 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Global LLM Leaderboards Are Misleading: Small Portfolios for Heterogeneous Supervised ML
May 07, 2026Ranking LLMs via pairwise human feedback underpins current leaderboards for open-ended tasks, such as creative writing and problem-solving. We analyze ~89K comparisons in 116 languages from 52 LLMs from Arena, and show that the best-fit global Bradley-Terry (BT) ranking is misleading. Nearly 2/3 of the decisive votes cancel out, and even the top 50 models according to the global BT ranking are statistically indistinguishable (pairwise win probabilities are at most 0.53 within the top 50 models). We trace this failure to strong, structured heterogeneity of opinions across language, task, and time. Moreover, we find an important characteristic - *language* plays a key role. Grouping by language (and families) increases the agreement of votes massively, resulting in two orders of magnitude higher spread in the ELO scores (i.e., very consistent rankings). What appears as global noise is in fact a mixture of coherent but conflicting subpopulations. To address such heterogeneity in supervised machine learning, we introduce the framework of $(λ, ν)$-portfolios, which are small sets of models that achieve a prediction error at most $λ$, "covering" at least a $ν$ fraction of users. We formulate this as a variant of the set cover problem and provide guarantees using the VC dimension of the underlying set system. On the Arena data, our algorithms recover just 5 distinct BT rankings that cover over 96% of votes at a modest $λ$, compared to the 21% coverage by the global ranking. We also provide a portfolio of 6 LLMs that cover twice as many votes as the top-6 LLMs from a global ranking. We further construct portfolios for a classification problem on the COMPAS dataset using an ensemble of fairness-regularized classification models and show that these portfolios can be used to detect blind spots in the data, which might be of independent interest to policymakers.
Many Preferences, Few Policies: Towards Scalable Language Model Personalization
Apr 05, 2026The holy grail of LLM personalization is a single LLM for each user, perfectly aligned with that user's preferences. However, maintaining a separate LLM per user is impractical due to constraints on compute, memory, and system complexity. We address this challenge by developing a principled method for selecting a small portfolio of LLMs that captures representative behaviors across heterogeneous users. We model user preferences across multiple traits (e.g., safety, humor, brevity) through a multi-dimensional weight vector. Given reward functions across these dimensions, our algorithm PALM (Portfolio of Aligned LLMs) generates a small portfolio of LLMs such that, for any weight vector, the portfolio contains a near-optimal LLM for the corresponding scalarized objective. To the best of our knowledge, this is the first result that provides theoretical guarantees on both the size and approximation quality of LLM portfolios for personalization. It characterizes the trade-off between system cost and personalization, as well as the diversity of LLMs required to cover the landscape of user preferences. We provide empirical results that validate these guarantees and demonstrate greater output diversity over common baselines.
Improved Regret Guarantees for Online Mirror Descent using a Portfolio of Mirror Maps
Feb 13, 2026OMD and its variants give a flexible framework for OCO where the performance depends crucially on the choice of the mirror map. While the geometries underlying OPGD and OEG, both special cases of OMD, are well understood, it remains a challenging open question on how to construct an optimal mirror map for any given constrained set and a general family of loss functions, e.g., sparse losses. Motivated by parameterizing a near-optimal set of mirror maps, we consider a simpler question: is it even possible to obtain polynomial gains in regret by using mirror maps for geometries that interpolate between $L_1$ and $L_2$, which may not be possible by restricting to only OEG ($L_1$) or OPGD ($L_2$). Our main result answers this question positively. We show that mirror maps based on block norms adapt better to the sparsity of loss functions, compared to previous $L_p$ (for $p \in [1, 2]$) interpolations. In particular, we construct a family of online convex optimization instances in $\mathbb{R}^d$, where block norm-based mirror maps achieve a provable polynomial (in $d$) improvement in regret over OEG and OPGD for sparse loss functions. We then turn to the setting in which the sparsity level of the loss functions is unknown. In this case, the choice of geometry itself becomes an online decision problem. We first show that naively switching between OEG and OPGD can incur linear regret, highlighting the intrinsic difficulty of geometry selection. To overcome this issue, we propose a meta-algorithm based on multiplicative weights that dynamically selects among a family of uniform block norms. We show that this approach effectively tunes OMD to the sparsity of the losses, yielding adaptive regret guarantees. Overall, our results demonstrate that online mirror-map selection can significantly enhance the ability of OMD to exploit sparsity in online convex optimization.
Reusing Combinatorial Structure: Faster Iterative Projections over Submodular Base Polytopes
Jun 22, 2021
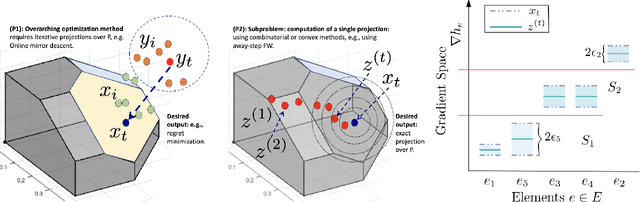

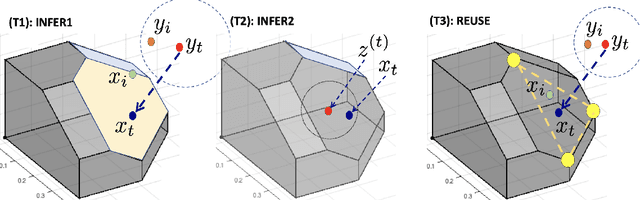
Optimization algorithms such as projected Newton's method, FISTA, mirror descent and its variants enjoy near-optimal regret bounds and convergence rates, but suffer from a computational bottleneck of computing "projections'' in potentially each iteration (e.g., $O(T^{1/2})$ regret of online mirror descent). On the other hand, conditional gradient variants solve a linear optimization in each iteration, but result in suboptimal rates (e.g., $O(T^{3/4})$ regret of online Frank-Wolfe). Motivated by this trade-off in runtime v/s convergence rates, we consider iterative projections of close-by points over widely-prevalent submodular base polytopes $B(f)$. We develop a toolkit to speed up the computation of projections using both discrete and continuous perspectives. We subsequently adapt the away-step Frank-Wolfe algorithm to use this information and enable early termination. For the special case of cardinality based submodular polytopes, we improve the runtime of computing certain Bregman projections by a factor of $\Omega(n/\log(n))$. Our theoretical results show orders of magnitude reduction in runtime in preliminary computational experiments.