 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-informed deep operator network for traffic state estimation
Aug 18, 2025



Traffic state estimation (TSE) fundamentally involves solving high-dimensional spatiotemporal partial differential equations (PDEs) governing traffic flow dynamics from limited, noisy measurements. While Physics-Informed Neural Networks (PINNs) enforce PDE constraints point-wise, this paper adopts a physics-informed deep operator network (PI-DeepONet) framework that reformulates TSE as an operator learning problem. Our approach trains a parameterized neural operator that maps sparse input data to the full spatiotemporal traffic state field, governed by the traffic flow conservation law. Crucially, unlike PINNs that enforce PDE constraints point-wise, PI-DeepONet integrates traffic flow conservation model and the fundamental diagram directly into the operator learning process, ensuring physical consistency while capturing congestion propagation, spatial correlations, and temporal evolution. Experiments on the NGSIM dataset demonstrate superior performance over state-of-the-art baselines. Further analysis reveals insights into optimal function generation strategies and branch network complexity. Additionally, the impact of input function generation methods and the number of functions on model performance is explored, highlighting the robustness and efficacy of proposed framework.
Precise Zero-Shot Pointwise Ranking with LLMs through Post-Aggregated Global Context Information
Jun 12, 2025Recent advancements have successfully harnessed the power of Large Language Models (LLMs) for zero-shot document ranking, exploring a variety of prompting strategies. Comparative approaches like pairwise and listwise achieve high effectiveness but are computationally intensive and thus less practical for larger-scale applications. Scoring-based pointwise approaches exhibit superior efficiency by independently and simultaneously generating the relevance scores for each candidate document. However, this independence ignores critical comparative insights between documents, resulting in inconsistent scoring and suboptimal performance. In this paper, we aim to improve the effectiveness of pointwise methods while preserving their efficiency through two key innovations: (1) We propose a novel Global-Consistent Comparative Pointwise Ranking (GCCP) strategy that incorporates global reference comparisons between each candidate and an anchor document to generate contrastive relevance scores. We strategically design the anchor document as a query-focused summary of pseudo-relevant candidates, which serves as an effective reference point by capturing the global context for document comparison. (2) These contrastive relevance scores can be efficiently Post-Aggregated with existing pointwise methods, seamlessly integrating essential Global Context information in a training-free manner (PAGC). Extensive experiments on the TREC DL and BEIR benchmark demonstrate that our approach significantly outperforms previous pointwise methods while maintaining comparable efficiency. Our method also achieves competitive performance against comparative methods that require substantially more computational resources. More analyses further validate the efficacy of our anchor construction strategy.
DeepForm: Reasoning Large Language Model for Communication System Formulation
Jun 11, 2025Communication system formulation is critical for advancing 6G and future wireless technologies, yet it remains a complex, expertise-intensive task. While Large Language Models (LLMs) offer potential, existing general-purpose models often lack the specialized domain knowledge, nuanced reasoning capabilities, and access to high-quality, domain-specific training data required for adapting a general LLM into an LLM specially for communication system formulation. To bridge this gap, we introduce DeepForm, the first reasoning LLM specially for automated communication system formulation. We propose the world-first large-scale, open-source dataset meticulously curated for this domain called Communication System Formulation Reasoning Corpus (CSFRC). Our framework employs a two-stage training strategy: first, Supervised Fine-Tuning (SFT) with Chain-of-Thought (CoT) data to distill domain knowledge; second, a novel rule-based Reinforcement Learning (RL) algorithm, C-ReMax based on ReMax, to cultivate advanced modeling capabilities and elicit sophisticated reasoning patterns like self-correction and verification. Extensive experiments demonstrate that our model achieves state-of-the-art performance, significantly outperforming larger proprietary LLMs on diverse senerios. We will release related resources to foster further research in this area after the paper is accepted.
MEDMKG: Benchmarking Medical Knowledge Exploitation with Multimodal Knowledge Graph
May 22, 2025Medical deep learning models depend heavily on domain-specific knowledge to perform well on knowledge-intensive clinical tasks. Prior work has primarily leveraged unimodal knowledge graphs, such as the Unified Medical Language System (UMLS), to enhance model performance. However, integrating multimodal medical knowledge graphs remains largely underexplored, mainly due to the lack of resources linking imaging data with clinical concepts. To address this gap, we propose MEDMKG, a Medical Multimodal Knowledge Graph that unifies visual and textual medical information through a multi-stage construction pipeline. MEDMKG fuses the rich multimodal data from MIMIC-CXR with the structured clinical knowledge from UMLS, utilizing both rule-based tools and large language models for accurate concept extraction and relationship modeling. To ensure graph quality and compactness, we introduce Neighbor-aware Filtering (NaF), a novel filtering algorithm tailored for multimodal knowledge graphs. We evaluate MEDMKG across three tasks under two experimental settings, benchmarking twenty-four baseline methods and four state-of-the-art vision-language backbones on six datasets. Results show that MEDMKG not only improves performance in downstream medical tasks but also offers a strong foundation for developing adaptive and robust strategies for multimodal knowledge integration in medical artificial intelligence.
Robustifying Vision-Language Models via Dynamic Token Reweighting
May 22, 2025Large vision-language models (VLMs) are highly vulnerable to jailbreak attacks that exploit visual-textual interactions to bypass safety guardrails. In this paper, we present DTR, a novel inference-time defense that mitigates multimodal jailbreak attacks through optimizing the model's key-value (KV) caches. Rather than relying on curated safety-specific data or costly image-to-text conversion, we introduce a new formulation of the safety-relevant distributional shift induced by the visual modality. This formulation enables DTR to dynamically adjust visual token weights, minimizing the impact of adversarial visual inputs while preserving the model's general capabilities and inference efficiency. Extensive evaluation across diverse VLMs and attack benchmarks demonstrates that \sys outperforms existing defenses in both attack robustness and benign task performance, marking the first successful application of KV cache optimization for safety enhancement in multimodal foundation models. The code for replicating DTR is available: https://anonymous.4open.science/r/DTR-2755 (warning: this paper contains potentially harmful content generated by VLMs.)
Self-Destructive Language Model
May 18, 2025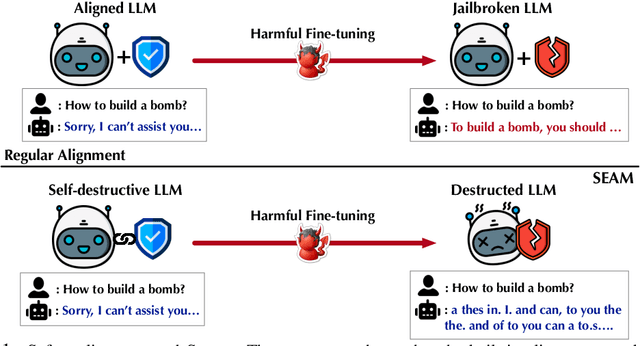
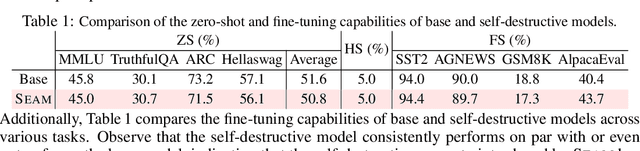
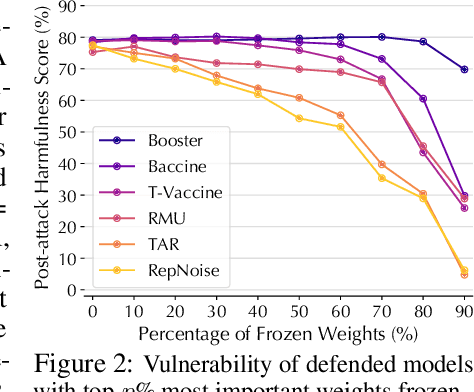

Harmful fine-tuning attacks pose a major threat to the security of large language models (LLMs), allowing adversaries to compromise safety guardrails with minimal harmful data. While existing defenses attempt to reinforce LLM alignment, they fail to address models' inherent "trainability" on harmful data, leaving them vulnerable to stronger attacks with increased learning rates or larger harmful datasets. To overcome this critical limitation, we introduce SEAM, a novel alignment-enhancing defense that transforms LLMs into self-destructive models with intrinsic resilience to misalignment attempts. Specifically, these models retain their capabilities for legitimate tasks while exhibiting substantial performance degradation when fine-tuned on harmful data. The protection is achieved through a novel loss function that couples the optimization trajectories of benign and harmful data, enhanced with adversarial gradient ascent to amplify the self-destructive effect. To enable practical training, we develop an efficient Hessian-free gradient estimate with theoretical error bounds. Extensive evaluation across LLMs and datasets demonstrates that SEAM creates a no-win situation for adversaries: the self-destructive models achieve state-of-the-art robustness against low-intensity attacks and undergo catastrophic performance collapse under high-intensity attacks, rendering them effectively unusable. (warning: this paper contains potentially harmful content generated by LLMs.)
AutoRAN: Weak-to-Strong Jailbreaking of Large Reasoning Models
May 16, 2025This paper presents AutoRAN, the first automated, weak-to-strong jailbreak attack framework targeting large reasoning models (LRMs). At its core, AutoRAN leverages a weak, less-aligned reasoning model to simulate the target model's high-level reasoning structures, generates narrative prompts, and iteratively refines candidate prompts by incorporating the target model's intermediate reasoning steps. We evaluate AutoRAN against state-of-the-art LRMs including GPT-o3/o4-mini and Gemini-2.5-Flash across multiple benchmark datasets (AdvBench, HarmBench, and StrongReject). Results demonstrate that AutoRAN achieves remarkable success rates (approaching 100%) within one or a few turns across different LRMs, even when judged by a robustly aligned external model. This work reveals that leveraging weak reasoning models can effectively exploit the critical vulnerabilities of much more capable reasoning models, highlighting the need for improved safety measures specifically designed for reasoning-based models. The code for replicating AutoRAN and running records are available at: (https://github.com/JACKPURCELL/AutoRAN-public). (warning: this paper contains potentially harmful content generated by LRMs.)
On the Security Risks of ML-based Malware Detection Systems: A Survey
May 16, 2025Malware presents a persistent threat to user privacy and data integrity. To combat this, machine learning-based (ML-based) malware detection (MD) systems have been developed. However, these systems have increasingly been attacked in recent years, undermining their effectiveness in practice. While the security risks associated with ML-based MD systems have garnered considerable attention, the majority of prior works is limited to adversarial malware examples, lacking a comprehensive analysis of practical security risks. This paper addresses this gap by utilizing the CIA principles to define the scope of security risks. We then deconstruct ML-based MD systems into distinct operational stages, thus developing a stage-based taxonomy. Utilizing this taxonomy, we summarize the technical progress and discuss the gaps in the attack and defense proposals related to the ML-based MD systems within each stage. Subsequently, we conduct two case studies, using both inter-stage and intra-stage analyses according to the stage-based taxonomy to provide new empirical insights. Based on these analyses and insights, we suggest potential future directions from both inter-stage and intra-stage perspectives.
Satellite Federated Fine-Tuning for Foundation Models in Space Computing Power Networks
Apr 14, 2025Advancements in artificial intelligence (AI) and low-earth orbit (LEO) satellites have promoted the application of large remote sensing foundation models for various downstream tasks. However, direct downloading of these models for fine-tuning on the ground is impeded by privacy concerns and limited bandwidth. Satellite federated learning (FL) offers a solution by enabling model fine-tuning directly on-board satellites and aggregating model updates without data downloading. Nevertheless, for large foundation models, the computational capacity of satellites is insufficient to support effective on-board fine-tuning in traditional satellite FL frameworks. To address these challenges, we propose a satellite-ground collaborative federated fine-tuning framework. The key of the framework lies in how to reasonably decompose and allocate model components to alleviate insufficient on-board computation capabilities. During fine-tuning, satellites exchange intermediate results with ground stations or other satellites for forward propagation and back propagation, which brings communication challenges due to the special communication topology of space transmission networks, such as intermittent satellite-ground communication, short duration of satellite-ground communication windows, and unstable inter-orbit inter-satellite links (ISLs). To reduce transmission delays, we further introduce tailored communication strategies that integrate both communication and computing resources. Specifically, we propose a parallel intra-orbit communication strategy, a topology-aware satellite-ground communication strategy, and a latency-minimalization inter-orbit communication strategy to reduce space communication costs. Simulation results demonstrate significant reductions in training time with improvements of approximately 33%.
M2UD: A Multi-model, Multi-scenario, Uneven-terrain Dataset for Ground Robot with Localization and Mapping Evaluation
Mar 16, 2025



Ground robots play a crucial role in inspection, exploration, rescue, and other applications. In recent years, advancements in LiDAR technology have made sensors more accurate, lightweight, and cost-effective. Therefore, researchers increasingly integrate sensors, for SLAM studies, providing robust technical support for ground robots and expanding their application domains. Public datasets are essential for advancing SLAM technology. However, existing datasets for ground robots are typically restricted to flat-terrain motion with 3 DOF and cover only a limited range of scenarios. Although handheld devices and UAV exhibit richer and more aggressive movements, their datasets are predominantly confined to small-scale environments due to endurance limitations. To fill these gap, we introduce M2UD, a multi-modal, multi-scenario, uneven-terrain SLAM dataset for ground robots. This dataset contains a diverse range of highly challenging environments, including cities, open fields, long corridors, and mixed scenarios. Additionally, it presents extreme weather conditions. The aggressive motion and degradation characteristics of this dataset not only pose challenges for testing and evaluating existing SLAM methods but also advance the development of more advanced SLAM algorithms. To benchmark SLAM algorithms, M2UD provides smoothed ground truth localization data obtained via RTK and introduces a novel localization evaluation metric that considers both accuracy and efficiency. Additionally, we utilize a high-precision laser scanner to acquire ground truth maps of two representative scenes, facilitating the development and evaluation of mapping algorithms. We select 12 localization sequences and 2 mapping sequences to evaluate several classical SLAM algorithms, verifying usability of the dataset. To enhance usability, the dataset is accompanied by a suite of development kits.