 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmartChoices: Augmenting Software with Learned Implementations
Apr 12, 2023



We are living in a golden age of machine learning. Powerful models are being trained to perform many tasks far better than is possible using traditional software engineering approaches alone. However, developing and deploying those models in existing software systems remains difficult. In this paper we present SmartChoices, a novel approach to incorporating machine learning into mature software stacks easily, safely, and effectively. We explain the overall design philosophy and present case studies using SmartChoices within large scale industrial systems.
Training for Faster Adversarial Robustness Verification via Inducing ReLU Stability
Sep 26, 2018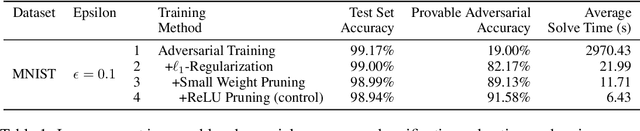
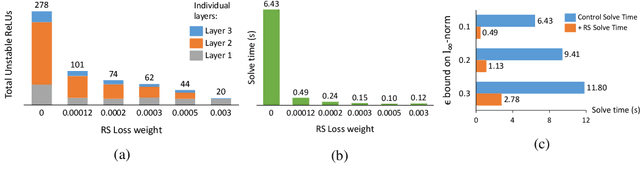

We explore the concept of co-design in the context of neural network verification. Specifically, we aim to train deep neural networks that not only are robust to adversarial perturbations but also whose robustness can be verified more easily. To this end, we identify two properties of network models - weight sparsity and so-called ReLU stability - that turn out to significantly impact the complexity of the corresponding verification task. We demonstrate that improving weight sparsity alone already enables us to turn computationally intractable verification problems into tractable ones. Then, improving ReLU stability leads to an additional 4-13x speedup in verification times. An important feature of our methodology is its "universality," in the sense that it can be used with a broad range of training procedures and verification approaches.
Evaluating Robustness of Neural Networks with Mixed Integer Programming
Jun 11, 2018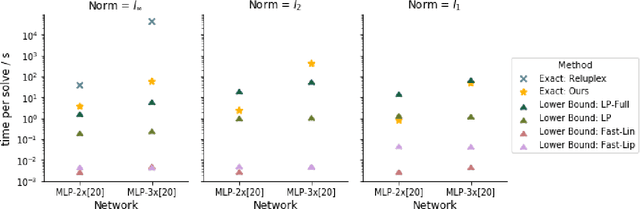
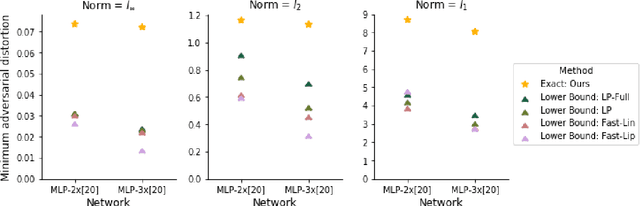
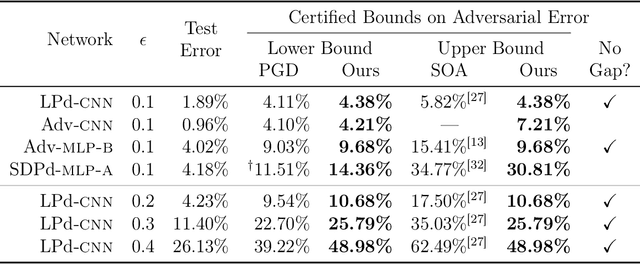
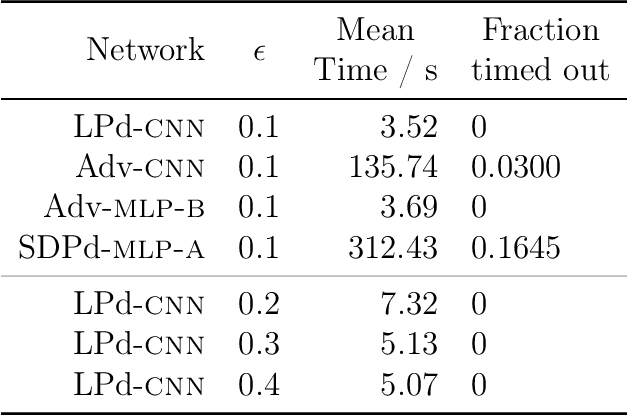
Neural networks have demonstrated considerable success on a wide variety of real-world problems. However, networks trained only to optimize for training accuracy can often be fooled by adversarial examples - slightly perturbed inputs that are misclassified with high confidence. Verification of networks enables us to gauge their vulnerability to such adversarial examples. We formulate verification of piecewise-linear neural networks as a mixed integer program. On a representative task of finding minimum adversarial distortions, our verifier is two to three orders of magnitude quicker than the state-of-the-art. We achieve this computational speedup via tight formulations for non-linearities, as well as a novel presolve algorithm that makes full use of all information available. The computational speedup allows us to verify properties on convolutional networks with an order of magnitude more ReLUs than networks previously verified by any complete verifier. In particular, we determine for the first time the exact adversarial accuracy of an MNIST classifier to perturbations with bounded $l_\infty$ norm $\epsilon=0.1$: for this classifier, we find an adversarial example for 4.38% of samples, and a certificate of robustness (to perturbations with bounded norm) for the remainder. Across all robust training procedures and network architectures considered, we are able to certify more samples than the state-of-the-art and find more adversarial examples than a strong first-order attack.