 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoice Biomarkers for Depression and Anxiety
May 11, 2026Current approaches to detecting depression and anxiety from speech primarily rely on machine learning techniques that utilize hand-engineered paralinguistic features and related acoustic descriptors derived from time- and frequency-domain representations of speech signals. Applying deep learning methods directly to raw speech signals has the potential to produce biomarker representations with substantially greater predictive power. However, these approaches typically require large volumes of carefully annotated data to learn robust and clinically meaningful representations of the underlying biomarkers. In this paper, we describe our efforts toward developing a deep learning model trained on a large-scale proprietary dataset comprising ~65,000 utterances collected from more than 23,000 subjects representative of relevant United States demographics. We present the techniques employed and analyze their impact on model performance. Our results demonstrate that the proposed models can extract content-agnostic biomarker information, which, when combined with lexical features extracted from audio, yields improved predictive performance in production settings. Our models are evaluated on ~5000 unique subjects and achieve performance of 71% in terms of sensitivity and specificity. To foster further research in mental health assessment from speech, we release the best-performing model described in this paper on HuggingFace.
On Front-end Gain Invariant Modeling for Wake Word Spotting
Oct 13, 2020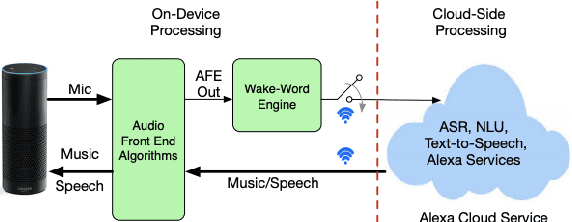
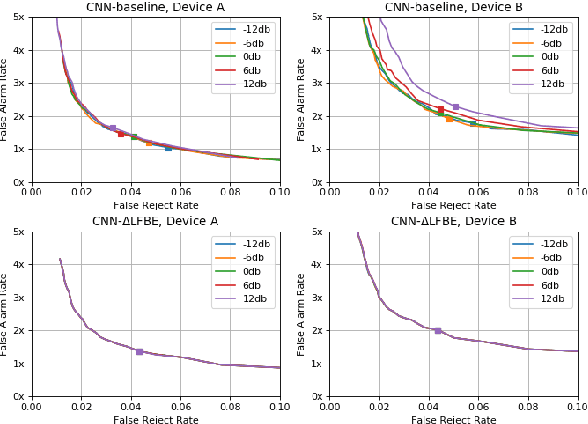
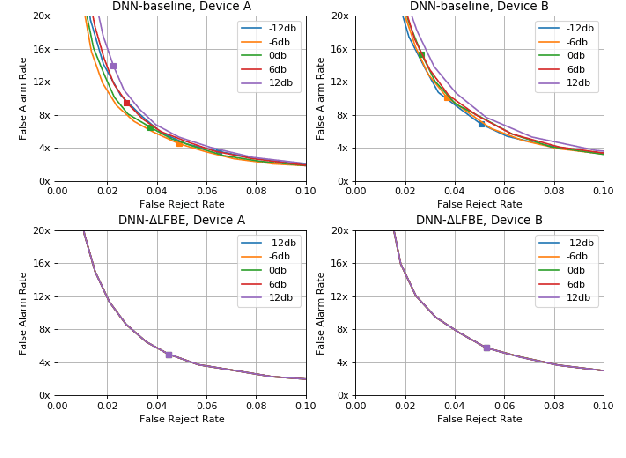
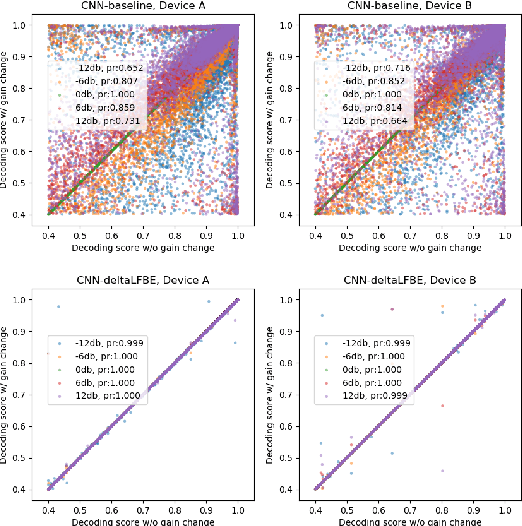
Wake word (WW) spotting is challenging in far-field due to the complexities and variations in acoustic conditions and the environmental interference in signal transmission. A suite of carefully designed and optimized audio front-end (AFE) algorithms help mitigate these challenges and provide better quality audio signals to the downstream modules such as WW spotter. Since the WW model is trained with the AFE-processed audio data, its performance is sensitive to AFE variations, such as gain changes. In addition, when deploying to new devices, the WW performance is not guaranteed because the AFE is unknown to the WW model. To address these issues, we propose a novel approach to use a new feature called $\Delta$LFBE to decouple the AFE gain variations from the WW model. We modified the neural network architectures to accommodate the delta computation, with the feature extraction module unchanged. We evaluate our WW models using data collected from real household settings and showed the models with the $\Delta$LFBE is robust to AFE gain changes. Specifically, when AFE gain changes up to $\pm$12dB, the baseline CNN model lost up to relative 19.0% in false alarm rate or 34.3% in false reject rate, while the model with $\Delta$LFBE demonstrates no performance loss.
Nonnegative Tensor Factorization for Directional Blind Audio Source Separation
May 26, 2017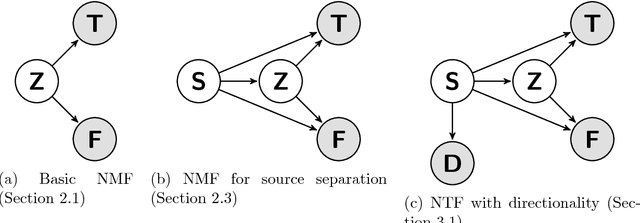
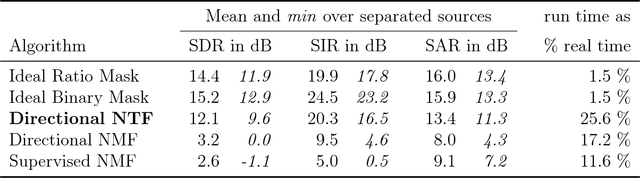
We augment the nonnegative matrix factorization method for audio source separation with cues about directionality of sound propagation. This improves separation quality greatly and removes the need for training data, with only a twofold increase in run time. This is the first method which can exploit directional information from microphone arrays much smaller than the wavelength of sound, working both in simulation and in practice on millimeter-scale microphone arrays.