 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Convex Tensor Low-Rank Approximation for Infrared Small Target Detection
May 31, 2021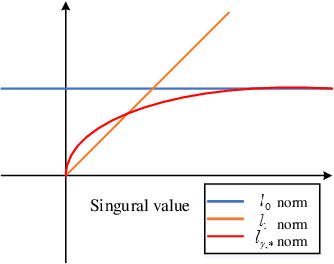



Infrared small target detection plays an important role in many infrared systems. Recently, many infrared small target detection methods have been proposed, in which the lowrank model has been used as a powerful tool. However, most low-rank-based methods assign the same weights for different singular values, which will lead to inaccurate background estimation. Considering that different singular values have different importance and should be treated discriminatively, in this paper, we propose a non-convex tensor low-rank approximation (NTLA) method for infrared small target detection. In our method, NTLA adaptively assigns different weights to different singular values for accurate background estimation. Based on the proposed NTLA, we use the asymmetric spatial-temporal total variation (ASTTV) to thoroughly describe background feature, which can achieve good background estimation and detection in complex scenes. Compared with the traditional total variation approach, ASTTV exploits different smoothness strength for spatial and temporal regularization. We develop an efficient algorithm to find the optimal solution of the proposed model. Compared with some state-of-the-art methods, the proposed method achieve an improvement in different evaluation metrics. Extensive experiments on both synthetic and real data demonstrate the proposed method provide a more robust detection in complex situations with low false rates.
Language Model as an Annotator: Exploring DialoGPT for Dialogue Summarization
May 28, 2021
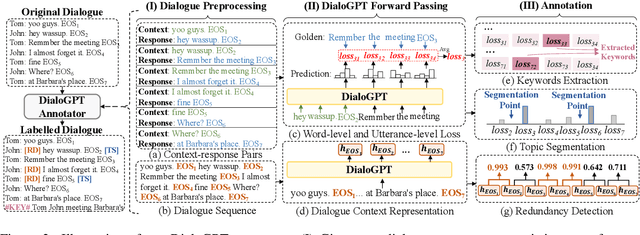
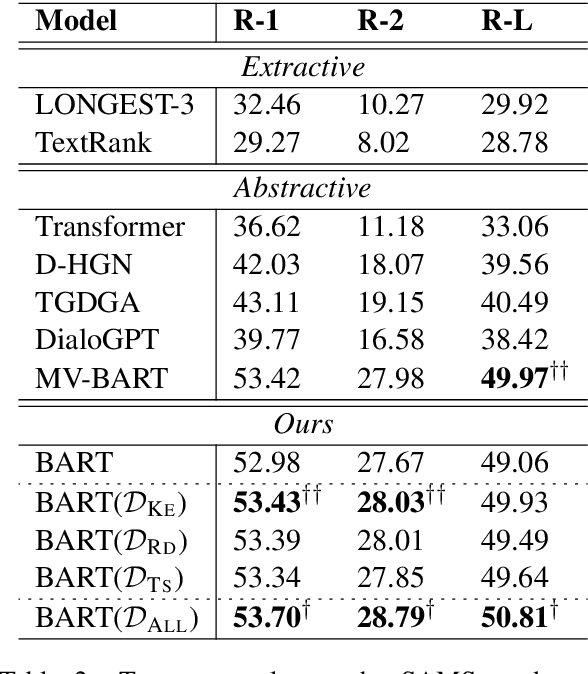
Current dialogue summarization systems usually encode the text with a number of general semantic features (e.g., keywords and topics) to gain more powerful dialogue modeling capabilities. However, these features are obtained via open-domain toolkits that are dialog-agnostic or heavily relied on human annotations. In this paper, we show how DialoGPT, a pre-trained model for conversational response generation, can be developed as an unsupervised dialogue annotator, which takes advantage of dialogue background knowledge encoded in DialoGPT. We apply DialoGPT to label three types of features on two dialogue summarization datasets, SAMSum and AMI, and employ pre-trained and non pre-trained models as our summarizes. Experimental results show that our proposed method can obtain remarkable improvements on both datasets and achieves new state-of-the-art performance on the SAMSum dataset.
ExpMRC: Explainability Evaluation for Machine Reading Comprehension
May 10, 2021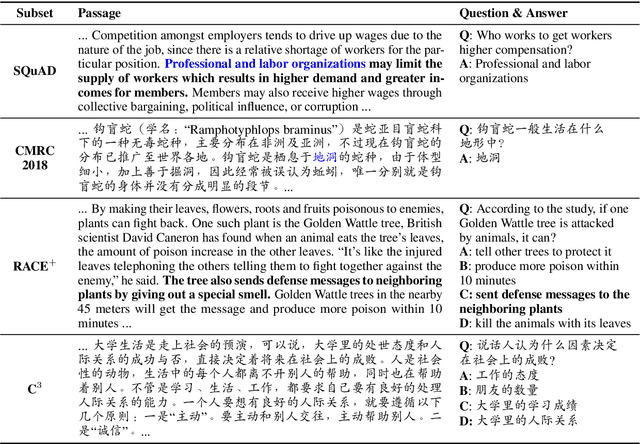
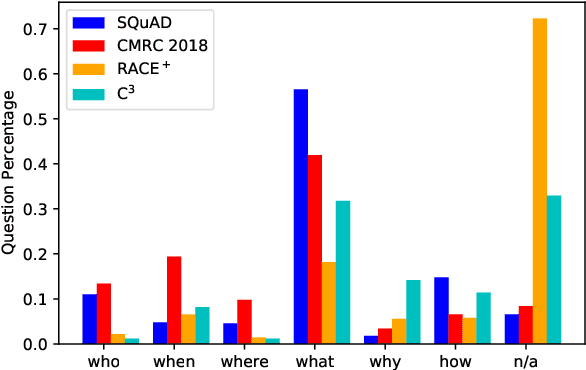
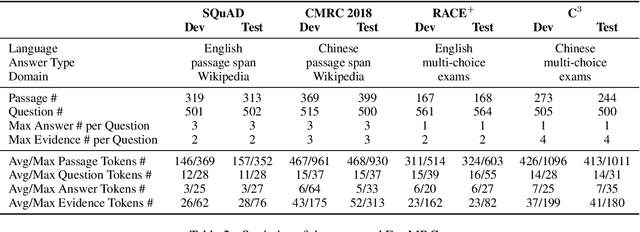
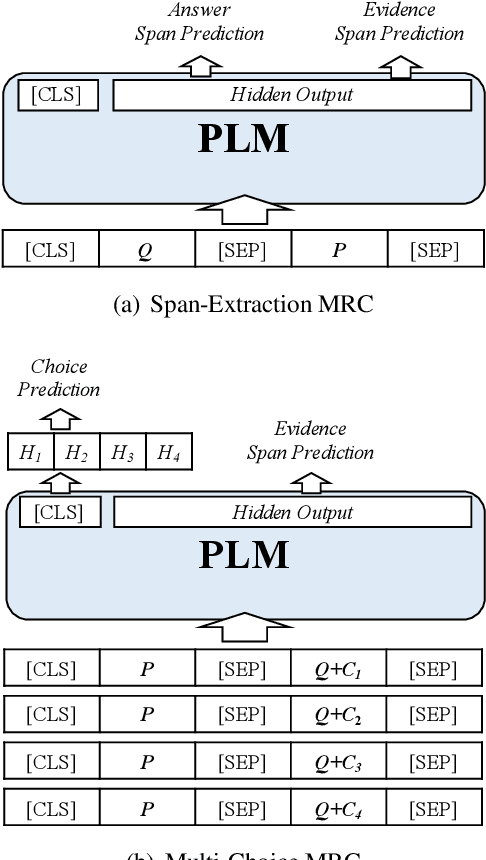
Achieving human-level performance on some of Machine Reading Comprehension (MRC) datasets is no longer challenging with the help of powerful Pre-trained Language Models (PLMs). However, it is necessary to provide both answer prediction and its explanation to further improve the MRC system's reliability, especially for real-life applications. In this paper, we propose a new benchmark called ExpMRC for evaluating the explainability of the MRC systems. ExpMRC contains four subsets, including SQuAD, CMRC 2018, RACE$^+$, and C$^3$ with additional annotations of the answer's evidence. The MRC systems are required to give not only the correct answer but also its explanation. We use state-of-the-art pre-trained language models to build baseline systems and adopt various unsupervised approaches to extract evidence without a human-annotated training set. The experimental results show that these models are still far from human performance, suggesting that the ExpMRC is challenging. Resources will be available through https://github.com/ymcui/expmrc
DADgraph: A Discourse-aware Dialogue Graph Neural Network for Multiparty Dialogue Machine Reading Comprehension
Apr 26, 2021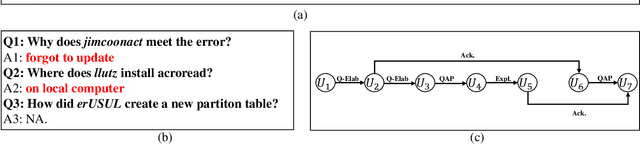
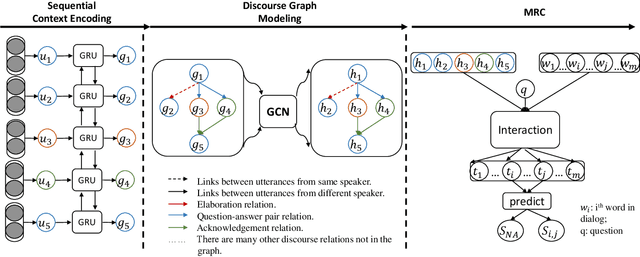
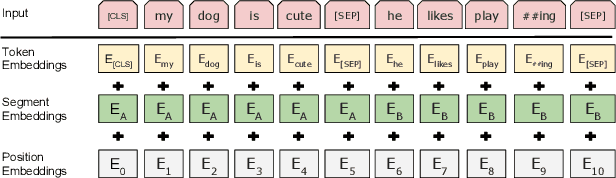
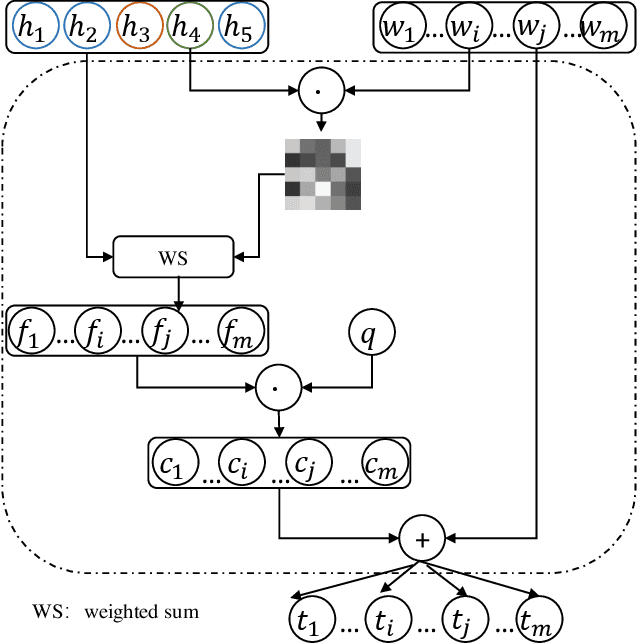
Multiparty Dialogue Machine Reading Comprehension (MRC) differs from traditional MRC as models must handle the complex dialogue discourse structure, previously unconsidered in traditional MRC. To fully exploit such discourse structure in multiparty dialogue, we present a discourse-aware dialogue graph neural network, DADgraph, which explicitly constructs the dialogue graph using discourse dependency links and discourse relations. To validate our model, we perform experiments on the Molweni corpus, a large-scale MRC dataset built over multiparty dialogue annotated with discourse structure. Experiments on Molweni show that our discourse-aware model achieves statistically significant improvements compared against strong neural network MRC baselines.
Learning to Share by Masking the Non-shared for Multi-domain Sentiment Classification
Apr 17, 2021
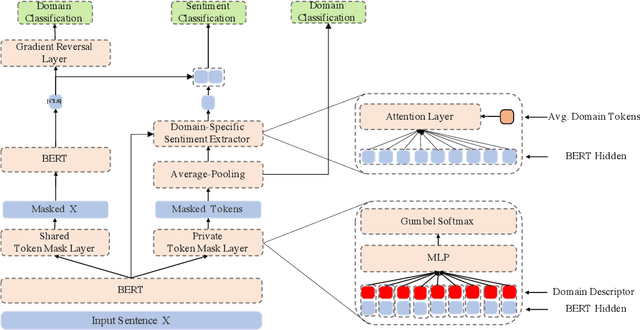
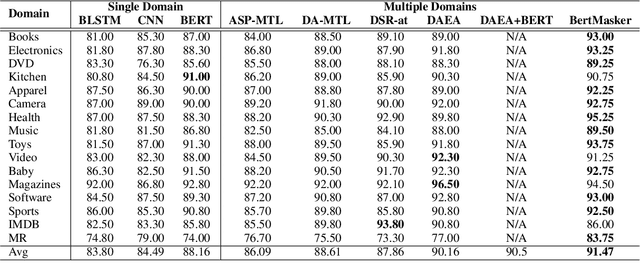
Multi-domain sentiment classification deals with the scenario where labeled data exists for multiple domains but insufficient for training effective sentiment classifiers that work across domains. Thus, fully exploiting sentiment knowledge shared across domains is crucial for real world applications. While many existing works try to extract domain-invariant features in high-dimensional space, such models fail to explicitly distinguish between shared and private features at text-level, which to some extent lacks interpretablity. Based on the assumption that removing domain-related tokens from texts would help improve their domain-invariance, we instead first transform original sentences to be domain-agnostic. To this end, we propose the BertMasker network which explicitly masks domain-related words from texts, learns domain-invariant sentiment features from these domain-agnostic texts, and uses those masked words to form domain-aware sentence representations. Empirical experiments on a well-adopted multiple domain sentiment classification dataset demonstrate the effectiveness of our proposed model on both multi-domain sentiment classification and cross-domain settings, by increasing the accuracy by 0.94% and 1.8% respectively. Further analysis on masking proves that removing those domain-related and sentiment irrelevant tokens decreases texts' domain distinction, resulting in the performance degradation of a BERT-based domain classifier by over 12%.
Learning from Self-Discrepancy via Multiple Co-teaching for Cross-Domain Person Re-Identification
Apr 06, 2021
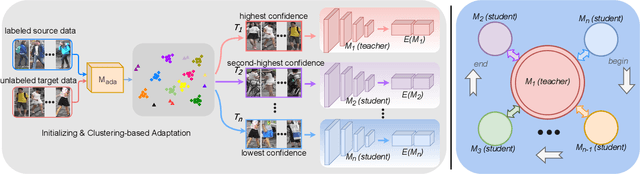
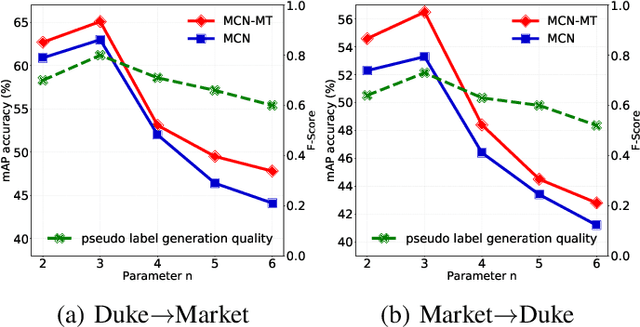

Employing clustering strategy to assign unlabeled target images with pseudo labels has become a trend for person re-identification (re-ID) algorithms in domain adaptation. A potential limitation of these clustering-based methods is that they always tend to introduce noisy labels, which will undoubtedly hamper the performance of our re-ID system. To handle this limitation, an intuitive solution is to utilize collaborative training to purify the pseudo label quality. However, there exists a challenge that the complementarity of two networks, which inevitably share a high similarity, becomes weakened gradually as training process goes on; worse still, these approaches typically ignore to consider the self-discrepancy of intra-class relations. To address this issue, in this letter, we propose a multiple co-teaching framework for domain adaptive person re-ID, opening up a promising direction about self-discrepancy problem under unsupervised condition. On top of that, a mean-teaching mechanism is leveraged to enlarge the difference and discover more complementary features. Comprehensive experiments conducted on several large-scale datasets show that our method achieves competitive performance compared with the state-of-the-arts.
A Survey on Spoken Language Understanding: Recent Advances and New Frontiers
Mar 04, 2021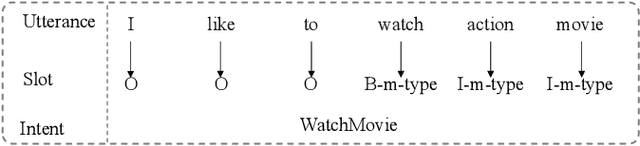
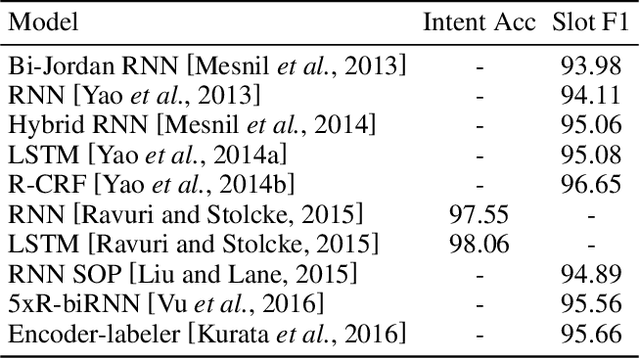
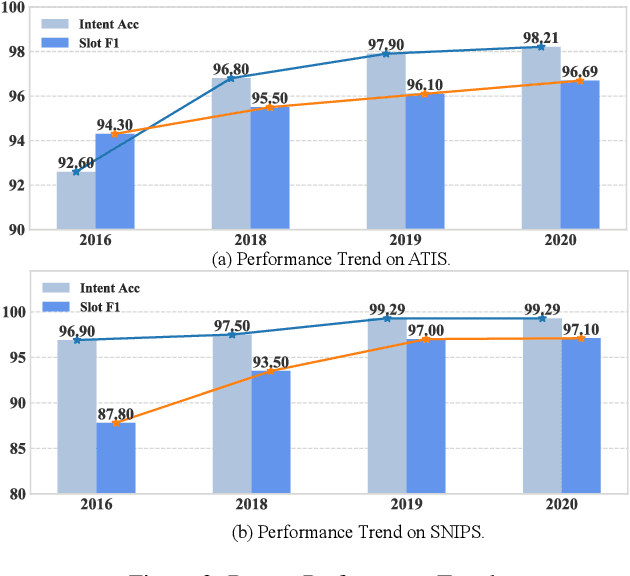
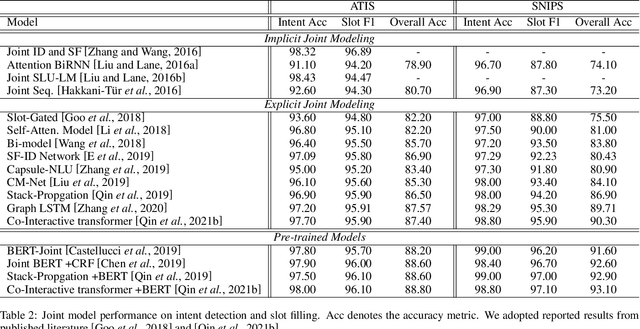
Spoken Language Understanding (SLU) aims to extract the semantics frame of user queries, which is a core component in a task-oriented dialog system. With the burst of deep neural networks and the evolution of pre-trained language models, the research of SLU has obtained significant breakthroughs. However, there remains a lack of a comprehensive survey summarizing existing approaches and recent trends, which motivated the work presented in this article. In this paper, we survey recent advances and new frontiers in SLU. Specifically, we give a thorough review of this research field, covering different aspects including (1) new taxonomy: we provide a new perspective for SLU filed, including single model vs. joint model, implicit joint modeling vs. explicit joint modeling in joint model, non pre-trained paradigm vs. pre-trained paradigm;(2) new frontiers: some emerging areas in complex SLU as well as the corresponding challenges; (3) abundant open-source resources: to help the community, we have collected, organized the related papers, baseline projects and leaderboard on a public website where SLU researchers could directly access to the recent progress. We hope that this survey can shed a light on future research in SLU field.
Memory Augmented Sequential Paragraph Retrieval for Multi-hop Question Answering
Feb 07, 2021Retrieving information from correlative paragraphs or documents to answer open-domain multi-hop questions is very challenging. To deal with this challenge, most of the existing works consider paragraphs as nodes in a graph and propose graph-based methods to retrieve them. However, in this paper, we point out the intrinsic defect of such methods. Instead, we propose a new architecture that models paragraphs as sequential data and considers multi-hop information retrieval as a kind of sequence labeling task. Specifically, we design a rewritable external memory to model the dependency among paragraphs. Moreover, a threshold gate mechanism is proposed to eliminate the distraction of noise paragraphs. We evaluate our method on both full wiki and distractor subtask of HotpotQA, a public textual multi-hop QA dataset requiring multi-hop information retrieval. Experiments show that our method achieves significant improvement over the published state-of-the-art method in retrieval and downstream QA task performance.
Discovering Dialog Structure Graph for Open-Domain Dialog Generation
Dec 31, 2020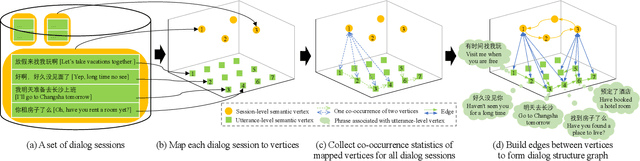
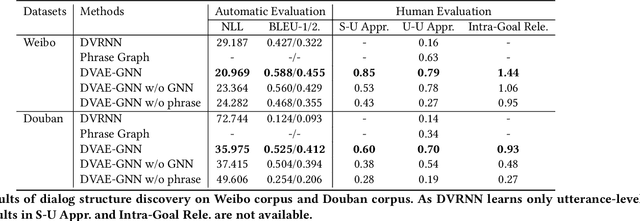
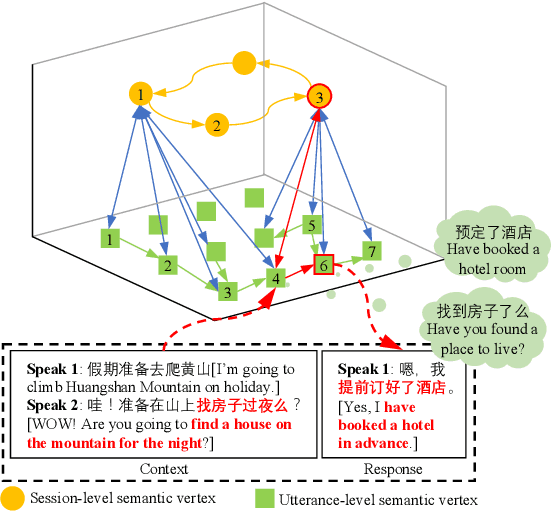
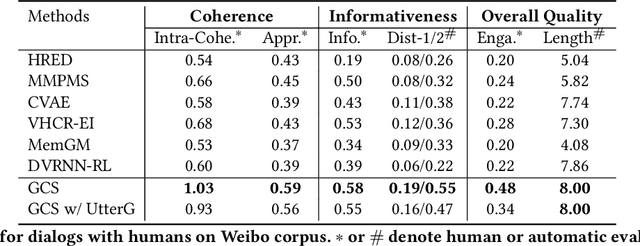
Learning interpretable dialog structure from human-human dialogs yields basic insights into the structure of conversation, and also provides background knowledge to facilitate dialog generation. In this paper, we conduct unsupervised discovery of dialog structure from chitchat corpora, and then leverage it to facilitate dialog generation in downstream systems. To this end, we present a Discrete Variational Auto-Encoder with Graph Neural Network (DVAE-GNN), to discover a unified human-readable dialog structure. The structure is a two-layer directed graph that contains session-level semantics in the upper-layer vertices, utterance-level semantics in the lower-layer vertices, and edges among these semantic vertices. In particular, we integrate GNN into DVAE to fine-tune utterance-level semantics for more effective recognition of session-level semantic vertex. Furthermore, to alleviate the difficulty of discovering a large number of utterance-level semantics, we design a coupling mechanism that binds each utterance-level semantic vertex with a distinct phrase to provide prior semantics. Experimental results on two benchmark corpora confirm that DVAE-GNN can discover meaningful dialog structure, and the use of dialog structure graph as background knowledge can facilitate a graph grounded conversational system to conduct coherent multi-turn dialog generation.
Multiple Structural Priors Guided Self Attention Network for Language Understanding
Dec 29, 2020Self attention networks (SANs) have been widely utilized in recent NLP studies. Unlike CNNs or RNNs, standard SANs are usually position-independent, and thus are incapable of capturing the structural priors between sequences of words. Existing studies commonly apply one single mask strategy on SANs for incorporating structural priors while failing at modeling more abundant structural information of texts. In this paper, we aim at introducing multiple types of structural priors into SAN models, proposing the Multiple Structural Priors Guided Self Attention Network (MS-SAN) that transforms different structural priors into different attention heads by using a novel multi-mask based multi-head attention mechanism. In particular, we integrate two categories of structural priors, including the sequential order and the relative position of words. For the purpose of capturing the latent hierarchical structure of the texts, we extract these information not only from the word contexts but also from the dependency syntax trees. Experimental results on two tasks show that MS-SAN achieves significant improvements against other strong baselines.