 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFull-Step-DPO: Self-Supervised Preference Optimization with Step-wise Rewards for Mathematical Reasoning
Feb 20, 2025Direct Preference Optimization (DPO) often struggles with long-chain mathematical reasoning. Existing approaches, such as Step-DPO, typically improve this by focusing on the first erroneous step in the reasoning chain. However, they overlook all other steps and rely heavily on humans or GPT-4 to identify erroneous steps. To address these issues, we propose Full-Step-DPO, a novel DPO framework tailored for mathematical reasoning. Instead of optimizing only the first erroneous step, it leverages step-wise rewards from the entire reasoning chain. This is achieved by training a self-supervised process reward model, which automatically scores each step, providing rewards while avoiding reliance on external signals. Furthermore, we introduce a novel step-wise DPO loss, which dynamically updates gradients based on these step-wise rewards. This endows stronger reasoning capabilities to language models. Extensive evaluations on both in-domain and out-of-domain mathematical reasoning benchmarks across various base language models, demonstrate that Full-Step-DPO achieves superior performance compared to state-of-the-art baselines.
Multi-Task Model Merging via Adaptive Weight Disentanglement
Nov 27, 2024



Model merging has gained increasing attention as an efficient and effective technique for integrating task-specific weights from various tasks into a unified multi-task model without retraining or additional data. As a representative approach, Task Arithmetic (TA) has demonstrated that combining task vectors through arithmetic operations facilitates efficient capability transfer between different tasks. In this framework, task vectors are obtained by subtracting the parameter values of a pre-trained model from those of individually fine-tuned models initialized from it. Despite the notable effectiveness of TA, interference among task vectors can adversely affect the performance of the merged model. In this paper, we relax the constraints of Task Arithmetic Property and propose Task Consistency Property, which can be regarded as being free from task interference. Through theoretical derivation, we show that such a property can be approximately achieved by seeking orthogonal task vectors. Guiding by this insight, we propose Adaptive Weight Disentanglement (AWD), which decomposes traditional task vectors into a redundant vector and several disentangled task vectors. The primary optimization objective of AWD is to achieve orthogonality among the disentangled task vectors, thereby closely approximating the desired solution. Notably, these disentangled task vectors can be seamlessly integrated into existing merging methodologies. Experimental results demonstrate that our AWD consistently and significantly improves upon previous merging approaches, achieving state-of-the-art results. Our code is available at \href{https://github.com/FarisXiong/AWD.git}{https://github.com/FarisXiong/AWD.git}.
Point-PRC: A Prompt Learning Based Regulation Framework for Generalizable Point Cloud Analysis
Oct 27, 2024This paper investigates the 3D domain generalization (3DDG) ability of large 3D models based on prevalent prompt learning. Recent works demonstrate the performances of 3D point cloud recognition can be boosted remarkably by parameter-efficient prompt tuning. However, we observe that the improvement on downstream tasks comes at the expense of a severe drop in 3D domain generalization. To resolve this challenge, we present a comprehensive regulation framework that allows the learnable prompts to actively interact with the well-learned general knowledge in large 3D models to maintain good generalization. Specifically, the proposed framework imposes multiple explicit constraints on the prompt learning trajectory by maximizing the mutual agreement between task-specific predictions and task-agnostic knowledge. We design the regulation framework as a plug-and-play module to embed into existing representative large 3D models. Surprisingly, our method not only realizes consistently increasing generalization ability but also enhances task-specific 3D recognition performances across various 3DDG benchmarks by a clear margin. Considering the lack of study and evaluation on 3DDG, we also create three new benchmarks, namely base-to-new, cross-dataset and few-shot generalization benchmarks, to enrich the field and inspire future research. Code and benchmarks are available at \url{https://github.com/auniquesun/Point-PRC}.
As Simple as Fine-tuning: LLM Alignment via Bidirectional Negative Feedback Loss
Oct 07, 2024



Direct Preference Optimization (DPO) has emerged as a more computationally efficient alternative to Reinforcement Learning from Human Feedback (RLHF) with Proximal Policy Optimization (PPO), eliminating the need for reward models and online sampling. Despite these benefits, DPO and its variants remain sensitive to hyper-parameters and prone to instability, particularly on mathematical datasets. We argue that these issues arise from the unidirectional likelihood-derivative negative feedback inherent in the log-likelihood loss function. To address this, we propose a novel LLM alignment loss that establishes a stable Bidirectional Negative Feedback (BNF) during optimization. Our proposed BNF loss eliminates the need for pairwise contrastive losses and does not require any extra tunable hyper-parameters or pairwise preference data, streamlining the alignment pipeline to be as simple as supervised fine-tuning. We conduct extensive experiments across two challenging QA benchmarks and four reasoning benchmarks. The experimental results show that BNF achieves comparable performance to the best methods on QA benchmarks, while its performance decrease on the four reasoning benchmarks is significantly lower compared to the best methods, thus striking a better balance between value alignment and reasoning ability. In addition, we further validate the performance of BNF on non-pairwise datasets, and conduct in-depth analysis of log-likelihood and logit shifts across different preference optimization methods.
Parameter-efficient Prompt Learning for 3D Point Cloud Understanding
Feb 24, 2024This paper presents a parameter-efficient prompt tuning method, named PPT, to adapt a large multi-modal model for 3D point cloud understanding. Existing strategies are quite expensive in computation and storage, and depend on time-consuming prompt engineering. We address the problems from three aspects. Firstly, a PromptLearner module is devised to replace hand-crafted prompts with learnable contexts to automate the prompt tuning process. Then, we lock the pre-trained backbone instead of adopting the full fine-tuning paradigm to substantially improve the parameter efficiency. Finally, a lightweight PointAdapter module is arranged near target tasks to enhance prompt tuning for 3D point cloud understanding. Comprehensive experiments are conducted to demonstrate the superior parameter and data efficiency of the proposed method.Meanwhile, we obtain new records on 4 public datasets and multiple 3D tasks, i.e., point cloud recognition, few-shot learning, and part segmentation. The implementation is available at https://github.com/auniquesun/PPT.
Infrastructure Crack Segmentation: Boundary Guidance Method and Benchmark Dataset
Jun 15, 2023Cracks provide an essential indicator of infrastructure performance degradation, and achieving high-precision pixel-level crack segmentation is an issue of concern. Unlike the common research paradigms that adopt novel artificial intelligence (AI) methods directly, this paper examines the inherent characteristics of cracks so as to introduce boundary features into crack identification and then builds a boundary guidance crack segmentation model (BGCrack) with targeted structures and modules, including a high frequency module, global information modeling module, joint optimization module, etc. Extensive experimental results verify the feasibility of the proposed designs and the effectiveness of the edge information in improving segmentation results. In addition, considering that notable open-source datasets mainly consist of asphalt pavement cracks because of ease of access, there is no standard and widely recognized dataset yet for steel structures, one of the primary structural forms in civil infrastructure. This paper provides a steel crack dataset that establishes a unified and fair benchmark for the identification of steel cracks.
MLOps Spanning Whole Machine Learning Life Cycle: A Survey
Apr 13, 2023



Google AlphaGos win has significantly motivated and sped up machine learning (ML) research and development, which led to tremendous ML technical advances and wider adoptions in various domains (e.g., Finance, Health, Defense, and Education). These advances have resulted in numerous new concepts and technologies, which are too many for people to catch up to and even make them confused, especially for newcomers to the ML area. This paper is aimed to present a clear picture of the state-of-the-art of the existing ML technologies with a comprehensive survey. We lay out this survey by viewing ML as a MLOps (ML Operations) process, where the key concepts and activities are collected and elaborated with representative works and surveys. We hope that this paper can serve as a quick reference manual (a survey of surveys) for newcomers (e.g., researchers, practitioners) of ML to get an overview of the MLOps process, as well as a good understanding of the key technologies used in each step of the ML process, and know where to find more details.
SR-DCSK Cooperative Communication System with Code Index Modulation: A New Design for 6G New Radios
Aug 27, 2022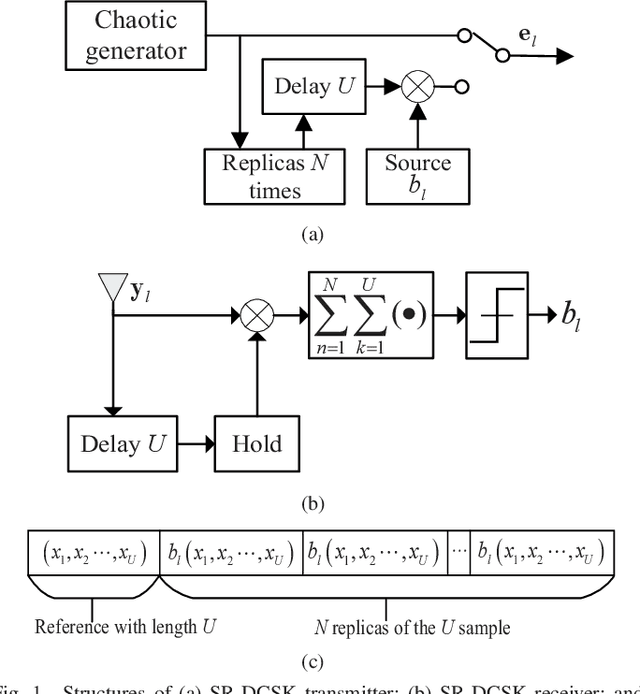
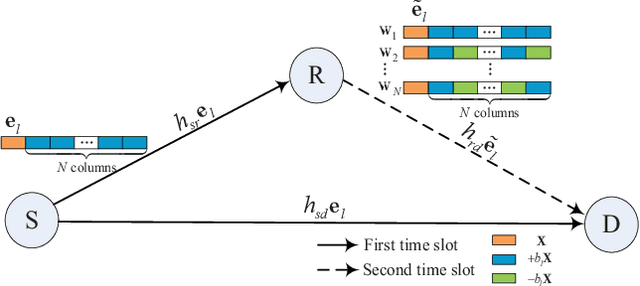
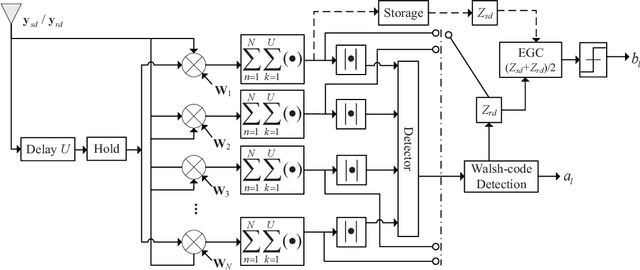
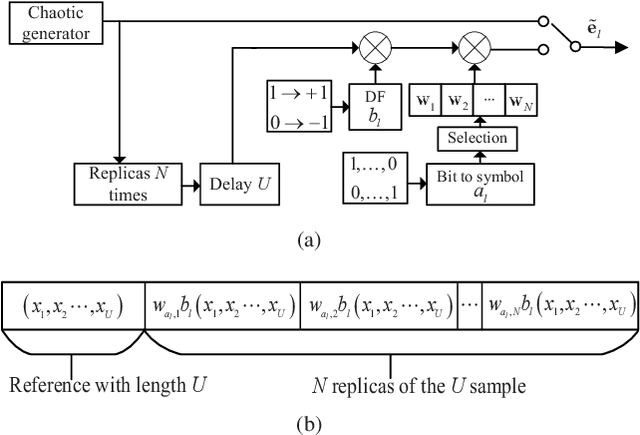
This paper proposes a high-throughput short reference differential chaos shift keying cooperative communication system with the aid of code index modulation, referred to as CIM-SR-DCSK-CC system. In the proposed CIM-SR-DCSK-CC system, the source transmits information bits to both the relay and destination in the first time slot, while the relay not only forwards the source information bits but also sends new information bits to the destination in the second time slot. To be specific, the relay employs an $N$-order Walsh code to carry additional ${{\log }_{2}}N$ information bits, which are superimposed onto the SR-DCSK signal carrying the decoded source information bits. Subsequently, the superimposed signal carrying both the source and relay information bits is transmitted to the destination. Moreover, the theoretical bit error rate (BER) expressions of the proposed CIM-SR-DCSK-CC system are derived over additive white Gaussian noise (AWGN) and multipath Rayleigh fading channels. Compared with the conventional DCSK-CC system and SR-DCSK-CC system, the proposed CIM-SR-DCSK-CC system can significantly improve the throughput without deteriorating any BER performance. As a consequence, the proposed system is very promising for the applications of the 6G-enabled low-power and high-rate communication.
Global Mixup: Eliminating Ambiguity with Clustering
Jun 06, 2022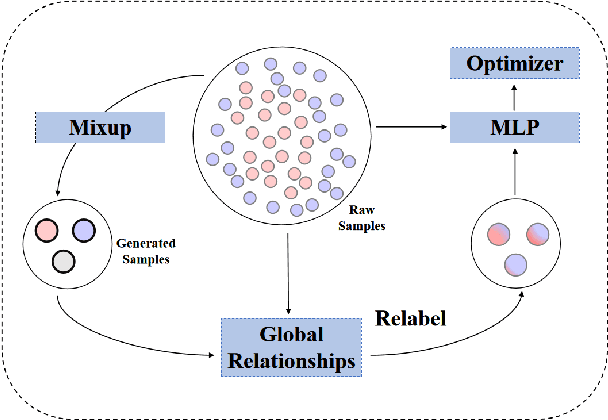
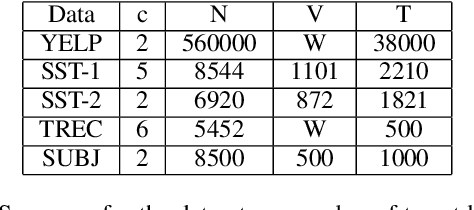
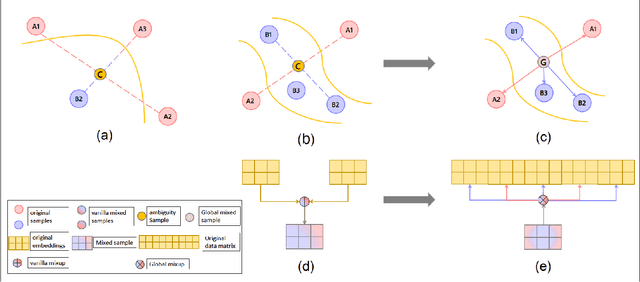
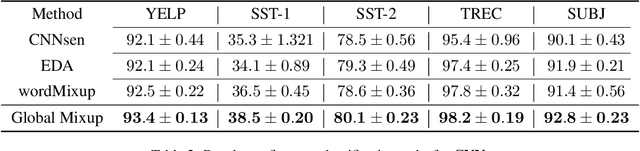
Data augmentation with \textbf{Mixup} has been proven an effective method to regularize the current deep neural networks. Mixup generates virtual samples and corresponding labels at once through linear interpolation. However, this one-stage generation paradigm and the use of linear interpolation have the following two defects: (1) The label of the generated sample is directly combined from the labels of the original sample pairs without reasonable judgment, which makes the labels likely to be ambiguous. (2) linear combination significantly limits the sampling space for generating samples. To tackle these problems, we propose a novel and effective augmentation method based on global clustering relationships named \textbf{Global Mixup}. Specifically, we transform the previous one-stage augmentation process into two-stage, decoupling the process of generating virtual samples from the labeling. And for the labels of the generated samples, relabeling is performed based on clustering by calculating the global relationships of the generated samples. In addition, we are no longer limited to linear relationships but generate more reliable virtual samples in a larger sampling space. Extensive experiments for \textbf{CNN}, \textbf{LSTM}, and \textbf{BERT} on five tasks show that Global Mixup significantly outperforms previous state-of-the-art baselines. Further experiments also demonstrate the advantage of Global Mixup in low-resource scenarios.
A novel multiobjective evolutionary algorithm based on decomposition and multi-reference points strategy
Nov 11, 2021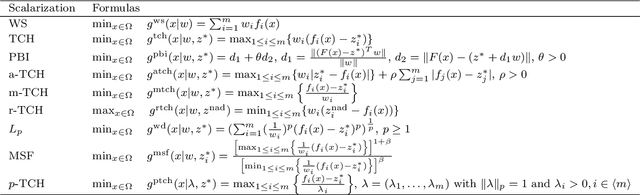
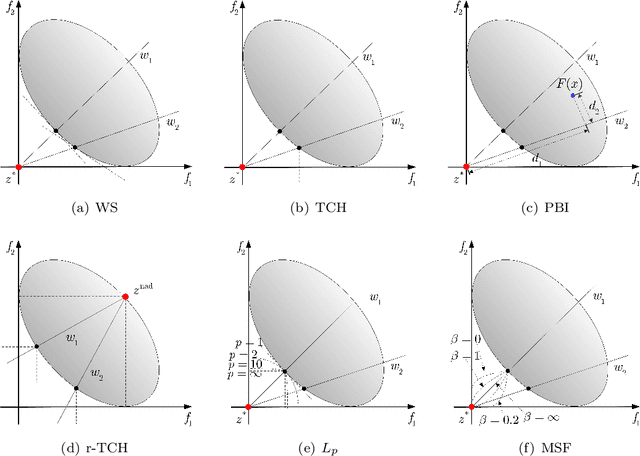
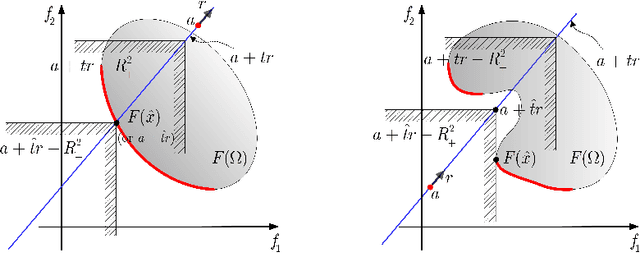
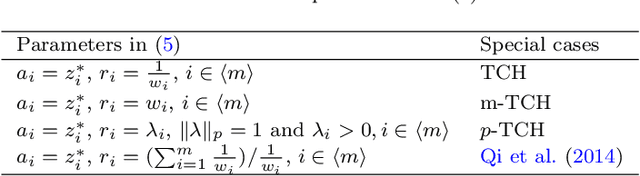
Many real-world optimization problems such as engineering design can be eventually modeled as the corresponding multiobjective optimization problems (MOPs) which must be solved to obtain approximate Pareto optimal fronts. Multiobjective evolutionary algorithm based on decomposition (MOEA/D) has been regarded as a significantly promising approach for solving MOPs. Recent studies have shown that MOEA/D with uniform weight vectors is well-suited to MOPs with regular Pareto optimal fronts, but its performance in terms of diversity usually deteriorates when solving MOPs with irregular Pareto optimal fronts. In this way, the solution set obtained by the algorithm can not provide more reasonable choices for decision makers. In order to efficiently overcome this drawback, we propose an improved MOEA/D algorithm by virtue of the well-known Pascoletti-Serafini scalarization method and a new strategy of multi-reference points. Specifically, this strategy consists of the setting and adaptation of reference points generated by the techniques of equidistant partition and projection. For performance assessment, the proposed algorithm is compared with existing four state-of-the-art multiobjective evolutionary algorithms on benchmark test problems with various types of Pareto optimal fronts. According to the experimental results, the proposed algorithm exhibits better diversity performance than that of the other compared algorithms. Finally, our algorithm is applied to two real-world MOPs in engineering optimization successfully.