 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoundWeaver: Semantic Warm-Starting for Text-to-Audio Diffusion Serving
Mar 09, 2026Text-to-audio diffusion models produce high-fidelity audio but require tens of function evaluations (NFEs), incurring multi-second latency and limited throughput. We present SoundWeaver, the first training-free, model-agnostic serving system that accelerates text-to-audio diffusion by warm-starting from semantically similar cached audio. SoundWeaver introduces three components: a Reference Selector that retrieves and temporally aligns cached candidates via semantic and duration-aware gating; a Skip Gater that dynamically determines the percentage of NFEs to skip; and a lightweight Cache Manager that maintains cache utility through quality-aware eviction and refinement. On real-world audio traces, SoundWeaver achieves 1.8--3.0$ \times $ latency reduction with a cache of only ${\sim}$1K entries while preserving or improving perceptual quality.
Prompt Cache: Modular Attention Reuse for Low-Latency Inference
Nov 07, 2023



We present Prompt Cache, an approach for accelerating inference for large language models (LLM) by reusing attention states across different LLM prompts. Many input prompts have overlapping text segments, such as system messages, prompt templates, and documents provided for context. Our key insight is that by precomputing and storing the attention states of these frequently occurring text segments on the inference server, we can efficiently reuse them when these segments appear in user prompts. Prompt Cache employs a schema to explicitly define such reusable text segments, called prompt modules. The schema ensures positional accuracy during attention state reuse and provides users with an interface to access cached states in their prompt. Using a prototype implementation, we evaluate Prompt Cache across several LLMs. We show that Prompt Cache significantly reduce latency in time-to-first-token, especially for longer prompts such as document-based question answering and recommendations. The improvements range from 8x for GPU-based inference to 60x for CPU-based inference, all while maintaining output accuracy and without the need for model parameter modifications.
SmartChoices: Augmenting Software with Learned Implementations
Apr 12, 2023



We are living in a golden age of machine learning. Powerful models are being trained to perform many tasks far better than is possible using traditional software engineering approaches alone. However, developing and deploying those models in existing software systems remains difficult. In this paper we present SmartChoices, a novel approach to incorporating machine learning into mature software stacks easily, safely, and effectively. We explain the overall design philosophy and present case studies using SmartChoices within large scale industrial systems.
Predicted Variables in Programming
Oct 01, 2018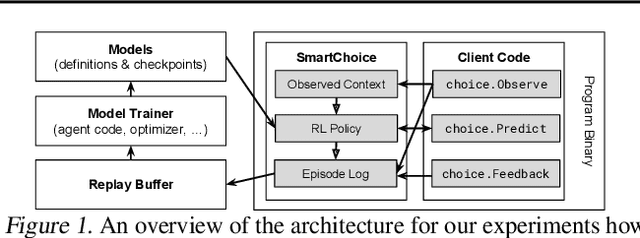
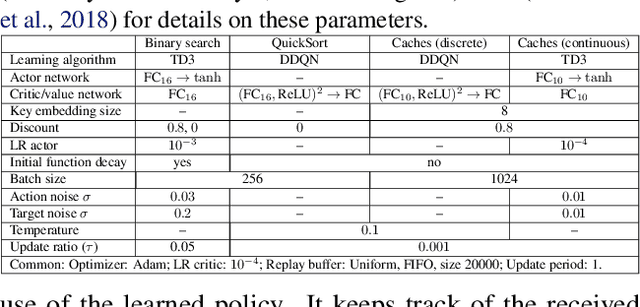
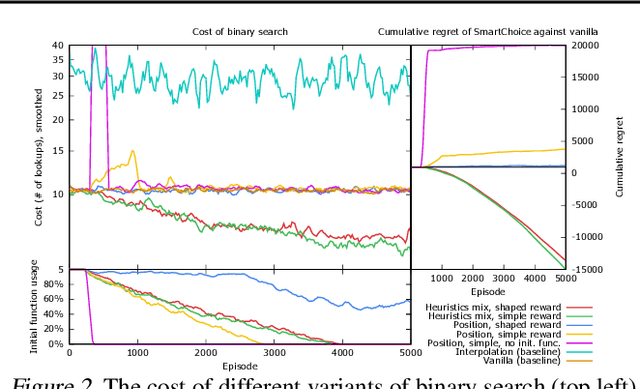

We present Predicted Variables (PVars), an approach to making machine learning (ML) a first class citizen in programming languages. There is a growing divide in approaches to building systems: using human experts (e.g. programming) on the one hand, and using behavior learned from data (e.g. ML) on the other hand. PVars aim to make ML in programming as easy as `if' statements and with that hybridize ML with programming. We leverage the existing concept of variables and create a new type, a predicted variable. PVars are akin to native variables with one important distinction: PVars determine their value using ML when evaluated. We describe PVars and their interface, how they can be used in programming, and demonstrate the feasibility of our approach on three algorithmic problems: binary search, Quicksort, and caches. We show experimentally that PVars are able to improve over the commonly used heuristics and lead to a better performance than the original algorithms. As opposed to previous work applying ML to algorithmic problems, PVars have the advantage that they can be used within the existing frameworks and do not require the existing domain knowledge to be replaced. PVars allow for a seamless integration of ML into existing systems and algorithms. Our PVars implementation currently relies on standard Reinforcement Learning (RL) methods. To learn faster, PVars use the heuristic function, which they are replacing, as an initial function. We show that PVars quickly pick up the behavior of the initial function and then improve performance beyond that without ever performing substantially worse -- allowing for a safe deployment in critical applications.