 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Synthetic Doctor-Patient Conversations for Long-form Audio Summarization
Apr 07, 2026Long-context audio reasoning is underserved in both training data and evaluation. Existing benchmarks target short-context tasks, and the open-ended generation tasks most relevant to long-context reasoning pose well-known challenges for automatic evaluation. We propose a synthetic data generation pipeline designed to serve both as a training resource and as a controlled evaluation environment, and instantiate it for first-visit doctor-patient conversations with SOAP note generation as the task. The pipeline has three stages, persona-driven dialogue generation, multi-speaker audio synthesis with overlap/pause modeling, room acoustics, and sound events, and LLM-based reference SOAP note production, built entirely on open-weight models. We release 8,800 synthetic conversations with 1.3k hours of corresponding audio and reference notes. Evaluating current open-weight systems, we find that cascaded approaches still substantially outperform end-to-end models.
Many Preferences, Few Policies: Towards Scalable Language Model Personalization
Apr 05, 2026The holy grail of LLM personalization is a single LLM for each user, perfectly aligned with that user's preferences. However, maintaining a separate LLM per user is impractical due to constraints on compute, memory, and system complexity. We address this challenge by developing a principled method for selecting a small portfolio of LLMs that captures representative behaviors across heterogeneous users. We model user preferences across multiple traits (e.g., safety, humor, brevity) through a multi-dimensional weight vector. Given reward functions across these dimensions, our algorithm PALM (Portfolio of Aligned LLMs) generates a small portfolio of LLMs such that, for any weight vector, the portfolio contains a near-optimal LLM for the corresponding scalarized objective. To the best of our knowledge, this is the first result that provides theoretical guarantees on both the size and approximation quality of LLM portfolios for personalization. It characterizes the trade-off between system cost and personalization, as well as the diversity of LLMs required to cover the landscape of user preferences. We provide empirical results that validate these guarantees and demonstrate greater output diversity over common baselines.
Optimizing Resource-Constrained Non-Pharmaceutical Interventions for Multi-Cluster Outbreak Control Using Hierarchical Reinforcement Learning
Mar 19, 2026Non-pharmaceutical interventions (NPIs), such as diagnostic testing and quarantine, are crucial for controlling infectious disease outbreaks but are often constrained by limited resources, particularly in early outbreak stages. In real-world public health settings, resources must be allocated across multiple outbreak clusters that emerge asynchronously, vary in size and risk, and compete for a shared resource budget. Here, a cluster corresponds to a group of close contacts generated by a single infected index case. Thus, decisions must be made under uncertainty and heterogeneous demands, while respecting operational constraints. We formulate this problem as a constrained restless multi-armed bandit and propose a hierarchical reinforcement learning framework. A global controller learns a continuous action cost multiplier that adjusts global resource demand, while a generalized local policy estimates the marginal value of allocating resources to individuals within each cluster. We evaluate the proposed framework in a realistic agent-based simulator of SARS-CoV-2 with dynamically arriving clusters. Across a wide range of system scales and testing budgets, our method consistently outperforms RMAB-inspired and heuristic baselines, improving outbreak control effectiveness by 20%-30%. Experiments on up to 40 concurrently active clusters further demonstrate that the hierarchical framework is highly scalable and enables faster decision-making than the RMAB-inspired method.
Beyond Length: Context-Aware Expansion and Independence as Developmentally Sensitive Evaluation in Child Utterances
Feb 05, 2026Evaluating the quality of children's utterances in adult-child dialogue remains challenging due to insufficient context-sensitive metrics. Common proxies such as Mean Length of Utterance (MLU), lexical diversity (vocd-D), and readability indices (Flesch-Kincaid Grade Level, Gunning Fog Index) are dominated by length and ignore conversational context, missing aspects of response quality such as reasoning depth, topic maintenance, and discourse planning. We introduce an LLM-as-a-judge framework that first classifies the Previous Adult Utterance Type and then scores the child's response along two axes: Expansion (contextual elaboration and inferential depth) and Independence (the child's contribution to advancing the discourse). These axes reflect fundamental dimensions in child language development, where Expansion captures elaboration, clause combining, and causal and contrastive connectives. Independence captures initiative, topic control, decreasing reliance on adult scaffolding through growing self-regulation, and audience design. We establish developmental validity by showing age-related patterns and demonstrate predictive value by improving age estimation over common baselines. We further confirm semantic sensitivity by detecting differences tied to discourse relations. Our metrics align with human judgments, enabling large-scale evaluation. This shifts child utterance assessment from simply measuring length to evaluating how meaningfully the child's speech contributes to and advances the conversation within its context.
Learning Provably Correct Distributed Protocols Without Human Knowledge
Jan 29, 2026Provably correct distributed protocols, which are a critical component of modern distributed systems, are highly challenging to design and have often required decades of human effort. These protocols allow multiple agents to coordinate to come to a common agreement in an environment with uncertainty and failures. We formulate protocol design as a search problem over strategies in a game with imperfect information, and the desired correctness conditions are specified in Satisfiability Modulo Theories (SMT). However, standard methods for solving multi-agent games fail to learn correct protocols in this setting, even when the number of agents is small. We propose a learning framework, GGMS, which integrates a specialized variant of Monte Carlo Tree Search with a transformer-based action encoder, a global depth-first search to break out of local minima, and repeated feedback from a model checker. Protocols output by GGMS are verified correct via exhaustive model checking for all executions within the bounded setting. We further prove that, under mild assumptions, the search process is complete: if a correct protocol exists, GGMS will eventually find it. In experiments, we show that GGMS can learn correct protocols for larger settings than existing methods.
VISTA Score: Verification In Sequential Turn-based Assessment
Oct 30, 2025Hallucination--defined here as generating statements unsupported or contradicted by available evidence or conversational context--remains a major obstacle to deploying conversational AI systems in settings that demand factual reliability. Existing metrics either evaluate isolated responses or treat unverifiable content as errors, limiting their use for multi-turn dialogue. We introduce VISTA (Verification In Sequential Turn-based Assessment), a framework for evaluating conversational factuality through claim-level verification and sequential consistency tracking. VISTA decomposes each assistant turn into atomic factual claims, verifies them against trusted sources and dialogue history, and categorizes unverifiable statements (subjective, contradicted, lacking evidence, or abstaining). Across eight large language models and four dialogue factuality benchmarks (AIS, BEGIN, FAITHDIAL, and FADE), VISTA substantially improves hallucination detection over FACTSCORE and LLM-as-Judge baselines. Human evaluation confirms that VISTA's decomposition improves annotator agreement and reveals inconsistencies in existing benchmarks. By modeling factuality as a dynamic property of conversation, VISTA offers a more transparent, human-aligned measure of truthfulness in dialogue systems.
Cultivating Archipelago of Forests: Evolving Robust Decision Trees through Island Coevolution
Dec 18, 2024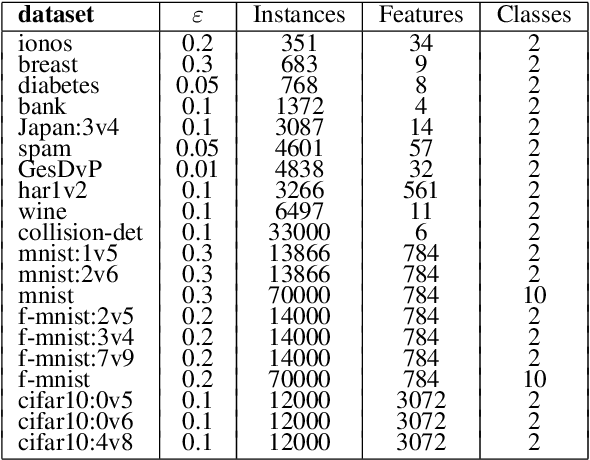
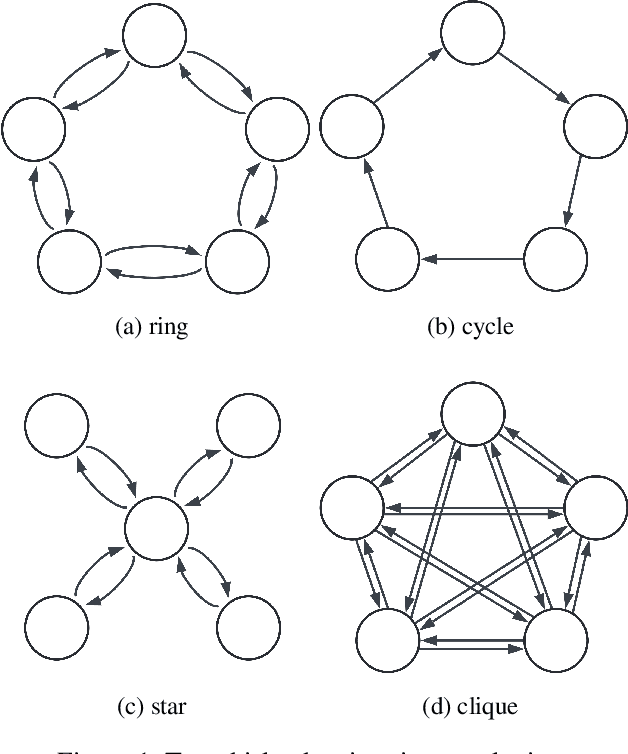
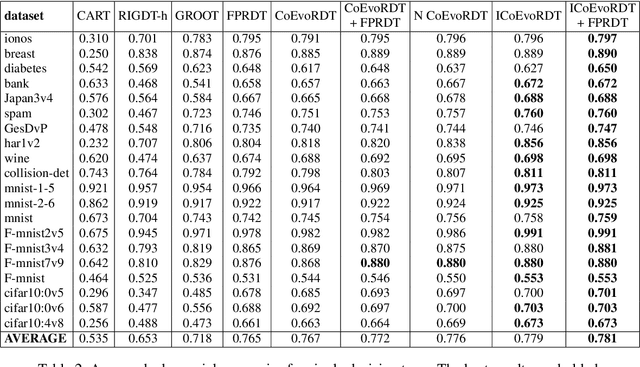
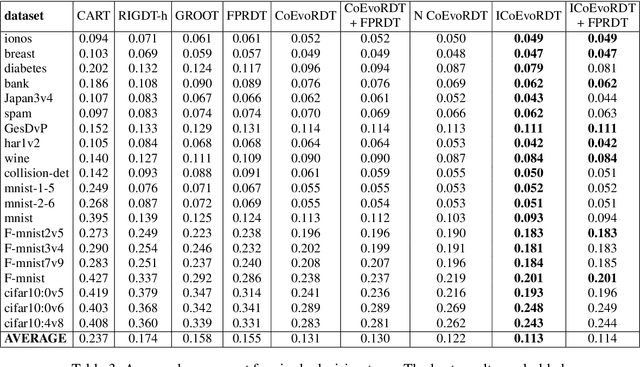
Decision trees are widely used in machine learning due to their simplicity and interpretability, but they often lack robustness to adversarial attacks and data perturbations. The paper proposes a novel island-based coevolutionary algorithm (ICoEvoRDF) for constructing robust decision tree ensembles. The algorithm operates on multiple islands, each containing populations of decision trees and adversarial perturbations. The populations on each island evolve independently, with periodic migration of top-performing decision trees between islands. This approach fosters diversity and enhances the exploration of the solution space, leading to more robust and accurate decision tree ensembles. ICoEvoRDF utilizes a popular game theory concept of mixed Nash equilibrium for ensemble weighting, which further leads to improvement in results. ICoEvoRDF is evaluated on 20 benchmark datasets, demonstrating its superior performance compared to state-of-the-art methods in optimizing both adversarial accuracy and minimax regret. The flexibility of ICoEvoRDF allows for the integration of decision trees from various existing methods, providing a unified framework for combining diverse solutions. Our approach offers a promising direction for developing robust and interpretable machine learning models
Using RLHF to align speech enhancement approaches to mean-opinion quality scores
Oct 17, 2024



Objective speech quality measures are typically used to assess speech enhancement algorithms, but it has been shown that they are sub-optimal as learning objectives because they do not always align well with human subjective ratings. This misalignment often results in noticeable distortions and artifacts that cause speech enhancement to be ineffective. To address these issues, we propose a reinforcement learning from human feedback (RLHF) framework to fine-tune an existing speech enhancement approach by optimizing performance using a mean-opinion score (MOS)-based reward model. Our results show that the RLHF-finetuned model has the best performance across different benchmarks for both objective and MOS-based speech quality assessment metrics on the Voicebank+DEMAND dataset. Through ablation studies, we show that both policy gradient loss and supervised MSE loss are important for balanced optimization across the different metrics.
ARES: Alternating Reinforcement Learning and Supervised Fine-Tuning for Enhanced Multi-Modal Chain-of-Thought Reasoning Through Diverse AI Feedback
Jun 25, 2024



Large Multimodal Models (LMMs) excel at comprehending human instructions and demonstrate remarkable results across a broad spectrum of tasks. Reinforcement Learning from Human Feedback (RLHF) and AI Feedback (RLAIF) further refine LLMs by aligning them with specific preferences. These methods primarily use ranking-based feedback for entire generations. With advanced AI models (Teacher), such as GPT-4 and Claude 3 Opus, we can request various types of detailed feedback that are expensive for humans to provide. We propose a two-stage algorithm ARES that Alternates REinforcement Learning (RL) and Supervised Fine-Tuning (SFT). First, we request the Teacher to score how much each sentence contributes to solving the problem in a Chain-of-Thought (CoT). This sentence-level feedback allows us to consider individual valuable segments, providing more granular rewards for the RL procedure. Second, we ask the Teacher to correct the wrong reasoning after the RL stage. The RL procedure requires massive efforts for hyperparameter tuning and often generates errors like repetitive words and incomplete sentences. With the correction feedback, we stabilize the RL fine-tuned model through SFT. We conduct experiments on multi-model dataset ScienceQA and A-OKVQA to demonstrate the effectiveness of our proposal. ARES rationale reasoning achieves around 70% win rate against baseline models judged by GPT-4o. Additionally, we observe that the improved rationale reasoning leads to a 2.5% increase in inference answer accuracy on average for the multi-modal datasets.
Symmetric Reinforcement Learning Loss for Robust Learning on Diverse Tasks and Model Scales
May 29, 2024Reinforcement learning (RL) training is inherently unstable due to factors such as moving targets and high gradient variance. Reinforcement Learning from Human Feedback (RLHF) and Reinforcement Learning from AI Feedback (RLAIF) can introduce additional difficulty. Differing preferences can complicate the alignment process, and prediction errors in a trained reward model can become more severe as the LLM generates unseen outputs. To enhance training robustness, RL has adopted techniques from supervised learning, such as ensembles and layer normalization. In this work, we improve the stability of RL training by adapting the reverse cross entropy (RCE) from supervised learning for noisy data to define a symmetric RL loss. We demonstrate performance improvements across various tasks and scales. We conduct experiments in discrete action tasks (Atari games) and continuous action space tasks (MuJoCo benchmark and Box2D) using Symmetric A2C (SA2C) and Symmetric PPO (SPPO), with and without added noise with especially notable performance in SPPO across different hyperparameters. Furthermore, we validate the benefits of the symmetric RL loss when using SPPO for large language models through improved performance in RLHF tasks, such as IMDB positive sentiment sentiment and TL;DR summarization tasks.