajectories, online behavior planning is required for these perception-guided industrial applications. Aside from perception and planning algorithms, deploying perception-guided manipulators also requires substantial effort in integration. One approach is writing scripts in a traditional language (such as Python) to construct the planning problem and perform integration with other algorithmic modules & external devices. While scripting in Python is feasible for a handful of robots and applications, deploying perception-guided manipulation at scale (e.g., more than 10000 robot workstations in over 2000 customer sites) becomes intractable. To resolve this challenge, we propose a Domain-Specific Language (DSL) for perception-guided manipulation applications. To scale up the deployment,our DSL provides: 1) an easily accessible interface to construct & solve a sub-class of Task and Motion Planning (TAMP) problems that are important in practical applications; and 2) a mechanism to implement flexible control flow to perform integration and address customized requirements of distinct industrial application. Combined with an intuitive graphical programming frontend, our DSL is mainly used by machine operators without coding experience in traditional programming languages. Within hours of training, operators are capable of orchestrating interesting sophisticated manipulation behaviors with our DSL. Extensive practical deployments demonstrate the efficacy of our method.
E-Bench: Subjective-Aligned Benchmark Suite for Text-Driven Video Editing Quality Assessment
Aug 21, 2024
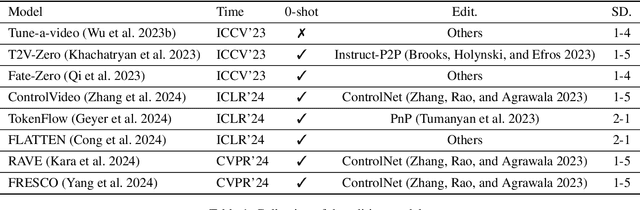
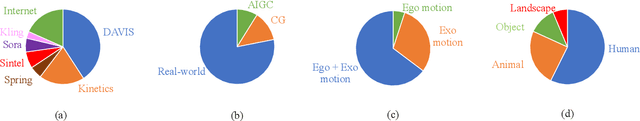
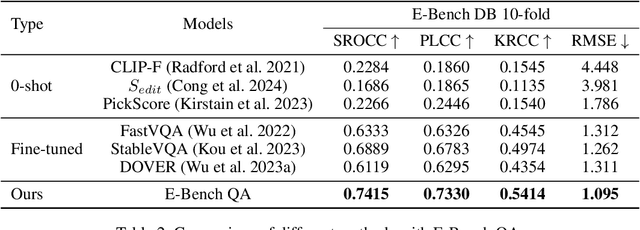
Text-driven video editing has recently experienced rapid development. Despite this, evaluating edited videos remains a considerable challenge. Current metrics tend to fail to align with human perceptions, and effective quantitative metrics for video editing are still notably absent. To address this, we introduce E-Bench, a benchmark suite tailored to the assessment of text-driven video editing. This suite includes E-Bench DB, a video quality assessment (VQA) database for video editing. E-Bench DB encompasses a diverse set of source videos featuring various motions and subjects, along with multiple distinct editing prompts, editing results from 8 different models, and the corresponding Mean Opinion Scores (MOS) from 24 human annotators. Based on E-Bench DB, we further propose E-Bench QA, a quantitative human-aligned measurement for the text-driven video editing task. In addition to the aesthetic, distortion, and other visual quality indicators that traditional VQA methods emphasize, E-Bench QA focuses on the text-video alignment and the relevance modeling between source and edited videos. It proposes a new assessment network for video editing that attains superior performance in alignment with human preferences. To the best of our knowledge, E-Bench introduces the first quality assessment dataset for video editing and an effective subjective-aligned quantitative metric for this domain. All data and code will be publicly available at https://github.com/littlespray/E-Bench.
LLM-PCGC: Large Language Model-based Point Cloud Geometry Compression
Aug 16, 2024



The key to effective point cloud compression is to obtain a robust context model consistent with complex 3D data structures. Recently, the advancement of large language models (LLMs) has highlighted their capabilities not only as powerful generators for in-context learning and generation but also as effective compressors. These dual attributes of LLMs make them particularly well-suited to meet the demands of data compression. Therefore, this paper explores the potential of using LLM for compression tasks, focusing on lossless point cloud geometry compression (PCGC) experiments. However, applying LLM directly to PCGC tasks presents some significant challenges, i.e., LLM does not understand the structure of the point cloud well, and it is a difficult task to fill the gap between text and point cloud through text description, especially for large complicated and small shapeless point clouds. To address these problems, we introduce a novel architecture, namely the Large Language Model-based Point Cloud Geometry Compression (LLM-PCGC) method, using LLM to compress point cloud geometry information without any text description or aligning operation. By utilizing different adaptation techniques for cross-modality representation alignment and semantic consistency, including clustering, K-tree, token mapping invariance, and Low Rank Adaptation (LoRA), the proposed method can translate LLM to a compressor/generator for point cloud. To the best of our knowledge, this is the first structure to employ LLM as a compressor for point cloud data. Experiments demonstrate that the LLM-PCGC outperforms the other existing methods significantly, by achieving -40.213% bit rate reduction compared to the reference software of MPEG Geometry-based Point Cloud Compression (G-PCC) standard, and by achieving -2.267% bit rate reduction compared to the state-of-the-art learning-based method.
Active Loop Closure for OSM-guided Robotic Mapping in Large-Scale Urban Environments
Jul 24, 2024



The autonomous mapping of large-scale urban scenes presents significant challenges for autonomous robots. To mitigate the challenges, global planning, such as utilizing prior GPS trajectories from OpenStreetMap (OSM), is often used to guide the autonomous navigation of robots for mapping. However, due to factors like complex terrain, unexpected body movement, and sensor noise, the uncertainty of the robot's pose estimates inevitably increases over time, ultimately leading to the failure of robotic mapping. To address this issue, we propose a novel active loop closure procedure, enabling the robot to actively re-plan the previously planned GPS trajectory. The method can guide the robot to re-visit the previous places where the loop-closure detection can be performed to trigger the back-end optimization, effectively reducing errors and uncertainties in pose estimation. The proposed active loop closure mechanism is implemented and embedded into a real-time OSM-guided robot mapping framework. Empirical results on several large-scale outdoor scenarios demonstrate its effectiveness and promising performance.
Power Optimization and Deep Learning for Channel Estimation of Active IRS-Aided IoT
Jul 12, 2024



In this paper, channel estimation of an active intelligent reflecting surface (IRS) aided uplink Internet of Things (IoT) network is investigated. Firstly, the least square (LS) estimators for the direct channel and the cascaded channel are presented, respectively. The corresponding mean square errors (MSE) of channel estimators are derived. Subsequently, in order to evaluate the influence of adjusting the transmit power at the IoT devices or the reflected power at the active IRS on Sum-MSE performance, two situations are considered. In the first case, under the total power sum constraint of the IoT devices and active IRS, the closed-form expression of the optimal power allocation factor is derived. In the second case, when the transmit power at the IoT devices is fixed, there exists an optimal reflective power at active IRS. To further improve the estimation performance, the convolutional neural network (CNN)-based direct channel estimation (CDCE) algorithm and the CNN-based cascaded channel estimation (CCCE) algorithm are designed. Finally, simulation results demonstrate the existence of an optimal power allocation strategy that minimizes the Sum-MSE, and further validate the superiority of the proposed CDCE / CCCE algorithms over their respective traditional LS and minimum mean square error (MMSE) baselines.
PCAC-GAN:ASparse-Tensor-Based Generative Adversarial Network for 3D Point Cloud Attribute Compression
Jul 09, 2024



Learning-based methods have proven successful in compressing geometric information for point clouds. For attribute compression, however, they still lag behind non-learning-based methods such as the MPEG G-PCC standard. To bridge this gap, we propose a novel deep learning-based point cloud attribute compression method that uses a generative adversarial network (GAN) with sparse convolution layers. Our method also includes a module that adaptively selects the resolution of the voxels used to voxelize the input point cloud. Sparse vectors are used to represent the voxelized point cloud, and sparse convolutions process the sparse tensors, ensuring computational efficiency. To the best of our knowledge, this is the first application of GANs to compress point cloud attributes. Our experimental results show that our method outperforms existing learning-based techniques and rivals the latest G-PCC test model (TMC13v23) in terms of visual quality.
IntentionNet: Map-Lite Visual Navigation at the Kilometre Scale
Jul 03, 2024



This work explores the challenges of creating a scalable and robust robot navigation system that can traverse both indoor and outdoor environments to reach distant goals. We propose a navigation system architecture called IntentionNet that employs a monolithic neural network as the low-level planner/controller, and uses a general interface that we call intentions to steer the controller. The paper proposes two types of intentions, Local Path and Environment (LPE) and Discretised Local Move (DLM), and shows that DLM is robust to significant metric positioning and mapping errors. The paper also presents Kilo-IntentionNet, an instance of the IntentionNet system using the DLM intention that is deployed on a Boston Dynamics Spot robot, and which successfully navigates through complex indoor and outdoor environments over distances of up to a kilometre with only noisy odometry.
Learning Robust 3D Representation from CLIP via Dual Denoising
Jul 01, 2024In this paper, we explore a critical yet under-investigated issue: how to learn robust and well-generalized 3D representation from pre-trained vision language models such as CLIP. Previous works have demonstrated that cross-modal distillation can provide rich and useful knowledge for 3D data. However, like most deep learning models, the resultant 3D learning network is still vulnerable to adversarial attacks especially the iterative attack. In this work, we propose Dual Denoising, a novel framework for learning robust and well-generalized 3D representations from CLIP. It combines a denoising-based proxy task with a novel feature denoising network for 3D pre-training. Additionally, we propose utilizing parallel noise inference to enhance the generalization of point cloud features under cross domain settings. Experiments show that our model can effectively improve the representation learning performance and adversarial robustness of the 3D learning network under zero-shot settings without adversarial training. Our code is available at https://github.com/luoshuqing2001/Dual_Denoising.
Joint Power Allocation and Beamforming Design for Active IRS-Aided Directional Modulation Secure Systems
Jun 13, 2024



Since the secrecy rate (SR) performance improvement obtained by secure directional modulation (DM) network is limited, an active intelligent reflective surface (IRS)-assisted DM network is considered to attain a high SR. To address the SR maximization problem, a novel method based on Lagrangian dual transform and closed-form fractional programming algorithm (LDT-CFFP) is proposed, where the solutions to base station (BS) beamforming vectors and IRS reflection coefficient matrix are achieved. However, the computational complexity of LDT-CFFP method is high . To reduce its complexity, a blocked IRS-assisted DM network is designed. To meet the requirements of the network performance, a power allocation (PA) strategy is proposed and adopted in the system. Specifically, the system power between BS and IRS, as well as the transmission power for confidential messages (CM) and artificial noise (AN) from the BS, are allocated separately. Then we put forward null-space projection (NSP) method, maximum-ratio-reflecting (MRR) algorithm and PA strategy (NSP-MRR-PA) to solve the SR maximization problem. The CF solutions to BS beamforming vectors and IRS reflection coefficient matrix are respectively attained via NSP and MRR algorithms. For the PA factors, we take advantage of exhaustive search (ES) algorithm, particle swarm optimization (PSO) and simulated annealing (SA) algorithm to search for the solutions. From simulation results, it is verified that the LDT-CFFP method derives a higher SR gain over NSP-MRR-PA method. For NSP-MRR-PA method, the number of IRS units in each block possesses a significant SR performance. In addition, the application PA strategies, namely ES, PSO, SA methods outperforms the other PA strategies with fixed PA factors.
Chain of Preference Optimization: Improving Chain-of-Thought Reasoning in LLMs
Jun 13, 2024



The recent development of chain-of-thought (CoT) decoding has enabled large language models (LLMs) to generate explicit logical reasoning paths for complex problem-solving. However, research indicates that these paths are not always deliberate and optimal. The tree-of-thought (ToT) method employs tree-searching to extensively explore the reasoning space and find better reasoning paths that CoT decoding might overlook. This deliberation, however, comes at the cost of significantly increased inference complexity. In this work, we demonstrate that fine-tuning LLMs leveraging the search tree constructed by ToT allows CoT to achieve similar or better performance, thereby avoiding the substantial inference burden. This is achieved through Chain of Preference Optimization (CPO), where LLMs are fine-tuned to align each step of the CoT reasoning paths with those of ToT using the inherent preference information in the tree-search process. Extensive experimental results show that CPO significantly improves LLM performance in solving a variety of complex problems, including question answering, fact verification, and arithmetic reasoning, demonstrating its effectiveness. Our code is available at https://github.com/sail-sg/CPO.