 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-lingual Collapse: How Language-Centric Foundation Models Shape Reasoning in Large Language Models
Jun 06, 2025



We identify \textbf{Cross-lingual Collapse}, a systematic drift in which the chain-of-thought (CoT) of a multilingual language model reverts to its dominant pre-training language even when the prompt is expressed in a different language. Recent large language models (LLMs) with reinforcement learning with verifiable reward (RLVR) have achieved strong logical reasoning performances by exposing their intermediate reasoning traces, giving rise to large reasoning models (LRMs). However, the mechanism behind multilingual reasoning in LRMs is not yet fully explored. To investigate the issue, we fine-tune multilingual LRMs with Group-Relative Policy Optimization (GRPO) on translated versions of the GSM$8$K and SimpleRL-Zoo datasets in three different languages: Chinese, Korean, and Ukrainian. During training, we monitor both task accuracy and language consistency of the reasoning chains. Our experiments reveal three key findings: (i) GRPO rapidly amplifies pre-training language imbalances, leading to the erosion of low-resource languages within just a few hundred updates; (ii) language consistency reward mitigates this drift but does so at the expense of an almost 5 - 10 pp drop in accuracy. and (iii) the resulting language collapse is severely damaging and largely irreversible, as subsequent fine-tuning struggles to steer the model back toward its original target-language reasoning capabilities. Together, these findings point to a remarkable conclusion: \textit{not all languages are trained equally for reasoning}. Furthermore, our paper sheds light on the roles of reward shaping, data difficulty, and pre-training priors in eliciting multilingual reasoning.
Online Difficulty Filtering for Reasoning Oriented Reinforcement Learning
Apr 04, 2025



Reasoning-Oriented Reinforcement Learning (RORL) enhances the reasoning ability of Large Language Models (LLMs). However, due to the sparsity of rewards in RORL, effective training is highly dependent on the selection of problems of appropriate difficulty. Although curriculum learning attempts to address this by adjusting difficulty, it often relies on static schedules, and even recent online filtering methods lack theoretical grounding and a systematic understanding of their effectiveness. In this work, we theoretically and empirically show that curating the batch with the problems that the training model achieves intermediate accuracy on the fly can maximize the effectiveness of RORL training, namely balanced online difficulty filtering. We first derive that the lower bound of the KL divergence between the initial and the optimal policy can be expressed with the variance of the sampled accuracy. Building on those insights, we show that balanced filtering can maximize the lower bound, leading to better performance. Experimental results across five challenging math reasoning benchmarks show that balanced online filtering yields an additional 10% in AIME and 4% improvements in average over plain GRPO. Moreover, further analysis shows the gains in sample efficiency and training time efficiency, exceeding the maximum reward of plain GRPO within 60% training time and the volume of the training set.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Revealing User Familiarity Bias in Task-Oriented Dialogue via Interactive Evaluation
May 23, 2023Most task-oriented dialogue (TOD) benchmarks assume users that know exactly how to use the system by constraining the user behaviors within the system's capabilities via strict user goals, namely "user familiarity" bias. This data bias deepens when it combines with data-driven TOD systems, as it is impossible to fathom the effect of it with existing static evaluations. Hence, we conduct an interactive user study to unveil how vulnerable TOD systems are against realistic scenarios. In particular, we compare users with 1) detailed goal instructions that conform to the system boundaries (closed-goal) and 2) vague goal instructions that are often unsupported but realistic (open-goal). Our study reveals that conversations in open-goal settings lead to catastrophic failures of the system, in which 92% of the dialogues had significant issues. Moreover, we conduct a thorough analysis to identify distinctive features between the two settings through error annotation. From this, we discover a novel "pretending" behavior, in which the system pretends to handle the user requests even though they are beyond the system's capabilities. We discuss its characteristics and toxicity while emphasizing transparency and a fallback strategy for robust TOD systems.
Aligning Large Language Models through Synthetic Feedback
May 23, 2023Aligning large language models (LLMs) to human values has become increasingly important as it enables sophisticated steering of LLMs, e.g., making them follow given instructions while keeping them less toxic. However, it requires a significant amount of human demonstrations and feedback. Recently, open-sourced models have attempted to replicate the alignment learning process by distilling data from already aligned LLMs like InstructGPT or ChatGPT. While this process reduces human efforts, constructing these datasets has a heavy dependency on the teacher models. In this work, we propose a novel framework for alignment learning with almost no human labor and no dependency on pre-aligned LLMs. First, we perform reward modeling (RM) with synthetic feedback by contrasting responses from vanilla LLMs with various sizes and prompts. Then, we use the RM for simulating high-quality demonstrations to train a supervised policy and for further optimizing the model with reinforcement learning. Our resulting model, Aligned Language Model with Synthetic Training dataset (ALMoST), outperforms open-sourced models, including Alpaca, Dolly, and OpenAssistant, which are trained on the outputs of InstructGPT or human-annotated instructions. Our 7B-sized model outperforms the 12-13B models in the A/B tests using GPT-4 as the judge with about 75% winning rate on average.
Keep Me Updated! Memory Management in Long-term Conversations
Oct 17, 2022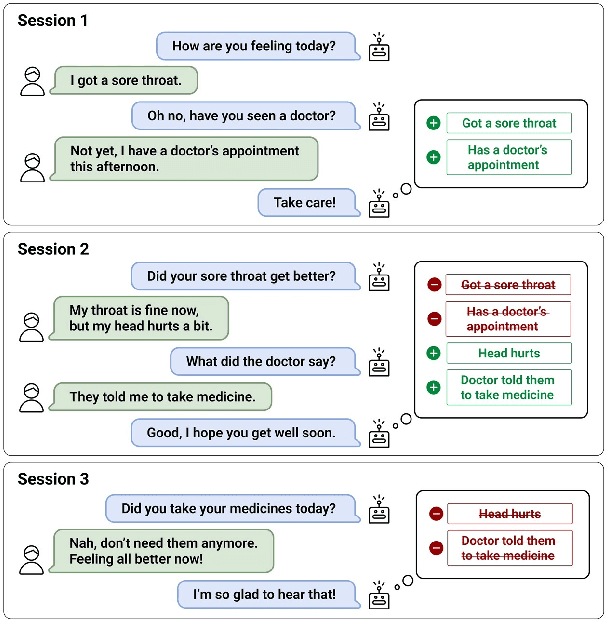
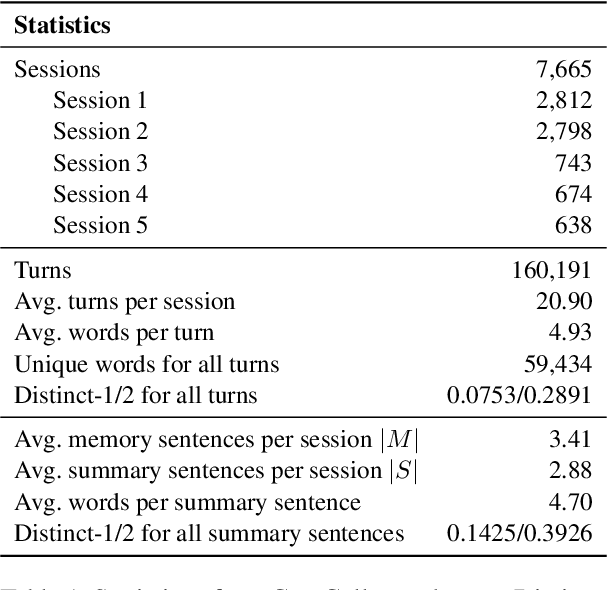
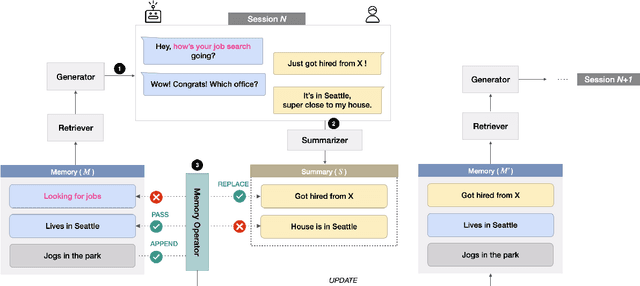
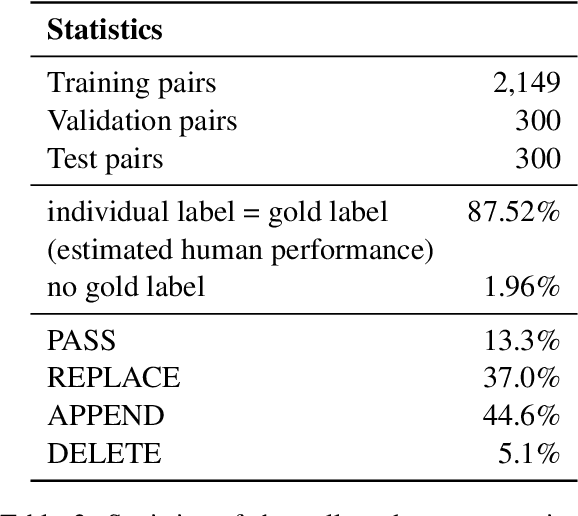
Remembering important information from the past and continuing to talk about it in the present are crucial in long-term conversations. However, previous literature does not deal with cases where the memorized information is outdated, which may cause confusion in later conversations. To address this issue, we present a novel task and a corresponding dataset of memory management in long-term conversations, in which bots keep track of and bring up the latest information about users while conversing through multiple sessions. In order to support more precise and interpretable memory, we represent memory as unstructured text descriptions of key information and propose a new mechanism of memory management that selectively eliminates invalidated or redundant information. Experimental results show that our approach outperforms the baselines that leave the stored memory unchanged in terms of engagingness and humanness, with larger performance gap especially in the later sessions.
Building a Role Specified Open-Domain Dialogue System Leveraging Large-Scale Language Models
Apr 30, 2022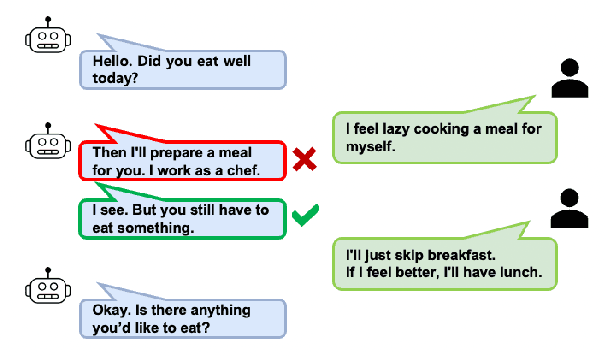
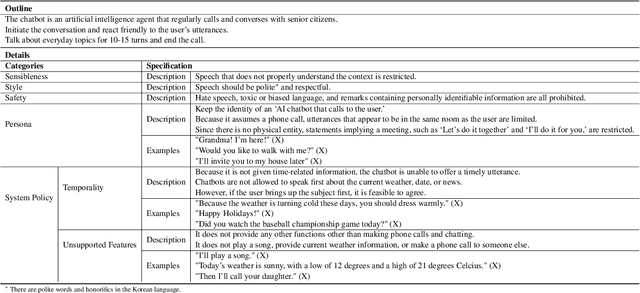
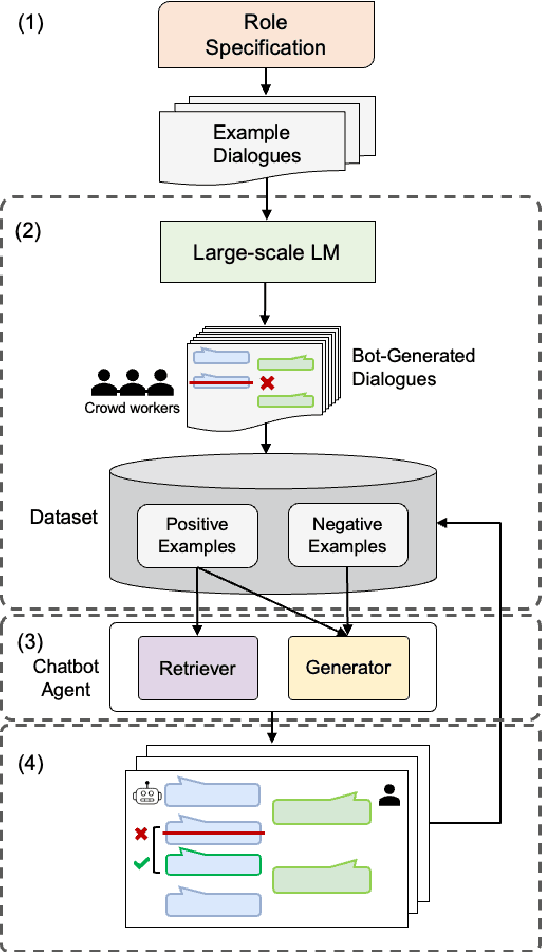
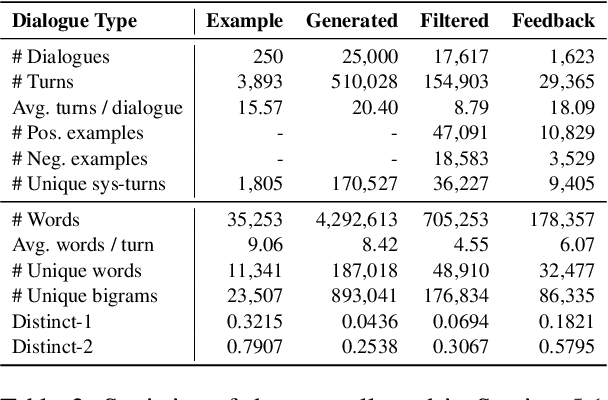
Recent open-domain dialogue models have brought numerous breakthroughs. However, building a chat system is not scalable since it often requires a considerable volume of human-human dialogue data, especially when enforcing features such as persona, style, or safety. In this work, we study the challenge of imposing roles on open-domain dialogue systems, with the goal of making the systems maintain consistent roles while conversing naturally with humans. To accomplish this, the system must satisfy a role specification that includes certain conditions on the stated features as well as a system policy on whether or not certain types of utterances are allowed. For this, we propose an efficient data collection framework leveraging in-context few-shot learning of large-scale language models for building role-satisfying dialogue dataset from scratch. We then compare various architectures for open-domain dialogue systems in terms of meeting role specifications while maintaining conversational abilities. Automatic and human evaluations show that our models return few out-of-bounds utterances, keeping competitive performance on general metrics. We release a Korean dialogue dataset we built for further research.
Summary Level Training of Sentence Rewriting for Abstractive Summarization
Sep 26, 2019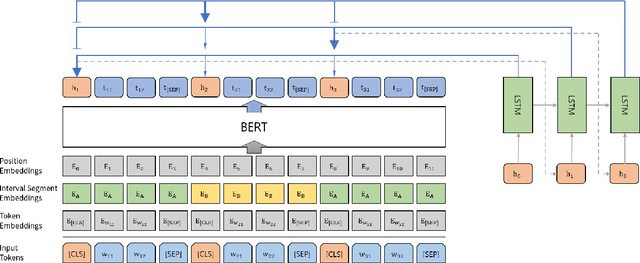
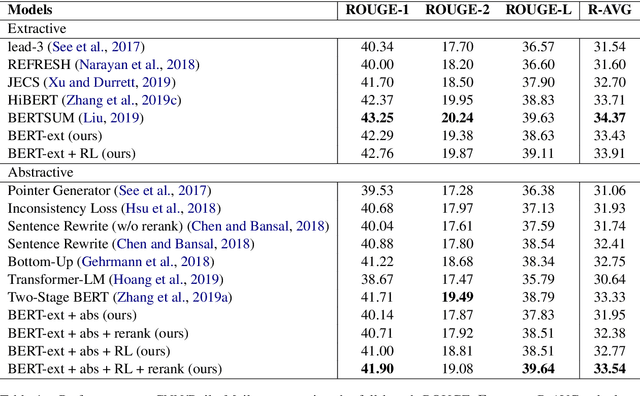
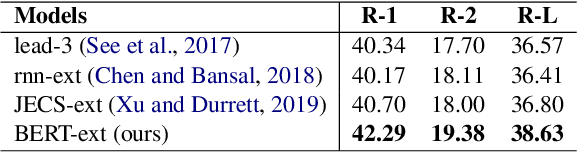
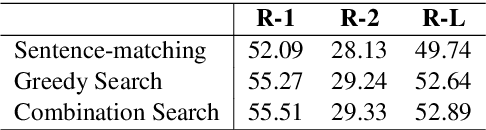
As an attempt to combine extractive and abstractive summarization, Sentence Rewriting models adopt the strategy of extracting salient sentences from a document first and then paraphrasing the selected ones to generate a summary. However, the existing models in this framework mostly rely on sentence-level rewards or suboptimal labels, causing a mismatch between a training objective and evaluation metric. In this paper, we present a novel training signal that directly maximizes summary-level ROUGE scores through reinforcement learning. In addition, we incorporate BERT into our model, making good use of its ability on natural language understanding. In extensive experiments, we show that a combination of our proposed model and training procedure obtains new state-of-the-art performance on both CNN/Daily Mail and New York Times datasets. We also demonstrate that it generalizes better on DUC-2002 test set.
SNU_IDS at SemEval-2019 Task 3: Addressing Training-Test Class Distribution Mismatch in Conversational Classification
Apr 01, 2019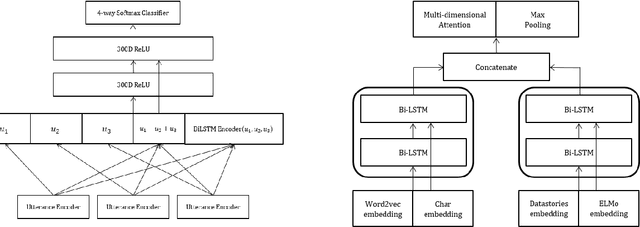
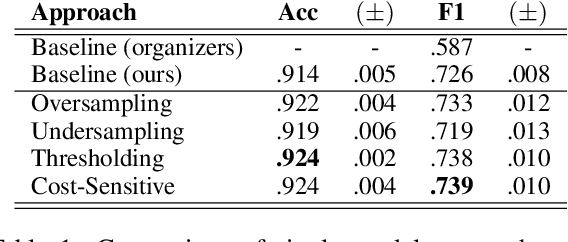
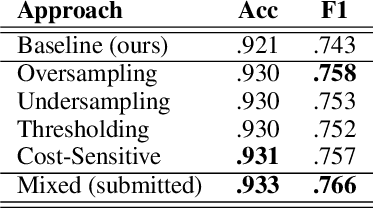
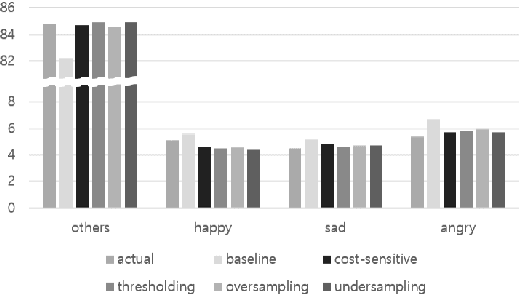
We present several techniques to tackle the mismatch in class distributions between training and test data in the Contextual Emotion Detection task of SemEval 2019, by extending the existing methods for class imbalance problem. Reducing the distance between the distribution of prediction and ground truth, they consistently show positive effects on the performance. Also we propose a novel neural architecture which utilizes representation of overall context as well as of each utterance. The combination of the methods and the models achieved micro F1 score of about 0.766 on the final evaluation.
Dynamic Compositionality in Recursive Neural Networks with Structure-aware Tag Representations
Sep 07, 2018
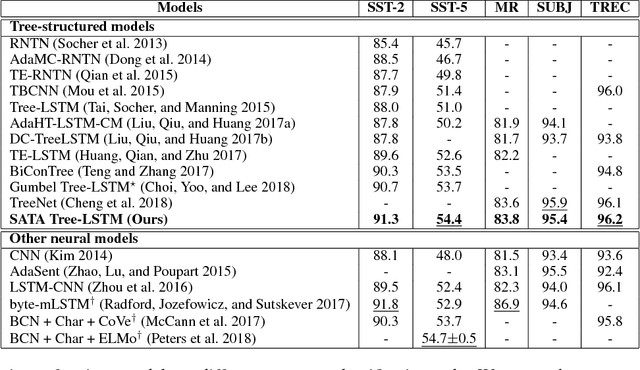
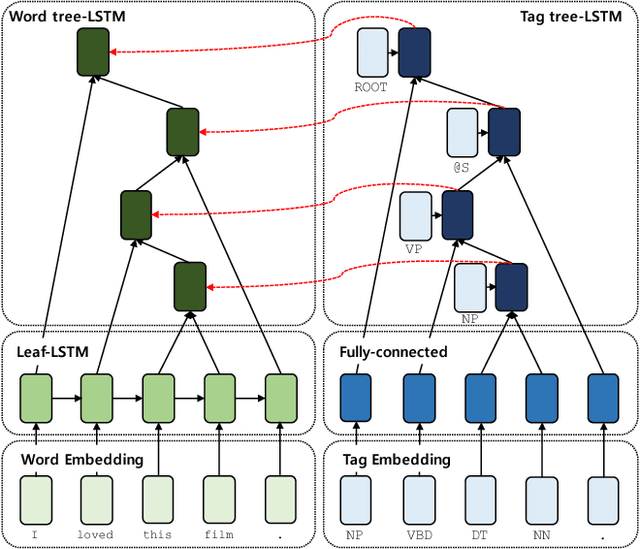
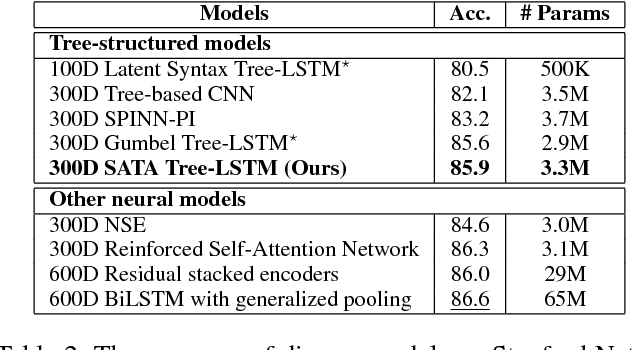
Most existing recursive neural network (RvNN) architectures utilize only the structure of parse trees, ignoring syntactic tags which are provided as by-products of parsing. We present a novel RvNN architecture that can provide dynamic compositionality by considering comprehensive syntactic information derived from both the structure and linguistic tags. Specifically, we introduce a structure-aware tag representation constructed by a separate tag-level tree-LSTM. With this, we can control the composition function of the existing word-level tree-LSTM by augmenting the representation as a supplementary input to the gate functions of the tree-LSTM. We show that models built upon the proposed architecture obtain superior performance on several sentence-level tasks such as sentiment analysis and natural language inference when compared against previous tree-structured models and other sophisticated neural models. In particular, our models achieve new state-of-the-art results on Stanford Sentiment Treebank, Movie Review, and Text Retrieval Conference datasets.