 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Vizier Gaussian Process Bandit Algorithm
Aug 21, 2024



Google Vizier has performed millions of optimizations and accelerated numerous research and production systems at Google, demonstrating the success of Bayesian optimization as a large-scale service. Over multiple years, its algorithm has been improved considerably, through the collective experiences of numerous research efforts and user feedback. In this technical report, we discuss the implementation details and design choices of the current default algorithm provided by Open Source Vizier. Our experiments on standardized benchmarks reveal its robustness and versatility against well-established industry baselines on multiple practical modes.
Learning Energy-based Model with Flow-based Backbone by Neural Transport MCMC
Jun 12, 2020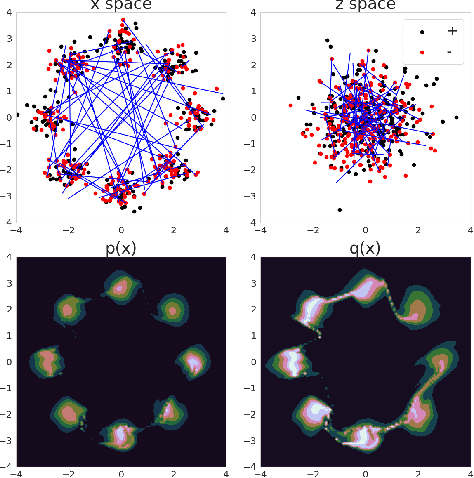
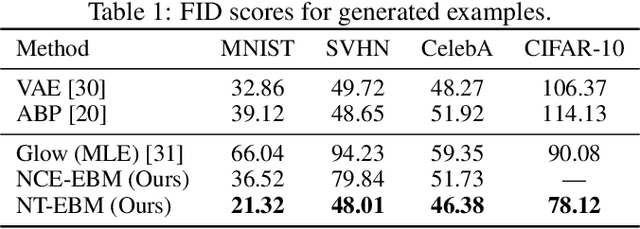

Learning energy-based model (EBM) requires MCMC sampling of the learned model as the inner loop of the learning algorithm. However, MCMC sampling of EBM in data space is generally not mixing, because the energy function, which is usually parametrized by deep network, is highly multi-modal in the data space. This is a serious handicap for both the theory and practice of EBM. In this paper, we propose to learn EBM with a flow-based model serving as a backbone, so that the EBM is a correction or an exponential tilting of the flow-based model. We show that the model has a particularly simple form in the space of the latent variables of the flow-based model, and MCMC sampling of the EBM in the latent space, which is a simple special case of neural transport MCMC, mixes well and traverses modes in the data space. This enables proper sampling and learning of EBM.
NeuTra-lizing Bad Geometry in Hamiltonian Monte Carlo Using Neural Transport
Mar 09, 2019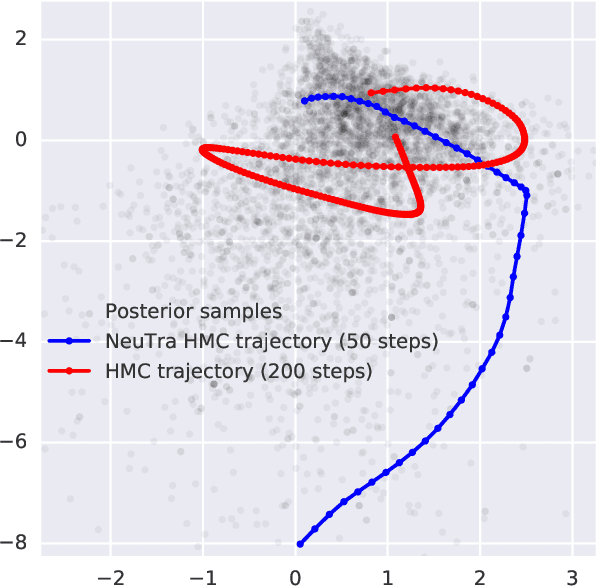

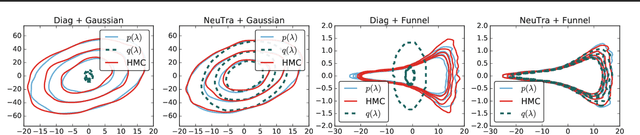
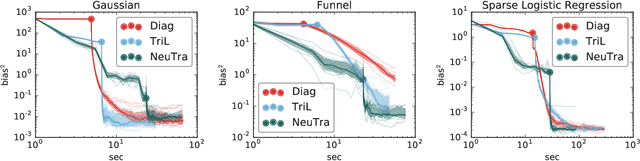
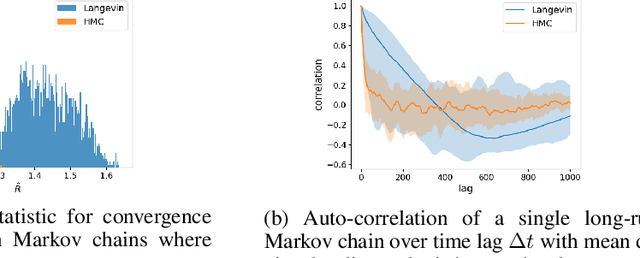
Hamiltonian Monte Carlo is a powerful algorithm for sampling from difficult-to-normalize posterior distributions. However, when the geometry of the posterior is unfavorable, it may take many expensive evaluations of the target distribution and its gradient to converge and mix. We propose neural transport (NeuTra) HMC, a technique for learning to correct this sort of unfavorable geometry using inverse autoregressive flows (IAF), a powerful neural variational inference technique. The IAF is trained to minimize the KL divergence from an isotropic Gaussian to the warped posterior, and then HMC sampling is performed in the warped space. We evaluate NeuTra HMC on a variety of synthetic and real problems, and find that it significantly outperforms vanilla HMC both in time to reach the stationary distribution and asymptotic effective-sample-size rates.
Simple, Distributed, and Accelerated Probabilistic Programming
Nov 29, 2018
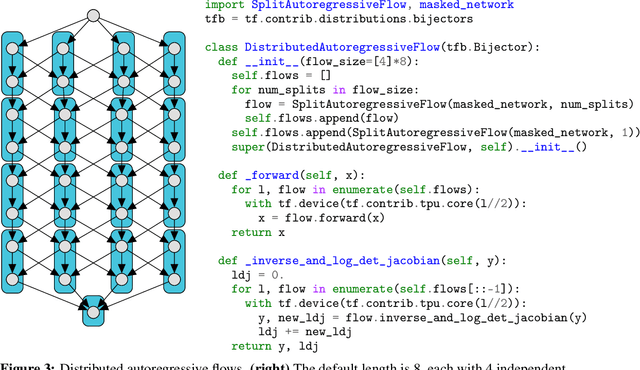
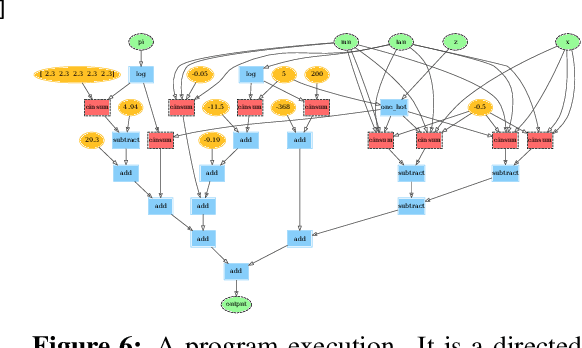
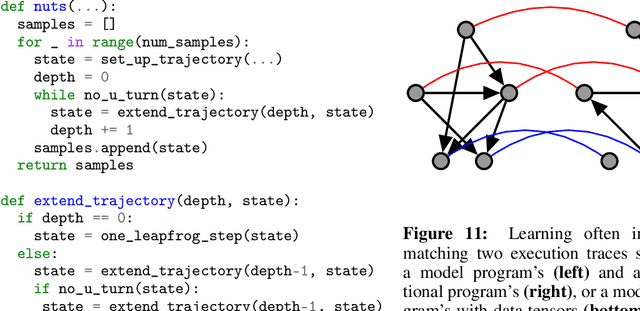
We describe a simple, low-level approach for embedding probabilistic programming in a deep learning ecosystem. In particular, we distill probabilistic programming down to a single abstraction---the random variable. Our lightweight implementation in TensorFlow enables numerous applications: a model-parallel variational auto-encoder (VAE) with 2nd-generation tensor processing units (TPUv2s); a data-parallel autoregressive model (Image Transformer) with TPUv2s; and multi-GPU No-U-Turn Sampler (NUTS). For both a state-of-the-art VAE on 64x64 ImageNet and Image Transformer on 256x256 CelebA-HQ, our approach achieves an optimal linear speedup from 1 to 256 TPUv2 chips. With NUTS, we see a 100x speedup on GPUs over Stan and 37x over PyMC3.
TensorFlow Distributions
Nov 28, 2017


The TensorFlow Distributions library implements a vision of probability theory adapted to the modern deep-learning paradigm of end-to-end differentiable computation. Building on two basic abstractions, it offers flexible building blocks for probabilistic computation. Distributions provide fast, numerically stable methods for generating samples and computing statistics, e.g., log density. Bijectors provide composable volume-tracking transformations with automatic caching. Together these enable modular construction of high dimensional distributions and transformations not possible with previous libraries (e.g., pixelCNNs, autoregressive flows, and reversible residual networks). They are the workhorse behind deep probabilistic programming systems like Edward and empower fast black-box inference in probabilistic models built on deep-network components. TensorFlow Distributions has proven an important part of the TensorFlow toolkit within Google and in the broader deep learning community.