 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Learning Semantic Representations for Million-Scale Free-Hand Sketches
Jul 07, 2020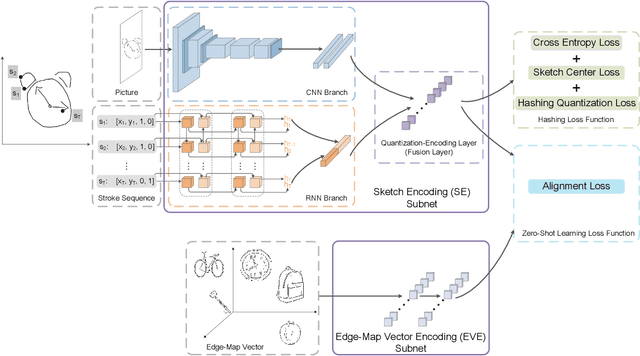
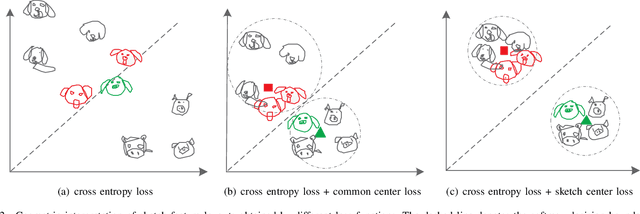
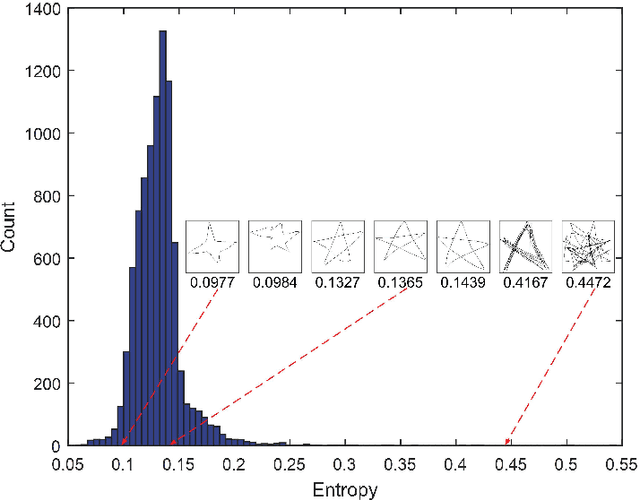

In this paper, we study learning semantic representations for million-scale free-hand sketches. This is highly challenging due to the domain-unique traits of sketches, e.g., diverse, sparse, abstract, noisy. We propose a dual-branch CNNRNN network architecture to represent sketches, which simultaneously encodes both the static and temporal patterns of sketch strokes. Based on this architecture, we further explore learning the sketch-oriented semantic representations in two challenging yet practical settings, i.e., hashing retrieval and zero-shot recognition on million-scale sketches. Specifically, we use our dual-branch architecture as a universal representation framework to design two sketch-specific deep models: (i) We propose a deep hashing model for sketch retrieval, where a novel hashing loss is specifically designed to accommodate both the abstract and messy traits of sketches. (ii) We propose a deep embedding model for sketch zero-shot recognition, via collecting a large-scale edge-map dataset and proposing to extract a set of semantic vectors from edge-maps as the semantic knowledge for sketch zero-shot domain alignment. Both deep models are evaluated by comprehensive experiments on million-scale sketches and outperform the state-of-the-art competitors.
Learning to Generate Novel Domains for Domain Generalization
Jul 07, 2020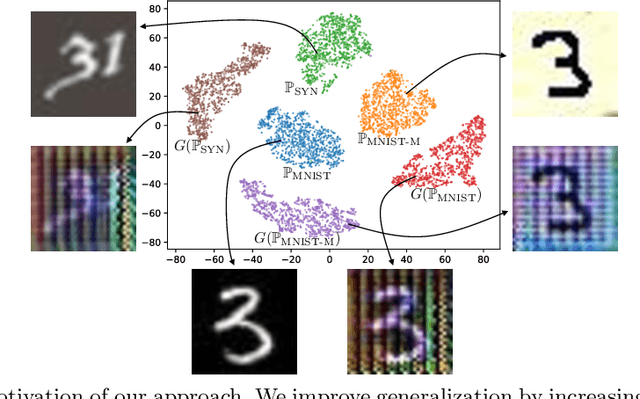
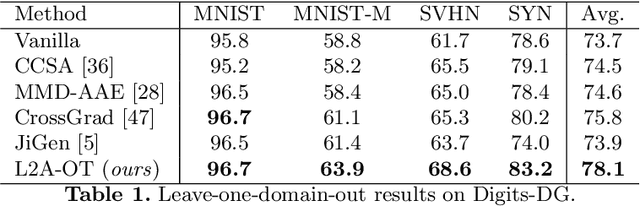

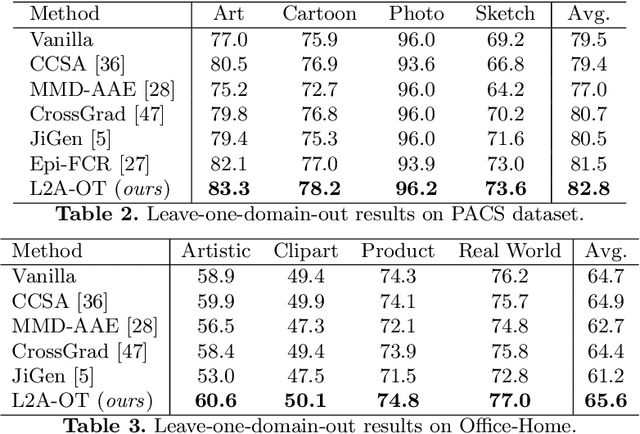
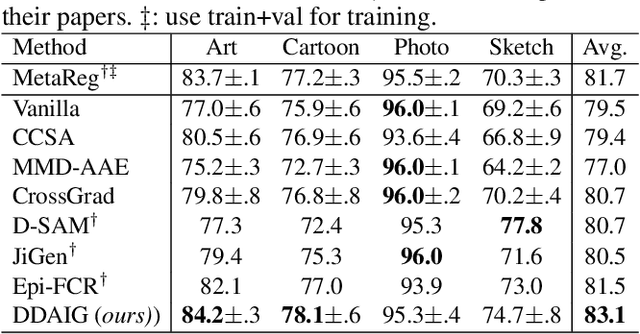
This paper focuses on domain generalization (DG), the task of learning from multiple source domains a model that generalizes well to unseen domains. A main challenge for DG is that the available source domains often exhibit limited diversity, hampering the model's ability to learn to generalize. We therefore employ a data generator to synthesize data from pseudo-novel domains to augment the source domains. This explicitly increases the diversity of available training domains and leads to a more generalizable model. To train the generator, we model the distribution divergence between source and synthesized pseudo-novel domains using optimal transport, and maximize the divergence. To ensure that semantics are preserved in the synthesized data, we further impose cycle-consistency and classification losses on the generator. Our method, L2A-OT (Learning to Augment by Optimal Transport) outperforms current state-of-the-art DG methods on four benchmark datasets.
Egocentric Action Recognition by Video Attention and Temporal Context
Jul 03, 2020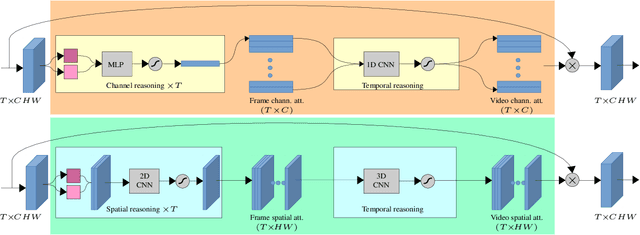
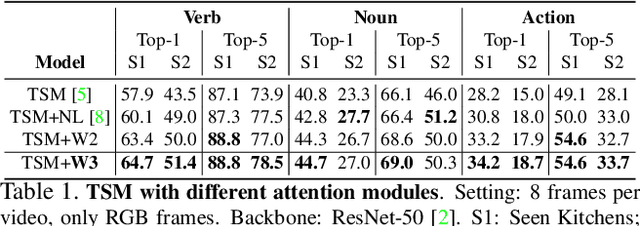
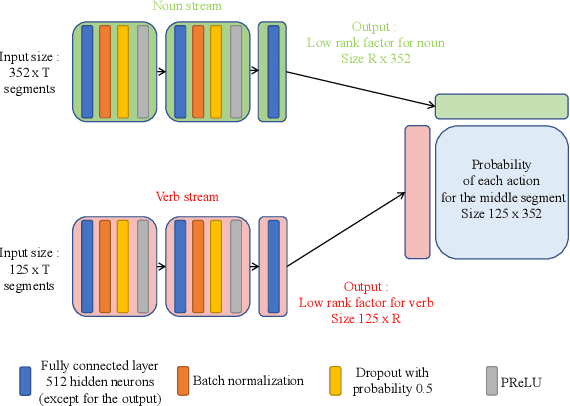
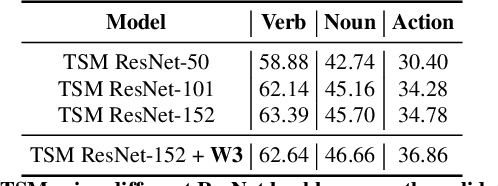
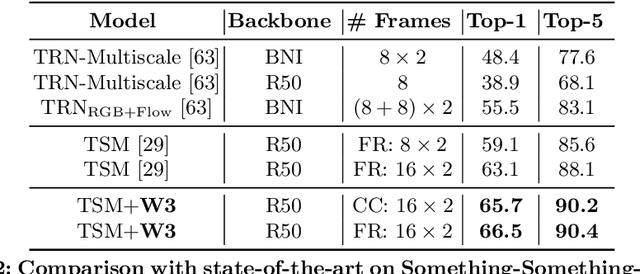
We present the submission of Samsung AI Centre Cambridge to the CVPR2020 EPIC-Kitchens Action Recognition Challenge. In this challenge, action recognition is posed as the problem of simultaneously predicting a single `verb' and `noun' class label given an input trimmed video clip. That is, a `verb' and a `noun' together define a compositional `action' class. The challenging aspects of this real-life action recognition task include small fast moving objects, complex hand-object interactions, and occlusions. At the core of our submission is a recently-proposed spatial-temporal video attention model, called `W3' (`What-Where-When') attention~\cite{perez2020knowing}. We further introduce a simple yet effective contextual learning mechanism to model `action' class scores directly from long-term temporal behaviour based on the `verb' and `noun' prediction scores. Our solution achieves strong performance on the challenge metrics without using object-specific reasoning nor extra training data. In particular, our best solution with multimodal ensemble achieves the 2$^{nd}$ best position for `verb', and 3$^{rd}$ best for `noun' and `action' on the Seen Kitchens test set.
Differentially Private Decentralized Learning
Jun 14, 2020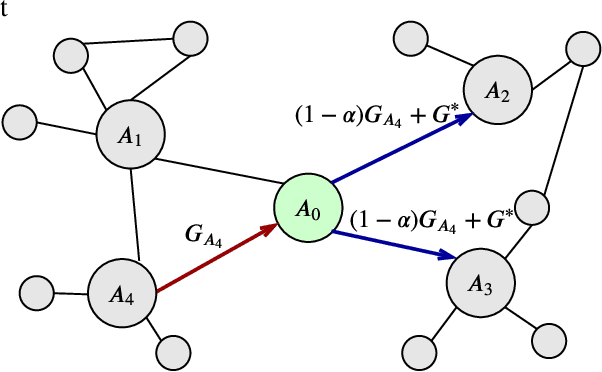
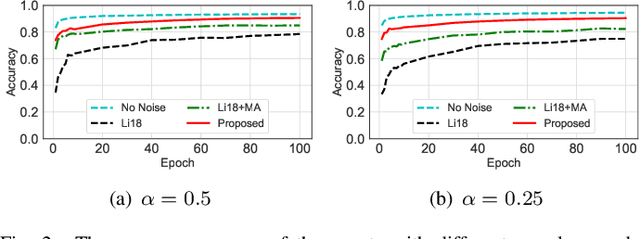
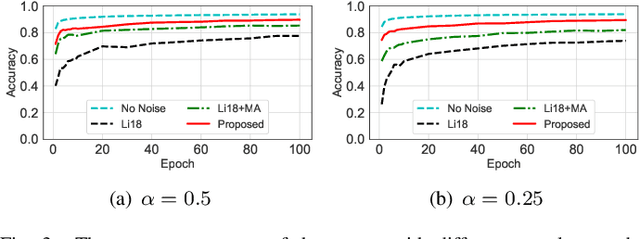
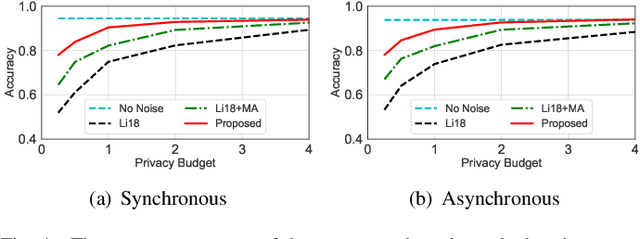
Decentralized learning has received great attention for its high efficiency and performance. In such systems, every participant constantly exchanges parameters with each other to train a shared model, which can put him at the risk of data privacy leakage. Differential Privacy (DP) has been adopted to enhance the Stochastic Gradient Descent (SGD) algorithm. However, these approaches mainly focus on single-party learning, or centralized learning in the synchronous mode. In this paper, we design a novel DP-SGD algorithm for decentralized learning systems. The key contribution of our solution is a \emph{topology-aware} optimization strategy, which leverages the unique network characteristics of decentralized systems to effectively reduce the noise scale and improve the model usability. Besides, we design a novel learning protocol for both synchronous and asynchronous decentralized systems by restricting the sensitivity of the SGD algorithm and maximizing the noise reduction. We formally analyze and prove the DP requirement of our proposed algorithms. Experimental evaluations demonstrate that our algorithm achieves a better trade-off between usability and privacy than prior works.
Long-Term Cloth-Changing Person Re-identification
May 27, 2020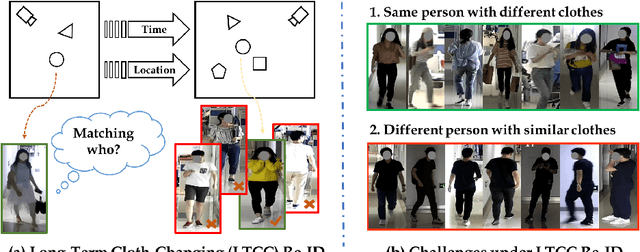
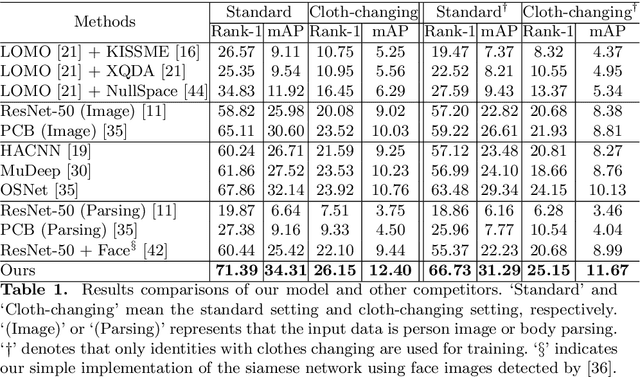
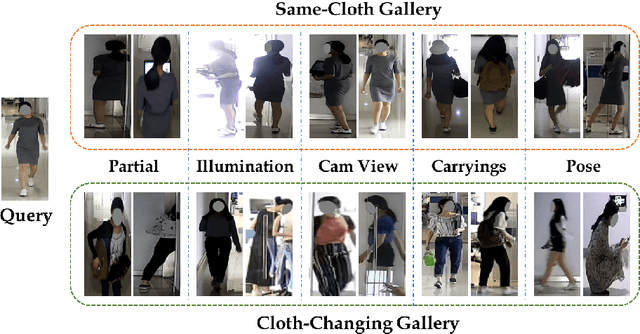
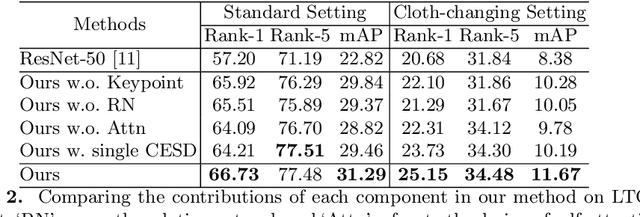
Person re-identification (Re-ID) aims to match a target person across camera views at different locations and times. Existing Re-ID studies focus on the short-term cloth-consistent setting, under which a person re-appears in different camera views with the same outfit. A discriminative feature representation learned by existing deep Re-ID models is thus dominated by the visual appearance of clothing. In this work, we focus on a much more difficult yet practical setting where person matching is conducted over long-duration, e.g., over days and months and therefore inevitably under the new challenge of changing clothes. This problem, termed Long-Term Cloth-Changing (LTCC) Re-ID is much understudied due to the lack of large scale datasets. The first contribution of this work is a new LTCC dataset containing people captured over a long period of time with frequent clothing changes. As a second contribution, we propose a novel Re-ID method specifically designed to address the cloth-changing challenge. Specifically, we consider that under cloth-changes, soft-biometrics such as body shape would be more reliable. We, therefore, introduce a shape embedding module as well as a cloth-elimination shape-distillation module aiming to eliminate the now unreliable clothing appearance features and focus on the body shape information. Extensive experiments show that superior performance is achieved by the proposed model on the new LTCC dataset. The code and dataset will be available at https://naiq.github.io/LTCC_Perosn_ReID.html.
Knowing What, Where and When to Look: Efficient Video Action Modeling with Attention
Apr 02, 2020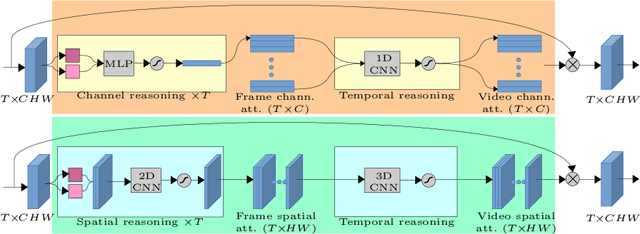
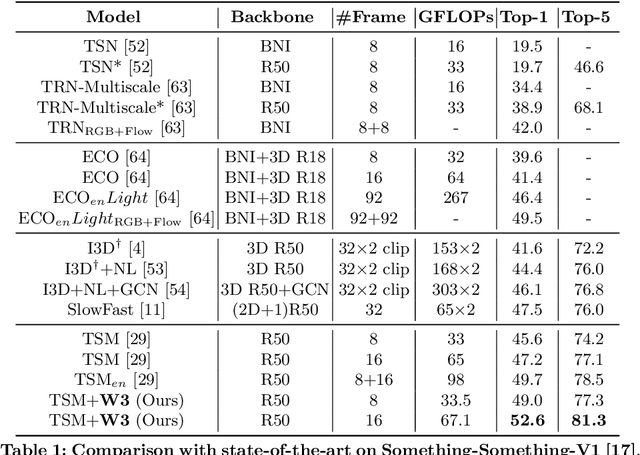
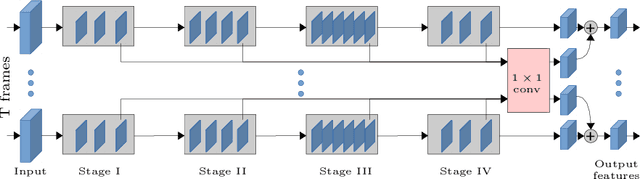
Attentive video modeling is essential for action recognition in unconstrained videos due to their rich yet redundant information over space and time. However, introducing attention in a deep neural network for action recognition is challenging for two reasons. First, an effective attention module needs to learn what (objects and their local motion patterns), where (spatially), and when (temporally) to focus on. Second, a video attention module must be efficient because existing action recognition models already suffer from high computational cost. To address both challenges, a novel What-Where-When (W3) video attention module is proposed. Departing from existing alternatives, our W3 module models all three facets of video attention jointly. Crucially, it is extremely efficient by factorizing the high-dimensional video feature data into low-dimensional meaningful spaces (1D channel vector for `what' and 2D spatial tensors for `where'), followed by lightweight temporal attention reasoning. Extensive experiments show that our attention model brings significant improvements to existing action recognition models, achieving new state-of-the-art performance on a number of benchmarks.
Domain-Adaptive Few-Shot Learning
Mar 19, 2020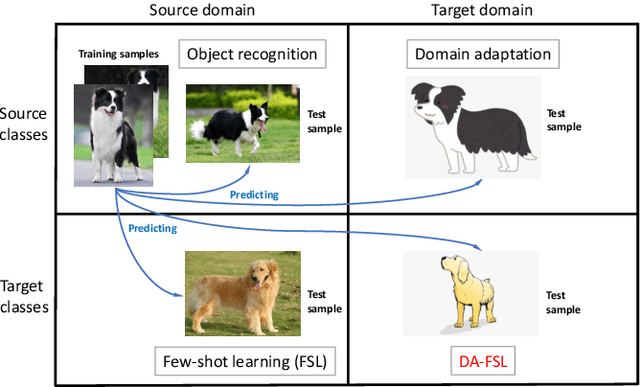
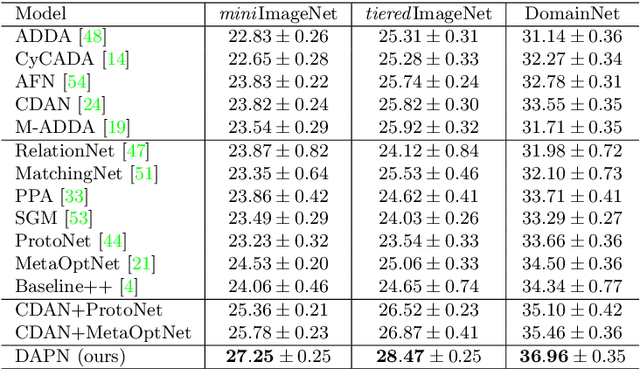
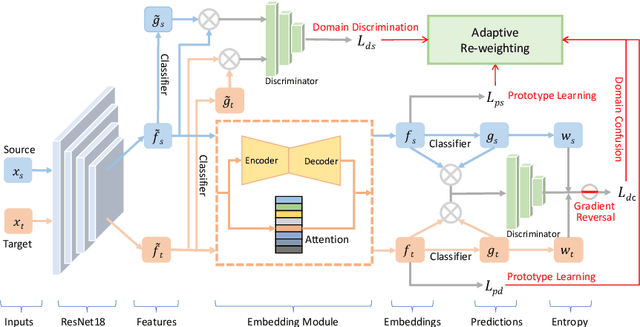
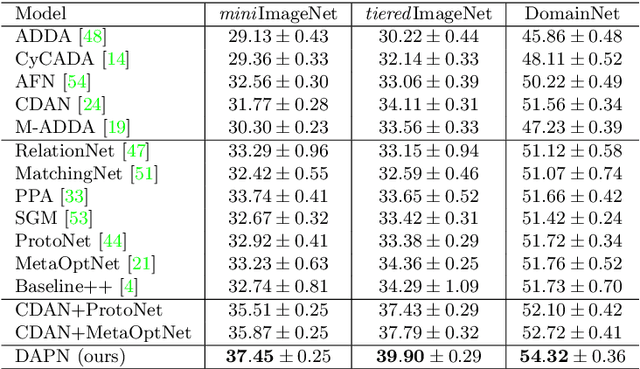
Existing few-shot learning (FSL) methods make the implicit assumption that the few target class samples are from the same domain as the source class samples. However, in practice this assumption is often invalid -- the target classes could come from a different domain. This poses an additional challenge of domain adaptation (DA) with few training samples. In this paper, the problem of domain-adaptive few-shot learning (DA-FSL) is tackled, which requires solving FSL and DA in a unified framework. To this end, we propose a novel domain-adversarial prototypical network (DAPN) model. It is designed to address a specific challenge in DA-FSL: the DA objective means that the source and target data distributions need to be aligned, typically through a shared domain-adaptive feature embedding space; but the FSL objective dictates that the target domain per class distribution must be different from that of any source domain class, meaning aligning the distributions across domains may harm the FSL performance. How to achieve global domain distribution alignment whilst maintaining source/target per-class discriminativeness thus becomes the key. Our solution is to explicitly enhance the source/target per-class separation before domain-adaptive feature embedding learning in the DAPN, in order to alleviate the negative effect of domain alignment on FSL. Extensive experiments show that our DAPN outperforms the state-of-the-art FSL and DA models, as well as their na\"ive combinations. The code is available at https://github.com/dingmyu/DAPN.
Domain Adaptive Ensemble Learning
Mar 16, 2020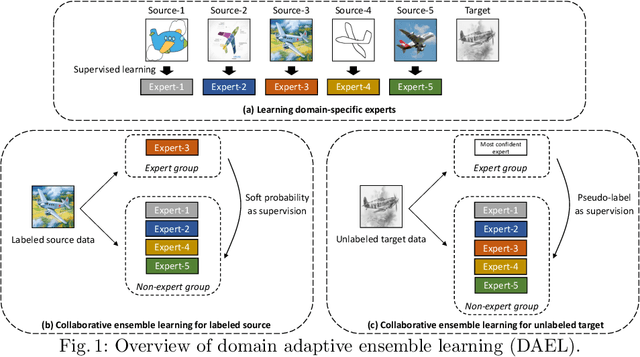
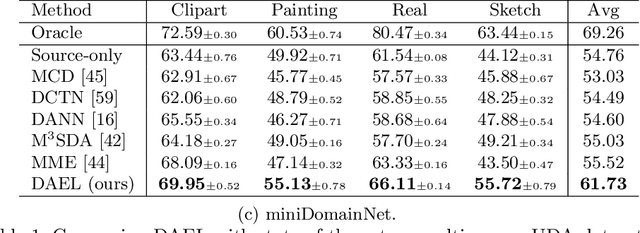
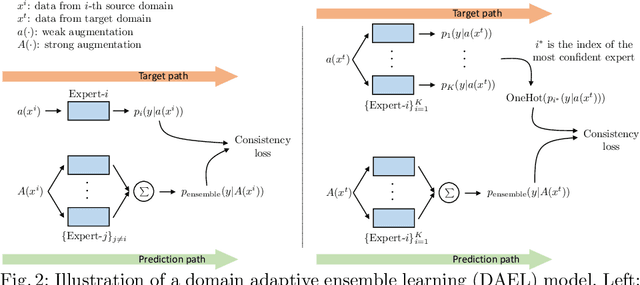
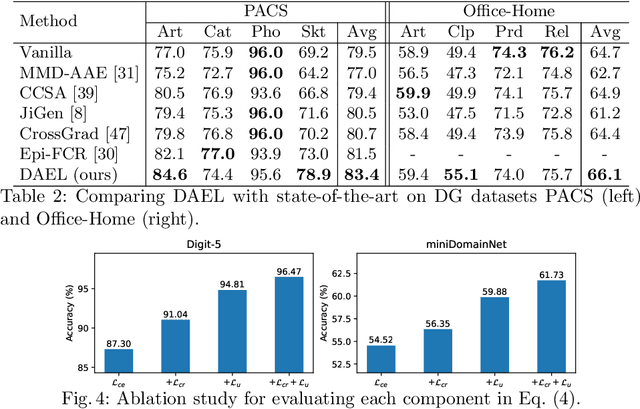
The problem of generalizing deep neural networks from multiple source domains to a target one is studied under two settings: When unlabeled target data is available, it is a multi-source unsupervised domain adaptation (UDA) problem, otherwise a domain generalization (DG) problem. We propose a unified framework termed domain adaptive ensemble learning (DAEL) to address both problems. A DAEL model is composed of a CNN feature extractor shared across domains and multiple classifier heads each trained to specialize in a particular source domain. Each such classifier is an expert to its own domain and a non-expert to others. DAEL aims to learn these experts collaboratively so that when forming an ensemble, they can leverage complementary information from each other to be more effective for an unseen target domain. To this end, each source domain is used in turn as a pseudo-target-domain with its own expert providing supervision signal to the ensemble of non-experts learned from the other sources. For unlabeled target data under the UDA setting where real expert does not exist, DAEL uses pseudo-label to supervise the ensemble learning. Extensive experiments on three multi-source UDA datasets and two DG datasets show that DAEL improves the state-of-the-art on both problems, often by significant margins. The code is released at \url{https://github.com/KaiyangZhou/Dassl.pytorch}.
Deep Domain-Adversarial Image Generation for Domain Generalisation
Mar 12, 2020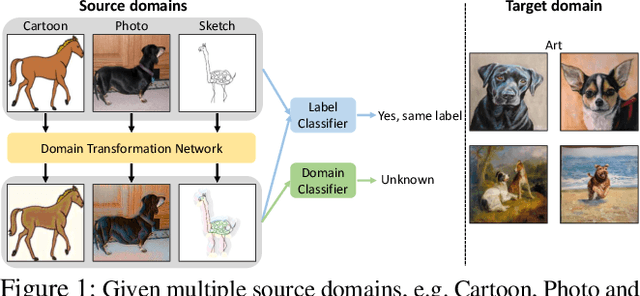
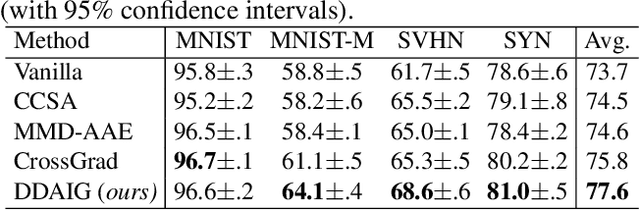
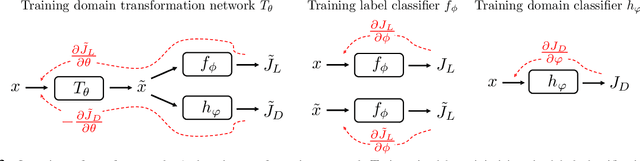
Machine learning models typically suffer from the domain shift problem when trained on a source dataset and evaluated on a target dataset of different distribution. To overcome this problem, domain generalisation (DG) methods aim to leverage data from multiple source domains so that a trained model can generalise to unseen domains. In this paper, we propose a novel DG approach based on \emph{Deep Domain-Adversarial Image Generation} (DDAIG). Specifically, DDAIG consists of three components, namely a label classifier, a domain classifier and a domain transformation network (DoTNet). The goal for DoTNet is to map the source training data to unseen domains. This is achieved by having a learning objective formulated to ensure that the generated data can be correctly classified by the label classifier while fooling the domain classifier. By augmenting the source training data with the generated unseen domain data, we can make the label classifier more robust to unknown domain changes. Extensive experiments on four DG datasets demonstrate the effectiveness of our approach.
Incremental Few-Shot Object Detection
Mar 12, 2020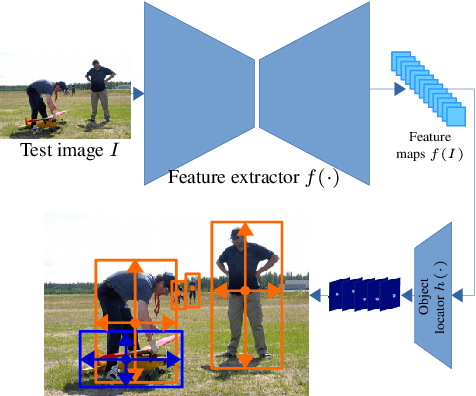
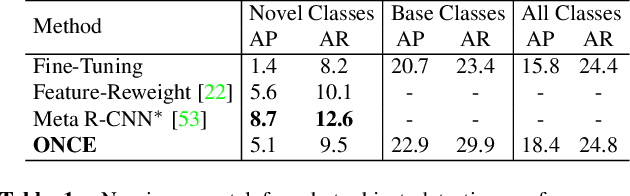
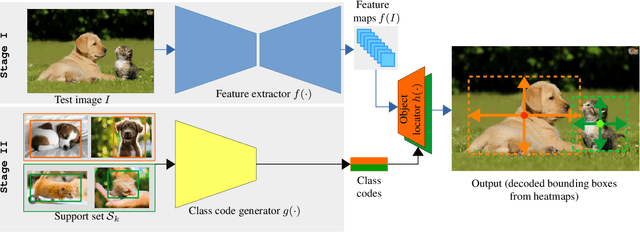
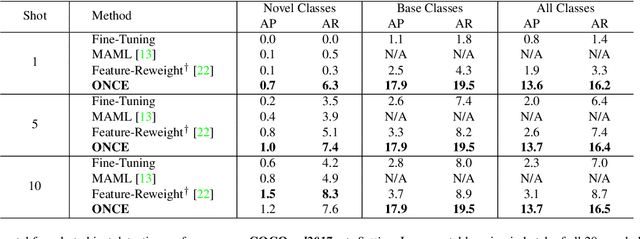
Most existing object detection methods rely on the availability of abundant labelled training samples per class and offline model training in a batch mode. These requirements substantially limit their scalability to open-ended accommodation of novel classes with limited labelled training data. We present a study aiming to go beyond these limitations by considering the Incremental Few-Shot Detection (iFSD) problem setting, where new classes must be registered incrementally (without revisiting base classes) and with few examples. To this end we propose OpeN-ended Centre nEt (ONCE), a detector designed for incrementally learning to detect novel class objects with few examples. This is achieved by an elegant adaptation of the CentreNet detector to the few-shot learning scenario, and meta-learning a class-specific code generator model for registering novel classes. ONCE fully respects the incremental learning paradigm, with novel class registration requiring only a single forward pass of few-shot training samples, and no access to base classes -- thus making it suitable for deployment on embedded devices. Extensive experiments conducted on both the standard object detection and fashion landmark detection tasks show the feasibility of iFSD for the first time, opening an interesting and very important line of research.