 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Point-BEV Fusion for 3D Point Cloud Object Tracking with Transformer
Aug 10, 2022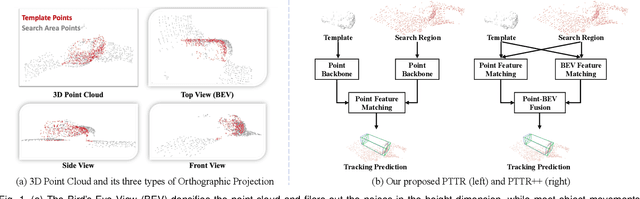
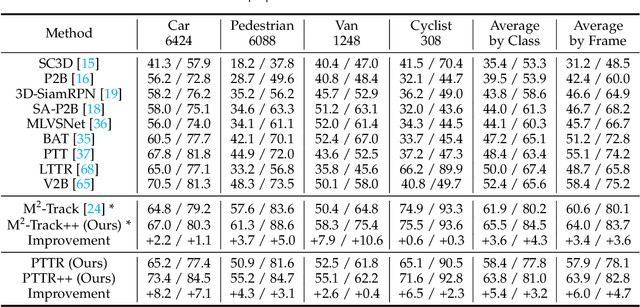
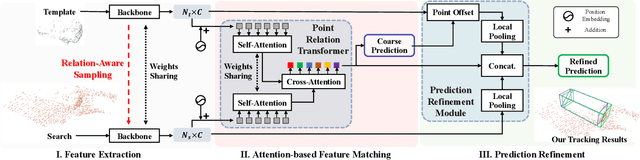
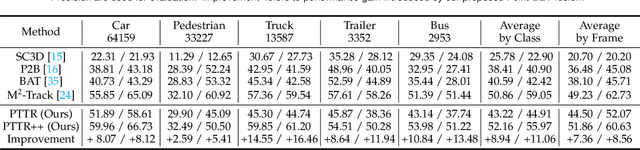
With the prevalence of LiDAR sensors in autonomous driving, 3D object tracking has received increasing attention. In a point cloud sequence, 3D object tracking aims to predict the location and orientation of an object in consecutive frames given an object template. Motivated by the success of transformers, we propose Point Tracking TRansformer (PTTR), which efficiently predicts high-quality 3D tracking results in a coarse-to-fine manner with the help of transformer operations. PTTR consists of three novel designs. 1) Instead of random sampling, we design Relation-Aware Sampling to preserve relevant points to the given template during subsampling. 2) We propose a Point Relation Transformer for effective feature aggregation and feature matching between the template and search region. 3) Based on the coarse tracking results, we employ a novel Prediction Refinement Module to obtain the final refined prediction through local feature pooling. In addition, motivated by the favorable properties of the Bird's-Eye View (BEV) of point clouds in capturing object motion, we further design a more advanced framework named PTTR++, which incorporates both the point-wise view and BEV representation to exploit their complementary effect in generating high-quality tracking results. PTTR++ substantially boosts the tracking performance on top of PTTR with low computational overhead. Extensive experiments over multiple datasets show that our proposed approaches achieve superior 3D tracking accuracy and efficiency.
TransPillars: Coarse-to-Fine Aggregation for Multi-Frame 3D Object Detection
Aug 04, 2022



3D object detection using point clouds has attracted increasing attention due to its wide applications in autonomous driving and robotics. However, most existing studies focus on single point cloud frames without harnessing the temporal information in point cloud sequences. In this paper, we design TransPillars, a novel transformer-based feature aggregation technique that exploits temporal features of consecutive point cloud frames for multi-frame 3D object detection. TransPillars aggregates spatial-temporal point cloud features from two perspectives. First, it fuses voxel-level features directly from multi-frame feature maps instead of pooled instance features to preserve instance details with contextual information that are essential to accurate object localization. Second, it introduces a hierarchical coarse-to-fine strategy to fuse multi-scale features progressively to effectively capture the motion of moving objects and guide the aggregation of fine features. Besides, a variant of deformable transformer is introduced to improve the effectiveness of cross-frame feature matching. Extensive experiments show that our proposed TransPillars achieves state-of-art performance as compared to existing multi-frame detection approaches. Code will be released.
MulViMotion: Shape-aware 3D Myocardial Motion Tracking from Multi-View Cardiac MRI
Jul 29, 2022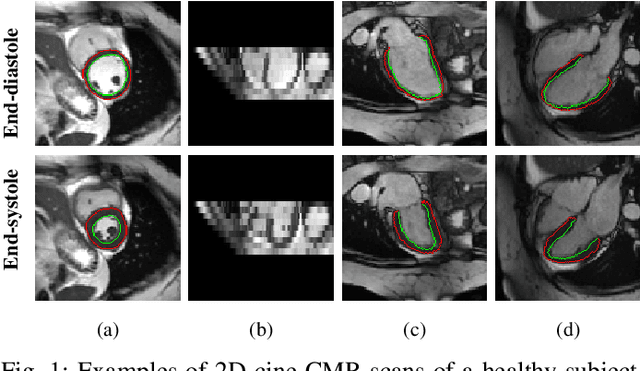
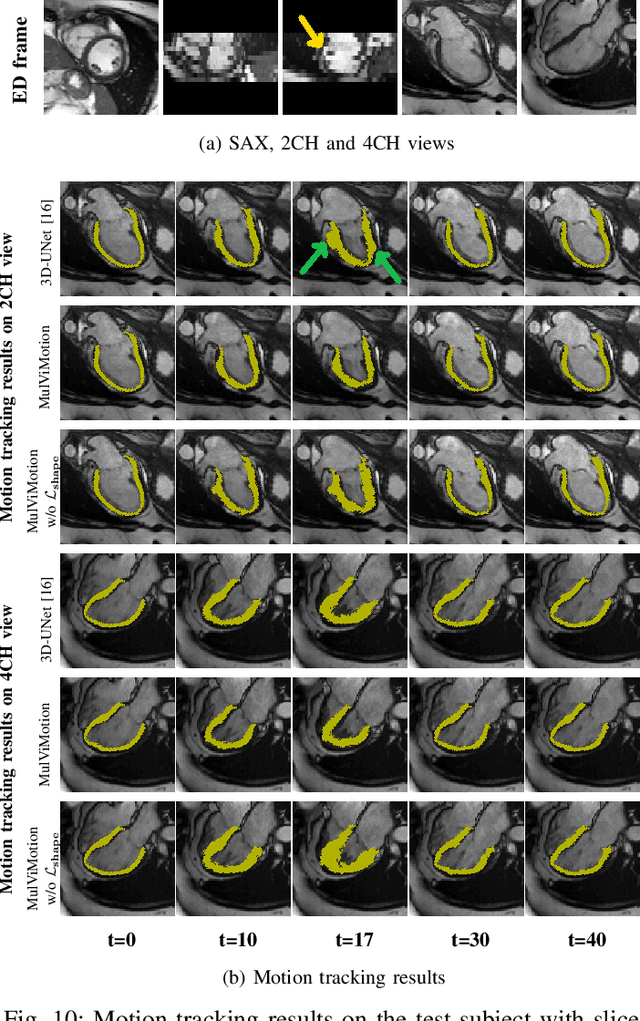
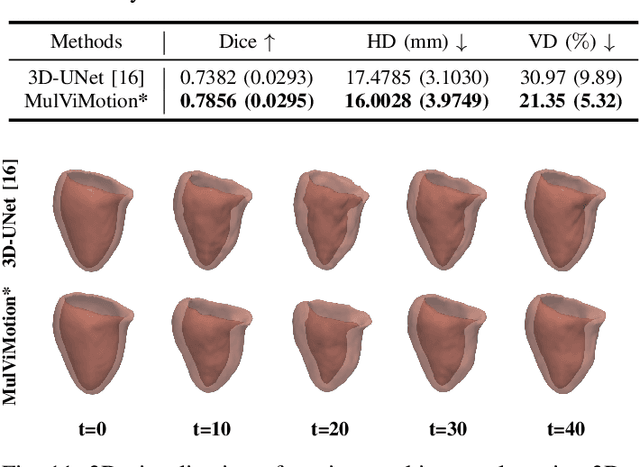
Recovering the 3D motion of the heart from cine cardiac magnetic resonance (CMR) imaging enables the assessment of regional myocardial function and is important for understanding and analyzing cardiovascular disease. However, 3D cardiac motion estimation is challenging because the acquired cine CMR images are usually 2D slices which limit the accurate estimation of through-plane motion. To address this problem, we propose a novel multi-view motion estimation network (MulViMotion), which integrates 2D cine CMR images acquired in short-axis and long-axis planes to learn a consistent 3D motion field of the heart. In the proposed method, a hybrid 2D/3D network is built to generate dense 3D motion fields by learning fused representations from multi-view images. To ensure that the motion estimation is consistent in 3D, a shape regularization module is introduced during training, where shape information from multi-view images is exploited to provide weak supervision to 3D motion estimation. We extensively evaluate the proposed method on 2D cine CMR images from 580 subjects of the UK Biobank study for 3D motion tracking of the left ventricular myocardium. Experimental results show that the proposed method quantitatively and qualitatively outperforms competing methods.
DURRNet: Deep Unfolded Single Image Reflection Removal Network
Mar 12, 2022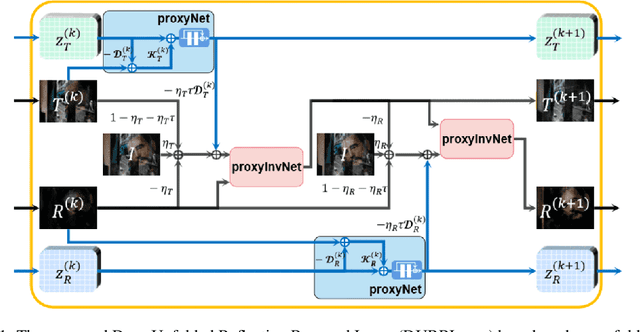

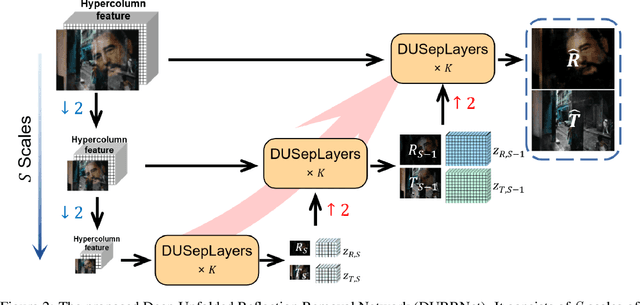

Single image reflection removal problem aims to divide a reflection-contaminated image into a transmission image and a reflection image. It is a canonical blind source separation problem and is highly ill-posed. In this paper, we present a novel deep architecture called deep unfolded single image reflection removal network (DURRNet) which makes an attempt to combine the best features from model-based and learning-based paradigms and therefore leads to a more interpretable deep architecture. Specifically, we first propose a model-based optimization with transform-based exclusion prior and then design an iterative algorithm with simple closed-form solutions for solving each sub-problems. With the deep unrolling technique, we build the DURRNet with ProxNets to model natural image priors and ProxInvNets which are constructed with invertible networks to impose the exclusion prior. Comprehensive experimental results on commonly used datasets demonstrate that the proposed DURRNet achieves state-of-the-art results both visually and quantitatively.
PTTR: Relational 3D Point Cloud Object Tracking with Transformer
Dec 07, 2021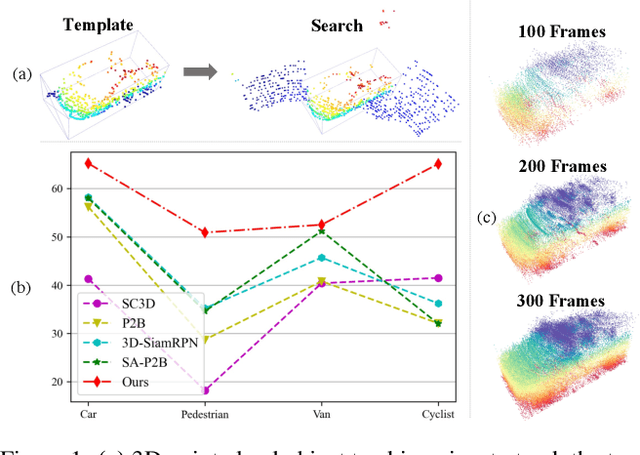
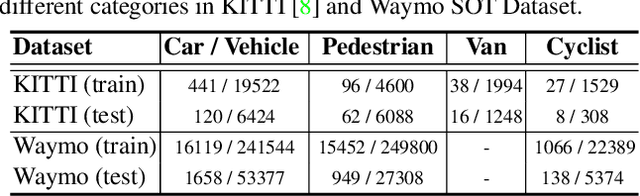
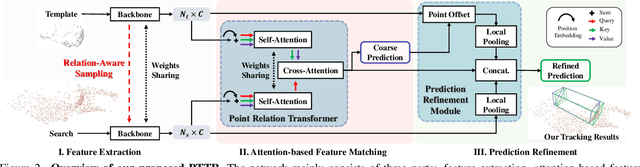
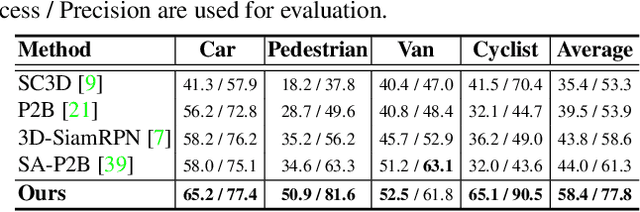
In a point cloud sequence, 3D object tracking aims to predict the location and orientation of an object in the current search point cloud given a template point cloud. Motivated by the success of transformers, we propose Point Tracking TRansformer (PTTR), which efficiently predicts high-quality 3D tracking results in a coarse-to-fine manner with the help of transformer operations. PTTR consists of three novel designs. 1) Instead of random sampling, we design Relation-Aware Sampling to preserve relevant points to given templates during subsampling. 2) Furthermore, we propose a Point Relation Transformer (PRT) consisting of a self-attention and a cross-attention module. The global self-attention operation captures long-range dependencies to enhance encoded point features for the search area and the template, respectively. Subsequently, we generate the coarse tracking results by matching the two sets of point features via cross-attention. 3) Based on the coarse tracking results, we employ a novel Prediction Refinement Module to obtain the final refined prediction. In addition, we create a large-scale point cloud single object tracking benchmark based on the Waymo Open Dataset. Extensive experiments show that PTTR achieves superior point cloud tracking in both accuracy and efficiency.
Detecting Hypo-plastic Left Heart Syndrome in Fetal Ultrasound via Disease-specific Atlas Maps
Jul 06, 2021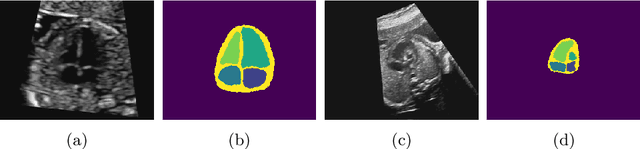
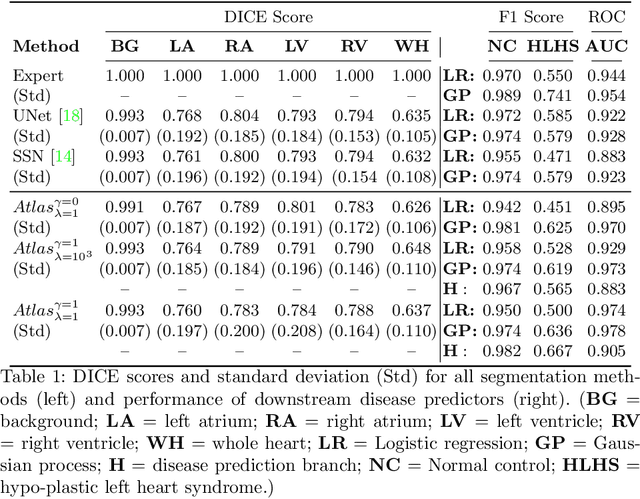

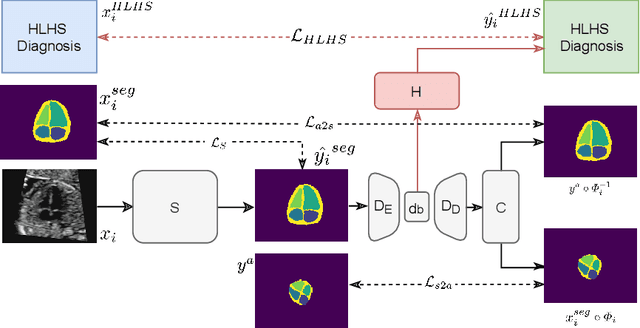
Fetal ultrasound screening during pregnancy plays a vital role in the early detection of fetal malformations which have potential long-term health impacts. The level of skill required to diagnose such malformations from live ultrasound during examination is high and resources for screening are often limited. We present an interpretable, atlas-learning segmentation method for automatic diagnosis of Hypo-plastic Left Heart Syndrome (HLHS) from a single `4 Chamber Heart' view image. We propose to extend the recently introduced Image-and-Spatial Transformer Networks (Atlas-ISTN) into a framework that enables sensitising atlas generation to disease. In this framework we can jointly learn image segmentation, registration, atlas construction and disease prediction while providing a maximum level of clinical interpretability compared to direct image classification methods. As a result our segmentation allows diagnoses competitive with expert-derived manual diagnosis and yields an AUC-ROC of 0.978 (1043 cases for training, 260 for validation and 325 for testing).
Video Summarization through Reinforcement Learning with a 3D Spatio-Temporal U-Net
Jun 19, 2021
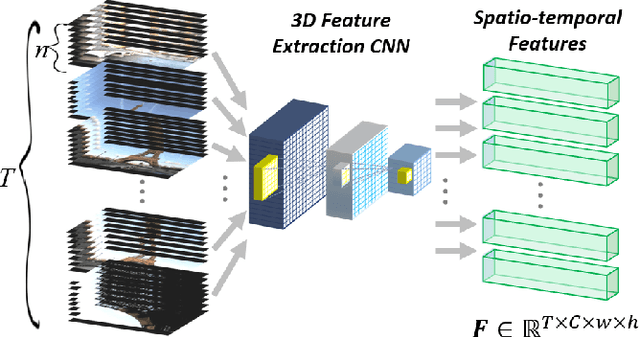
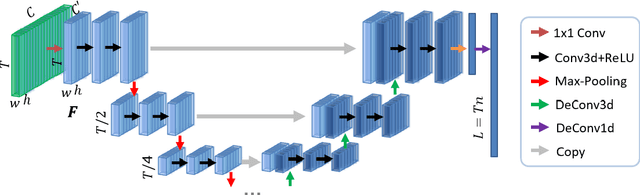
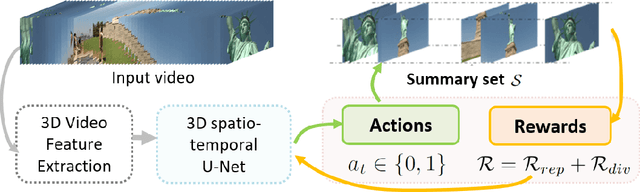
Intelligent video summarization algorithms allow to quickly convey the most relevant information in videos through the identification of the most essential and explanatory content while removing redundant video frames. In this paper, we introduce the 3DST-UNet-RL framework for video summarization. A 3D spatio-temporal U-Net is used to efficiently encode spatio-temporal information of the input videos for downstream reinforcement learning (RL). An RL agent learns from spatio-temporal latent scores and predicts actions for keeping or rejecting a video frame in a video summary. We investigate if real/inflated 3D spatio-temporal CNN features are better suited to learn representations from videos than commonly used 2D image features. Our framework can operate in both, a fully unsupervised mode and a supervised training mode. We analyse the impact of prescribed summary lengths and show experimental evidence for the effectiveness of 3DST-UNet-RL on two commonly used general video summarization benchmarks. We also applied our method on a medical video summarization task. The proposed video summarization method has the potential to save storage costs of ultrasound screening videos as well as to increase efficiency when browsing patient video data during retrospective analysis or audit without loosing essential information
On Learned Sketches for Randomized Numerical Linear Algebra
Jul 20, 2020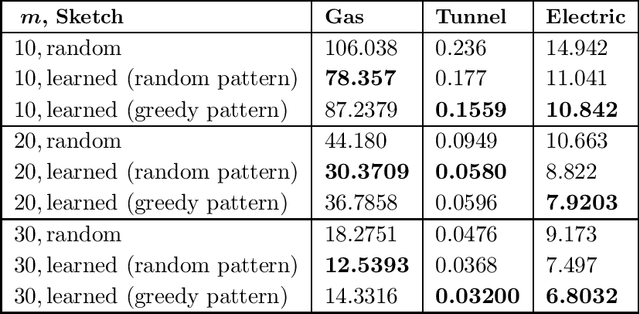
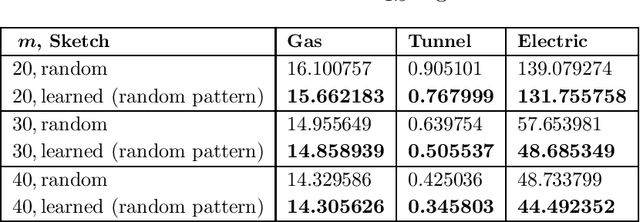
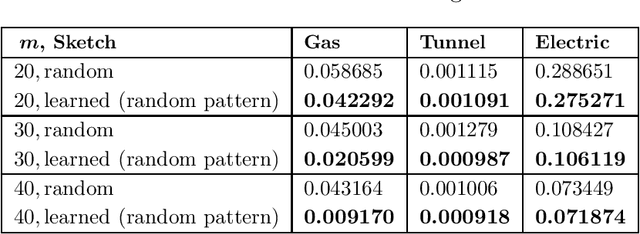
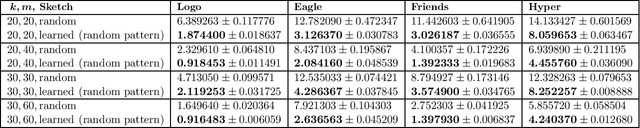
We study "learning-based" sketching approaches for diverse tasks in numerical linear algebra: least-squares regression, $\ell_p$ regression, Huber regression, low-rank approximation (LRA), and $k$-means clustering. Sketching methods are used to quickly and approximately compute properties of large matrices. Linear maps called "sketches" are applied to compress data, and these concise representations are used to compute the desired properties. Specifically, we consider sparse sketches (such as CountSketch). Recent works have dealt with optimizing sketches for data distributions to perform better than their random counterparts. We extend this theme to several important and ubiquitous tasks, each of which requires a new analysis and novel practical methods. Specifically, our contributions are: 1) For all tasks, we introduce fast algorithms using learned sketches with worst-case guarantees. We give a simple task-agnostic method for retaining the worst-case guarantees of randomized sketching, which yields time-optimal algorithms for LRA and least-squares regression. Also, for $k$-means clustering, we give a faster alternative for retaining worst-case guarantees. 2) We show empirically that learned sketches are reliable in improving approximation accuracy, with comparison against "non-learned" sketching baselines. 3) We introduce a greedy algorithm for optimizing the location of the nonzero entries of a sparse sketch and prove guarantees for certain distributions on the LRA task. Previous work only looked at optimizing the values rather than the locations. Also, we show empirically that it further improves learned sketch performance.
Ultrasound Video Summarization using Deep Reinforcement Learning
May 19, 2020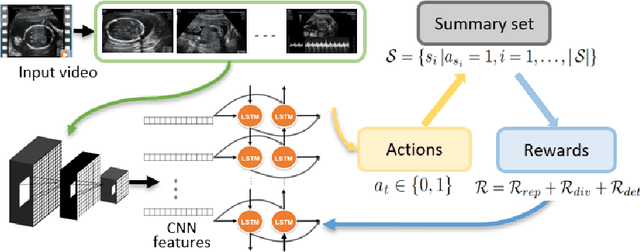
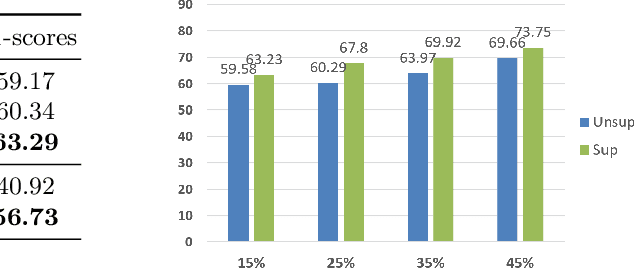
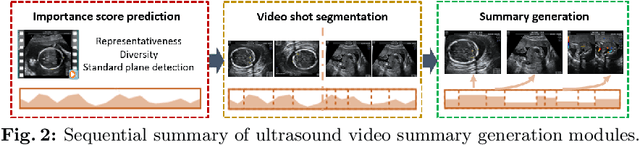
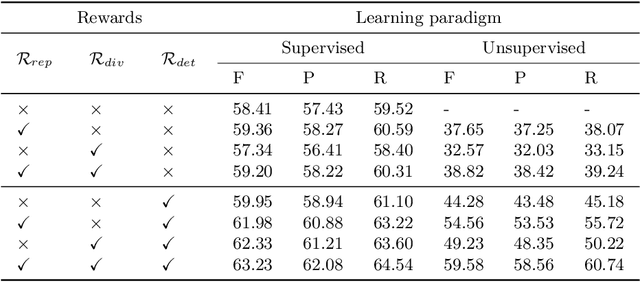
Video is an essential imaging modality for diagnostics, e.g. in ultrasound imaging, for endoscopy, or movement assessment. However, video hasn't received a lot of attention in the medical image analysis community. In the clinical practice, it is challenging to utilise raw diagnostic video data efficiently as video data takes a long time to process, annotate or audit. In this paper we introduce a novel, fully automatic video summarization method that is tailored to the needs of medical video data. Our approach is framed as reinforcement learning problem and produces agents focusing on the preservation of important diagnostic information. We evaluate our method on videos from fetal ultrasound screening, where commonly only a small amount of the recorded data is used diagnostically. We show that our method is superior to alternative video summarization methods and that it preserves essential information required by clinical diagnostic standards.
Coupled Network for Robust Pedestrian Detection with Gated Multi-Layer Feature Extraction and Deformable Occlusion Handling
Dec 18, 2019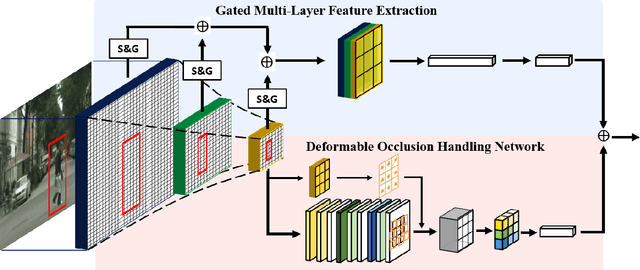
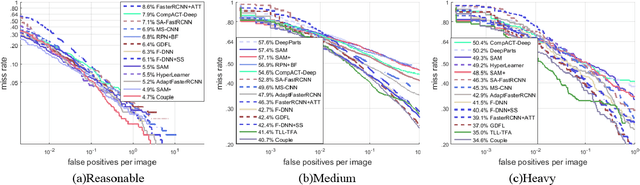


Pedestrian detection methods have been significantly improved with the development of deep convolutional neural networks. Nevertheless, detecting small-scaled pedestrians and occluded pedestrians remains a challenging problem. In this paper, we propose a pedestrian detection method with a couple-network to simultaneously address these two issues. One of the sub-networks, the gated multi-layer feature extraction sub-network, aims to adaptively generate discriminative features for pedestrian candidates in order to robustly detect pedestrians with large variations on scales. The second sub-network targets in handling the occlusion problem of pedestrian detection by using deformable regional RoI-pooling. We investigate two different gate units for the gated sub-network, namely, the channel-wise gate unit and the spatio-wise gate unit, which can enhance the representation ability of the regional convolutional features among the channel dimensions or across the spatial domain, repetitively. Ablation studies have validated the effectiveness of both the proposed gated multi-layer feature extraction sub-network and the deformable occlusion handling sub-network. With the coupled framework, our proposed pedestrian detector achieves state-of-the-art results on the Caltech and the CityPersons pedestrian detection benchmarks.