 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Far Can Disaggregation Go? A Design-Space Exploration of Attention-FFN Disaggregation for Efficient MoE LLM Serving
May 27, 2026Modern large language model (LLM) inference has progressively disaggregated to keep pace with growing model sizes and tight TTFT and TPOT service-level objectives: from chunked-prefill aggregation, to prefill-decode (P/D) disaggregation, and most recently to operator-level Attention-FFN Disaggregation (AFD). This trend is especially important for mixture-of-experts (MoE) models, where memory-bound attention, compute-intensive expert FFNs, and MoE dispatch/combine communication create distinct resource demands. AFD further exposes this heterogeneity by placing attention and MoE-FFN execution on separate GPU groups. Each level of disaggregation deepens the scheduling design space across workload characteristics, resource allocation, and interconnect topology, raising the central question: when does each level actually pay off? We systematically characterize this trade-off for MoE inference across realistic workloads spanning input/output sequence lengths, prefix-KV reuse, and per-user latency constraints. Using chunked-prefill and P/D disaggregation as baselines, we study the benefits and limits of AFD at scale through a framework that fuses on-device kernel measurements with high-fidelity network simulation. Under strict TTFT/TPOT SLOs, AFD sustains around 4k tokens/s of system throughput on DeepSeek-V3.2 across chat, coding, and agentic-coding workloads, where non-AFD deployments are infeasible. We distill concrete takeaways for jointly optimizing throughput and interactivity, including how to partition attention and FFN across GPUs as a function of workload and model architecture, providing design principles for current rack- and cluster-scale deployments as well as future disaggregated AI infrastructure.
FRED: Flexible REduction-Distribution Interconnect and Communication Implementation for Wafer-Scale Distributed Training of DNN Models
Jun 28, 2024



Distributed Deep Neural Network (DNN) training is a technique to reduce the training overhead by distributing the training tasks into multiple accelerators, according to a parallelization strategy. However, high-performance compute and interconnects are needed for maximum speed-up and linear scaling of the system. Wafer-scale systems are a promising technology that allows for tightly integrating high-end accelerators with high-speed wafer-scale interconnects, making it an attractive platform for distributed training. However, the wafer-scale interconnect should offer high performance and flexibility for various parallelization strategies to enable maximum optimizations for compute and memory usage. In this paper, we propose FRED, a wafer-scale interconnect that is tailored for the high-BW requirements of wafer-scale networks and can efficiently execute communication patterns of different parallelization strategies. Furthermore, FRED supports in-switch collective communication execution that reduces the network traffic by approximately 2X. Our results show that FRED can improve the average end-to-end training time of ResNet-152, Transformer-17B, GPT-3, and Transformer-1T by 1.76X, 1.87X, 1.34X, and 1.4X, respectively when compared to a baseline waferscale 2D-Mesh fabric.
TACOS: Topology-Aware Collective Algorithm Synthesizer for Distributed Training
Apr 11, 2023



Collective communications are an indispensable part of distributed training. Running a topology-aware collective algorithm is crucial for optimizing communication performance by minimizing congestion. Today such algorithms only exist for a small set of simple topologies, limiting the topologies employed in training clusters and handling irregular topologies due to network failures. In this paper, we propose TACOS, an automated topology-aware collective synthesizer for arbitrary input network topologies. TACOS synthesized 3.73x faster All-Reduce algorithm over baselines, and synthesized collective algorithms for 512-NPU system in just 6.1 minutes.
ASTRA-sim2.0: Modeling Hierarchical Networks and Disaggregated Systems for Large-model Training at Scale
Mar 24, 2023As deep learning models and input data are scaling at an unprecedented rate, it is inevitable to move towards distributed training platforms to fit the model and increase training throughput. State-of-the-art approaches and techniques, such as wafer-scale nodes, multi-dimensional network topologies, disaggregated memory systems, and parallelization strategies, have been actively adopted by emerging distributed training systems. This results in a complex SW/HW co-design stack of distributed training, necessitating a modeling/simulation infrastructure for design-space exploration. In this paper, we extend the open-source ASTRA-sim infrastructure and endow it with the capabilities to model state-of-the-art and emerging distributed training models and platforms. More specifically, (i) we enable ASTRA-sim to support arbitrary model parallelization strategies via a graph-based training-loop implementation, (ii) we implement a parameterizable multi-dimensional heterogeneous topology generation infrastructure with analytical performance estimates enabling simulating target systems at scale, and (iii) we enhance the memory system modeling to support accurate modeling of in-network collective communication and disaggregated memory systems. With such capabilities, we run comprehensive case studies targeting emerging distributed models and platforms. This infrastructure lets system designers swiftly traverse the complex co-design stack and give meaningful insights when designing and deploying distributed training platforms at scale.
Themis: A Network Bandwidth-Aware Collective Scheduling Policy for Distributed Training of DL Models
Oct 09, 2021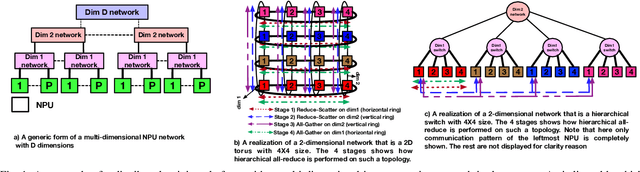



The continuous growth in both size and training data for modern Deep Neural Networks (DNNs) models has led to training tasks taking days or even months. Distributed training is a solution to reduce training time by splitting the task across multiple NPUs (e.g., GPU/TPU). However, distributed training adds communication overhead between the NPUs in order to synchronize the gradients and/or activation, depending on the parallelization strategy. In today's datacenters, for training at scale, NPUs are connected through multi-dimensional interconnection links with different bandwidth and latency. Hence, keeping all network dimensions busy and maximizing the network BW is a challenging task in such a hybrid network environment, as this work identifies. We propose Themis, a novel collective scheduling scheme that dynamically schedules collectives (divided into chunks) to balance the communication loads across all dimensions, further improving the network BW utilization. Our results show that on average, Themis can improve the network BW utilization of single All-Reduce by 1.88x (2.92x max), and improve the end-to-end training iteration performance of real workloads such as ResNet-50, GNMT, DLRM, and Transformer- 1T by 1.49x (1.96x max), 1.41x (1.81x max), 1.42x (1.80x max), and 1.35x (1.78x max), respectively.
Exploring Multi-dimensional Hierarchical Network Topologies for Efficient Distributed Training of Trillion Parameter DL Models
Sep 24, 2021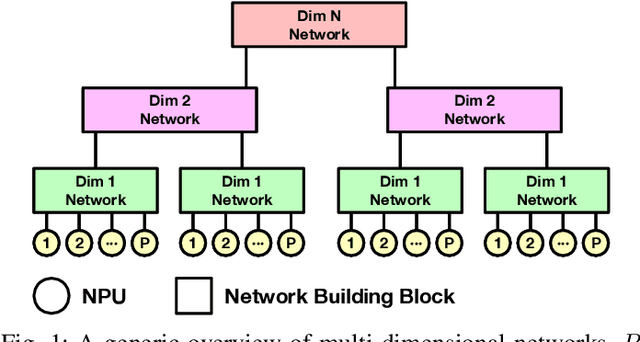
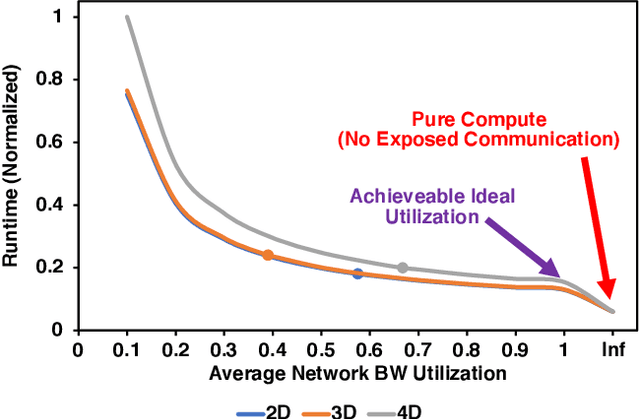
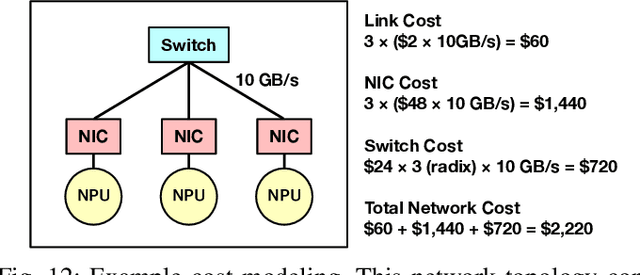
Deep Neural Networks have gained significant attraction due to their wide applicability in different domains. DNN sizes and training samples are constantly growing, making training of such workloads more challenging. Distributed training is a solution to reduce the training time. High-performance distributed training platforms should leverage multi-dimensional hierarchical networks, which interconnect accelerators through different levels of the network, to dramatically reduce expensive NICs required for the scale-out network. However, it comes at the expense of communication overhead between distributed accelerators to exchange gradients or input/output activation. In order to allow for further scaling of the workloads, communication overhead needs to be minimized. In this paper, we motivate the fact that in training platforms, adding more intermediate network dimensions is beneficial for efficiently mitigating the excessive use of expensive NIC resources. Further, we address different challenges of the DNN training on hierarchical networks. We discuss when designing the interconnect, how to distribute network bandwidth resources across different dimensions in order to (i) maximize BW utilization of all dimensions, and (ii) minimizing the overall training time for the target workload. We then implement a framework that, for a given workload, determines the best network configuration that maximizes performance, or performance-per-cost.