 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransforming Weather Data from Pixel to Latent Space
Mar 09, 2025The increasing impact of climate change and extreme weather events has spurred growing interest in deep learning for weather research. However, existing studies often rely on weather data in pixel space, which presents several challenges such as smooth outputs in model outputs, limited applicability to a single pressure-variable subset (PVS), and high data storage and computational costs. To address these challenges, we propose a novel Weather Latent Autoencoder (WLA) that transforms weather data from pixel space to latent space, enabling efficient weather task modeling. By decoupling weather reconstruction from downstream tasks, WLA improves the accuracy and sharpness of weather task model results. The incorporated Pressure-Variable Unified Module transforms multiple PVS into a unified representation, enhancing the adaptability of the model in multiple weather scenarios. Furthermore, weather tasks can be performed in a low-storage latent space of WLA rather than a high-storage pixel space, thus significantly reducing data storage and computational costs. Through extensive experimentation, we demonstrate its superior compression and reconstruction performance, enabling the creation of the ERA5-latent dataset with unified representations of multiple PVS from ERA5 data. The compressed full PVS in the ERA5-latent dataset reduces the original 244.34 TB of data to 0.43 TB. The downstream task further demonstrates that task models can apply to multiple PVS with low data costs in latent space and achieve superior performance compared to models in pixel space. Code, ERA5-latent data, and pre-trained models are available at https://anonymous.4open.science/r/Weather-Latent-Autoencoder-8467.
VQLTI: Long-Term Tropical Cyclone Intensity Forecasting with Physical Constraints
Jan 30, 2025



Tropical cyclone (TC) intensity forecasting is crucial for early disaster warning and emergency decision-making. Numerous researchers have explored deep-learning methods to address computational and post-processing issues in operational forecasting. Regrettably, they exhibit subpar long-term forecasting capabilities. We use two strategies to enhance long-term forecasting. (1) By enhancing the matching between TC intensity and spatial information, we can improve long-term forecasting performance. (2) Incorporating physical knowledge and physical constraints can help mitigate the accumulation of forecasting errors. To achieve the above strategies, we propose the VQLTI framework. VQLTI transfers the TC intensity information to a discrete latent space while retaining the spatial information differences, using large-scale spatial meteorological data as conditions. Furthermore, we leverage the forecast from the weather prediction model FengWu to provide additional physical knowledge for VQLTI. Additionally, we calculate the potential intensity (PI) to impose physical constraints on the latent variables. In the global long-term TC intensity forecasting, VQLTI achieves state-of-the-art results for the 24h to 120h, with the MSW (Maximum Sustained Wind) forecast error reduced by 35.65%-42.51% compared to ECMWF-IFS.
SignEye: Traffic Sign Interpretation from Vehicle First-Person View
Nov 18, 2024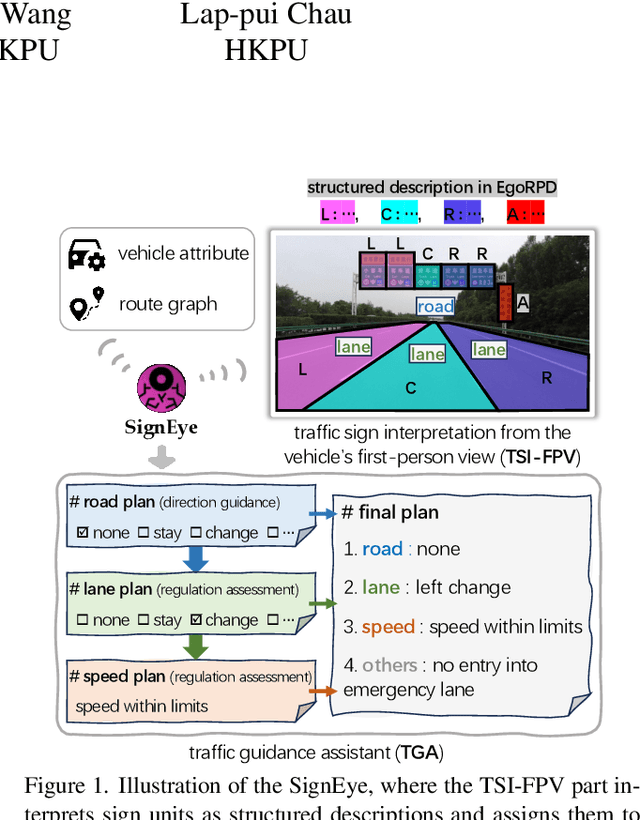

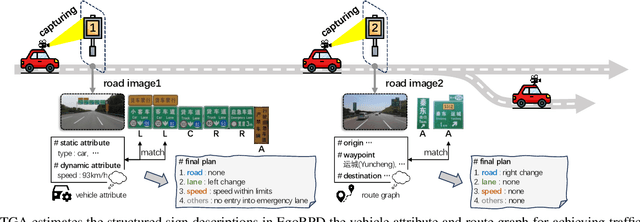

Traffic signs play a key role in assisting autonomous driving systems (ADS) by enabling the assessment of vehicle behavior in compliance with traffic regulations and providing navigation instructions. However, current works are limited to basic sign understanding without considering the egocentric vehicle's spatial position, which fails to support further regulation assessment and direction navigation. Following the above issues, we introduce a new task: traffic sign interpretation from the vehicle's first-person view, referred to as TSI-FPV. Meanwhile, we develop a traffic guidance assistant (TGA) scenario application to re-explore the role of traffic signs in ADS as a complement to popular autonomous technologies (such as obstacle perception). Notably, TGA is not a replacement for electronic map navigation; rather, TGA can be an automatic tool for updating it and complementing it in situations such as offline conditions or temporary sign adjustments. Lastly, a spatial and semantic logic-aware stepwise reasoning pipeline (SignEye) is constructed to achieve the TSI-FPV and TGA, and an application-specific dataset (Traffic-CN) is built. Experiments show that TSI-FPV and TGA are achievable via our SignEye trained on Traffic-CN. The results also demonstrate that the TGA can provide complementary information to ADS beyond existing popular autonomous technologies.
FengWu-W2S: A deep learning model for seamless weather-to-subseasonal forecast of global atmosphere
Nov 15, 2024Seamless forecasting that produces warning information at continuum timescales based on only one system is a long-standing pursuit for weather-climate service. While the rapid advancement of deep learning has induced revolutionary changes in classical forecasting field, current efforts are still focused on building separate AI models for weather and climate forecasts. To explore the seamless forecasting ability based on one AI model, we propose FengWu-Weather to Subseasonal (FengWu-W2S), which builds on the FengWu global weather forecast model and incorporates an ocean-atmosphere-land coupling structure along with a diverse perturbation strategy. FengWu-W2S can generate 6-hourly atmosphere forecasts extending up to 42 days through an autoregressive and seamless manner. Our hindcast results demonstrate that FengWu-W2S reliably predicts atmospheric conditions out to 3-6 weeks ahead, enhancing predictive capabilities for global surface air temperature, precipitation, geopotential height and intraseasonal signals such as the Madden-Julian Oscillation (MJO) and North Atlantic Oscillation (NAO). Moreover, our ablation experiments on forecast error growth from daily to seasonal timescales reveal potential pathways for developing AI-based integrated system for seamless weather-climate forecasting in the future.
WeatherFormer: Empowering Global Numerical Weather Forecasting with Space-Time Transformer
Sep 21, 2024Numerical Weather Prediction (NWP) system is an infrastructure that exerts considerable impacts on modern society.Traditional NWP system, however, resolves it by solving complex partial differential equations with a huge computing cluster, resulting in tons of carbon emission. Exploring efficient and eco-friendly solutions for NWP attracts interest from Artificial Intelligence (AI) and earth science communities. To narrow the performance gap between the AI-based methods and physic predictor, this work proposes a new transformer-based NWP framework, termed as WeatherFormer, to model the complex spatio-temporal atmosphere dynamics and empowering the capability of data-driven NWP. WeatherFormer innovatively introduces the space-time factorized transformer blocks to decrease the parameters and memory consumption, in which Position-aware Adaptive Fourier Neural Operator (PAFNO) is proposed for location sensible token mixing. Besides, two data augmentation strategies are utilized to boost the performance and decrease training consumption. Extensive experiments on WeatherBench dataset show WeatherFormer achieves superior performance over existing deep learning methods and further approaches the most advanced physical model.
DABench: A Benchmark Dataset for Data-Driven Weather Data Assimilation
Aug 21, 2024



Recent advancements in deep learning (DL) have led to the development of several Large Weather Models (LWMs) that rival state-of-the-art (SOTA) numerical weather prediction (NWP) systems. Up to now, these models still rely on traditional NWP-generated analysis fields as input and are far from being an autonomous system. While researchers are exploring data-driven data assimilation (DA) models to generate accurate initial fields for LWMs, the lack of a standard benchmark impedes the fair evaluation among different data-driven DA algorithms. Here, we introduce DABench, a benchmark dataset utilizing ERA5 data as ground truth to guide the development of end-to-end data-driven weather prediction systems. DABench contributes four standard features: (1) sparse and noisy simulated observations under the guidance of the observing system simulation experiment method; (2) a skillful pre-trained weather prediction model to generate background fields while fairly evaluating the impact of assimilation outcomes on predictions; (3) standardized evaluation metrics for model comparison; (4) a strong baseline called the DA Transformer (DaT). DaT integrates the four-dimensional variational DA prior knowledge into the Transformer model and outperforms the SOTA in physical state reconstruction, named 4DVarNet. Furthermore, we exemplify the development of an end-to-end data-driven weather prediction system by integrating DaT with the prediction model. Researchers can leverage DABench to develop their models and compare performance against established baselines, which will benefit the future advancements of data-driven weather prediction systems. The code is available on this Github repository and the dataset is available at the Baidu Drive.
Mixture of Experts based Multi-task Supervise Learning from Crowds
Jul 18, 2024



Existing truth inference methods in crowdsourcing aim to map redundant labels and items to the ground truth. They treat the ground truth as hidden variables and use statistical or deep learning-based worker behavior models to infer the ground truth. However, worker behavior models that rely on ground truth hidden variables overlook workers' behavior at the item feature level, leading to imprecise characterizations and negatively impacting the quality of truth inference. This paper proposes a new paradigm of multi-task supervised learning from crowds, which eliminates the need for modeling of items's ground truth in worker behavior models. Within this paradigm, we propose a worker behavior model at the item feature level called Mixture of Experts based Multi-task Supervised Learning from Crowds (MMLC). Two truth inference strategies are proposed within MMLC. The first strategy, named MMLC-owf, utilizes clustering methods in the worker spectral space to identify the projection vector of the oracle worker. Subsequently, the labels generated based on this vector are considered as the inferred truth. The second strategy, called MMLC-df, employs the MMLC model to fill the crowdsourced data, which can enhance the effectiveness of existing truth inference methods. Experimental results demonstrate that MMLC-owf outperforms state-of-the-art methods and MMLC-df enhances the quality of existing truth inference methods.
A Comprehensive Solution to Connect Speech Encoder and Large Language Model for ASR
Jun 25, 2024



Recent works have shown promising results in connecting speech encoders to large language models (LLMs) for speech recognition. However, several limitations persist, including limited fine-tuning options, a lack of mechanisms to enforce speech-text alignment, and high insertion errors especially in domain mismatch conditions. This paper presents a comprehensive solution to address these issues. We begin by investigating more thoughtful fine-tuning schemes. Next, we propose a matching loss to enhance alignment between modalities. Finally, we explore training and inference methods to mitigate high insertion errors. Experimental results on the Librispeech corpus demonstrate that partially fine-tuning the encoder and LLM using parameter-efficient methods, such as LoRA, is the most cost-effective approach. Additionally, the matching loss improves modality alignment, enhancing performance. The proposed training and inference methods significantly reduce insertion errors.
WEATHER-5K: A Large-scale Global Station Weather Dataset Towards Comprehensive Time-series Forecasting Benchmark
Jun 20, 2024



Global Station Weather Forecasting (GSWF) is crucial for various sectors, including aviation, agriculture, energy, and disaster preparedness. Recent advancements in deep learning have significantly improved the accuracy of weather predictions by optimizing models based on public meteorological data. However, existing public datasets for GSWF optimization and benchmarking still suffer from significant limitations, such as small sizes, limited temporal coverage, and a lack of comprehensive variables. These shortcomings prevent them from effectively reflecting the benchmarks of current forecasting methods and fail to support the real needs of operational weather forecasting. To address these challenges, we present the WEATHER-5K dataset. This dataset comprises a comprehensive collection of data from 5,672 weather stations worldwide, spanning a 10-year period with one-hour intervals. It includes multiple crucial weather elements, providing a more reliable and interpretable resource for forecasting. Furthermore, our WEATHER-5K dataset can serve as a benchmark for comprehensively evaluating existing well-known forecasting models, extending beyond GSWF methods to support future time-series research challenges and opportunities. The dataset and benchmark implementation are publicly available at: https://github.com/taohan10200/WEATHER-5K.
FNP: Fourier Neural Processes for Arbitrary-Resolution Data Assimilation
Jun 03, 2024Data assimilation is a vital component in modern global medium-range weather forecasting systems to obtain the best estimation of the atmospheric state by combining the short-term forecast and observations. Recently, AI-based data assimilation approaches have attracted increasing attention for their significant advantages over traditional techniques in terms of computational consumption. However, existing AI-based data assimilation methods can only handle observations with a specific resolution, lacking the compatibility and generalization ability to assimilate observations with other resolutions. Considering that complex real-world observations often have different resolutions, we propose the \textit{\textbf{Fourier Neural Processes}} (FNP) for \textit{arbitrary-resolution data assimilation} in this paper. Leveraging the efficiency of the designed modules and flexible structure of neural processes, FNP achieves state-of-the-art results in assimilating observations with varying resolutions, and also exhibits increasing advantages over the counterparts as the resolution and the amount of observations increase. Moreover, our FNP trained on a fixed resolution can directly handle the assimilation of observations with out-of-distribution resolutions and the observational information reconstruction task without additional fine-tuning, demonstrating its excellent generalization ability across data resolutions as well as across tasks.