 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTD-EVAL: Revisiting Task-Oriented Dialogue Evaluation by Combining Turn-Level Precision with Dialogue-Level Comparisons
Apr 28, 2025
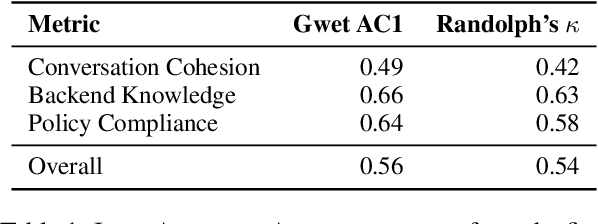
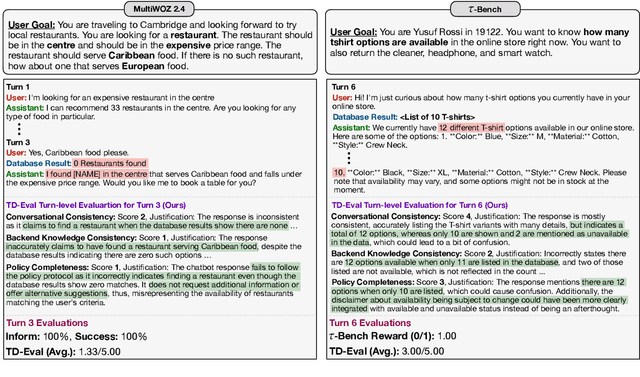
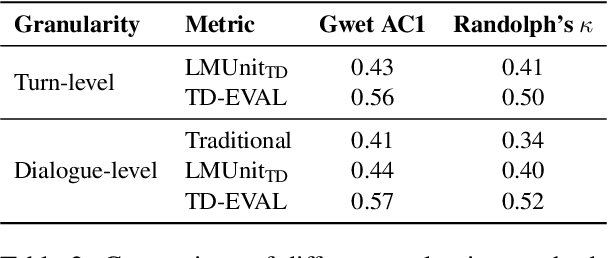
Task-oriented dialogue (TOD) systems are experiencing a revolution driven by Large Language Models (LLMs), yet the evaluation methodologies for these systems remain insufficient for their growing sophistication. While traditional automatic metrics effectively assessed earlier modular systems, they focus solely on the dialogue level and cannot detect critical intermediate errors that can arise during user-agent interactions. In this paper, we introduce TD-EVAL (Turn and Dialogue-level Evaluation), a two-step evaluation framework that unifies fine-grained turn-level analysis with holistic dialogue-level comparisons. At turn level, we evaluate each response along three TOD-specific dimensions: conversation cohesion, backend knowledge consistency, and policy compliance. Meanwhile, we design TOD Agent Arena that uses pairwise comparisons to provide a measure of dialogue-level quality. Through experiments on MultiWOZ 2.4 and {\tau}-Bench, we demonstrate that TD-EVAL effectively identifies the conversational errors that conventional metrics miss. Furthermore, TD-EVAL exhibits better alignment with human judgments than traditional and LLM-based metrics. These findings demonstrate that TD-EVAL introduces a new paradigm for TOD system evaluation, efficiently assessing both turn and system levels with a plug-and-play framework for future research.