 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbiased Multi-Modality Guidance for Image Inpainting
Aug 25, 2022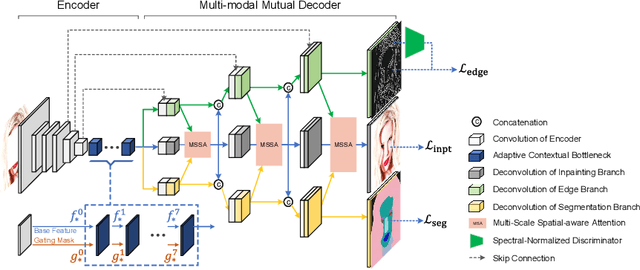
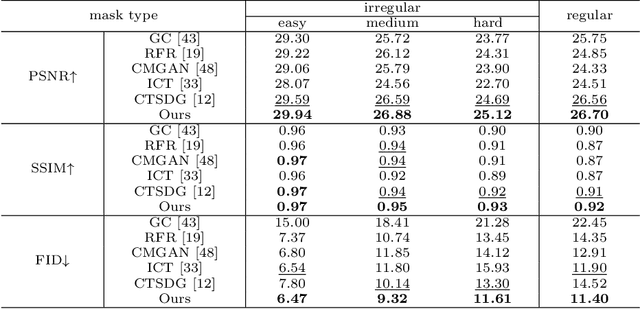
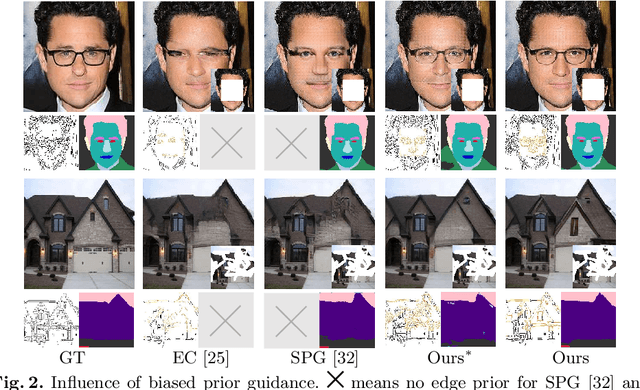
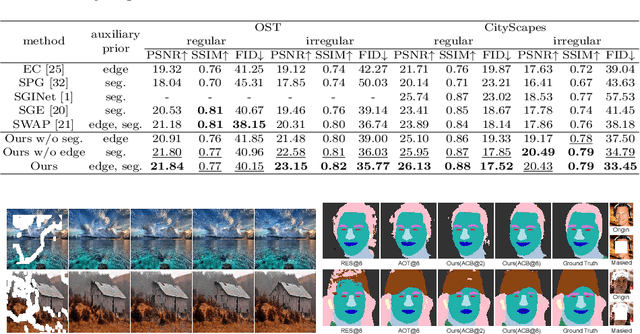
Image inpainting is an ill-posed problem to recover missing or damaged image content based on incomplete images with masks. Previous works usually predict the auxiliary structures (e.g., edges, segmentation and contours) to help fill visually realistic patches in a multi-stage fashion. However, imprecise auxiliary priors may yield biased inpainted results. Besides, it is time-consuming for some methods to be implemented by multiple stages of complex neural networks. To solve this issue, we develop an end-to-end multi-modality guided transformer network, including one inpainting branch and two auxiliary branches for semantic segmentation and edge textures. Within each transformer block, the proposed multi-scale spatial-aware attention module can learn the multi-modal structural features efficiently via auxiliary denormalization. Different from previous methods relying on direct guidance from biased priors, our method enriches semantically consistent context in an image based on discriminative interplay information from multiple modalities. Comprehensive experiments on several challenging image inpainting datasets show that our method achieves state-of-the-art performance to deal with various regular/irregular masks efficiently.
Structured Context Transformer for Generic Event Boundary Detection
Jun 07, 2022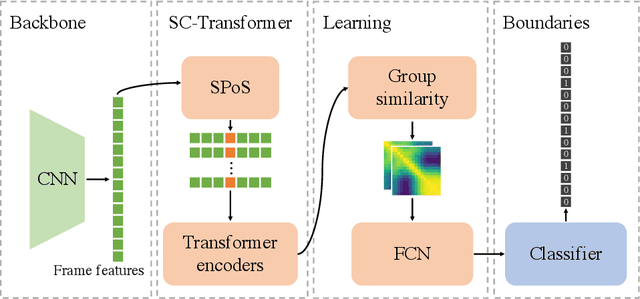
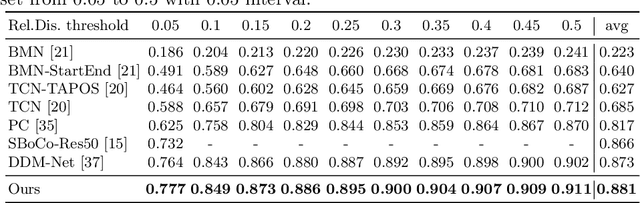
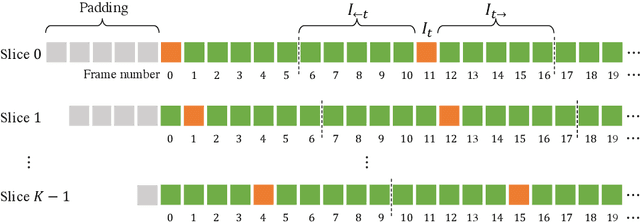
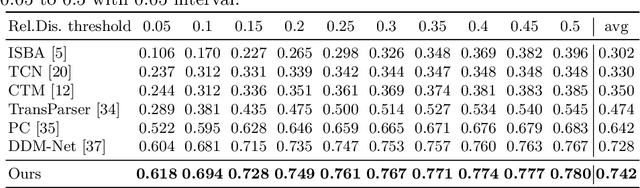
Generic Event Boundary Detection (GEBD) aims to detect moments where humans naturally perceive as event boundaries. In this paper, we present Structured Context Transformer (or SC-Transformer) to solve the GEBD task, which can be trained in an end-to-end fashion. Specifically, we use the backbone convolutional neural network (CNN) to extract the features of each video frame. To capture temporal context information of each frame, we design the structure context transformer (SC-Transformer) by re-partitioning input frame sequence. Note that, the overall computation complexity of SC-Transformer is linear to the video length. After that, the group similarities are computed to capture the differences between frames. Then, a lightweight fully convolutional network is used to determine the event boundaries based on the grouped similarity maps. To remedy the ambiguities of boundary annotations, the Gaussian kernel is adopted to preprocess the ground-truth event boundaries to further boost the accuracy. Extensive experiments conducted on the challenging Kinetics-GEBD and TAPOS datasets demonstrate the effectiveness of the proposed method compared to the state-of-the-art methods.
Multi-Granularity Alignment Domain Adaptation for Object Detection
Mar 31, 2022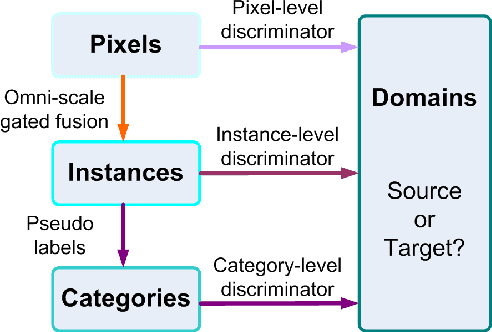
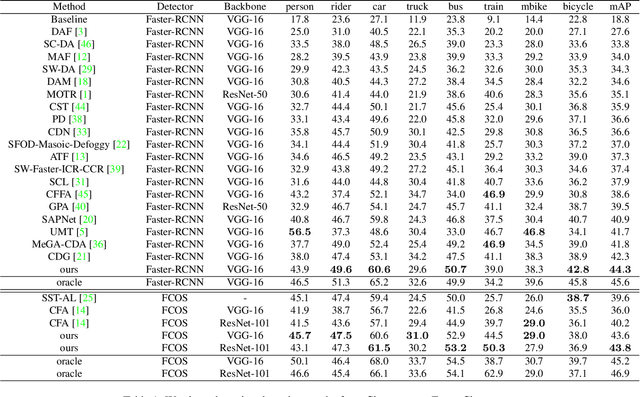
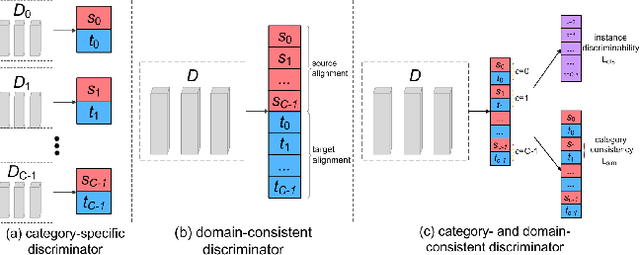
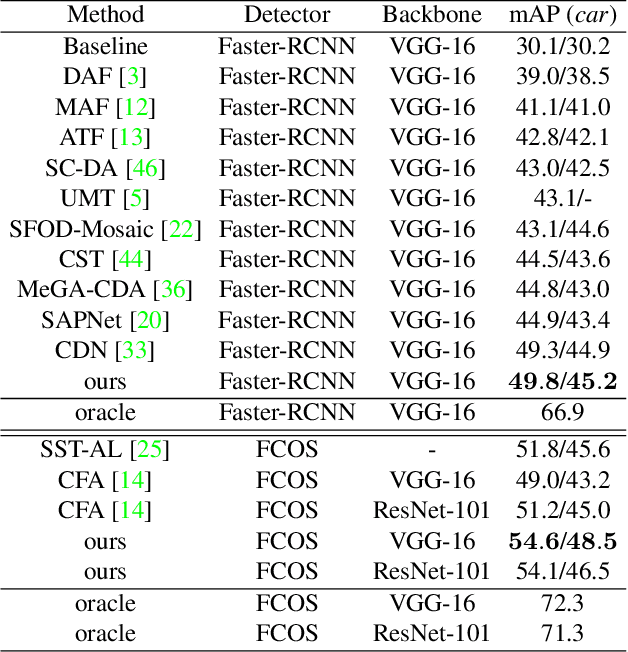
Domain adaptive object detection is challenging due to distinctive data distribution between source domain and target domain. In this paper, we propose a unified multi-granularity alignment based object detection framework towards domain-invariant feature learning. To this end, we encode the dependencies across different granularity perspectives including pixel-, instance-, and category-levels simultaneously to align two domains. Based on pixel-level feature maps from the backbone network, we first develop the omni-scale gated fusion module to aggregate discriminative representations of instances by scale-aware convolutions, leading to robust multi-scale object detection. Meanwhile, the multi-granularity discriminators are proposed to identify which domain different granularities of samples(i.e., pixels, instances, and categories) come from. Notably, we leverage not only the instance discriminability in different categories but also the category consistency between two domains. Extensive experiments are carried out on multiple domain adaptation scenarios, demonstrating the effectiveness of our framework over state-of-the-art algorithms on top of anchor-free FCOS and anchor-based Faster RCNN detectors with different backbones.
End-to-End Compressed Video Representation Learning for Generic Event Boundary Detection
Mar 29, 2022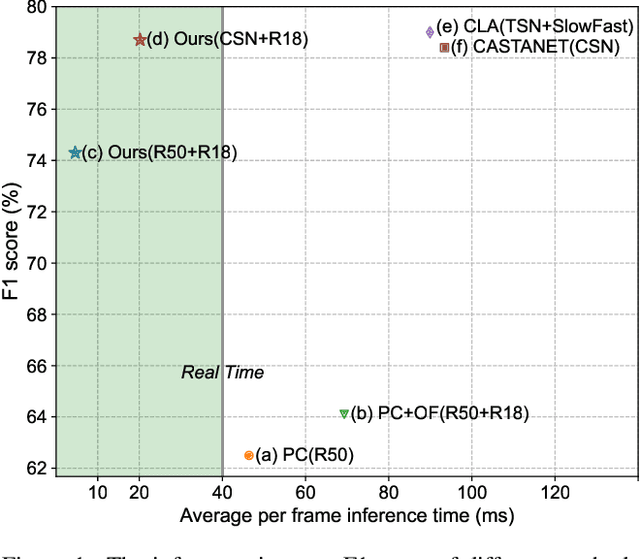
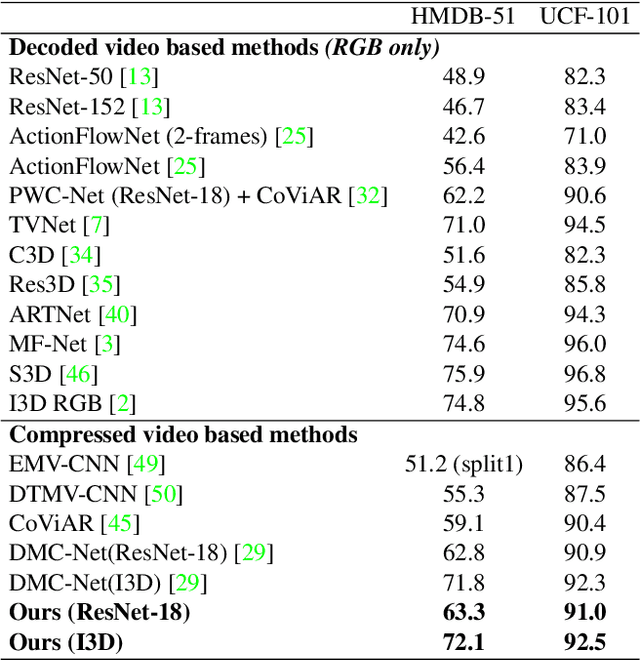
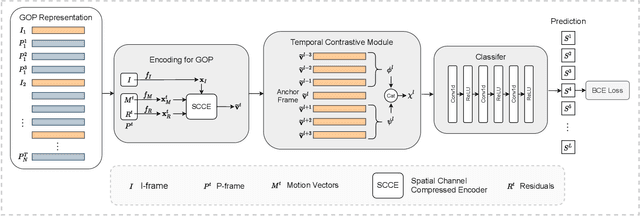
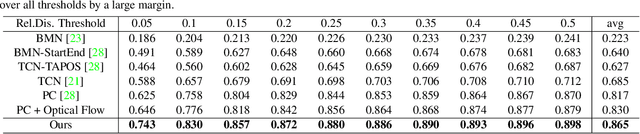
Generic event boundary detection aims to localize the generic, taxonomy-free event boundaries that segment videos into chunks. Existing methods typically require video frames to be decoded before feeding into the network, which demands considerable computational power and storage space. To that end, we propose a new end-to-end compressed video representation learning for event boundary detection that leverages the rich information in the compressed domain, i.e., RGB, motion vectors, residuals, and the internal group of pictures (GOP) structure, without fully decoding the video. Specifically, we first use the ConvNets to extract features of the I-frames in the GOPs. After that, a light-weight spatial-channel compressed encoder is designed to compute the feature representations of the P-frames based on the motion vectors, residuals and representations of their dependent I-frames. A temporal contrastive module is proposed to determine the event boundaries of video sequences. To remedy the ambiguities of annotations and speed up the training process, we use the Gaussian kernel to preprocess the ground-truth event boundaries. Extensive experiments conducted on the Kinetics-GEBD dataset demonstrate that the proposed method achieves comparable results to the state-of-the-art methods with $4.5\times$ faster running speed.
Learning to Infer User Hidden States for Online Sequential Advertising
Sep 03, 2020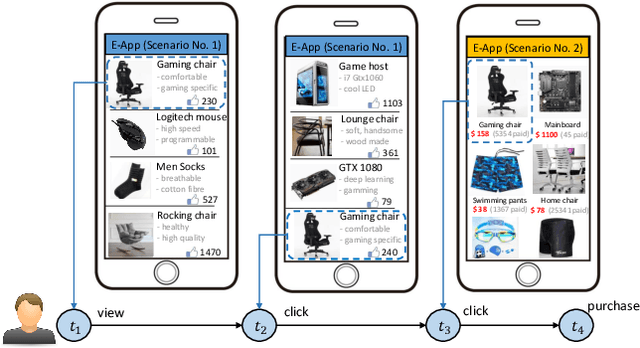
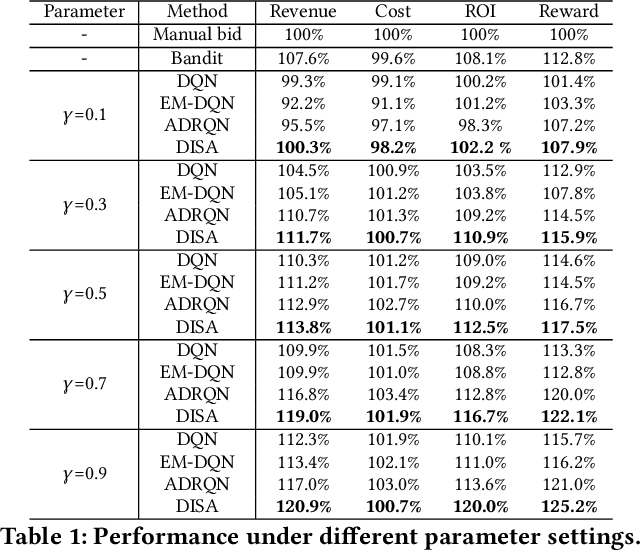
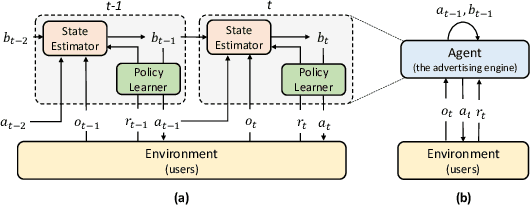
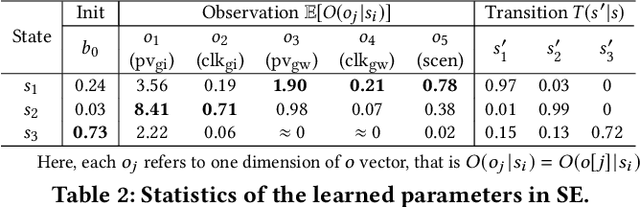
To drive purchase in online advertising, it is of the advertiser's great interest to optimize the sequential advertising strategy whose performance and interpretability are both important. The lack of interpretability in existing deep reinforcement learning methods makes it not easy to understand, diagnose and further optimize the strategy. In this paper, we propose our Deep Intents Sequential Advertising (DISA) method to address these issues. The key part of interpretability is to understand a consumer's purchase intent which is, however, unobservable (called hidden states). In this paper, we model this intention as a latent variable and formulate the problem as a Partially Observable Markov Decision Process (POMDP) where the underlying intents are inferred based on the observable behaviors. Large-scale industrial offline and online experiments demonstrate our method's superior performance over several baselines. The inferred hidden states are analyzed, and the results prove the rationality of our inference.
Spatial Attention Pyramid Network for Unsupervised Domain Adaptation
Mar 29, 2020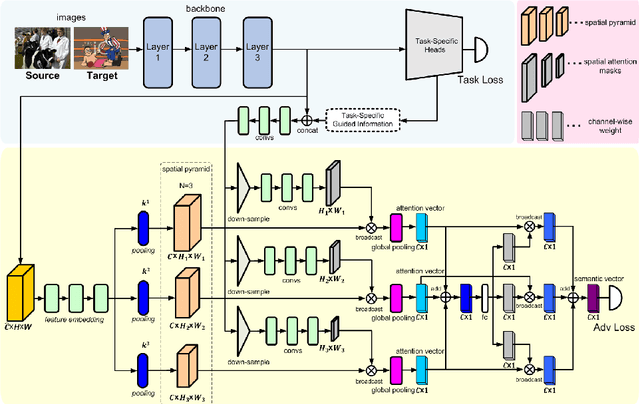
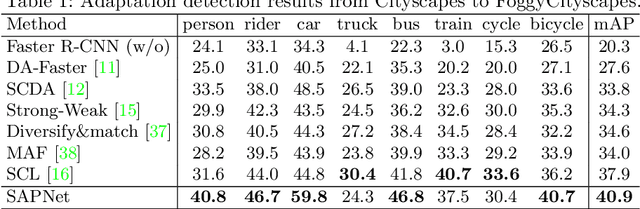
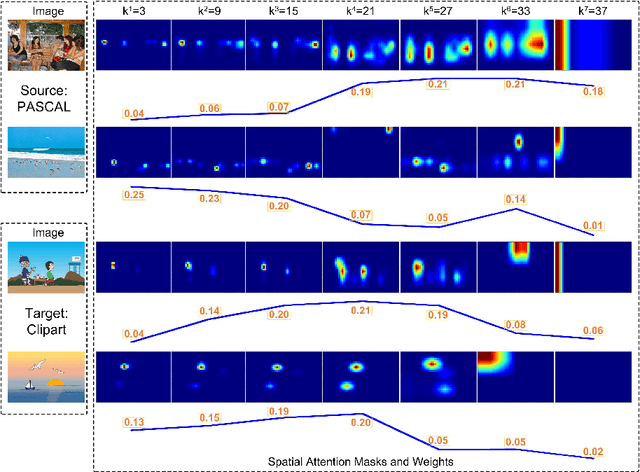
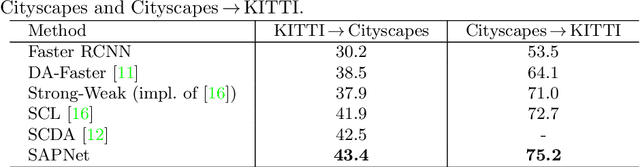
Unsupervised domain adaptation is critical in various computer vision tasks, such as object detection, instance segmentation, and semantic segmentation, which aims to alleviate performance degradation caused by domain-shift. Most of previous methods rely on a single-mode distribution of source and target domains to align them with adversarial learning, leading to inferior results in various scenarios. To that end, in this paper, we design a new spatial attention pyramid network for unsupervised domain adaptation. Specifically, we first build the spatial pyramid representation to capture context information of objects at different scales. Guided by the task-specific information, we combine the dense global structure representation and local texture patterns at each spatial location effectively using the spatial attention mechanism. In this way, the network is enforced to focus on the discriminative regions with context information for domain adaption. We conduct extensive experiments on various challenging datasets for unsupervised domain adaptation on object detection, instance segmentation, and semantic segmentation, which demonstrates that our method performs favorably against the state-of-the-art methods by a large margin. Our source code is available at code_path.
SiamMan: Siamese Motion-aware Network for Visual Tracking
Jan 18, 2020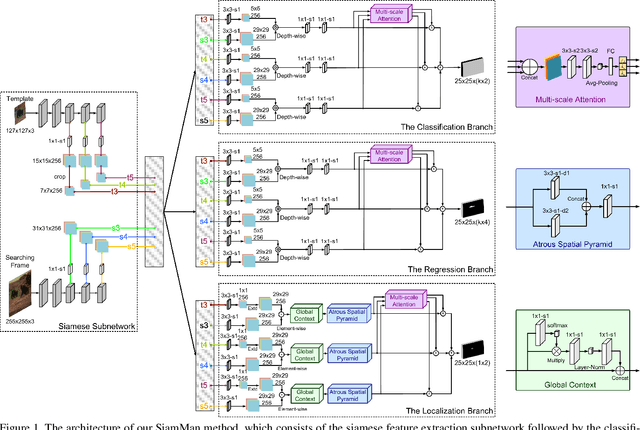
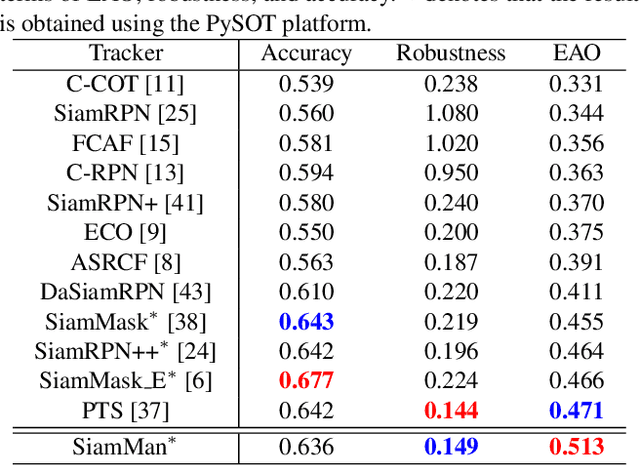
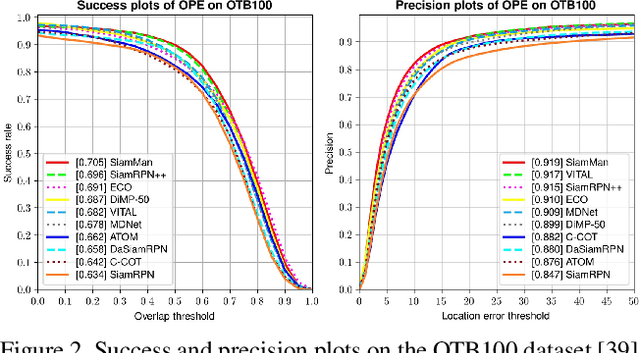
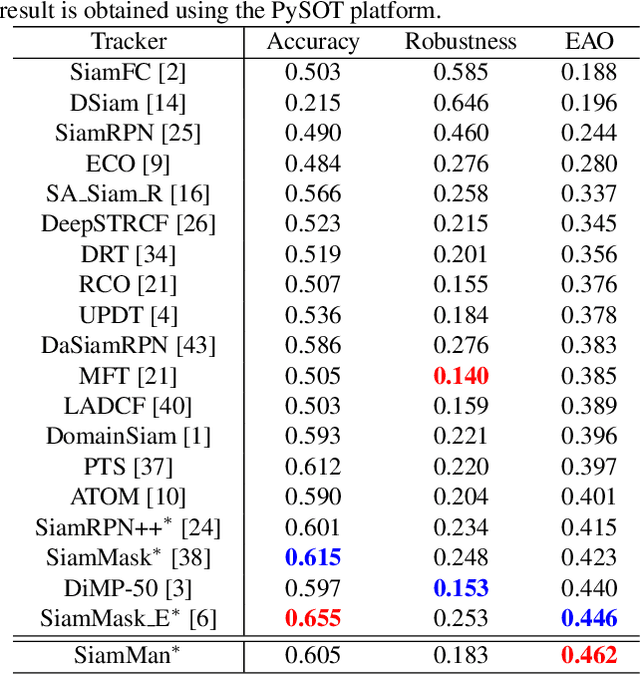
In this paper, we present a novel siamese motion-aware network (SiamMan) for visual tracking, which consists of the siamese feature extraction subnetwork, followed by the classification, regression, and localization branches in parallel. The classification branch is used to distinguish the foreground from background, and the regression branch is adopt to regress the bounding box of target. To reduce the impact of manually designed anchor boxes to adapt to different target motion patterns, we design the localization branch, which aims to coarsely localize the target to help the regression branch to generate accurate results. Meanwhile, we introduce the global context module into the localization branch to capture long-range dependency for more robustness in large displacement of target. In addition, we design a multi-scale learnable attention module to guide these three branches to exploit discriminative features for better performance. The whole network is trained offline in an end-to-end fashion with large-scale image pairs using the standard SGD algorithm with back-propagation. Extensive experiments on five challenging benchmarks, i.e., VOT2016, VOT2018, OTB100, UAV123 and LTB35, demonstrate that SiamMan achieves leading accuracy with high efficiency. Code can be found at https://isrc.iscas.ac.cn/gitlab/research/siamman.
Towards Interpretable and Robust Hand Detection via Pixel-wise Prediction
Jan 13, 2020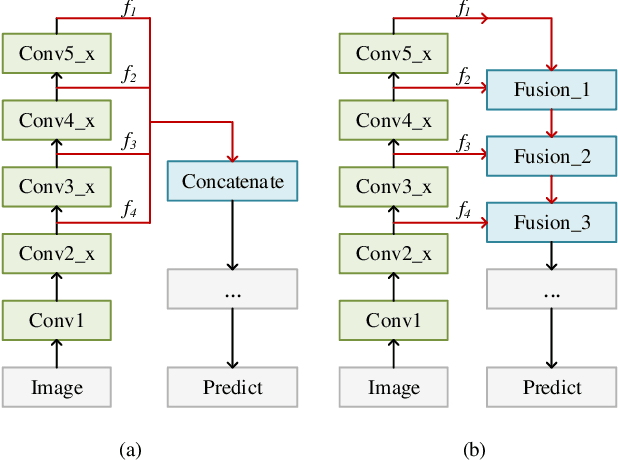
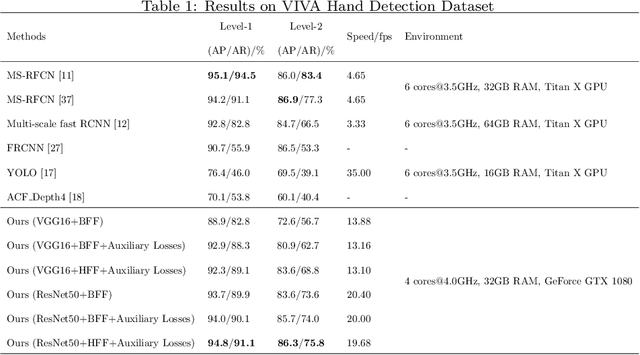
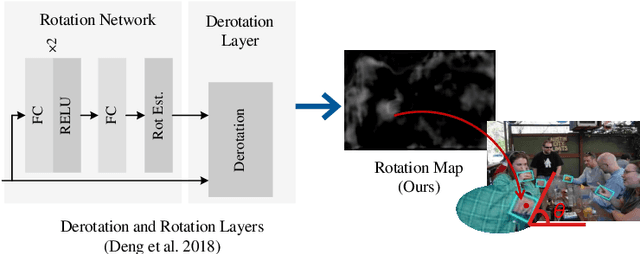
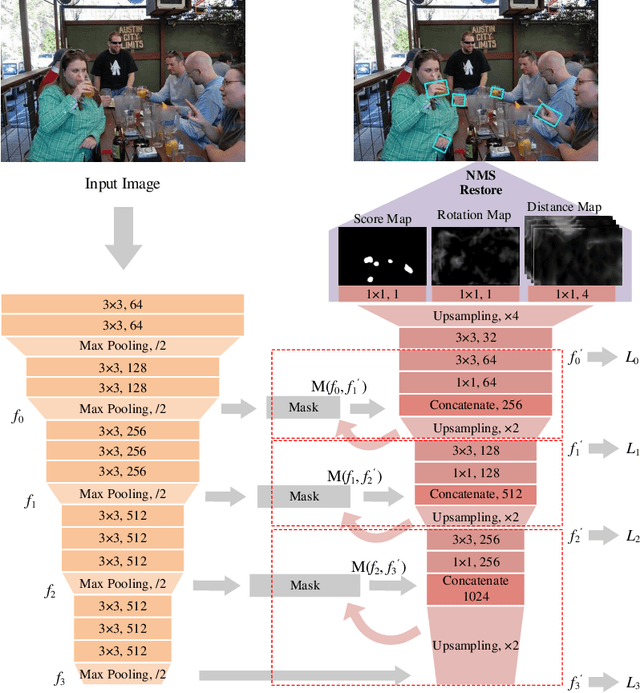
The lack of interpretability of existing CNN-based hand detection methods makes it difficult to understand the rationale behind their predictions. In this paper, we propose a novel neural network model, which introduces interpretability into hand detection for the first time. The main improvements include: (1) Detect hands at pixel level to explain what pixels are the basis for its decision and improve transparency of the model. (2) The explainable Highlight Feature Fusion block highlights distinctive features among multiple layers and learns discriminative ones to gain robust performance. (3) We introduce a transparent representation, the rotation map, to learn rotation features instead of complex and non-transparent rotation and derotation layers. (4) Auxiliary supervision accelerates the training process, which saves more than 10 hours in our experiments. Experimental results on the VIVA and Oxford hand detection and tracking datasets show competitive accuracy of our method compared with state-of-the-art methods with higher speed.
Scale Invariant Fully Convolutional Network: Detecting Hands Efficiently
Jun 11, 2019
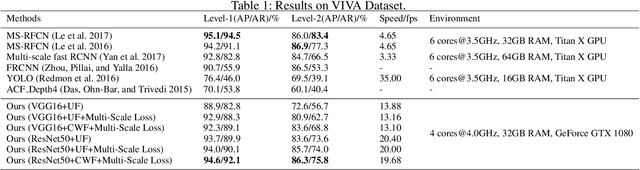
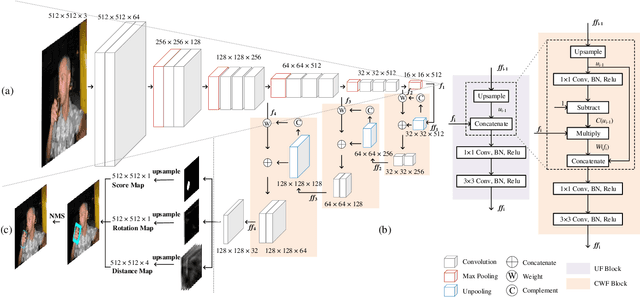
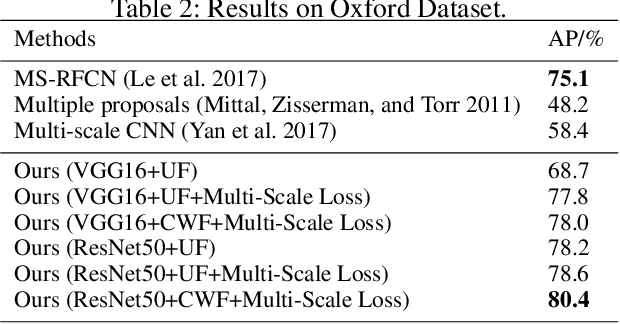
Existing hand detection methods usually follow the pipeline of multiple stages with high computation cost, i.e., feature extraction, region proposal, bounding box regression, and additional layers for rotated region detection. In this paper, we propose a new Scale Invariant Fully Convolutional Network (SIFCN) trained in an end-to-end fashion to detect hands efficiently. Specifically, we merge the feature maps from high to low layers in an iterative way, which handles different scales of hands better with less time overhead comparing to concatenating them simply. Moreover, we develop the Complementary Weighted Fusion (CWF) block to make full use of the distinctive features among multiple layers to achieve scale invariance. To deal with rotated hand detection, we present the rotation map to get rid of complex rotation and derotation layers. Besides, we design the multi-scale loss scheme to accelerate the training process significantly by adding supervision to the intermediate layers of the network. Compared with the state-of-the-art methods, our algorithm shows comparable accuracy and runs a 4.23 times faster speed on the VIVA dataset and achieves better average precision on Oxford hand detection dataset at a speed of 62.5 fps.
Data Priming Network for Automatic Check-Out
Apr 10, 2019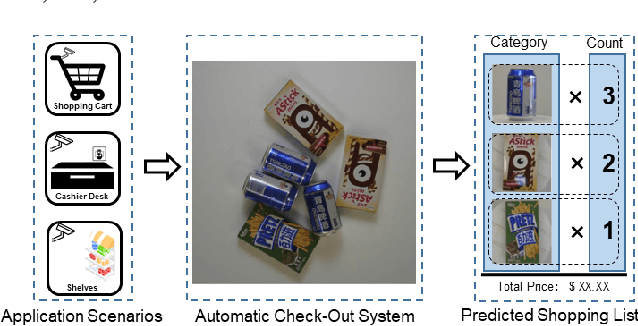
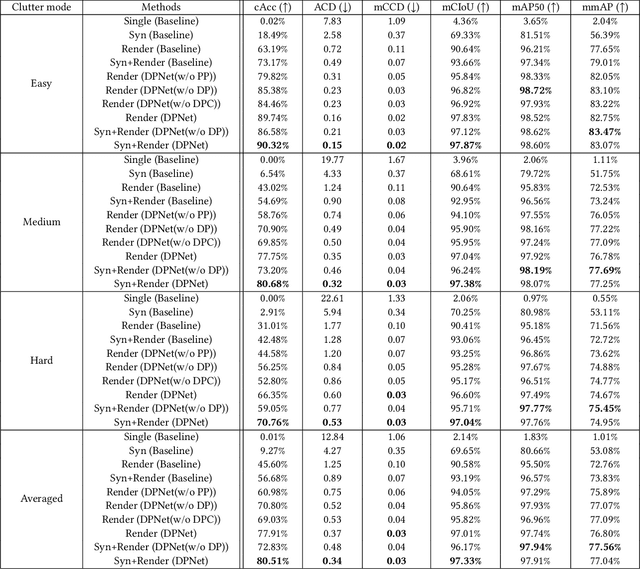
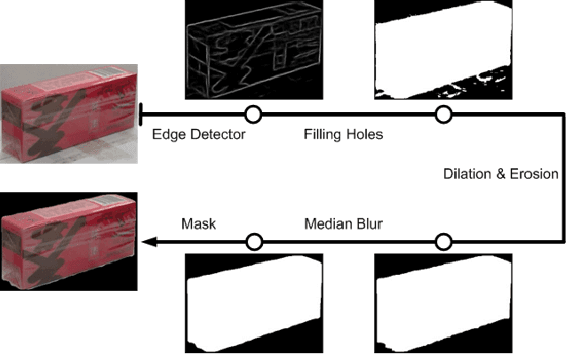

Automatic Check-Out (ACO) receives increased interests in recent years. An important component of the ACO system is the visual item counting, which recognize the categories and counts of the items chosen by the customers. However, the training of such a system is challenged by the domain adaptation problem, in which the training data are images from isolated items while the testing images are for collections of items. Existing methods solve this problem with data augmentation using synthesized images, but the image synthesis leads to unreal images that affect the training process. In this paper, we propose a new data priming method to solve the domain adaptation problem. Specifically, we first use pre-augmentation data priming, in which we remove distracting background from the training images and select images with realistic view angles by the pose pruning method. In the post-augmentation step, we train a data priming network using detection and counting collaborative learning, and select more reliable images from testing data to train the final visual item tallying network. Experiments on the large scale Retail Product Checkout (RPC) dataset demonstrate the superiority of the proposed method, i.e., we achieve 80.51% checkout accuracy compared with 56.68% of the baseline methods.