 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTao Zhang
Improving the Certified Robustness of Neural Networks via Consistency Regularization
Dec 24, 2020
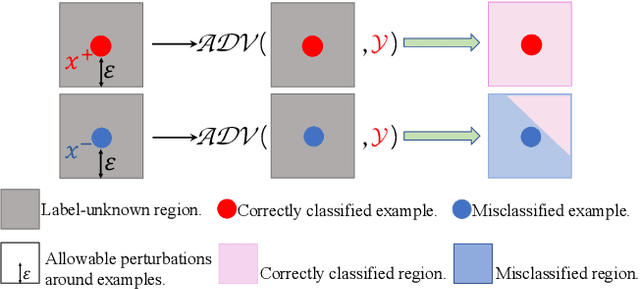
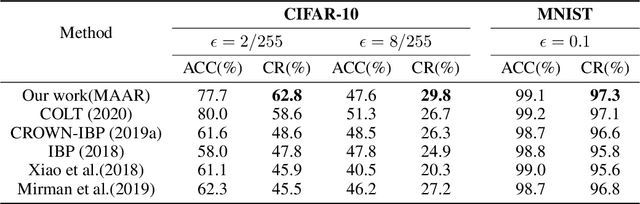
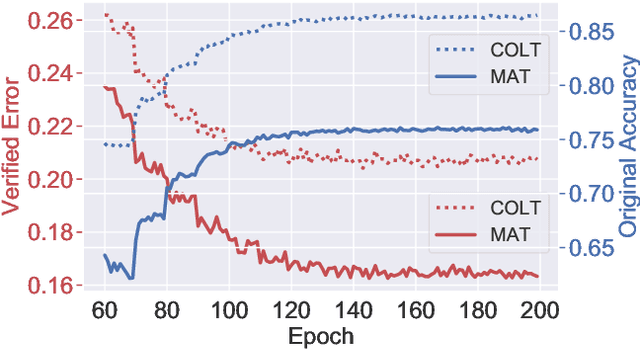
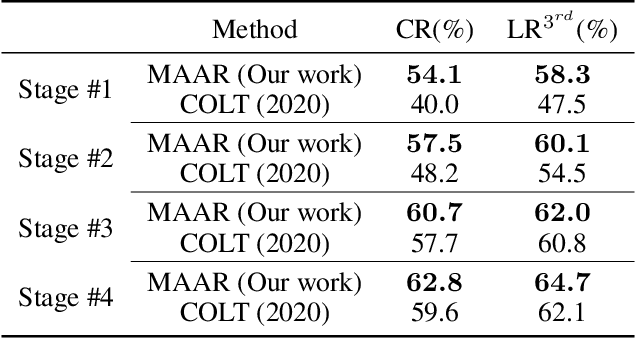
A range of defense methods have been proposed to improve the robustness of neural networks on adversarial examples, among which provable defense methods have been demonstrated to be effective to train neural networks that are certifiably robust to the attacker. However, most of these provable defense methods treat all examples equally during training process, which ignore the inconsistent constraint of certified robustness between correctly classified (natural) and misclassified examples. In this paper, we explore this inconsistency caused by misclassified examples and add a novel consistency regularization term to make better use of the misclassified examples. Specifically, we identified that the certified robustness of network can be significantly improved if the constraint of certified robustness on misclassified examples and correctly classified examples is consistent. Motivated by this discovery, we design a new defense regularization term called Misclassification Aware Adversarial Regularization (MAAR), which constrains the output probability distributions of all examples in the certified region of the misclassified example. Experimental results show that our proposed MAAR achieves the best certified robustness and comparable accuracy on CIFAR-10 and MNIST datasets in comparison with several state-of-the-art methods.
On Front-end Gain Invariant Modeling for Wake Word Spotting
Oct 13, 2020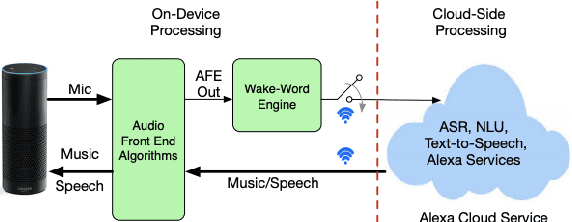
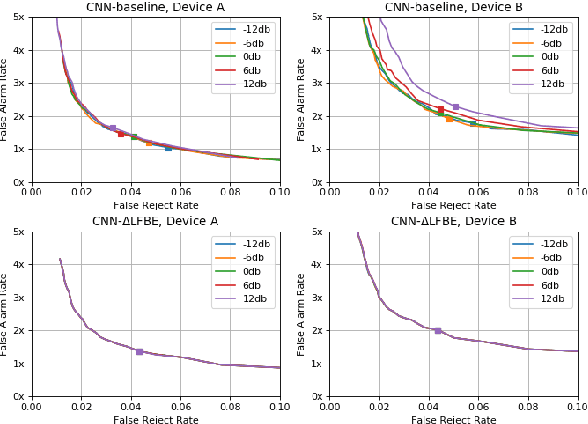
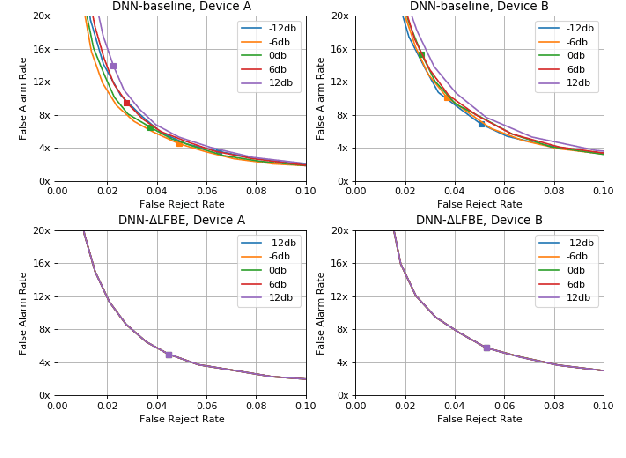
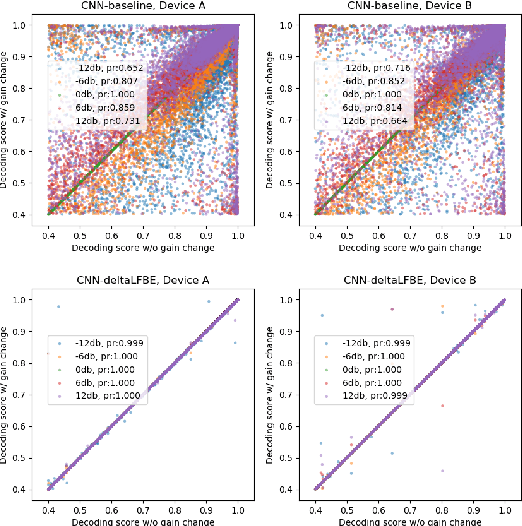
Wake word (WW) spotting is challenging in far-field due to the complexities and variations in acoustic conditions and the environmental interference in signal transmission. A suite of carefully designed and optimized audio front-end (AFE) algorithms help mitigate these challenges and provide better quality audio signals to the downstream modules such as WW spotter. Since the WW model is trained with the AFE-processed audio data, its performance is sensitive to AFE variations, such as gain changes. In addition, when deploying to new devices, the WW performance is not guaranteed because the AFE is unknown to the WW model. To address these issues, we propose a novel approach to use a new feature called $\Delta$LFBE to decouple the AFE gain variations from the WW model. We modified the neural network architectures to accommodate the delta computation, with the feature extraction module unchanged. We evaluate our WW models using data collected from real household settings and showed the models with the $\Delta$LFBE is robust to AFE gain changes. Specifically, when AFE gain changes up to $\pm$12dB, the baseline CNN model lost up to relative 19.0% in false alarm rate or 34.3% in false reject rate, while the model with $\Delta$LFBE demonstrates no performance loss.
Investigating Constraint Relationship in Evolutionary Many-Constraint Optimization
Oct 09, 2020
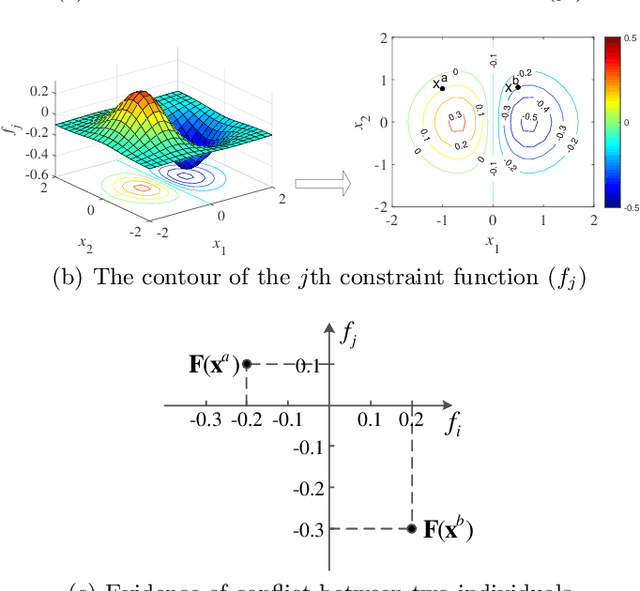
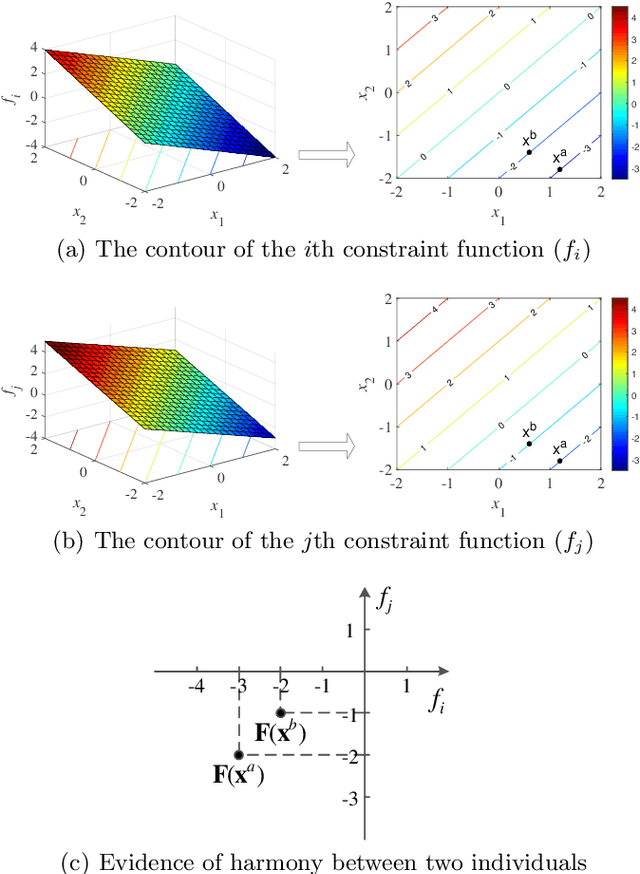
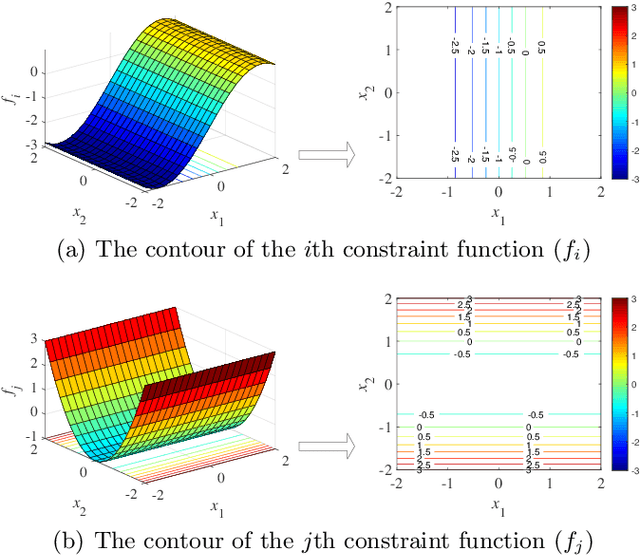
This paper contributes to the treatment of extensive constraints in evolutionary many-constraint optimization through consideration of the relationships between pair-wise constraints. In a conflicting relationship, the functional value of one constraint increases as the value in another constraint decreases. In a harmonious relationship, the improvement in one constraint is rewarded with simultaneous improvement in the other constraint. In an independent relationship, the adjustment to one constraint never affects the adjustment to the other. Based on the different features, methods for identifying constraint relationships are discussed, helping to simplify many-constraint optimization problems (MCOPs). Additionally, the transitivity of the relationships is further discussed at the aim of determining the relationship in a new pair of constraints.
Correlated Differential Privacy: Feature Selection in Machine Learning
Oct 07, 2020
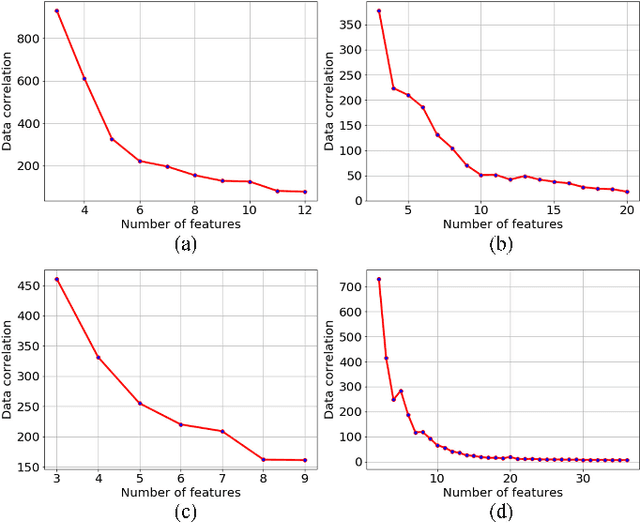
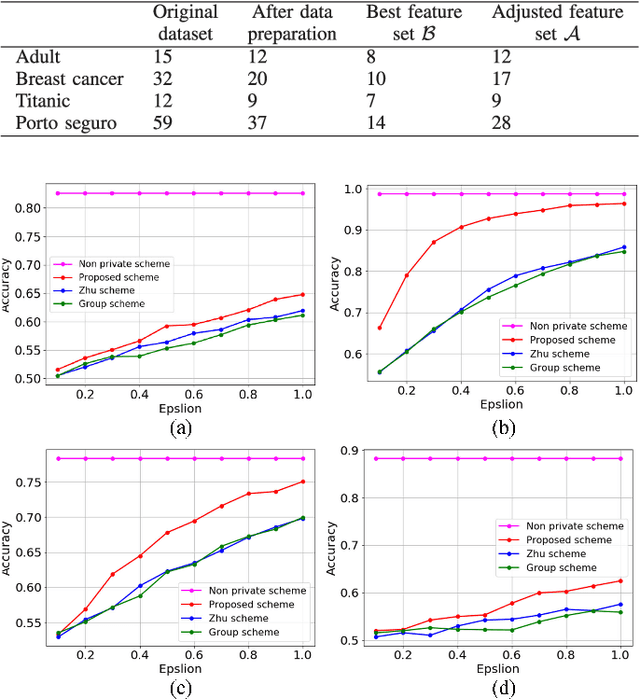
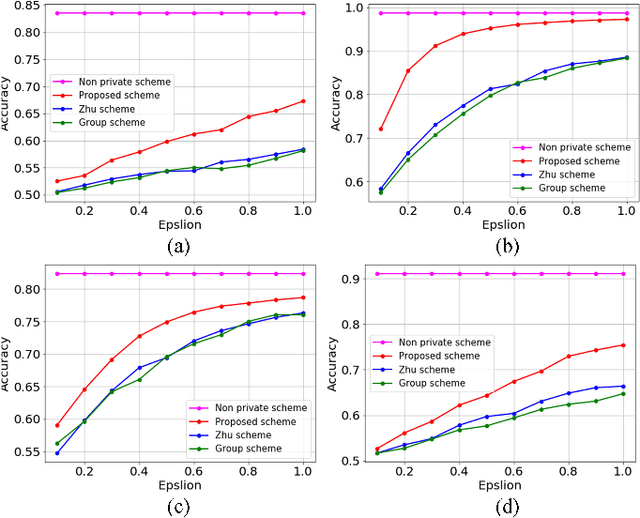
Privacy preserving in machine learning is a crucial issue in industry informatics since data used for training in industries usually contain sensitive information. Existing differentially private machine learning algorithms have not considered the impact of data correlation, which may lead to more privacy leakage than expected in industrial applications. For example, data collected for traffic monitoring may contain some correlated records due to temporal correlation or user correlation. To fill this gap, we propose a correlation reduction scheme with differentially private feature selection considering the issue of privacy loss when data have correlation in machine learning tasks. %The key to the proposed scheme is to describe the data correlation and select features which leads to less data correlation across the whole dataset. The proposed scheme involves five steps with the goal of managing the extent of data correlation, preserving the privacy, and supporting accuracy in the prediction results. In this way, the impact of data correlation is relieved with the proposed feature selection scheme, and moreover, the privacy issue of data correlation in learning is guaranteed. The proposed method can be widely used in machine learning algorithms which provide services in industrial areas. Experiments show that the proposed scheme can produce better prediction results with machine learning tasks and fewer mean square errors for data queries compared to existing schemes.
* This paper has been published in IEEE Transactions on Industrial Informatics
Fairness in Semi-supervised Learning: Unlabeled Data Help to Reduce Discrimination
Sep 25, 2020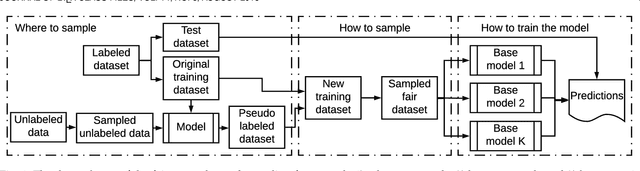
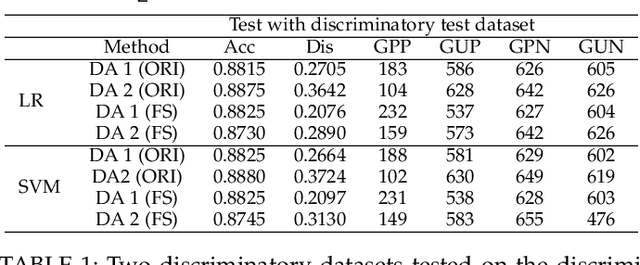
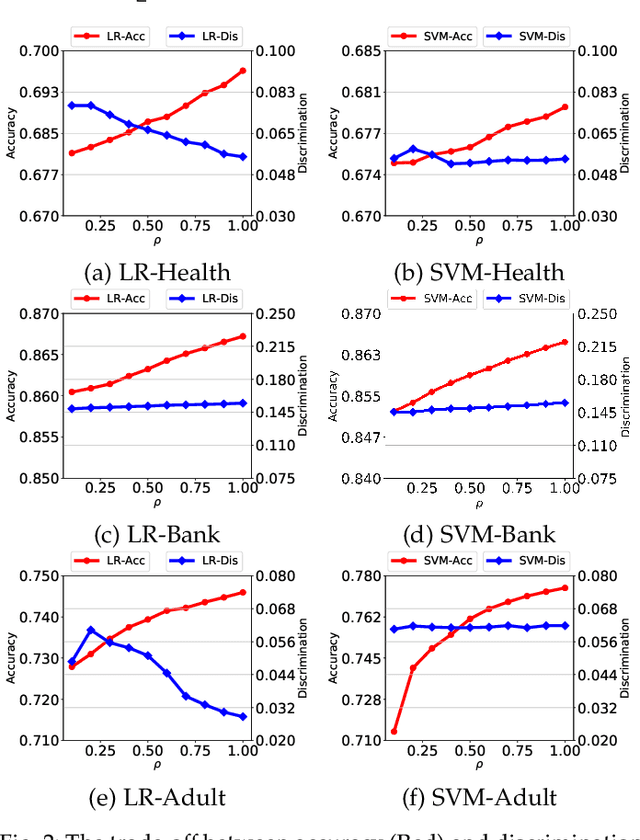
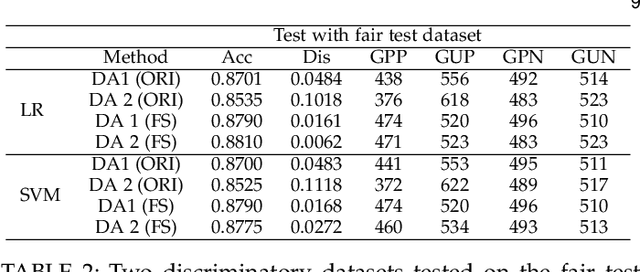
A growing specter in the rise of machine learning is whether the decisions made by machine learning models are fair. While research is already underway to formalize a machine-learning concept of fairness and to design frameworks for building fair models with sacrifice in accuracy, most are geared toward either supervised or unsupervised learning. Yet two observations inspired us to wonder whether semi-supervised learning might be useful to solve discrimination problems. First, previous study showed that increasing the size of the training set may lead to a better trade-off between fairness and accuracy. Second, the most powerful models today require an enormous of data to train which, in practical terms, is likely possible from a combination of labeled and unlabeled data. Hence, in this paper, we present a framework of fair semi-supervised learning in the pre-processing phase, including pseudo labeling to predict labels for unlabeled data, a re-sampling method to obtain multiple fair datasets and lastly, ensemble learning to improve accuracy and decrease discrimination. A theoretical decomposition analysis of bias, variance and noise highlights the different sources of discrimination and the impact they have on fairness in semi-supervised learning. A set of experiments on real-world and synthetic datasets show that our method is able to use unlabeled data to achieve a better trade-off between accuracy and discrimination.
Learning to Match Jobs with Resumes from Sparse Interaction Data using Multi-View Co-Teaching Network
Sep 25, 2020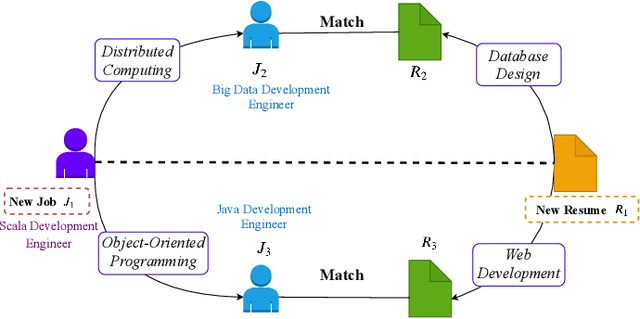
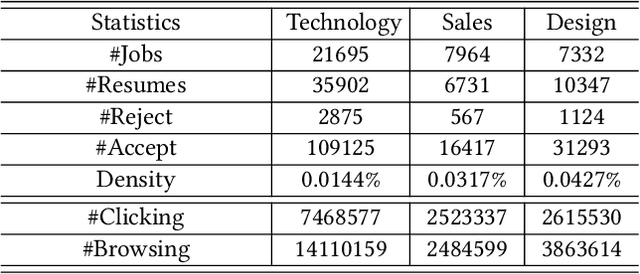
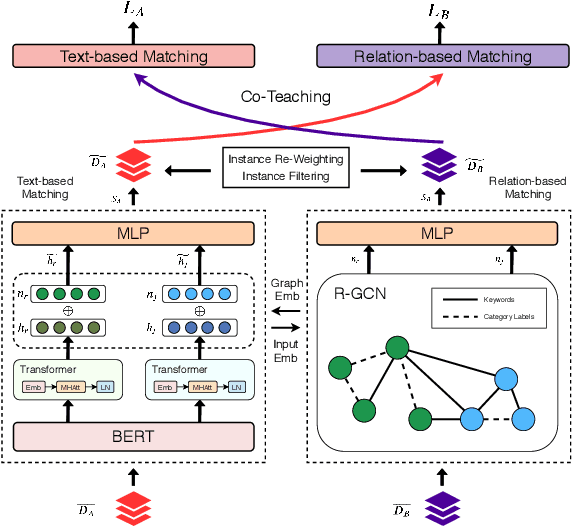
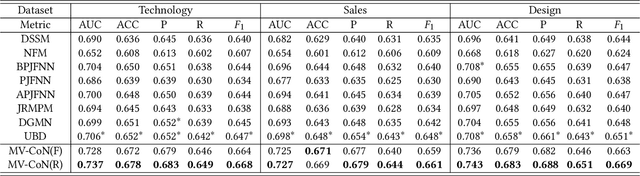
With the ever-increasing growth of online recruitment data, job-resume matching has become an important task to automatically match jobs with suitable resumes. This task is typically casted as a supervised text matching problem. Supervised learning is powerful when the labeled data is sufficient. However, on online recruitment platforms, job-resume interaction data is sparse and noisy, which affects the performance of job-resume match algorithms. To alleviate these problems, in this paper, we propose a novel multi-view co-teaching network from sparse interaction data for job-resume matching. Our network consists of two major components, namely text-based matching model and relation-based matching model. The two parts capture semantic compatibility in two different views, and complement each other. In order to address the challenges from sparse and noisy data, we design two specific strategies to combine the two components. First, two components share the learned parameters or representations, so that the original representations of each component can be enhanced. More importantly, we adopt a co-teaching mechanism to reduce the influence of noise in training data. The core idea is to let the two components help each other by selecting more reliable training instances. The two strategies focus on representation enhancement and data enhancement, respectively. Compared with pure text-based matching models, the proposed approach is able to learn better data representations from limited or even sparse interaction data, which is more resistible to noise in training data. Experiment results have demonstrated that our model is able to outperform state-of-the-art methods for job-resume matching.
Fairness Constraints in Semi-supervised Learning
Sep 14, 2020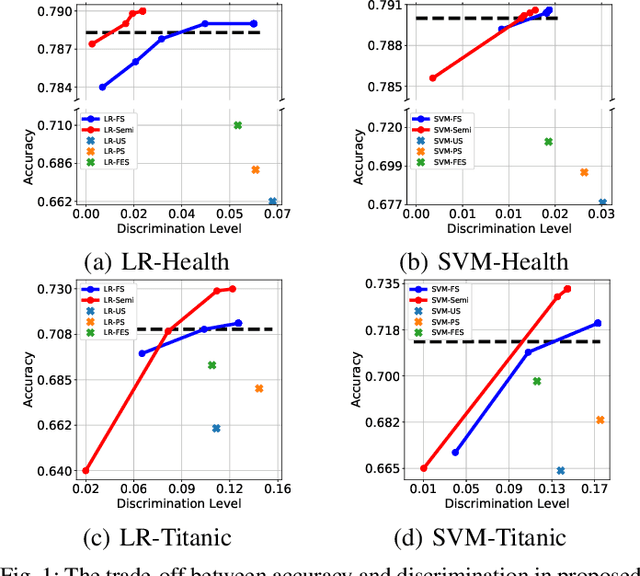
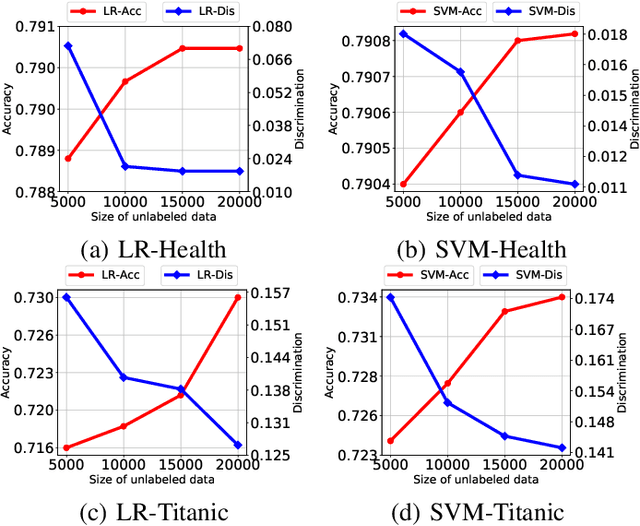
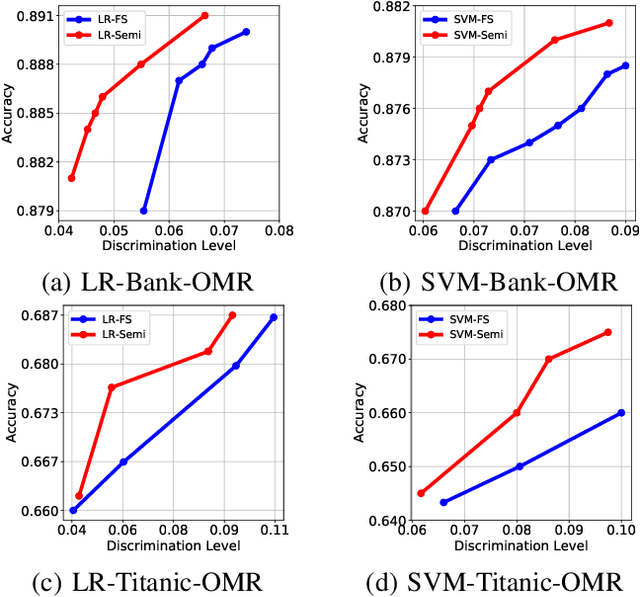
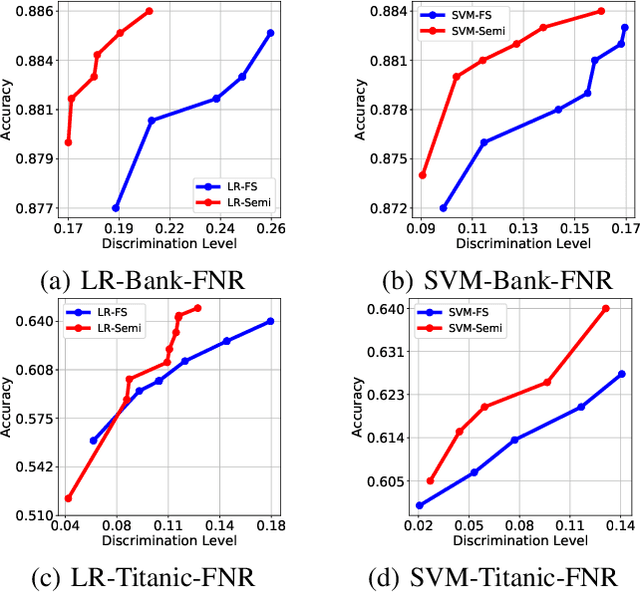
Fairness in machine learning has received considerable attention. However, most studies on fair learning focus on either supervised learning or unsupervised learning. Very few consider semi-supervised settings. Yet, in reality, most machine learning tasks rely on large datasets that contain both labeled and unlabeled data. One of key issues with fair learning is the balance between fairness and accuracy. Previous studies arguing that increasing the size of the training set can have a better trade-off. We believe that increasing the training set with unlabeled data may achieve the similar result. Hence, we develop a framework for fair semi-supervised learning, which is formulated as an optimization problem. This includes classifier loss to optimize accuracy, label propagation loss to optimize unlabled data prediction, and fairness constraints over labeled and unlabeled data to optimize the fairness level. The framework is conducted in logistic regression and support vector machines under the fairness metrics of disparate impact and disparate mistreatment. We theoretically analyze the source of discrimination in semi-supervised learning via bias, variance and noise decomposition. Extensive experiments show that our method is able to achieve fair semi-supervised learning, and reach a better trade-off between accuracy and fairness than fair supervised learning.
Re-weighting and 1-Point RANSAC-Based PnP Solution to Handle Outliers
Jul 16, 2020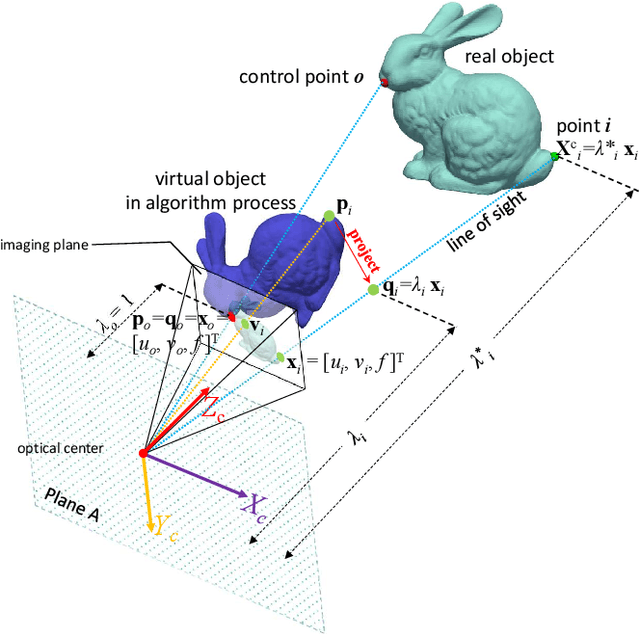
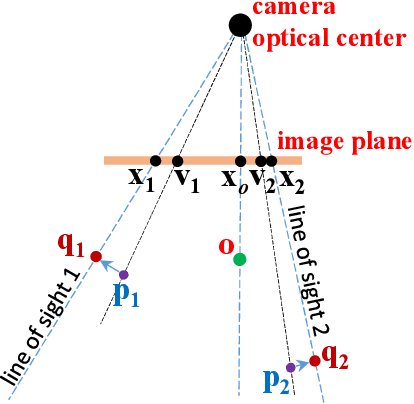
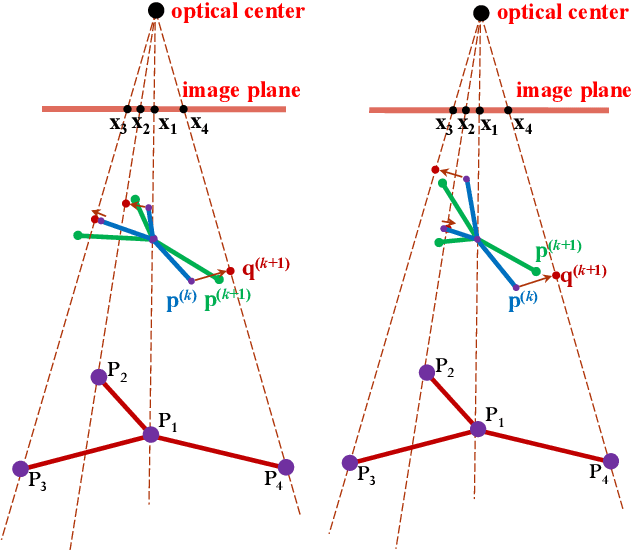
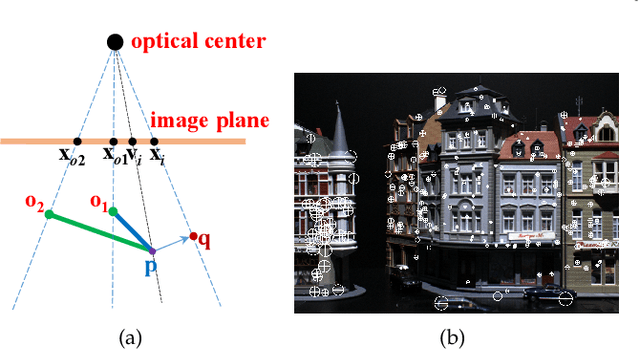
The ability to handle outliers is essential for performing the perspective-n-point (PnP) approach in practical applications, but conventional RANSAC+P3P or P4P methods have high time complexities. We propose a fast PnP solution named R1PPnP to handle outliers by utilizing a soft re-weighting mechanism and the 1-point RANSAC scheme. We first present a PnP algorithm, which serves as the core of R1PPnP, for solving the PnP problem in outlier-free situations. The core algorithm is an optimal process minimizing an objective function conducted with a random control point. Then, to reduce the impact of outliers, we propose a reprojection error-based re-weighting method and integrate it into the core algorithm. Finally, we employ the 1-point RANSAC scheme to try different control points. Experiments with synthetic and real-world data demonstrate that R1PPnP is faster than RANSAC+P3P or P4P methods especially when the percentage of outliers is large, and is accurate. Besides, comparisons with outlier-free synthetic data show that R1PPnP is among the most accurate and fast PnP solutions, which usually serve as the final refinement step of RANSAC+P3P or P4P. Compared with REPPnP, which is the state-of-the-art PnP algorithm with an explicit outliers-handling mechanism, R1PPnP is slower but does not suffer from the percentage of outliers limitation as REPPnP.
* https://github.com/haoyinzhou/PnP_Toolbox
Channel Compression: Rethinking Information Redundancy among Channels in CNN Architecture
Jul 02, 2020
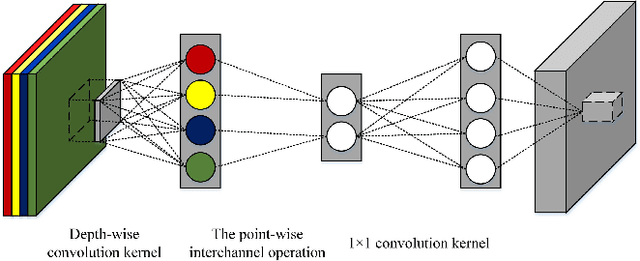
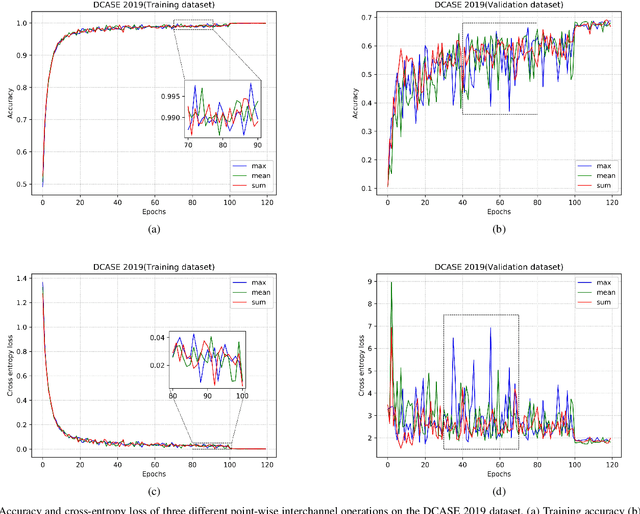
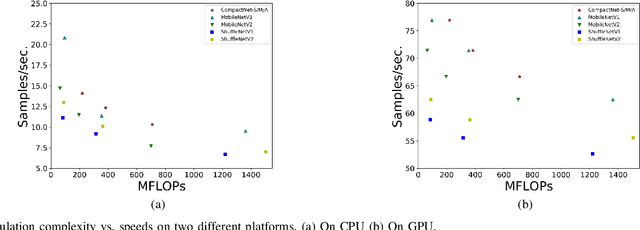
Model compression and acceleration are attracting increasing attentions due to the demand for embedded devices and mobile applications. Research on efficient convolutional neural networks (CNNs) aims at removing feature redundancy by decomposing or optimizing the convolutional calculation. In this work, feature redundancy is assumed to exist among channels in CNN architectures, which provides some leeway to boost calculation efficiency. Aiming at channel compression, a novel convolutional construction named compact convolution is proposed to embrace the progress in spatial convolution, channel grouping and pooling operation. Specifically, the depth-wise separable convolution and the point-wise interchannel operation are utilized to efficiently extract features. Different from the existing channel compression method which usually introduces considerable learnable weights, the proposed compact convolution can reduce feature redundancy with no extra parameters. With the point-wise interchannel operation, compact convolutions implicitly squeeze the channel dimension of feature maps. To explore the rules on reducing channel redundancy in neural networks, the comparison is made among different point-wise interchannel operations. Moreover, compact convolutions are extended to tackle with multiple tasks, such as acoustic scene classification, sound event detection and image classification. The extensive experiments demonstrate that our compact convolution not only exhibits high effectiveness in several multimedia tasks, but also can be efficiently implemented by benefiting from parallel computation.
Evolving Metric Learning for Incremental and Decremental Features
Jun 27, 2020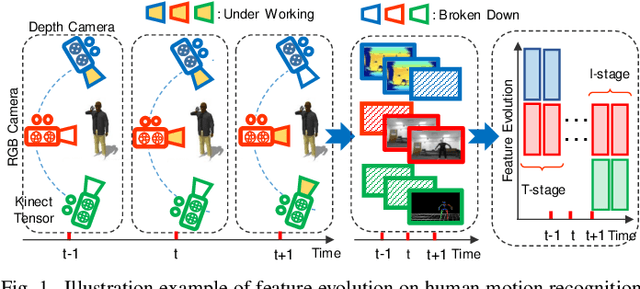
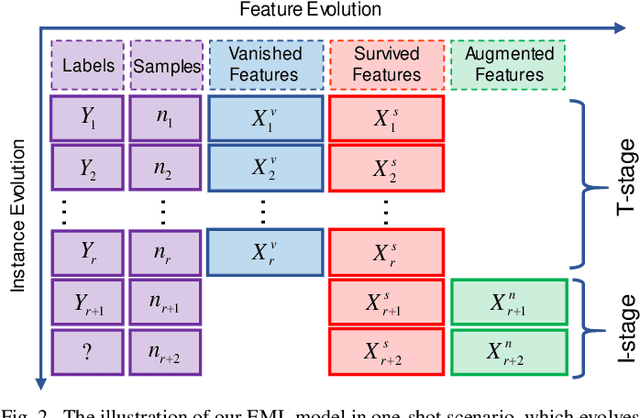
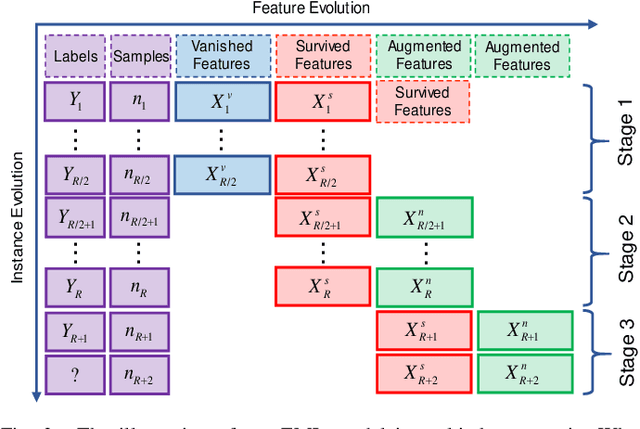

Online metric learning has been widely exploited for large-scale data classification due to the low computational cost. However, amongst online practical scenarios where the features are evolving (e.g., some features are vanished and some new features are augmented), most metric learning models cannot be successfully applied into these scenarios although they can tackle the evolving instances efficiently. To address the challenge, we propose a new online Evolving Metric Learning (EML) model for incremental and decremental features, which can handle the instance and feature evolutions simultaneously by incorporating with a smoothed Wasserstein metric distance. Specifically, our model contains two essential stages: the Transforming stage (T-stage) and the Inheriting stage (I-stage). For the T-stage, we propose to extract important information from vanished features while neglecting non-informative knowledge, and forward it into survived features by transforming them into a low-rank discriminative metric space. It further explores the intrinsic low-rank structure of heterogeneous samples to reduce the computation and memory burden especially for highly-dimensional large-scale data. For the I-stage, we inherit the metric performance of survived features from the T-stage and then expand to include the augmented new features. Moreover, the smoothed Wasserstein distance is utilized to characterize the similarity relations among the complex and heterogeneous data, since the evolving features in the different stages are not strictly aligned. In addition to tackling the challenges in one-shot case, we also extend our model into multi-shot scenario. After deriving an efficient optimization method for both T-stage and I-stage, extensive experiments on several benchmark datasets verify the superiority of our model.