 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence Adaptive Anytime Pixel-Level Recognition
Apr 01, 2021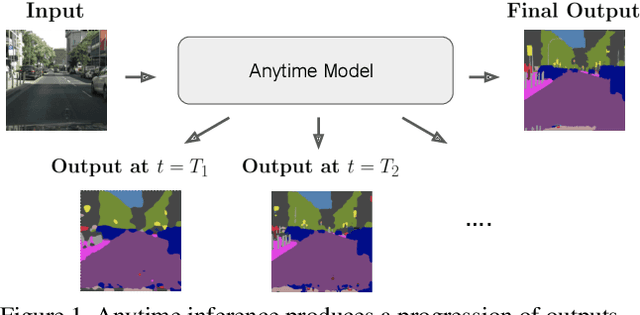
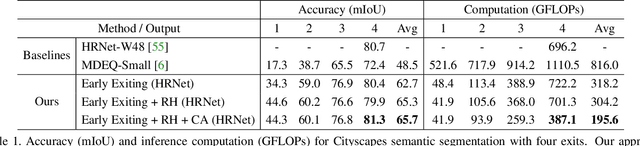
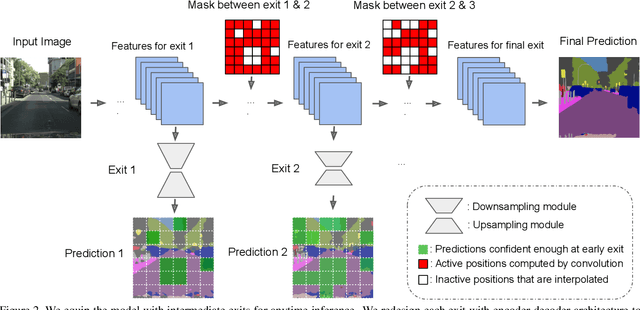
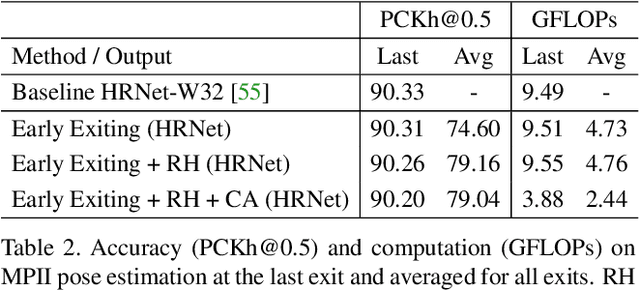
Anytime inference requires a model to make a progression of predictions which might be halted at any time. Prior research on anytime visual recognition has mostly focused on image classification. We propose the first unified and end-to-end model approach for anytime pixel-level recognition. A cascade of "exits" is attached to the model to make multiple predictions and direct further computation. We redesign the exits to account for the depth and spatial resolution of the features for each exit. To reduce total computation, and make full use of prior predictions, we develop a novel spatially adaptive approach to avoid further computation on regions where early predictions are already sufficiently confident. Our full model with redesigned exit architecture and spatial adaptivity enables anytime inference, achieves the same level of final accuracy, and even significantly reduces total computation. We evaluate our approach on semantic segmentation and human pose estimation. On Cityscapes semantic segmentation and MPII human pose estimation, our approach enables anytime inference while also reducing the total FLOPs of its base models by 44.4% and 59.1% without sacrificing accuracy. As a new anytime baseline, we measure the anytime capability of deep equilibrium networks, a recent class of model that is intrinsically iterative, and we show that the accuracy-computation curve of our architecture strictly dominates it.
Prototypical Cross-domain Self-supervised Learning for Few-shot Unsupervised Domain Adaptation
Mar 31, 2021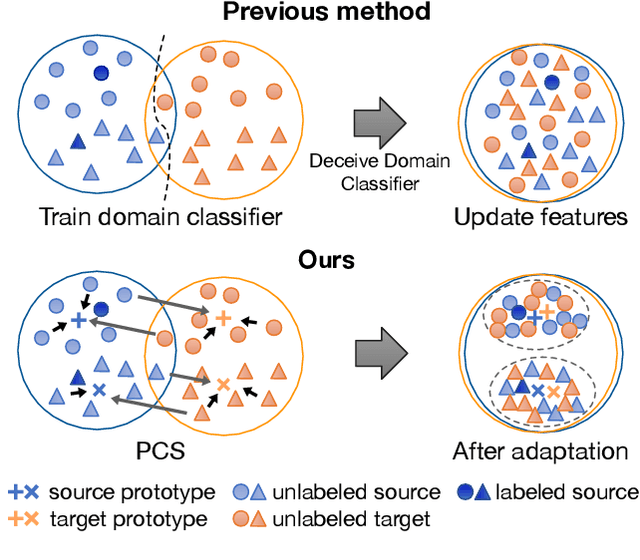
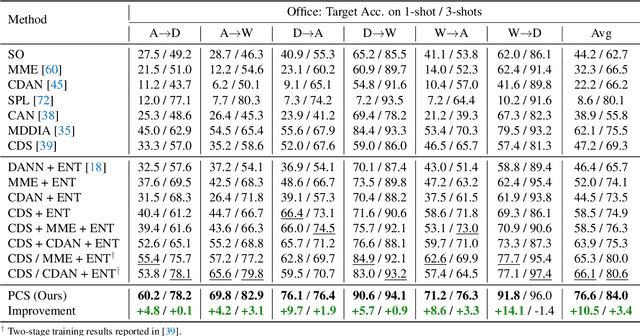
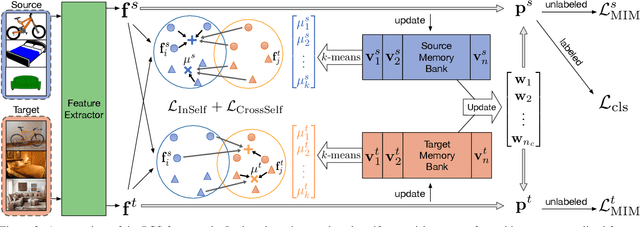
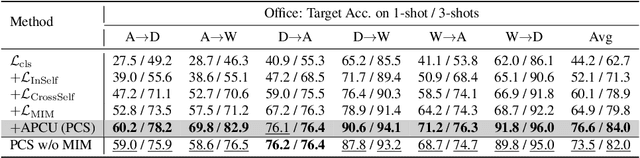
Unsupervised Domain Adaptation (UDA) transfers predictive models from a fully-labeled source domain to an unlabeled target domain. In some applications, however, it is expensive even to collect labels in the source domain, making most previous works impractical. To cope with this problem, recent work performed instance-wise cross-domain self-supervised learning, followed by an additional fine-tuning stage. However, the instance-wise self-supervised learning only learns and aligns low-level discriminative features. In this paper, we propose an end-to-end Prototypical Cross-domain Self-Supervised Learning (PCS) framework for Few-shot Unsupervised Domain Adaptation (FUDA). PCS not only performs cross-domain low-level feature alignment, but it also encodes and aligns semantic structures in the shared embedding space across domains. Our framework captures category-wise semantic structures of the data by in-domain prototypical contrastive learning; and performs feature alignment through cross-domain prototypical self-supervision. Compared with state-of-the-art methods, PCS improves the mean classification accuracy over different domain pairs on FUDA by 10.5%, 3.5%, 9.0%, and 13.2% on Office, Office-Home, VisDA-2017, and DomainNet, respectively. Our project page is at http://xyue.io/pcs-fuda/index.html
Self-Supervised Pretraining Improves Self-Supervised Pretraining
Mar 25, 2021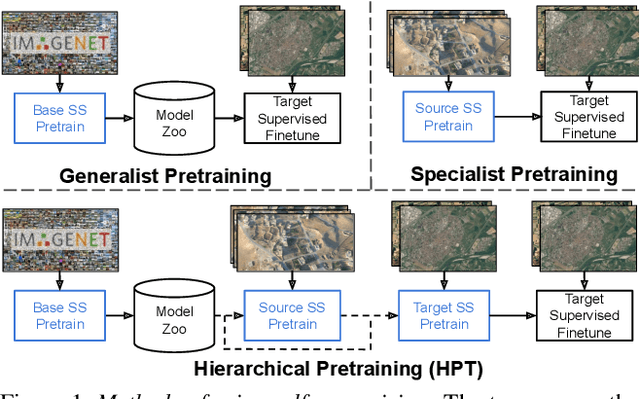
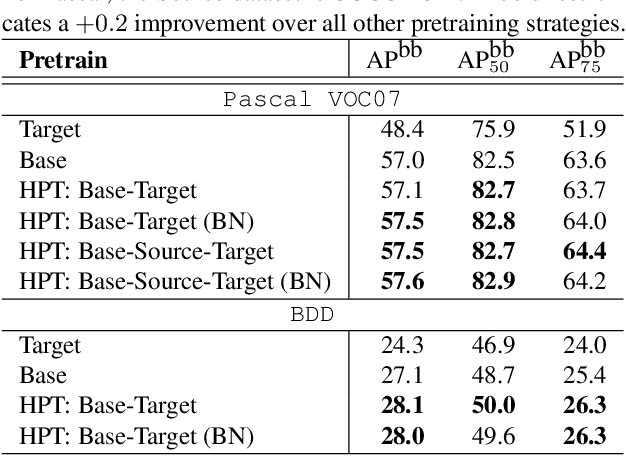
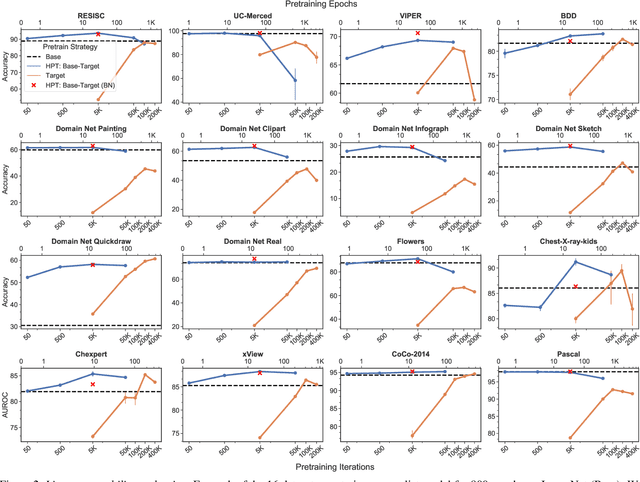
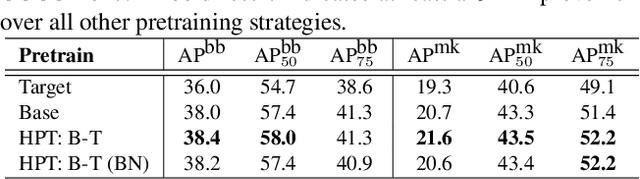
While self-supervised pretraining has proven beneficial for many computer vision tasks, it requires expensive and lengthy computation, large amounts of data, and is sensitive to data augmentation. Prior work demonstrates that models pretrained on datasets dissimilar to their target data, such as chest X-ray models trained on ImageNet, underperform models trained from scratch. Users that lack the resources to pretrain must use existing models with lower performance. This paper explores Hierarchical PreTraining (HPT), which decreases convergence time and improves accuracy by initializing the pretraining process with an existing pretrained model. Through experimentation on 16 diverse vision datasets, we show HPT converges up to 80x faster, improves accuracy across tasks, and improves the robustness of the self-supervised pretraining process to changes in the image augmentation policy or amount of pretraining data. Taken together, HPT provides a simple framework for obtaining better pretrained representations with less computational resources.
Region Similarity Representation Learning
Mar 24, 2021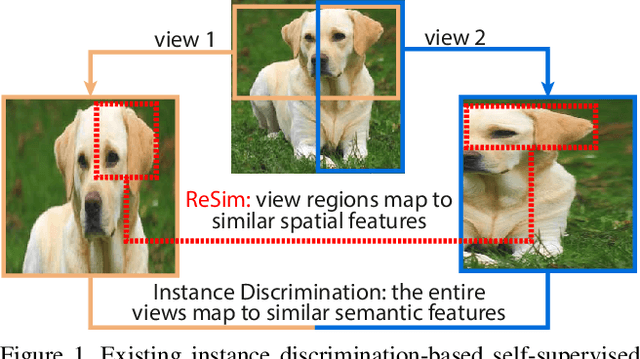
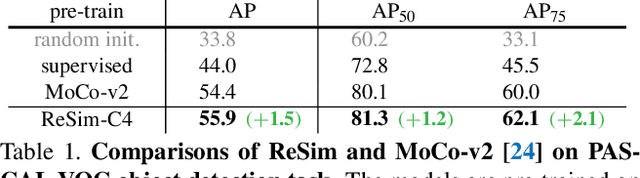
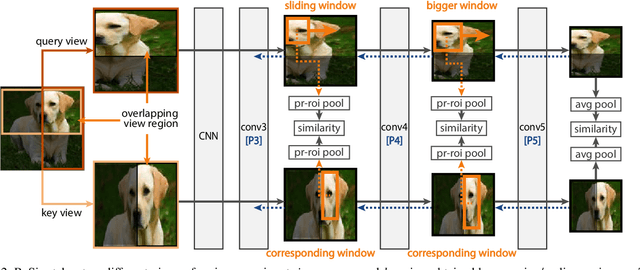
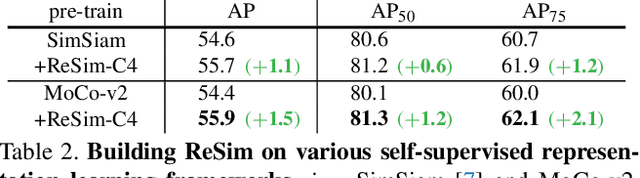
We present Region Similarity Representation Learning (ReSim), a new approach to self-supervised representation learning for localization-based tasks such as object detection and segmentation. While existing work has largely focused on solely learning global representations for an entire image, ReSim learns both regional representations for localization as well as semantic image-level representations. ReSim operates by sliding a fixed-sized window across the overlapping area between two views (e.g., image crops), aligning these areas with their corresponding convolutional feature map regions, and then maximizing the feature similarity across views. As a result, ReSim learns spatially and semantically consistent feature representation throughout the convolutional feature maps of a neural network. A shift or scale of an image region, e.g., a shift or scale of an object, has a corresponding change in the feature maps; this allows downstream tasks to leverage these representations for localization. Through object detection, instance segmentation, and dense pose estimation experiments, we illustrate how ReSim learns representations which significantly improve the localization and classification performance compared to a competitive MoCo-v2 baseline: $+2.7$ AP$^{\text{bb}}_{75}$ VOC, $+1.1$ AP$^{\text{bb}}_{75}$ COCO, and $+1.9$ AP$^{\text{mk}}$ Cityscapes. Code and pre-trained models are released at: \url{https://github.com/Tete-Xiao/ReSim}
Monocular Quasi-Dense 3D Object Tracking
Mar 12, 2021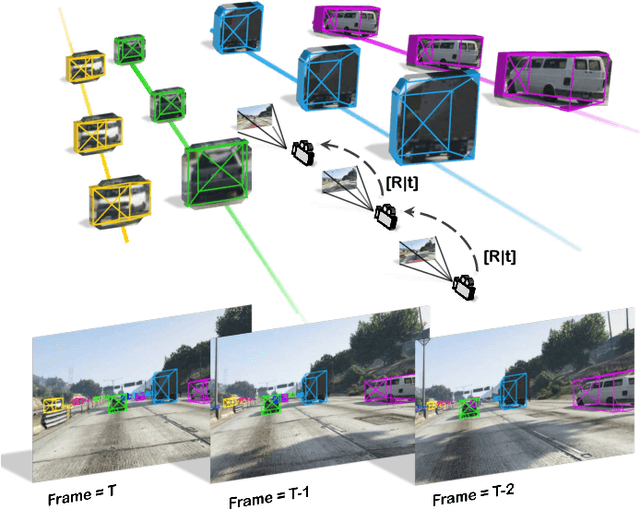
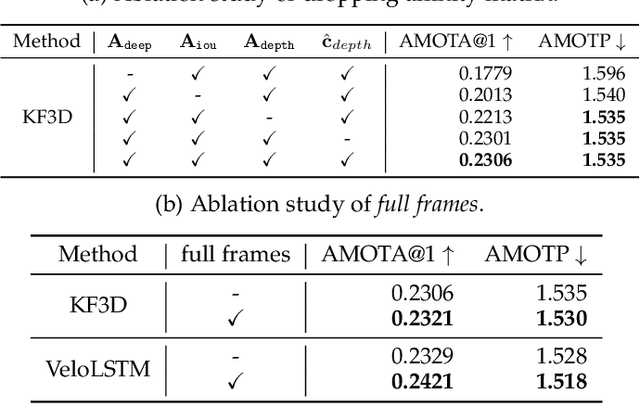
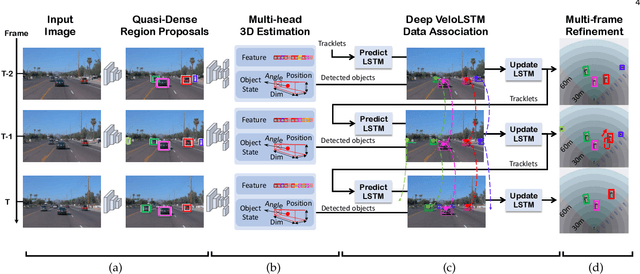
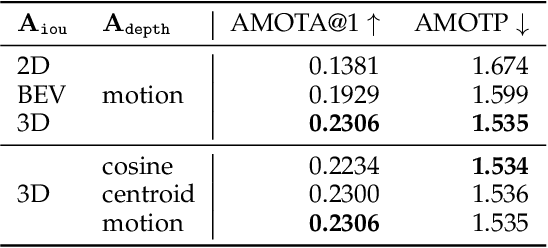
A reliable and accurate 3D tracking framework is essential for predicting future locations of surrounding objects and planning the observer's actions in numerous applications such as autonomous driving. We propose a framework that can effectively associate moving objects over time and estimate their full 3D bounding box information from a sequence of 2D images captured on a moving platform. The object association leverages quasi-dense similarity learning to identify objects in various poses and viewpoints with appearance cues only. After initial 2D association, we further utilize 3D bounding boxes depth-ordering heuristics for robust instance association and motion-based 3D trajectory prediction for re-identification of occluded vehicles. In the end, an LSTM-based object velocity learning module aggregates the long-term trajectory information for more accurate motion extrapolation. Experiments on our proposed simulation data and real-world benchmarks, including KITTI, nuScenes, and Waymo datasets, show that our tracking framework offers robust object association and tracking on urban-driving scenarios. On the Waymo Open benchmark, we establish the first camera-only baseline in the 3D tracking and 3D detection challenges. Our quasi-dense 3D tracking pipeline achieves impressive improvements on the nuScenes 3D tracking benchmark with near five times tracking accuracy of the best vision-only submission among all published methods. Our code, data and trained models are available at https://github.com/SysCV/qd-3dt.
Instance-Aware Predictive Navigation in Multi-Agent Environments
Jan 14, 2021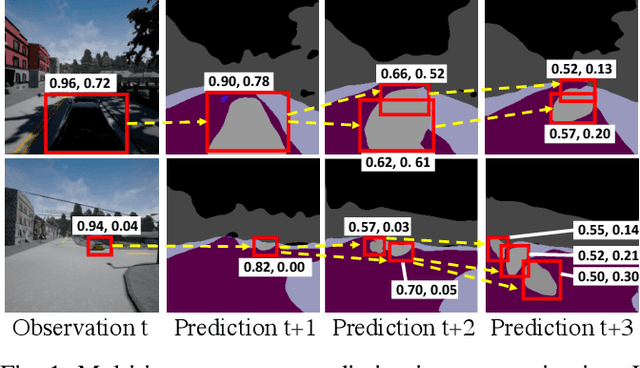
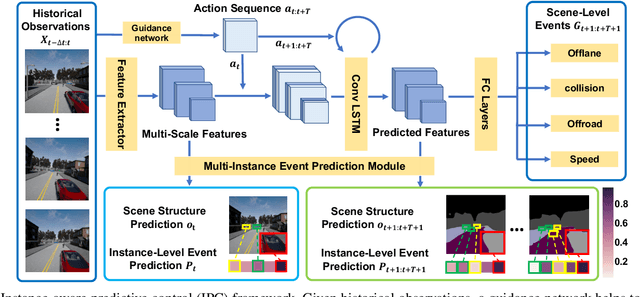

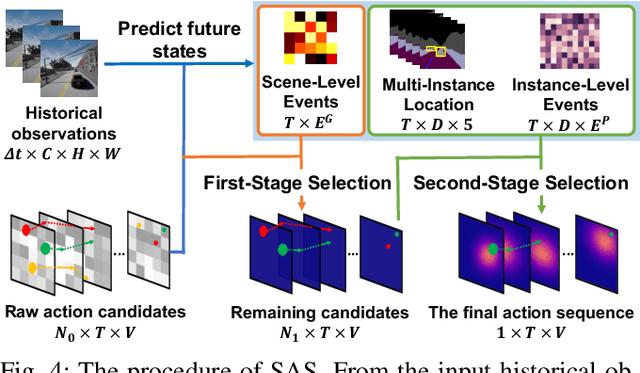
In this work, we aim to achieve efficient end-to-end learning of driving policies in dynamic multi-agent environments. Predicting and anticipating future events at the object level are critical for making informed driving decisions. We propose an Instance-Aware Predictive Control (IPC) approach, which forecasts interactions between agents as well as future scene structures. We adopt a novel multi-instance event prediction module to estimate the possible interaction among agents in the ego-centric view, conditioned on the selected action sequence of the ego-vehicle. To decide the action at each step, we seek the action sequence that can lead to safe future states based on the prediction module outputs by repeatedly sampling likely action sequences. We design a sequential action sampling strategy to better leverage predicted states on both scene-level and instance-level. Our method establishes a new state of the art in the challenging CARLA multi-agent driving simulation environments without expert demonstration, giving better explainability and sample efficiency.
Minimax Active Learning
Dec 18, 2020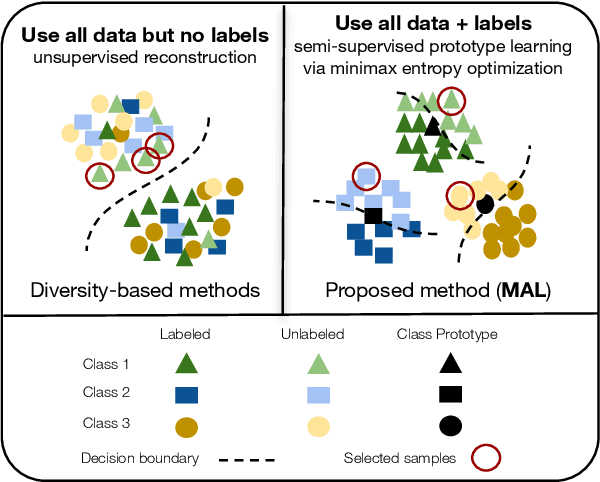
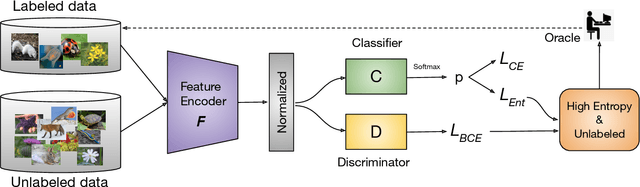

Active learning aims to develop label-efficient algorithms by querying the most representative samples to be labeled by a human annotator. Current active learning techniques either rely on model uncertainty to select the most uncertain samples or use clustering or reconstruction to choose the most diverse set of unlabeled examples. While uncertainty-based strategies are susceptible to outliers, solely relying on sample diversity does not capture the information available on the main task. In this work, we develop a semi-supervised minimax entropy-based active learning algorithm that leverages both uncertainty and diversity in an adversarial manner. Our model consists of an entropy minimizing feature encoding network followed by an entropy maximizing classification layer. This minimax formulation reduces the distribution gap between the labeled/unlabeled data, while a discriminator is simultaneously trained to distinguish the labeled/unlabeled data. The highest entropy samples from the classifier that the discriminator predicts as unlabeled are selected for labeling. We extensively evaluate our method on various image classification and semantic segmentation benchmark datasets and show superior performance over the state-of-the-art methods.
Temporal Action Detection with Multi-level Supervision
Nov 24, 2020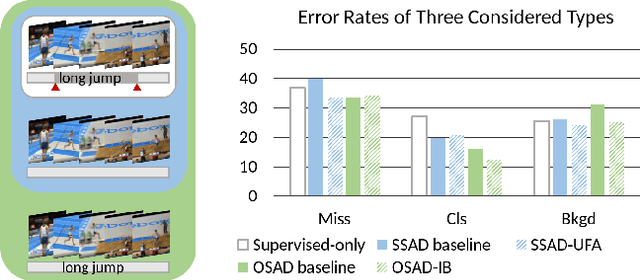
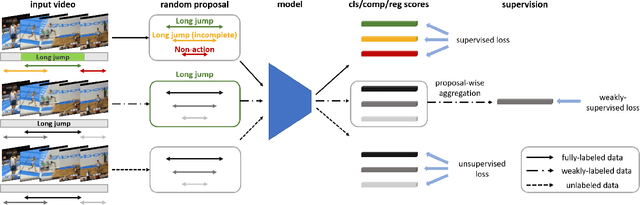
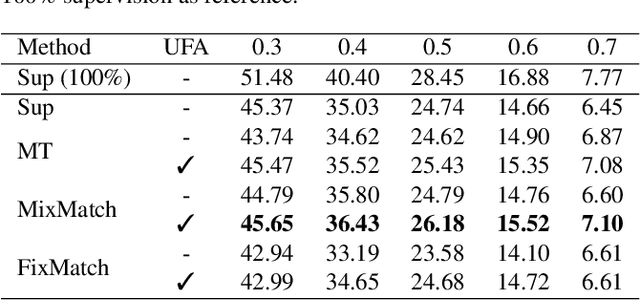
Training temporal action detection in videos requires large amounts of labeled data, yet such annotation is expensive to collect. Incorporating unlabeled or weakly-labeled data to train action detection model could help reduce annotation cost. In this work, we first introduce the Semi-supervised Action Detection (SSAD) task with a mixture of labeled and unlabeled data and analyze different types of errors in the proposed SSAD baselines which are directly adapted from the semi-supervised classification task. To alleviate the main error of action incompleteness (i.e., missing parts of actions) in SSAD baselines, we further design an unsupervised foreground attention (UFA) module utilizing the "independence" between foreground and background motion. Then we incorporate weakly-labeled data into SSAD and propose Omni-supervised Action Detection (OSAD) with three levels of supervision. An information bottleneck (IB) suppressing the scene information in non-action frames while preserving the action information is designed to help overcome the accompanying action-context confusion problem in OSAD baselines. We extensively benchmark against the baselines for SSAD and OSAD on our created data splits in THUMOS14 and ActivityNet1.2, and demonstrate the effectiveness of the proposed UFA and IB methods. Lastly, the benefit of our full OSAD-IB model under limited annotation budgets is shown by exploring the optimal annotation strategy for labeled, unlabeled and weakly-labeled data.
Fighting Copycat Agents in Behavioral Cloning from Observation Histories
Oct 28, 2020



Imitation learning trains policies to map from input observations to the actions that an expert would choose. In this setting, distribution shift frequently exacerbates the effect of misattributing expert actions to nuisance correlates among the observed variables. We observe that a common instance of this causal confusion occurs in partially observed settings when expert actions are strongly correlated over time: the imitator learns to cheat by predicting the expert's previous action, rather than the next action. To combat this "copycat problem", we propose an adversarial approach to learn a feature representation that removes excess information about the previous expert action nuisance correlate, while retaining the information necessary to predict the next action. In our experiments, our approach improves performance significantly across a variety of partially observed imitation learning tasks.
Modularity Improves Out-of-Domain Instruction Following
Oct 24, 2020
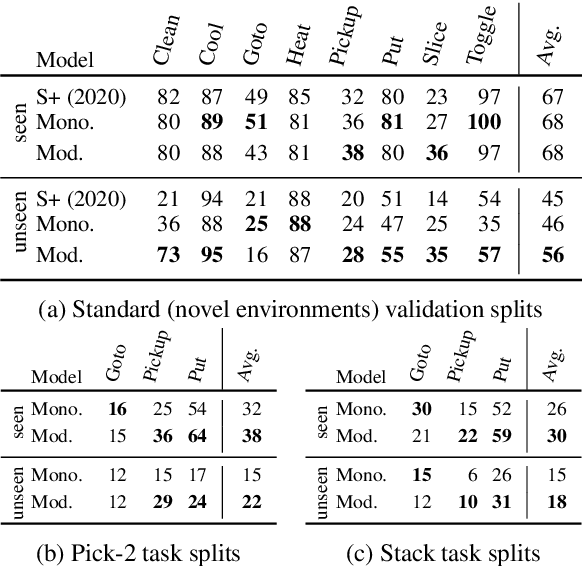
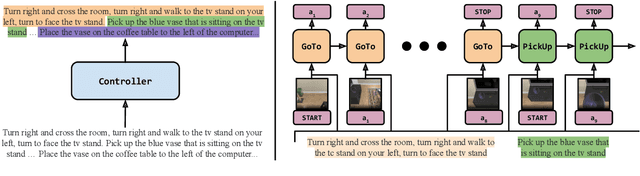

We propose a modular architecture for following natural language instructions that describe sequences of diverse subgoals, such as navigating to landmarks or picking up objects. Standard, non-modular, architectures used in instruction following do not exploit subgoal compositionality and often struggle on out-of-distribution tasks and environments. In our approach, subgoal modules each carry out natural language instructions for a specific subgoal type. A sequence of modules to execute is chosen by learning to segment the instructions and predicting a subgoal type for each segment. When compared to standard sequence-to-sequence approaches on ALFRED, a challenging instruction following benchmark, we find that modularization improves generalization to environments unseen in training and to novel tasks.