 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Vizier Gaussian Process Bandit Algorithm
Aug 21, 2024



Google Vizier has performed millions of optimizations and accelerated numerous research and production systems at Google, demonstrating the success of Bayesian optimization as a large-scale service. Over multiple years, its algorithm has been improved considerably, through the collective experiences of numerous research efforts and user feedback. In this technical report, we discuss the implementation details and design choices of the current default algorithm provided by Open Source Vizier. Our experiments on standardized benchmarks reveal its robustness and versatility against well-established industry baselines on multiple practical modes.
SmartChoices: Augmenting Software with Learned Implementations
Apr 12, 2023



We are living in a golden age of machine learning. Powerful models are being trained to perform many tasks far better than is possible using traditional software engineering approaches alone. However, developing and deploying those models in existing software systems remains difficult. In this paper we present SmartChoices, a novel approach to incorporating machine learning into mature software stacks easily, safely, and effectively. We explain the overall design philosophy and present case studies using SmartChoices within large scale industrial systems.
Long-term Prediction of Vehicle Behavior using Short-term Uncertainty-aware Trajectories and High-definition Maps
Mar 13, 2020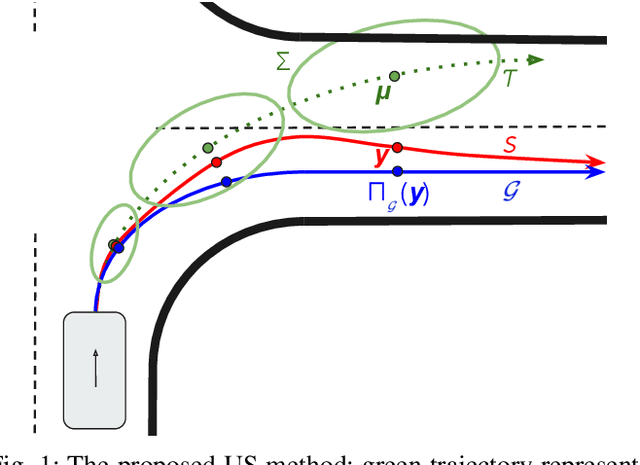



Motion prediction of surrounding vehicles is one of the most important tasks handled by a self-driving vehicle, and represents a critical step in the autonomous system necessary to ensure safety for all the involved traffic actors. Recently a number of researchers from both academic and industrial community focused on this important problem, proposing ideas ranging from engineered, rule-based methods to learned approaches, shown to perform well at different prediction horizons. In particular, while for longer-term trajectories the engineered methods outperform the competing approaches, the learned methods have proven to be the best choice at short-term horizons. In this work we describe how to overcome the discrepancy between these two research directions, and propose a method that combines the disparate approaches under a single unifying framework. The resulting algorithm fuses learned, uncertainty-aware trajectories with lane-based paths in a principled manner, resulting in improved prediction accuracy at both shorter- and longer-term horizons. Experiments on real-world, large-scale data strongly suggest benefits of the proposed unified method, which outperformed the existing state-of-the-art. Moreover, following offline evaluation the proposed method was successfully tested onboard a self-driving vehicle.
Predicting Motion of Vulnerable Road Users using High-Definition Maps and Efficient ConvNets
Jun 20, 2019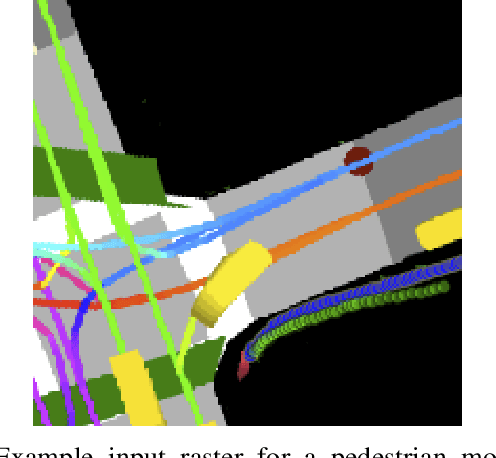
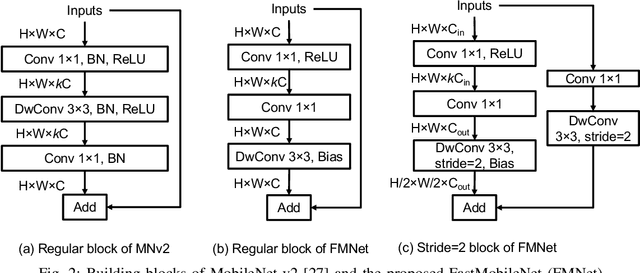
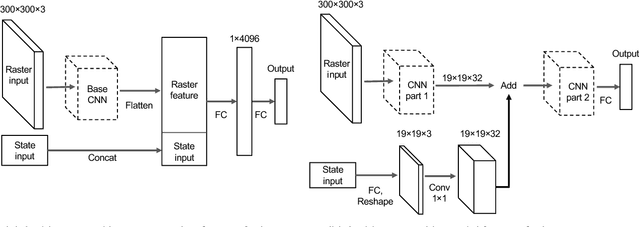
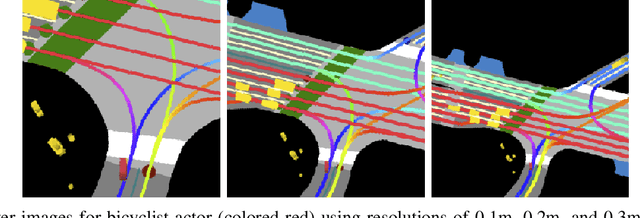
Following detection and tracking of traffic actors, prediction of their future motion is the next critical component of a self-driving vehicle (SDV) technology, allowing the SDV to operate safely and efficiently in its environment. This is particularly important when it comes to vulnerable road users (VRUs), such as pedestrians and bicyclists. These actors need to be handled with special care due to an increased risk of injury, as well as the fact that their behavior is less predictable than that of motorized actors. To address this issue, in this paper we present a deep learning-based method for predicting VRU movement, where we rasterize high-definition maps and actor's surroundings into bird's-eye view image used as an input to deep convolutional networks. In addition, we propose a fast architecture suitable for real-time inference, and present a detailed ablation study of various rasterization choices. The results strongly indicate benefits of using the proposed approach for motion prediction of VRUs, both in terms of accuracy and latency.
Multimodal Trajectory Predictions for Autonomous Driving using Deep Convolutional Networks
Mar 01, 2019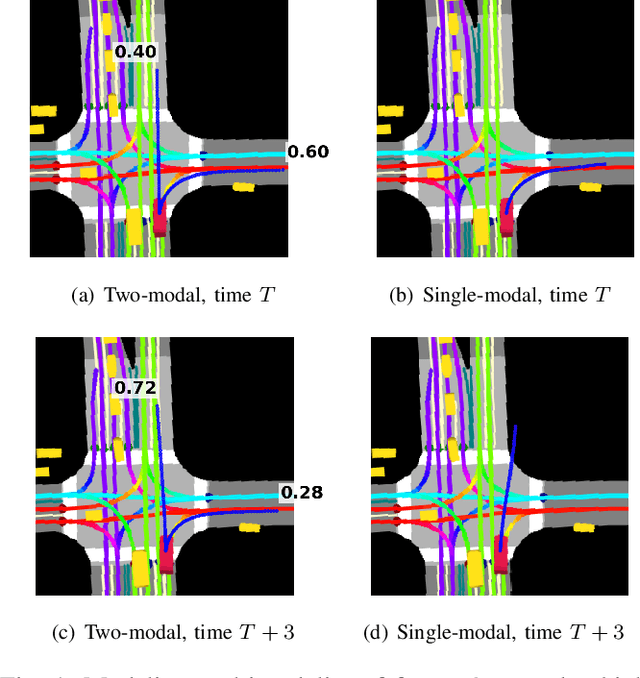
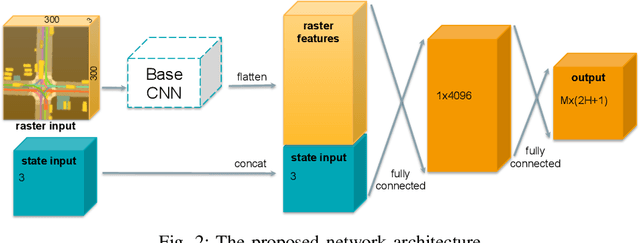
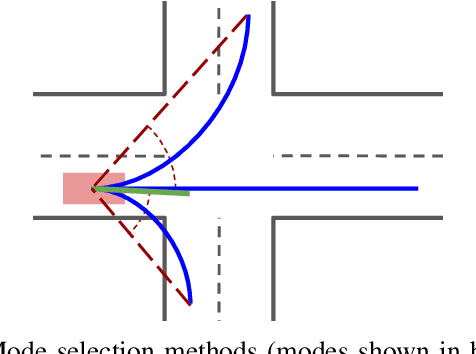
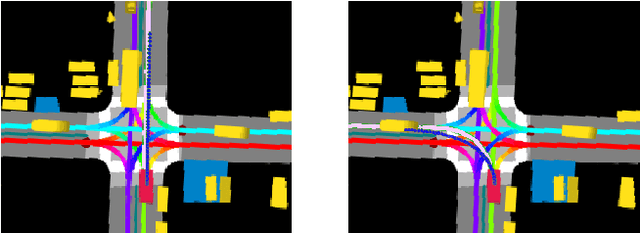
Autonomous driving presents one of the largest problems that the robotics and artificial intelligence communities are facing at the moment, both in terms of difficulty and potential societal impact. Self-driving vehicles (SDVs) are expected to prevent road accidents and save millions of lives while improving the livelihood and life quality of many more. However, despite large interest and a number of industry players working in the autonomous domain, there still remains more to be done in order to develop a system capable of operating at a level comparable to best human drivers. One reason for this is high uncertainty of traffic behavior and large number of situations that an SDV may encounter on the roads, making it very difficult to create a fully generalizable system. To ensure safe and efficient operations, an autonomous vehicle is required to account for this uncertainty and to anticipate a multitude of possible behaviors of traffic actors in its surrounding. We address this critical problem and present a method to predict multiple possible trajectories of actors while also estimating their probabilities. The method encodes each actor's surrounding context into a raster image, used as input by deep convolutional networks to automatically derive relevant features for the task. Following extensive offline evaluation and comparison to state-of-the-art baselines, the method was successfully tested on SDVs in closed-course tests.
Active Learning for Cost-Sensitive Classification
Nov 13, 2017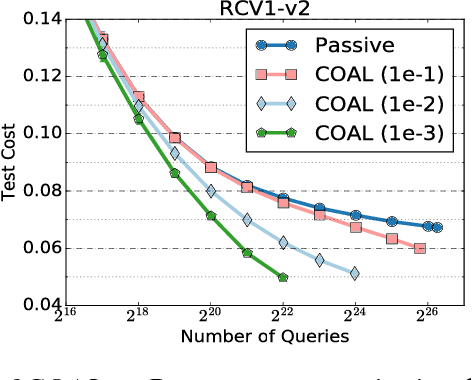
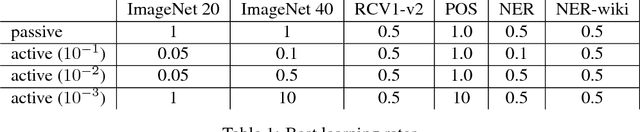
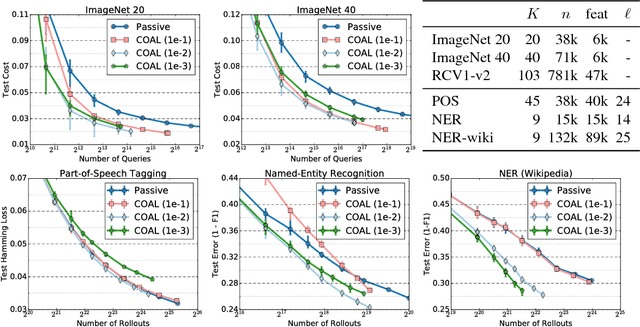
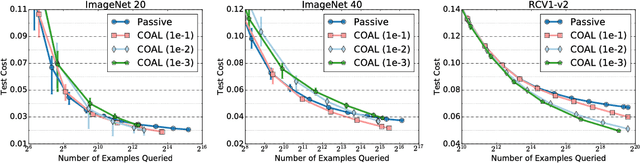
We design an active learning algorithm for cost-sensitive multiclass classification: problems where different errors have different costs. Our algorithm, COAL, makes predictions by regressing to each label's cost and predicting the smallest. On a new example, it uses a set of regressors that perform well on past data to estimate possible costs for each label. It queries only the labels that could be the best, ignoring the sure losers. We prove COAL can be efficiently implemented for any regression family that admits squared loss optimization; it also enjoys strong guarantees with respect to predictive performance and labeling effort. We empirically compare COAL to passive learning and several active learning baselines, showing significant improvements in labeling effort and test cost on real-world datasets.
Efficient and Parsimonious Agnostic Active Learning
Jan 07, 2016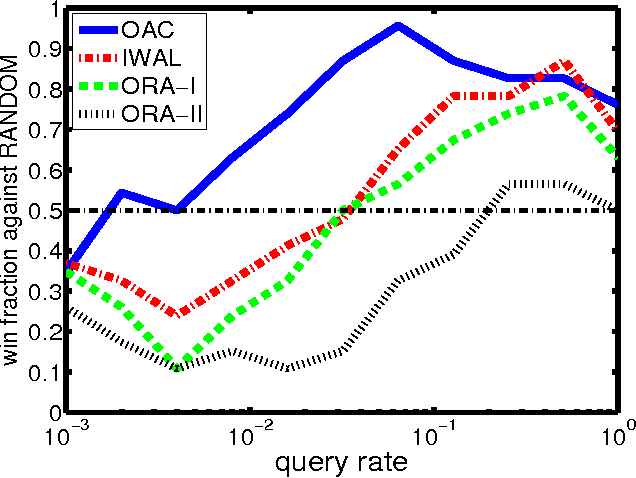
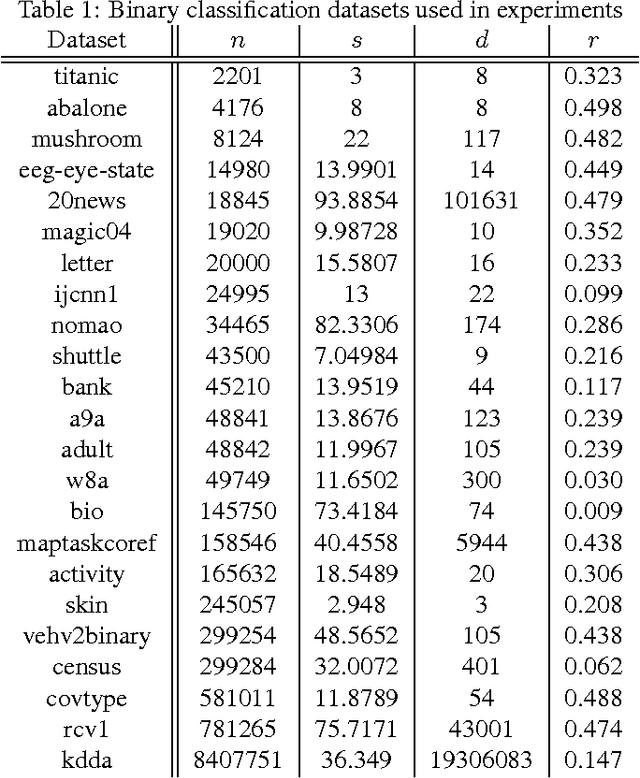
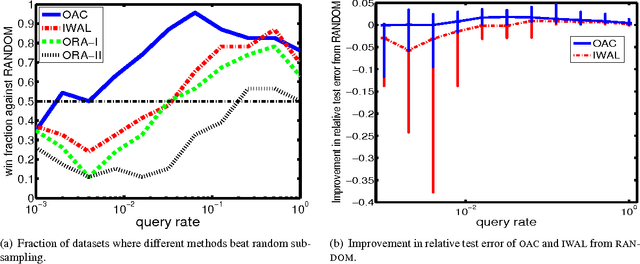
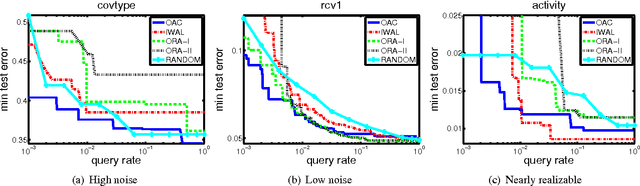
We develop a new active learning algorithm for the streaming setting satisfying three important properties: 1) It provably works for any classifier representation and classification problem including those with severe noise. 2) It is efficiently implementable with an ERM oracle. 3) It is more aggressive than all previous approaches satisfying 1 and 2. To do this we create an algorithm based on a newly defined optimization problem and analyze it. We also conduct the first experimental analysis of all efficient agnostic active learning algorithms, evaluating their strengths and weaknesses in different settings.