 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Kinematic Models for Physically Realistic Prediction of Vehicle Trajectories
Aug 01, 2019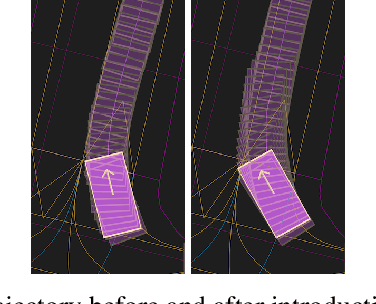
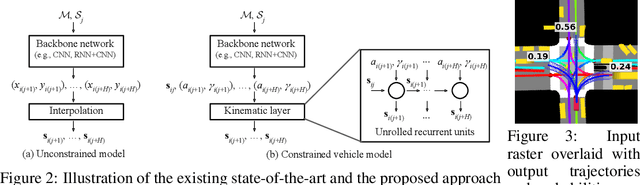
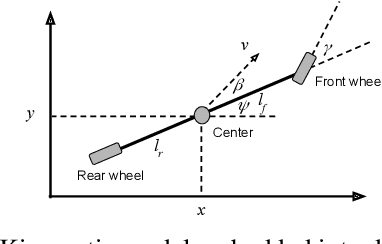
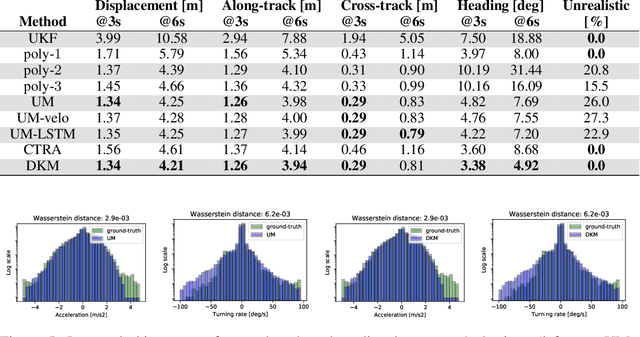
Self-driving vehicles (SDVs) hold great potential for improving traffic safety and are poised to positively affect the quality of life of millions of people. One of the critical aspects of the autonomous technology is understanding and predicting future movement of vehicles surrounding the SDV. This work presents a deep-learning-based method for physically realistic motion prediction of such traffic actors. Previous work did not explicitly encode physical realism and instead relied on the models to learn the laws of physics directly from the data, potentially resulting in implausible trajectory predictions. To account for this issue we propose a method that seamlessly combines ideas from the AI with physically grounded vehicle motion models. In this way we employ best of the both worlds, coupling powerful learning models with strong physical guarantees for their outputs. The proposed approach is general, being applicable to any type of learning method. Extensive experiments using deep convnets on large-scale, real-world data strongly indicate its benefits, outperforming the existing state-of-the-art.
Predicting Motion of Vulnerable Road Users using High-Definition Maps and Efficient ConvNets
Jun 20, 2019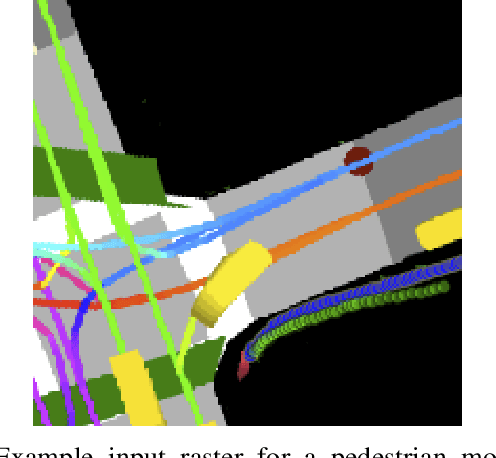
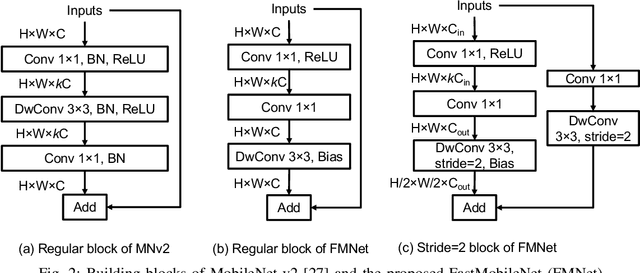
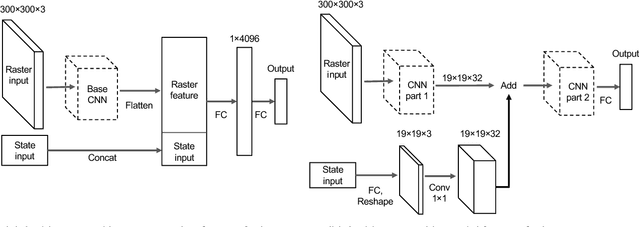
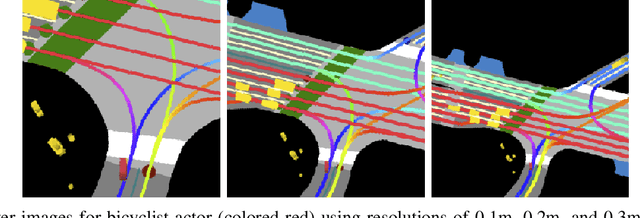
Following detection and tracking of traffic actors, prediction of their future motion is the next critical component of a self-driving vehicle (SDV) technology, allowing the SDV to operate safely and efficiently in its environment. This is particularly important when it comes to vulnerable road users (VRUs), such as pedestrians and bicyclists. These actors need to be handled with special care due to an increased risk of injury, as well as the fact that their behavior is less predictable than that of motorized actors. To address this issue, in this paper we present a deep learning-based method for predicting VRU movement, where we rasterize high-definition maps and actor's surroundings into bird's-eye view image used as an input to deep convolutional networks. In addition, we propose a fast architecture suitable for real-time inference, and present a detailed ablation study of various rasterization choices. The results strongly indicate benefits of using the proposed approach for motion prediction of VRUs, both in terms of accuracy and latency.
Multimodal Trajectory Predictions for Autonomous Driving using Deep Convolutional Networks
Mar 01, 2019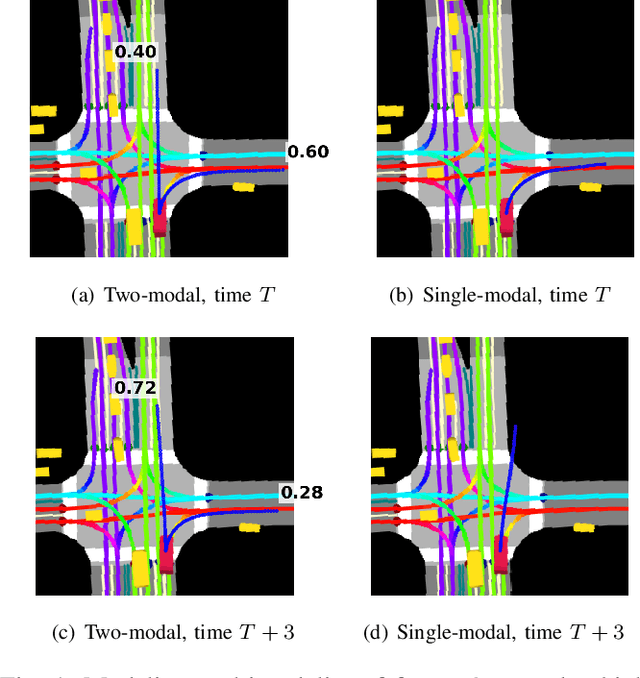
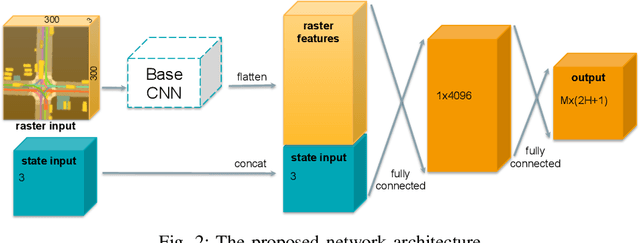
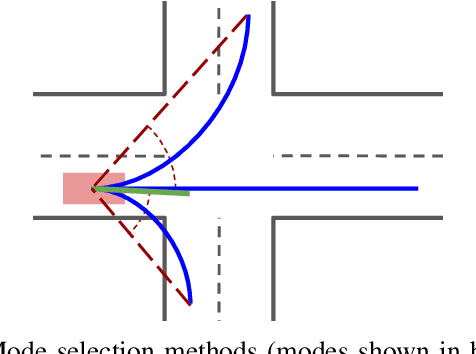
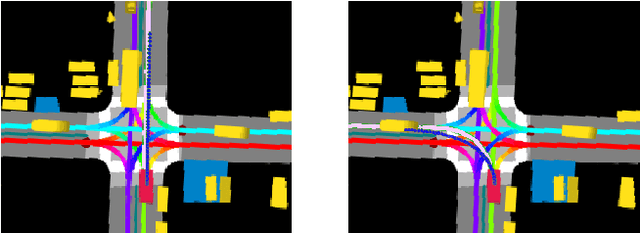
Autonomous driving presents one of the largest problems that the robotics and artificial intelligence communities are facing at the moment, both in terms of difficulty and potential societal impact. Self-driving vehicles (SDVs) are expected to prevent road accidents and save millions of lives while improving the livelihood and life quality of many more. However, despite large interest and a number of industry players working in the autonomous domain, there still remains more to be done in order to develop a system capable of operating at a level comparable to best human drivers. One reason for this is high uncertainty of traffic behavior and large number of situations that an SDV may encounter on the roads, making it very difficult to create a fully generalizable system. To ensure safe and efficient operations, an autonomous vehicle is required to account for this uncertainty and to anticipate a multitude of possible behaviors of traffic actors in its surrounding. We address this critical problem and present a method to predict multiple possible trajectories of actors while also estimating their probabilities. The method encodes each actor's surrounding context into a raster image, used as input by deep convolutional networks to automatically derive relevant features for the task. Following extensive offline evaluation and comparison to state-of-the-art baselines, the method was successfully tested on SDVs in closed-course tests.
Short-term Motion Prediction of Traffic Actors for Autonomous Driving using Deep Convolutional Networks
Sep 16, 2018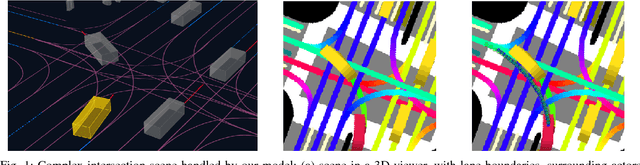


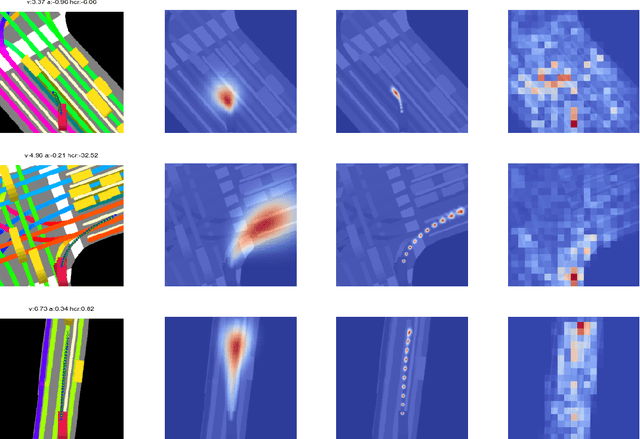
Despite its ubiquity in our daily lives, AI is only just starting to make advances in what may arguably have the largest societal impact thus far, the nascent field of autonomous driving. In this work we discuss this important topic and address one of crucial aspects of the emerging area, the problem of predicting future state of autonomous vehicle's surrounding necessary for safe and efficient operations. We introduce a deep learning-based approach that takes into account current world state and produces rasterized representations of each actor's vicinity. The raster images are then used by deep convolutional models to infer future movement of actors while accounting for inherent uncertainty of the prediction task. Extensive experiments on real-world data strongly suggest benefits of the proposed approach. Moreover, following successful tests the system was deployed to a fleet of autonomous vehicles.