 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLATON: Pruning Large Transformer Models with Upper Confidence Bound of Weight Importance
Jun 25, 2022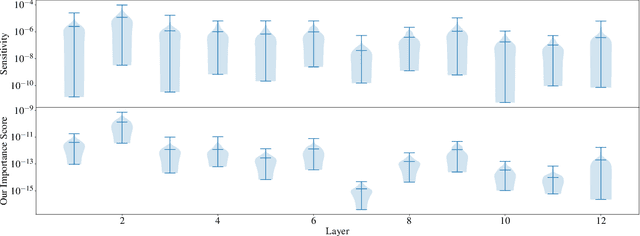
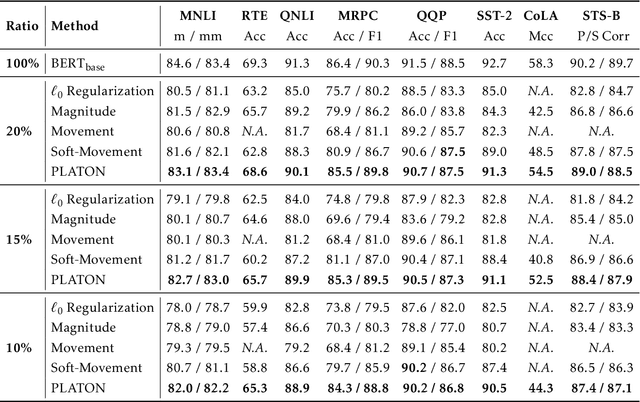
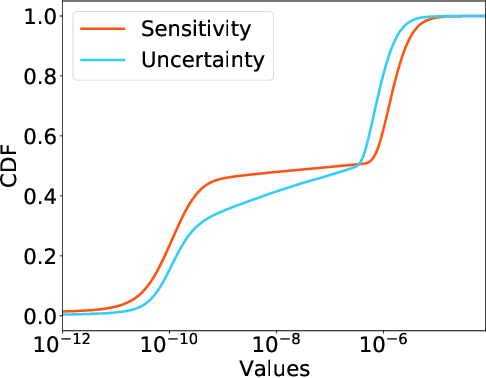
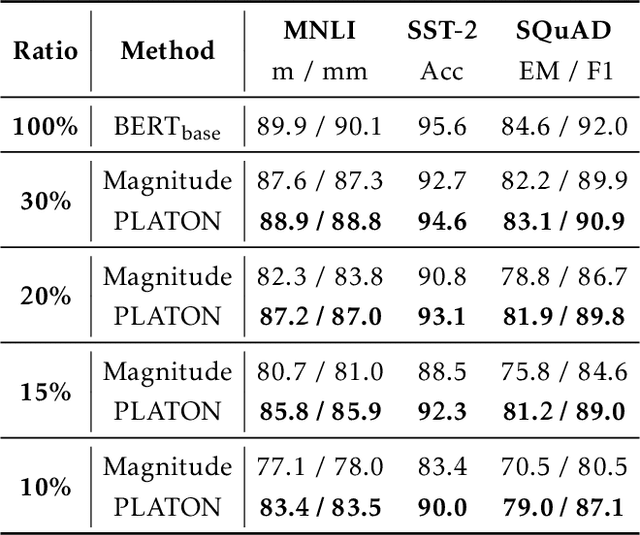
Large Transformer-based models have exhibited superior performance in various natural language processing and computer vision tasks. However, these models contain enormous amounts of parameters, which restrict their deployment to real-world applications. To reduce the model size, researchers prune these models based on the weights' importance scores. However, such scores are usually estimated on mini-batches during training, which incurs large variability/uncertainty due to mini-batch sampling and complicated training dynamics. As a result, some crucial weights could be pruned by commonly used pruning methods because of such uncertainty, which makes training unstable and hurts generalization. To resolve this issue, we propose PLATON, which captures the uncertainty of importance scores by upper confidence bound (UCB) of importance estimation. In particular, for the weights with low importance scores but high uncertainty, PLATON tends to retain them and explores their capacity. We conduct extensive experiments with several Transformer-based models on natural language understanding, question answering and image classification to validate the effectiveness of PLATON. Results demonstrate that PLATON manifests notable improvement under different sparsity levels. Our code is publicly available at https://github.com/QingruZhang/PLATON.
Benefits of Overparameterized Convolutional Residual Networks: Function Approximation under Smoothness Constraint
Jun 09, 2022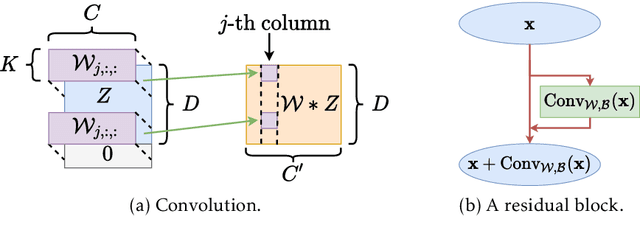
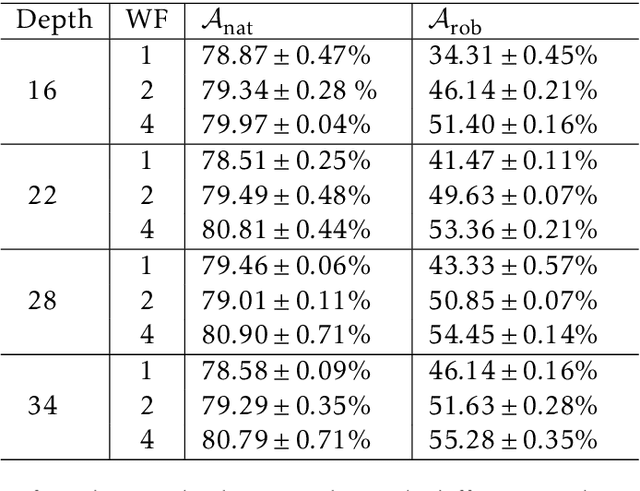
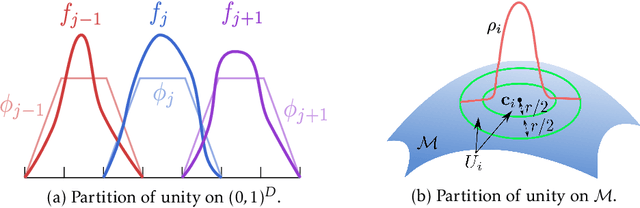
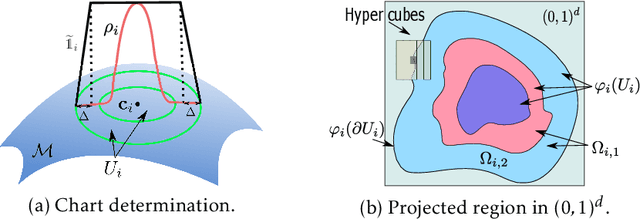
Overparameterized neural networks enjoy great representation power on complex data, and more importantly yield sufficiently smooth output, which is crucial to their generalization and robustness. Most existing function approximation theories suggest that with sufficiently many parameters, neural networks can well approximate certain classes of functions in terms of the function value. The neural network themselves, however, can be highly nonsmooth. To bridge this gap, we take convolutional residual networks (ConvResNets) as an example, and prove that large ConvResNets can not only approximate a target function in terms of function value, but also exhibit sufficient first-order smoothness. Moreover, we extend our theory to approximating functions supported on a low-dimensional manifold. Our theory partially justifies the benefits of using deep and wide networks in practice. Numerical experiments on adversarial robust image classification are provided to support our theory.
Sample Complexity of Nonparametric Off-Policy Evaluation on Low-Dimensional Manifolds using Deep Networks
Jun 06, 2022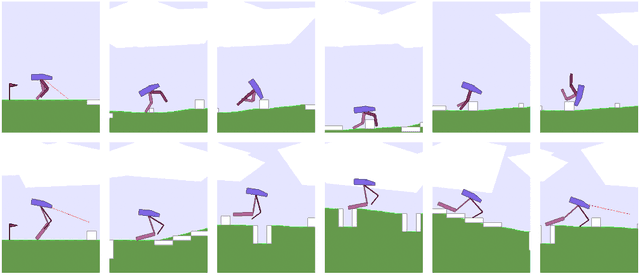
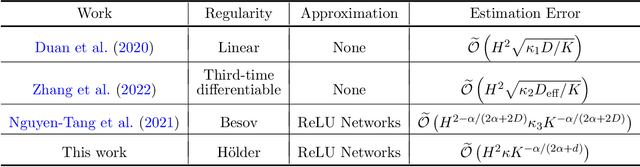
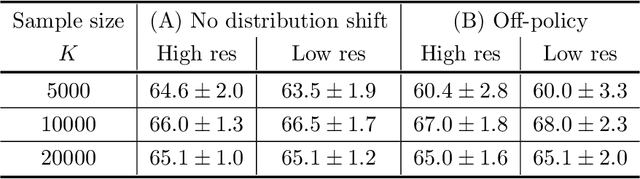
We consider the off-policy evaluation problem of reinforcement learning using deep neural networks. We analyze the deep fitted Q-evaluation method for estimating the expected cumulative reward of a target policy, when the data are generated from an unknown behavior policy. We show that, by choosing network size appropriately, one can leverage the low-dimensional manifold structure in the Markov decision process and obtain a sample-efficient estimator without suffering from the curse of high representation dimensionality. Specifically, we establish a sharp error bound for the fitted Q-evaluation that depends on the intrinsic low dimension, the smoothness of the state-action space, and a function class-restricted $\chi^2$-divergence. It is noteworthy that the restricted $\chi^2$-divergence measures the behavior and target policies' {\it mismatch in the function space}, which can be small even if the two policies are not close to each other in their tabular forms. Numerical experiments are provided to support our theoretical analysis.
A Manifold Two-Sample Test Study: Integral Probability Metric with Neural Networks
May 04, 2022
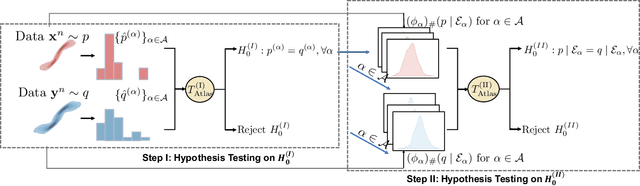
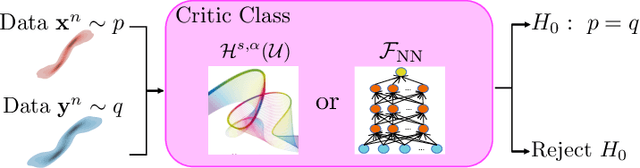
Two-sample tests are important areas aiming to determine whether two collections of observations follow the same distribution or not. We propose two-sample tests based on integral probability metric (IPM) for high-dimensional samples supported on a low-dimensional manifold. We characterize the properties of proposed tests with respect to the number of samples $n$ and the structure of the manifold with intrinsic dimension $d$. When an atlas is given, we propose two-step test to identify the difference between general distributions, which achieves the type-II risk in the order of $n^{-1/\max\{d,2\}}$. When an atlas is not given, we propose H\"older IPM test that applies for data distributions with $(s,\beta)$-H\"older densities, which achieves the type-II risk in the order of $n^{-(s+\beta)/d}$. To mitigate the heavy computation burden of evaluating the H\"older IPM, we approximate the H\"older function class using neural networks. Based on the approximation theory of neural networks, we show that the neural network IPM test has the type-II risk in the order of $n^{-(s+\beta)/d}$, which is in the same order of the type-II risk as the H\"older IPM test. Our proposed tests are adaptive to low-dimensional geometric structure because their performance crucially depends on the intrinsic dimension instead of the data dimension.
MoEBERT: from BERT to Mixture-of-Experts via Importance-Guided Adaptation
Apr 28, 2022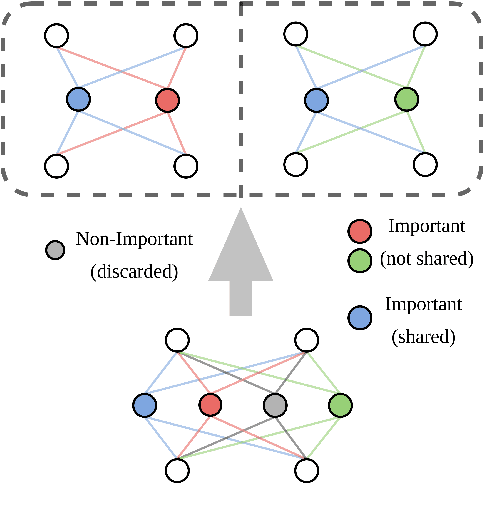
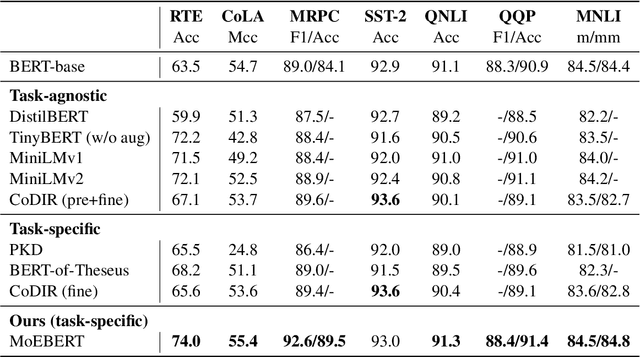
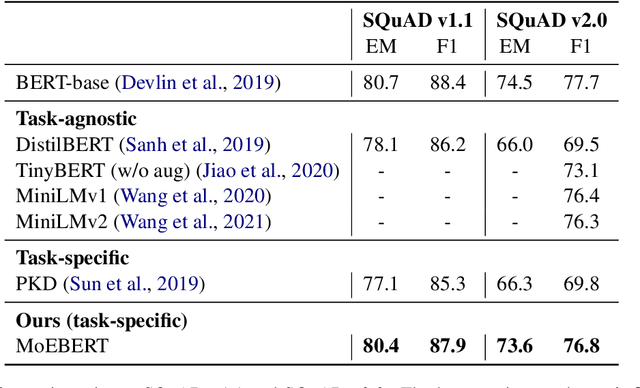
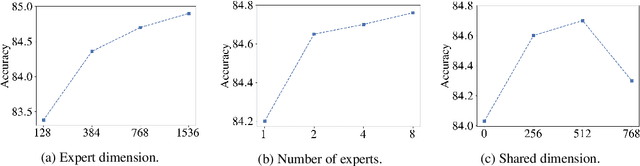
Pre-trained language models have demonstrated superior performance in various natural language processing tasks. However, these models usually contain hundreds of millions of parameters, which limits their practicality because of latency requirements in real-world applications. Existing methods train small compressed models via knowledge distillation. However, performance of these small models drops significantly compared with the pre-trained models due to their reduced model capacity. We propose MoEBERT, which uses a Mixture-of-Experts structure to increase model capacity and inference speed. We initialize MoEBERT by adapting the feed-forward neural networks in a pre-trained model into multiple experts. As such, representation power of the pre-trained model is largely retained. During inference, only one of the experts is activated, such that speed can be improved. We also propose a layer-wise distillation method to train MoEBERT. We validate the efficiency and effectiveness of MoEBERT on natural language understanding and question answering tasks. Results show that the proposed method outperforms existing task-specific distillation algorithms. For example, our method outperforms previous approaches by over 2% on the MNLI (mismatched) dataset. Our code is publicly available at https://github.com/SimiaoZuo/MoEBERT.
CAMERO: Consistency Regularized Ensemble of Perturbed Language Models with Weight Sharing
Apr 18, 2022
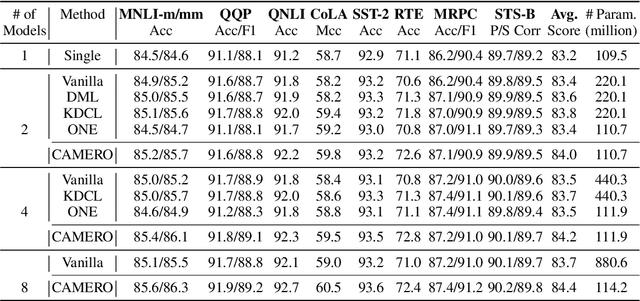
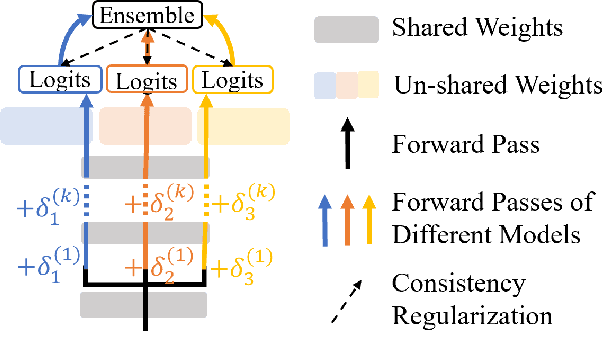
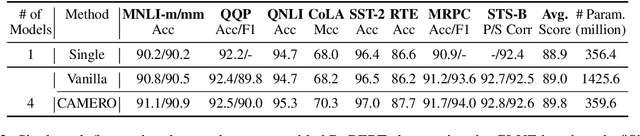
Model ensemble is a popular approach to produce a low-variance and well-generalized model. However, it induces large memory and inference costs, which are often not affordable for real-world deployment. Existing work has resorted to sharing weights among models. However, when increasing the proportion of the shared weights, the resulting models tend to be similar, and the benefits of using model ensemble diminish. To retain ensemble benefits while maintaining a low memory cost, we propose a consistency-regularized ensemble learning approach based on perturbed models, named CAMERO. Specifically, we share the weights of bottom layers across all models and apply different perturbations to the hidden representations for different models, which can effectively promote the model diversity. Meanwhile, we apply a prediction consistency regularizer across the perturbed models to control the variance due to the model diversity. Our experiments using large language models demonstrate that CAMERO significantly improves the generalization performance of the ensemble model. Specifically, CAMERO outperforms the standard ensemble of 8 BERT-base models on the GLUE benchmark by 0.7 with a significantly smaller model size (114.2M vs. 880.6M).
CERES: Pretraining of Graph-Conditioned Transformer for Semi-Structured Session Data
Apr 08, 2022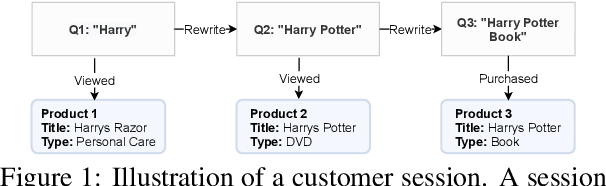
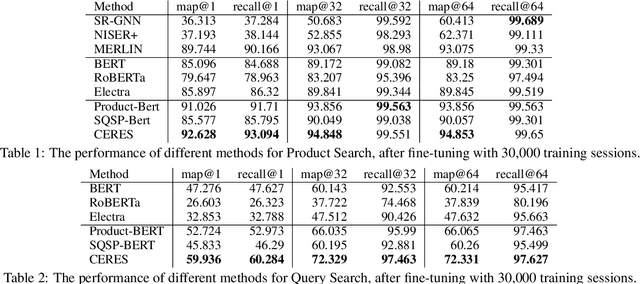
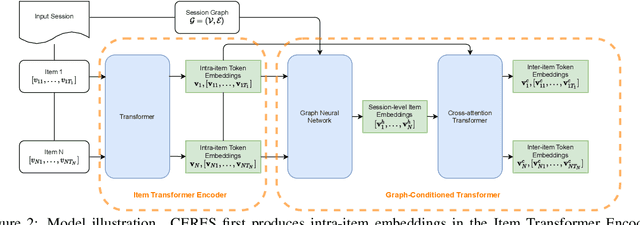
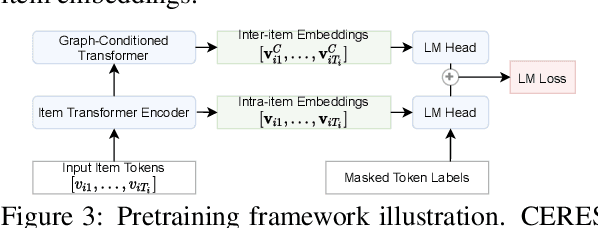
User sessions empower many search and recommendation tasks on a daily basis. Such session data are semi-structured, which encode heterogeneous relations between queries and products, and each item is described by the unstructured text. Despite recent advances in self-supervised learning for text or graphs, there lack of self-supervised learning models that can effectively capture both intra-item semantics and inter-item interactions for semi-structured sessions. To fill this gap, we propose CERES, a graph-based transformer model for semi-structured session data. CERES learns representations that capture both inter- and intra-item semantics with (1) a graph-conditioned masked language pretraining task that jointly learns from item text and item-item relations; and (2) a graph-conditioned transformer architecture that propagates inter-item contexts to item-level representations. We pretrained CERES using ~468 million Amazon sessions and find that CERES outperforms strong pretraining baselines by up to 9% in three session search and entity linking tasks.
No Parameters Left Behind: Sensitivity Guided Adaptive Learning Rate for Training Large Transformer Models
Feb 14, 2022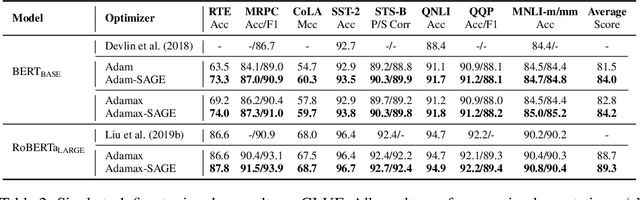
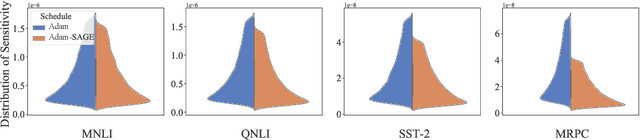

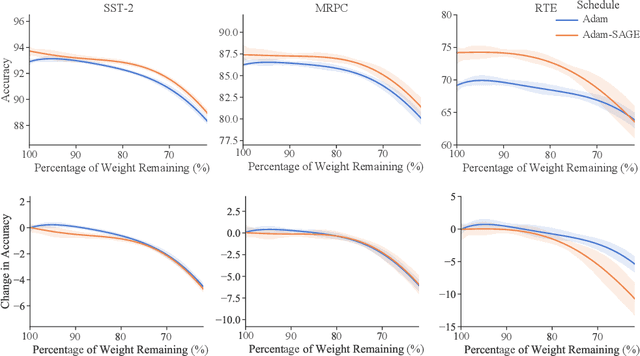
Recent research has shown the existence of significant redundancy in large Transformer models. One can prune the redundant parameters without significantly sacrificing the generalization performance. However, we question whether the redundant parameters could have contributed more if they were properly trained. To answer this question, we propose a novel training strategy that encourages all parameters to be trained sufficiently. Specifically, we adaptively adjust the learning rate for each parameter according to its sensitivity, a robust gradient-based measure reflecting this parameter's contribution to the model performance. A parameter with low sensitivity is redundant, and we improve its fitting by increasing its learning rate. In contrast, a parameter with high sensitivity is well-trained, and we regularize it by decreasing its learning rate to prevent further overfitting. We conduct extensive experiments on natural language understanding, neural machine translation, and image classification to demonstrate the effectiveness of the proposed schedule. Analysis shows that the proposed schedule indeed reduces the redundancy and improves generalization performance.
Noise Regularizes Over-parameterized Rank One Matrix Recovery, Provably
Feb 07, 2022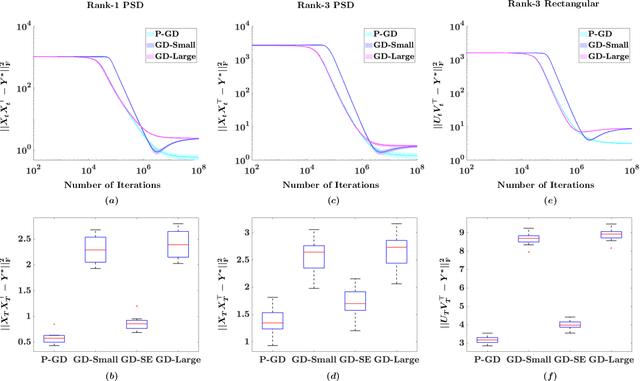
We investigate the role of noise in optimization algorithms for learning over-parameterized models. Specifically, we consider the recovery of a rank one matrix $Y^*\in R^{d\times d}$ from a noisy observation $Y$ using an over-parameterization model. We parameterize the rank one matrix $Y^*$ by $XX^\top$, where $X\in R^{d\times d}$. We then show that under mild conditions, the estimator, obtained by the randomly perturbed gradient descent algorithm using the square loss function, attains a mean square error of $O(\sigma^2/d)$, where $\sigma^2$ is the variance of the observational noise. In contrast, the estimator obtained by gradient descent without random perturbation only attains a mean square error of $O(\sigma^2)$. Our result partially justifies the implicit regularization effect of noise when learning over-parameterized models, and provides new understanding of training over-parameterized neural networks.
Homotopic Policy Mirror Descent: Policy Convergence, Implicit Regularization, and Improved Sample Complexity
Jan 30, 2022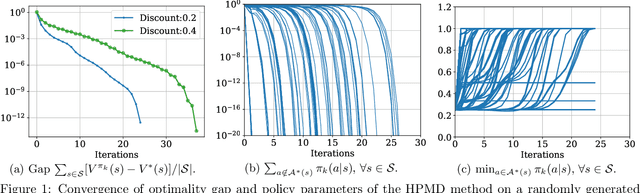
We propose the homotopic policy mirror descent (HPMD) method for solving discounted, infinite horizon MDPs with finite state and action space, and study its policy convergence. We report three properties that seem to be new in the literature of policy gradient methods: (1) HPMD exhibits global linear convergence of the value optimality gap, and local superlinear convergence of the policy to the set of optimal policies with order $\gamma^{-2}$. The superlinear convergence of the policy takes effect after no more than $\mathcal{O}(\log(1/\Delta^*))$ number of iterations, where $\Delta^*$ is defined via a gap quantity associated with the optimal state-action value function; (2) HPMD also exhibits last-iterate convergence of the policy, with the limiting policy corresponding exactly to the optimal policy with the maximal entropy for every state. No regularization is added to the optimization objective and hence the second observation arises solely as an algorithmic property of the homotopic policy gradient method. (3) For the stochastic HPMD method, we further demonstrate a better than $\mathcal{O}(|\mathcal{S}| |\mathcal{A}| / \epsilon^2)$ sample complexity for small optimality gap $\epsilon$, when assuming a generative model for policy evaluation.