 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTightly-Coupled Radar-Visual-Inertial Odometry
Mar 24, 2026Visual-Inertial Odometry (VIO) is a staple for reliable state estimation on constrained and lightweight platforms due to its versatility and demonstrated performance. However, pertinent challenges regarding robust operation in dark, low-texture, obscured environments complicate the use of such methods. Alternatively, Frequency Modulated Continuous Wave (FMCW) radars, and by extension Radar-Inertial Odometry (RIO), offer robustness to these visual challenges, albeit at the cost of reduced information density and worse long-term accuracy. To address these limitations, this work combines the two in a tightly coupled manner, enabling the resulting method to operate robustly regardless of environmental conditions or trajectory dynamics. The proposed method fuses image features, radar Doppler measurements, and Inertial Measurement Unit (IMU) measurements within an Iterated Extended Kalman Filter (IEKF) in real-time, with radar range data augmenting the visual feature depth initialization. The method is evaluated through flight experiments conducted in both indoor and outdoor environments, as well as through challenges to both exteroceptive modalities (such as darkness, fog, or fast flight), thoroughly demonstrating its robustness. The implementation of the proposed method is available at: https://github.com/ntnu-arl/radvio.
OmniPlanner: Universal Exploration and Inspection Path Planning across Robot Morphologies
Mar 04, 2026Autonomous robotic systems are increasingly deployed for mapping, monitoring, and inspection in complex and unstructured environments. However, most existing path planning approaches remain domain-specific (i.e., either on air, land, or sea), limiting their scalability and cross-platform applicability. This article presents OmniPlanner, a unified planning framework for autonomous exploration and inspection across aerial, ground, and underwater robots. The method integrates volumetric exploration and viewpoint-based inspection, alongside target reach behaviors within a single modular architecture, complemented by a platform abstraction layer that captures morphology-specific sensing, traversability and motion constraints. This enables the same planning strategy to generalize across distinct mobility domains with minimal retuning. The framework is validated through extensive simulation studies and field deployments in underground mines, industrial facilities, forests, submarine bunkers, and structured outdoor environments. Across these diverse scenarios, OmniPlanner demonstrates robust performance, consistent cross-domain generalization, and improved exploration and inspection efficiency compared to representative state-of-the-art baselines.
Improved Regret Guarantees for Online Mirror Descent using a Portfolio of Mirror Maps
Feb 13, 2026OMD and its variants give a flexible framework for OCO where the performance depends crucially on the choice of the mirror map. While the geometries underlying OPGD and OEG, both special cases of OMD, are well understood, it remains a challenging open question on how to construct an optimal mirror map for any given constrained set and a general family of loss functions, e.g., sparse losses. Motivated by parameterizing a near-optimal set of mirror maps, we consider a simpler question: is it even possible to obtain polynomial gains in regret by using mirror maps for geometries that interpolate between $L_1$ and $L_2$, which may not be possible by restricting to only OEG ($L_1$) or OPGD ($L_2$). Our main result answers this question positively. We show that mirror maps based on block norms adapt better to the sparsity of loss functions, compared to previous $L_p$ (for $p \in [1, 2]$) interpolations. In particular, we construct a family of online convex optimization instances in $\mathbb{R}^d$, where block norm-based mirror maps achieve a provable polynomial (in $d$) improvement in regret over OEG and OPGD for sparse loss functions. We then turn to the setting in which the sparsity level of the loss functions is unknown. In this case, the choice of geometry itself becomes an online decision problem. We first show that naively switching between OEG and OPGD can incur linear regret, highlighting the intrinsic difficulty of geometry selection. To overcome this issue, we propose a meta-algorithm based on multiplicative weights that dynamically selects among a family of uniform block norms. We show that this approach effectively tunes OMD to the sparsity of the losses, yielding adaptive regret guarantees. Overall, our results demonstrate that online mirror-map selection can significantly enhance the ability of OMD to exploit sparsity in online convex optimization.
DeepVL: Dynamics and Inertial Measurements-based Deep Velocity Learning for Underwater Odometry
Feb 11, 2025This paper presents a learned model to predict the robot-centric velocity of an underwater robot through dynamics-aware proprioception. The method exploits a recurrent neural network using as inputs inertial cues, motor commands, and battery voltage readings alongside the hidden state of the previous time-step to output robust velocity estimates and their associated uncertainty. An ensemble of networks is utilized to enhance the velocity and uncertainty predictions. Fusing the network's outputs into an Extended Kalman Filter, alongside inertial predictions and barometer updates, the method enables long-term underwater odometry without further exteroception. Furthermore, when integrated into visual-inertial odometry, the method assists in enhanced estimation resilience when dealing with an order of magnitude fewer total features tracked (as few as 1) as compared to conventional visual-inertial systems. Tested onboard an underwater robot deployed both in a laboratory pool and the Trondheim Fjord, the method takes less than 5ms for inference either on the CPU or the GPU of an NVIDIA Orin AGX and demonstrates less than 4% relative position error in novel trajectories during complete visual blackout, and approximately 2% relative error when a maximum of 2 visual features from a monocular camera are available.
Online Refractive Camera Model Calibration in Visual Inertial Odometry
Sep 18, 2024This paper presents a general refractive camera model and online co-estimation of odometry and the refractive index of unknown media. This enables operation in diverse and varying refractive fluids, given only the camera calibration in air. The refractive index is estimated online as a state variable of a monocular visual-inertial odometry framework in an iterative formulation using the proposed camera model. The method was verified on data collected using an underwater robot traversing inside a pool. The evaluations demonstrate convergence to the ideal refractive index for water despite significant perturbations in the initialization. Simultaneously, the approach enables on-par visual-inertial odometry performance in refractive media without prior knowledge of the refractive index or requirement of medium-specific camera calibration.
An Online Self-calibrating Refractive Camera Model with Application to Underwater Odometry
Oct 25, 2023This work presents a camera model for refractive media such as water and its application in underwater visual-inertial odometry. The model is self-calibrating in real-time and is free of known correspondences or calibration targets. It is separable as a distortion model (dependent on refractive index $n$ and radial pixel coordinate) and a virtual pinhole model (as a function of $n$). We derive the self-calibration formulation leveraging epipolar constraints to estimate the refractive index and subsequently correct for distortion. Through experimental studies using an underwater robot integrating cameras and inertial sensing, the model is validated regarding the accurate estimation of the refractive index and its benefits for robust odometry estimation in an extended envelope of conditions. Lastly, we show the transition between media and the estimation of the varying refractive index online, thus allowing computer vision tasks across refractive media.
Constant-Factor Approximation Algorithms for Socially Fair $k$-Clustering
Jun 22, 2022
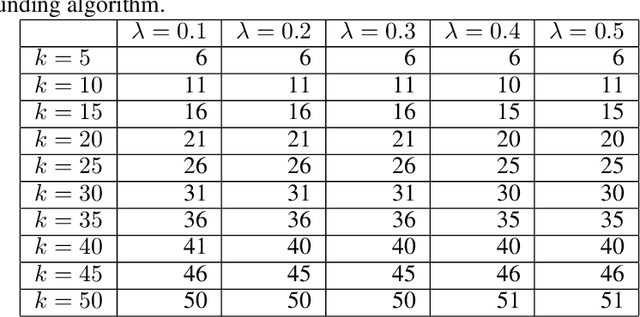
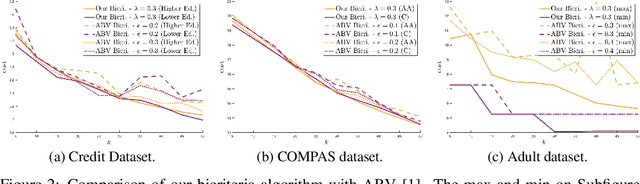
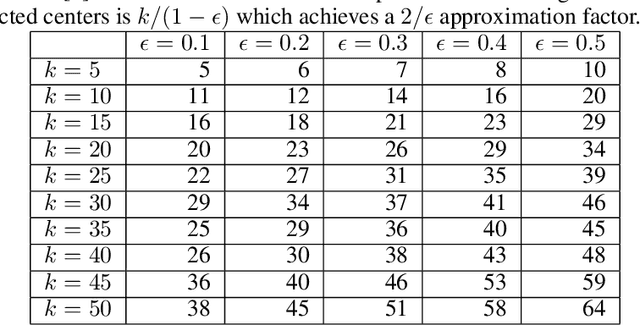
We study approximation algorithms for the socially fair $(\ell_p, k)$-clustering problem with $m$ groups, whose special cases include the socially fair $k$-median ($p=1$) and socially fair $k$-means ($p=2$) problems. We present (1) a polynomial-time $(5+2\sqrt{6})^p$-approximation with at most $k+m$ centers (2) a $(5+2\sqrt{6}+\epsilon)^p$-approximation with $k$ centers in time $n^{2^{O(p)}\cdot m^2}$, and (3) a $(15+6\sqrt{6})^p$ approximation with $k$ centers in time $k^{m}\cdot\text{poly}(n)$. The first result is obtained via a refinement of the iterative rounding method using a sequence of linear programs. The latter two results are obtained by converting a solution with up to $k+m$ centers to one with $k$ centers using sparsification methods for (2) and via an exhaustive search for (3). We also compare the performance of our algorithms with existing bicriteria algorithms as well as exactly $k$ center approximation algorithms on benchmark datasets, and find that our algorithms also outperform existing methods in practice.
Maximizing Determinants under Matroid Constraints
Apr 16, 2020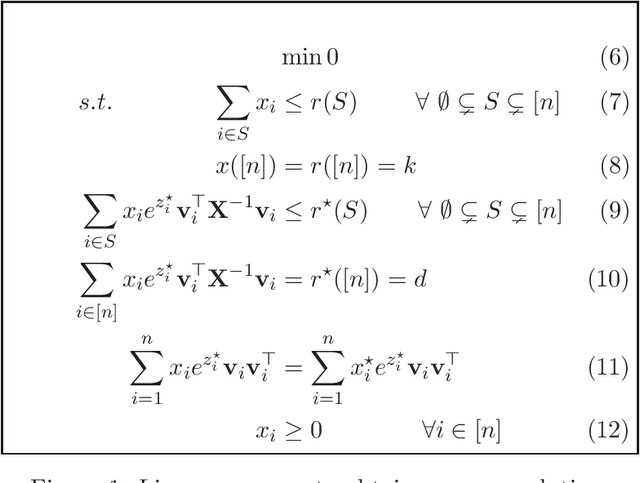
Given vectors $v_1,\dots,v_n\in\mathbb{R}^d$ and a matroid $M=([n],I)$, we study the problem of finding a basis $S$ of $M$ such that $\det(\sum_{i \in S}v_i v_i^\top)$ is maximized. This problem appears in a diverse set of areas such as experimental design, fair allocation of goods, network design, and machine learning. The current best results include an $e^{2k}$-estimation for any matroid of rank $k$ and a $(1+\epsilon)^d$-approximation for a uniform matroid of rank $k\ge d+\frac d\epsilon$, where the rank $k\ge d$ denotes the desired size of the optimal set. Our main result is a new approximation algorithm with an approximation guarantee that depends only on the dimension $d$ of the vectors and not on the size $k$ of the output set. In particular, we show an $(O(d))^{d}$-estimation and an $(O(d))^{d^3}$-approximation for any matroid, giving a significant improvement over prior work when $k\gg d$. Our result relies on the existence of an optimal solution to a convex programming relaxation for the problem which has sparse support; in particular, no more than $O(d^2)$ variables of the solution have fractional values. The sparsity results rely on the interplay between the first-order optimality conditions for the convex program and matroid theory. We believe that the techniques introduced to show sparsity of optimal solutions to convex programs will be of independent interest. We also give a randomized algorithm that rounds a sparse fractional solution to a feasible integral solution to the original problem. To show the approximation guarantee, we utilize recent works on strongly log-concave polynomials and show new relationships between different convex programs studied for the problem. Finally, we use the estimation algorithm and sparsity results to give an efficient deterministic approximation algorithm with an approximation guarantee that depends solely on the dimension $d$.
Fair Dimensionality Reduction and Iterative Rounding for SDPs
Feb 28, 2019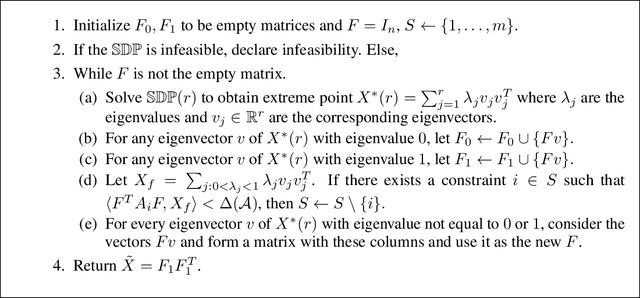
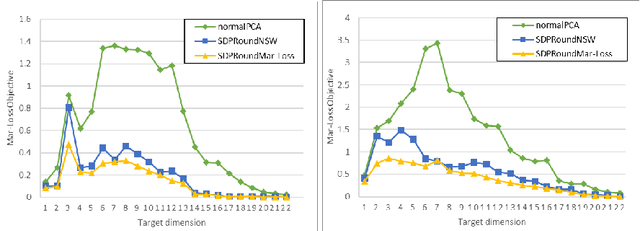
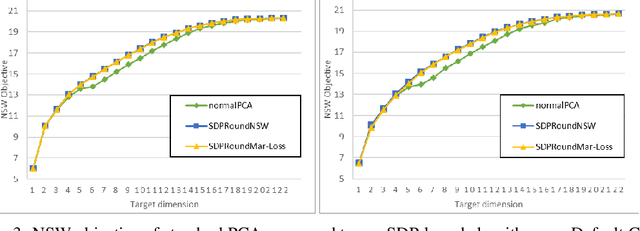
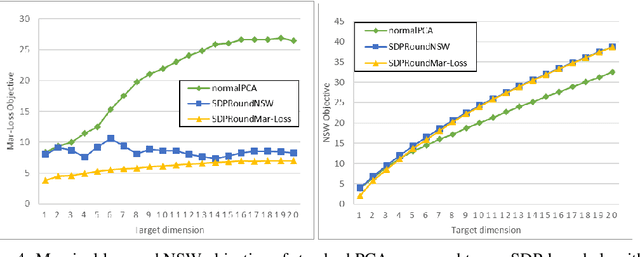
We model "fair" dimensionality reduction as an optimization problem. A central example is the fair PCA problem: the input data is divided into $k$ groups, and the goal is to find a single $d$-dimensional representation for all groups for which the maximum variance (or minimum reconstruction error) is optimized for all groups in a fair (or balanced) manner, e.g., by maximizing the minimum variance over the $k$ groups of the projection to a $d$-dimensional subspace. This problem was introduced by Samadi et al. (2018) who gave a polynomial-time algorithm which, for $k=2$ groups, returns a $(d+1)$-dimensional solution of value at least the best $d$-dimensional solution. We give an exact polynomial-time algorithm for $k=2$ groups. The result relies on extending results of Pataki (1998) regarding rank of extreme point solutions to semi-definite programs. This approach applies more generally to any monotone concave function of the individual group objectives. For $k>2$ groups, our results generalize to give a $(d+\sqrt{2k+0.25}-1.5)$-dimensional solution with objective value as good as the optimal $d$-dimensional solution for arbitrary $k,d$ in polynomial time. Using our extreme point characterization result for SDPs, we give an iterative rounding framework for general SDPs which generalizes the well-known iterative rounding approach for LPs. It returns low-rank solutions with bounded violation of constraints. We obtain a $d$-dimensional projection where the violation in the objective can be bounded additively in terms of the top $O(\sqrt{k})$-singular values of the data matrices. We also give an exact polynomial-time algorithm for any fixed number of groups and target dimension via the algorithm of Grigoriev and Pasechnik (2005). In contrast, when the number of groups is part of the input, even for target dimension $d=1$, we show this problem is NP-hard.
The Price of Fair PCA: One Extra Dimension
Oct 31, 2018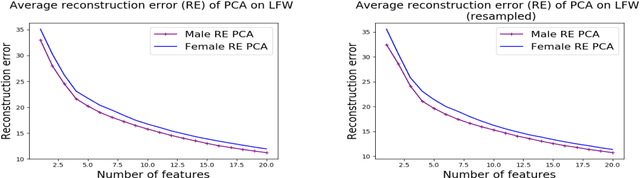
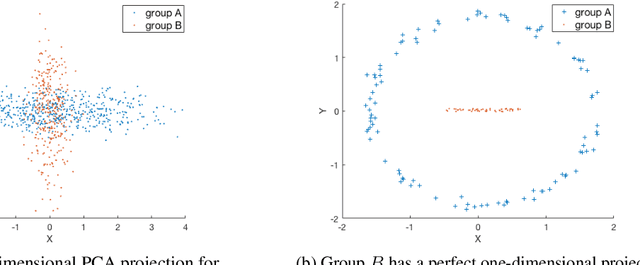
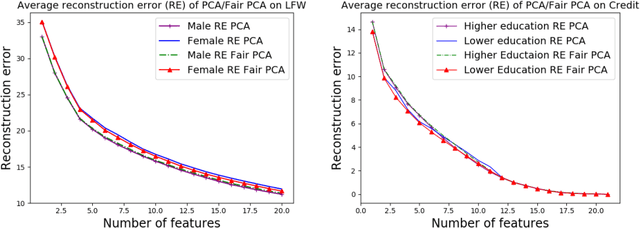
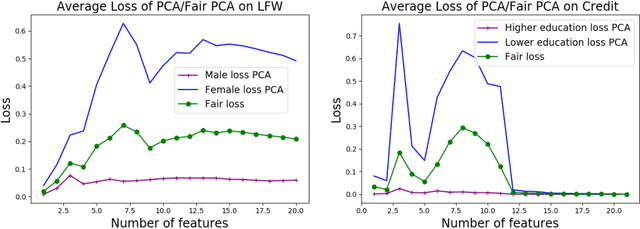
We investigate whether the standard dimensionality reduction technique of PCA inadvertently produces data representations with different fidelity for two different populations. We show on several real-world data sets, PCA has higher reconstruction error on population A than on B (for example, women versus men or lower- versus higher-educated individuals). This can happen even when the data set has a similar number of samples from A and B. This motivates our study of dimensionality reduction techniques which maintain similar fidelity for A and B. We define the notion of Fair PCA and give a polynomial-time algorithm for finding a low dimensional representation of the data which is nearly-optimal with respect to this measure. Finally, we show on real-world data sets that our algorithm can be used to efficiently generate a fair low dimensional representation of the data.