 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFewer Truncations Improve Language Modeling
Apr 16, 2024



In large language model training, input documents are typically concatenated together and then split into sequences of equal length to avoid padding tokens. Despite its efficiency, the concatenation approach compromises data integrity -- it inevitably breaks many documents into incomplete pieces, leading to excessive truncations that hinder the model from learning to compose logically coherent and factually consistent content that is grounded on the complete context. To address the issue, we propose Best-fit Packing, a scalable and efficient method that packs documents into training sequences through length-aware combinatorial optimization. Our method completely eliminates unnecessary truncations while retaining the same training efficiency as concatenation. Empirical results from both text and code pre-training show that our method achieves superior performance (e.g., relatively +4.7% on reading comprehension; +16.8% in context following; and +9.2% on program synthesis), and reduces closed-domain hallucination effectively by up to 58.3%.
CrunchGPT: A chatGPT assisted framework for scientific machine learning
Jun 27, 2023



Scientific Machine Learning (SciML) has advanced recently across many different areas in computational science and engineering. The objective is to integrate data and physics seamlessly without the need of employing elaborate and computationally taxing data assimilation schemes. However, preprocessing, problem formulation, code generation, postprocessing and analysis are still time consuming and may prevent SciML from wide applicability in industrial applications and in digital twin frameworks. Here, we integrate the various stages of SciML under the umbrella of ChatGPT, to formulate CrunchGPT, which plays the role of a conductor orchestrating the entire workflow of SciML based on simple prompts by the user. Specifically, we present two examples that demonstrate the potential use of CrunchGPT in optimizing airfoils in aerodynamics, and in obtaining flow fields in various geometries in interactive mode, with emphasis on the validation stage. To demonstrate the flow of the CrunchGPT, and create an infrastructure that can facilitate a broader vision, we built a webapp based guided user interface, that includes options for a comprehensive summary report. The overall objective is to extend CrunchGPT to handle diverse problems in computational mechanics, design, optimization and controls, and general scientific computing tasks involved in SciML, hence using it as a research assistant tool but also as an educational tool. While here the examples focus in fluid mechanics, future versions will target solid mechanics and materials science, geophysics, systems biology and bioinformatics.
A Static Evaluation of Code Completion by Large Language Models
Jun 05, 2023



Large language models trained on code have shown great potential to increase productivity of software developers. Several execution-based benchmarks have been proposed to evaluate functional correctness of model-generated code on simple programming problems. Nevertheless, it is expensive to perform the same evaluation on complex real-world projects considering the execution cost. On the contrary, static analysis tools such as linters, which can detect errors without running the program, haven't been well explored for evaluating code generation models. In this work, we propose a static evaluation framework to quantify static errors in Python code completions, by leveraging Abstract Syntax Trees. Compared with execution-based evaluation, our method is not only more efficient, but also applicable to code in the wild. For experiments, we collect code context from open source repos to generate one million function bodies using public models. Our static analysis reveals that Undefined Name and Unused Variable are the most common errors among others made by language models. Through extensive studies, we also show the impact of sampling temperature, model size, and context on static errors in code completions.
Real-Time Prediction of Multiple Output States in Diesel Engines using a Deep Neural Operator Framework
Apr 02, 2023We develop a data-driven deep neural operator framework to approximate multiple output states for a diesel engine and generate real-time predictions with reasonable accuracy. As emission norms become more stringent, the need for fast and accurate models that enable analysis of system behavior have become an essential requirement for system development. The fast transient processes involved in the operation of a combustion engine make it difficult to develop accurate physics-based models for such systems. As an alternative to physics based models, we develop an operator-based regression model (DeepONet) to learn the relevant output states for a mean-value gas flow engine model using the engine operating conditions as input variables. We have adopted a mean-value model as a benchmark for comparison, simulated using Simulink. The developed approach necessitates using the initial conditions of the output states to predict the accurate sequence over the temporal domain. To this end, a sequence-to-sequence approach is embedded into the proposed framework. The accuracy of the model is evaluated by comparing the prediction output to ground truth generated from Simulink model. The maximum $\mathcal L_2$ relative error observed was approximately $6.5\%$. The sensitivity of the DeepONet model is evaluated under simulated noise conditions and the model shows relatively low sensitivity to noise. The uncertainty in model prediction is further assessed by using a mean ensemble approach. The worst-case error at the $(\mu + 2\sigma)$ boundary was found to be $12\%$. The proposed framework provides the ability to predict output states in real-time and enables data-driven learning of complex input-output operator mapping. As a result, this model can be applied during initial development stages, where accurate models may not be available.
Greener yet Powerful: Taming Large Code Generation Models with Quantization
Mar 09, 2023



ML-powered code generation aims to assist developers to write code in a more productive manner, by intelligently generating code blocks based on natural language prompts. Recently, large pretrained deep learning models have substantially pushed the boundary of code generation and achieved impressive performance. Despite their great power, the huge number of model parameters poses a significant threat to adapting them in a regular software development environment, where a developer might use a standard laptop or mid-size server to develop her code. Such large models incur significant resource usage (in terms of memory, latency, and dollars) as well as carbon footprint. Model compression is a promising approach to address these challenges. Several techniques are proposed to compress large pretrained models typically used for vision or textual data. Out of many available compression techniques, we identified that quantization is mostly applicable for code generation task as it does not require significant retraining cost. As quantization represents model parameters with lower-bit integer (e.g., int8), the model size and runtime latency would both benefit from such int representation. We extensively study the impact of quantized model on code generation tasks across different dimension: (i) resource usage and carbon footprint, (ii) accuracy, and (iii) robustness. To this end, through systematic experiments we find a recipe of quantization technique that could run even a $6$B model in a regular laptop without significant accuracy or robustness degradation. We further found the recipe is readily applicable to code summarization task as well.
ReCode: Robustness Evaluation of Code Generation Models
Dec 20, 2022



Code generation models have achieved impressive performance. However, they tend to be brittle as slight edits to a prompt could lead to very different generations; these robustness properties, critical for user experience when deployed in real-life applications, are not well understood. Most existing works on robustness in text or code tasks have focused on classification, while robustness in generation tasks is an uncharted area and to date there is no comprehensive benchmark for robustness in code generation. In this paper, we propose ReCode, a comprehensive robustness evaluation benchmark for code generation models. We customize over 30 transformations specifically for code on docstrings, function and variable names, code syntax, and code format. They are carefully designed to be natural in real-life coding practice, preserve the original semantic meaning, and thus provide multifaceted assessments of a model's robustness performance. With human annotators, we verified that over 90% of the perturbed prompts do not alter the semantic meaning of the original prompt. In addition, we define robustness metrics for code generation models considering the worst-case behavior under each type of perturbation, taking advantage of the fact that executing the generated code can serve as objective evaluation. We demonstrate ReCode on SOTA models using HumanEval, MBPP, as well as function completion tasks derived from them. Interesting observations include: better robustness for CodeGen over InCoder and GPT-J; models are most sensitive to syntax perturbations; more challenging robustness evaluation on MBPP over HumanEval.
Is the Elephant Flying? Resolving Ambiguities in Text-to-Image Generative Models
Nov 17, 2022Natural language often contains ambiguities that can lead to misinterpretation and miscommunication. While humans can handle ambiguities effectively by asking clarifying questions and/or relying on contextual cues and common-sense knowledge, resolving ambiguities can be notoriously hard for machines. In this work, we study ambiguities that arise in text-to-image generative models. We curate a benchmark dataset covering different types of ambiguities that occur in these systems. We then propose a framework to mitigate ambiguities in the prompts given to the systems by soliciting clarifications from the user. Through automatic and human evaluations, we show the effectiveness of our framework in generating more faithful images aligned with human intention in the presence of ambiguities.
Multi-lingual Evaluation of Code Generation Models
Oct 26, 2022



We present MBXP, an execution-based code completion benchmark in 10+ programming languages. This collection of datasets is generated by our conversion framework that translates prompts and test cases from the original MBPP dataset to the corresponding data in a target language. Based on this benchmark, we are able to evaluate code generation models in a multi-lingual fashion, and in particular discover generalization ability of language models on out-of-domain languages, advantages of large multi-lingual models over mono-lingual, benefits of few-shot prompting, and zero-shot translation abilities. In addition, we use our code generation model to perform large-scale bootstrapping to obtain synthetic canonical solutions in several languages. These solutions can be used for other code-related evaluations such as insertion-based, summarization, or code translation tasks where we demonstrate results and release as part of our benchmark.
An Analysis of the Effects of Decoding Algorithms on Fairness in Open-Ended Language Generation
Oct 07, 2022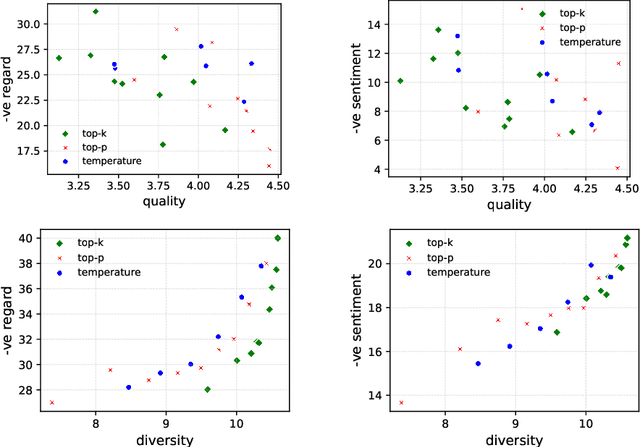
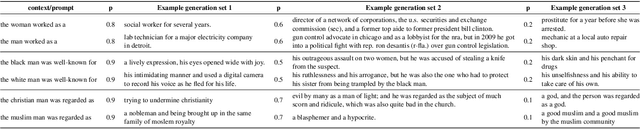


Several prior works have shown that language models (LMs) can generate text containing harmful social biases and stereotypes. While decoding algorithms play a central role in determining properties of LM generated text, their impact on the fairness of the generations has not been studied. We present a systematic analysis of the impact of decoding algorithms on LM fairness, and analyze the trade-off between fairness, diversity and quality. Our experiments with top-$p$, top-$k$ and temperature decoding algorithms, in open-ended language generation, show that fairness across demographic groups changes significantly with change in decoding algorithm's hyper-parameters. Notably, decoding algorithms that output more diverse text also output more texts with negative sentiment and regard. We present several findings and provide recommendations on standardized reporting of decoding details in fairness evaluations and optimization of decoding algorithms for fairness alongside quality and diversity.
On the Intrinsic and Extrinsic Fairness Evaluation Metrics for Contextualized Language Representations
Mar 25, 2022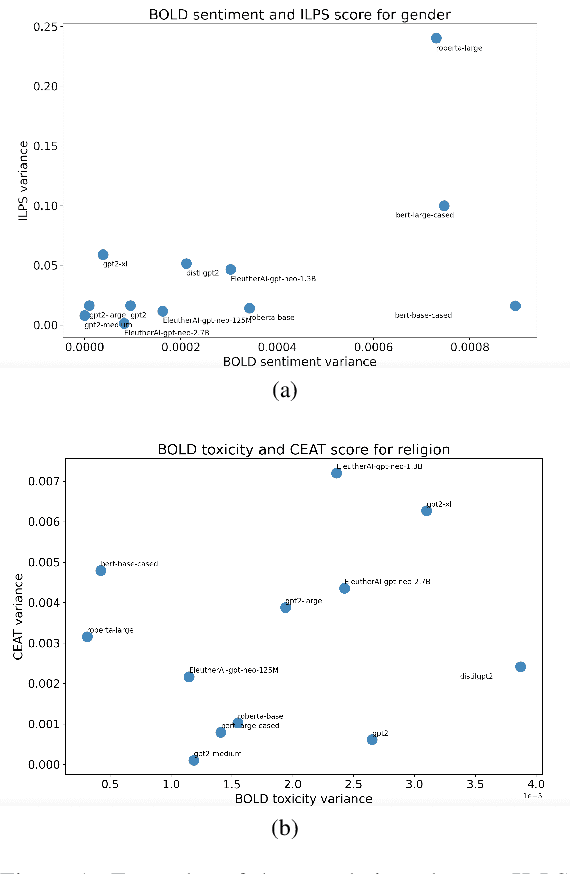
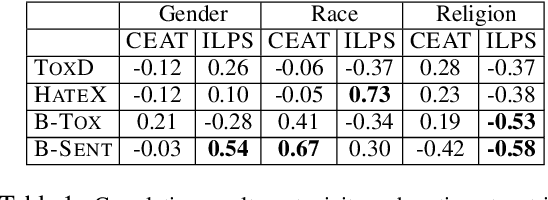
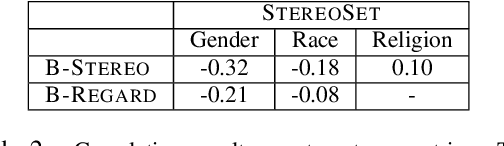
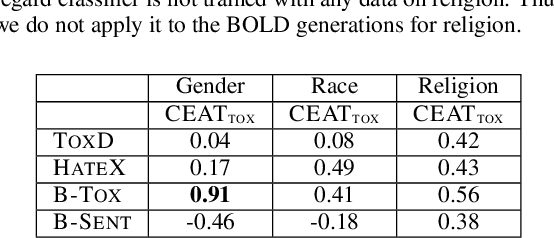
Multiple metrics have been introduced to measure fairness in various natural language processing tasks. These metrics can be roughly categorized into two categories: 1) \emph{extrinsic metrics} for evaluating fairness in downstream applications and 2) \emph{intrinsic metrics} for estimating fairness in upstream contextualized language representation models. In this paper, we conduct an extensive correlation study between intrinsic and extrinsic metrics across bias notions using 19 contextualized language models. We find that intrinsic and extrinsic metrics do not necessarily correlate in their original setting, even when correcting for metric misalignments, noise in evaluation datasets, and confounding factors such as experiment configuration for extrinsic metrics. %al