 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models can Solve Computer Tasks
Mar 30, 2023



Agents capable of carrying out general tasks on a computer can improve efficiency and productivity by automating repetitive tasks and assisting in complex problem-solving. Ideally, such agents should be able to solve new computer tasks presented to them through natural language commands. However, previous approaches to this problem require large amounts of expert demonstrations and task-specific reward functions, both of which are impractical for new tasks. In this work, we show that a pre-trained large language model (LLM) agent can execute computer tasks guided by natural language using a simple prompting scheme where the agent recursively criticizes and improves its output (RCI). The RCI approach significantly outperforms existing LLM methods for automating computer tasks and surpasses supervised learning (SL) and reinforcement learning (RL) approaches on the MiniWoB++ benchmark. RCI is competitive with the state-of-the-art SL+RL method, using only a handful of demonstrations per task rather than tens of thousands, and without a task-specific reward function. Furthermore, we demonstrate RCI prompting's effectiveness in enhancing LLMs' reasoning abilities on a suite of natural language reasoning tasks, outperforming chain of thought (CoT) prompting. We find that RCI combined with CoT performs better than either separately.
Ensemble Value Functions for Efficient Exploration in Multi-Agent Reinforcement Learning
Mar 02, 2023



Cooperative multi-agent reinforcement learning (MARL) requires agents to explore to learn to cooperate. Existing value-based MARL algorithms commonly rely on random exploration, such as $\epsilon$-greedy, which is inefficient in discovering multi-agent cooperation. Additionally, the environment in MARL appears non-stationary to any individual agent due to the simultaneous training of other agents, leading to highly variant and thus unstable optimisation signals. In this work, we propose ensemble value functions for multi-agent exploration (EMAX), a general framework to extend any value-based MARL algorithm. EMAX trains ensembles of value functions for each agent to address the key challenges of exploration and non-stationarity: (1) The uncertainty of value estimates across the ensemble is used in a UCB policy to guide the exploration of agents to parts of the environment which require cooperation. (2) Average value estimates across the ensemble serve as target values. These targets exhibit lower variance compared to commonly applied target networks and we show that they lead to more stable gradients during the optimisation. We instantiate three value-based MARL algorithms with EMAX, independent DQN, VDN and QMIX, and evaluate them in 21 tasks across four environments. Using ensembles of five value functions, EMAX improves sample efficiency and final evaluation returns of these algorithms by 54%, 55%, and 844%, respectively, averaged all 21 tasks.
ASP: Learn a Universal Neural Solver!
Mar 01, 2023



Applying machine learning to combinatorial optimization problems has the potential to improve both efficiency and accuracy. However, existing learning-based solvers often struggle with generalization when faced with changes in problem distributions and scales. In this paper, we propose a new approach called ASP: Adaptive Staircase Policy Space Response Oracle to address these generalization issues and learn a universal neural solver. ASP consists of two components: Distributional Exploration, which enhances the solver's ability to handle unknown distributions using Policy Space Response Oracles, and Persistent Scale Adaption, which improves scalability through curriculum learning. We have tested ASP on several challenging COPs, including the traveling salesman problem, the vehicle routing problem, and the prize collecting TSP, as well as the real-world instances from TSPLib and CVRPLib. Our results show that even with the same model size and weak training signal, ASP can help neural solvers explore and adapt to unseen distributions and varying scales, achieving superior performance. In particular, compared with the same neural solvers under a standard training pipeline, ASP produces a remarkable decrease in terms of the optimality gap with 90.9% and 47.43% on generated instances and real-world instances for TSP, and a decrease of 19% and 45.57% for CVRP.
Game Theoretic Rating in N-player general-sum games with Equilibria
Oct 05, 2022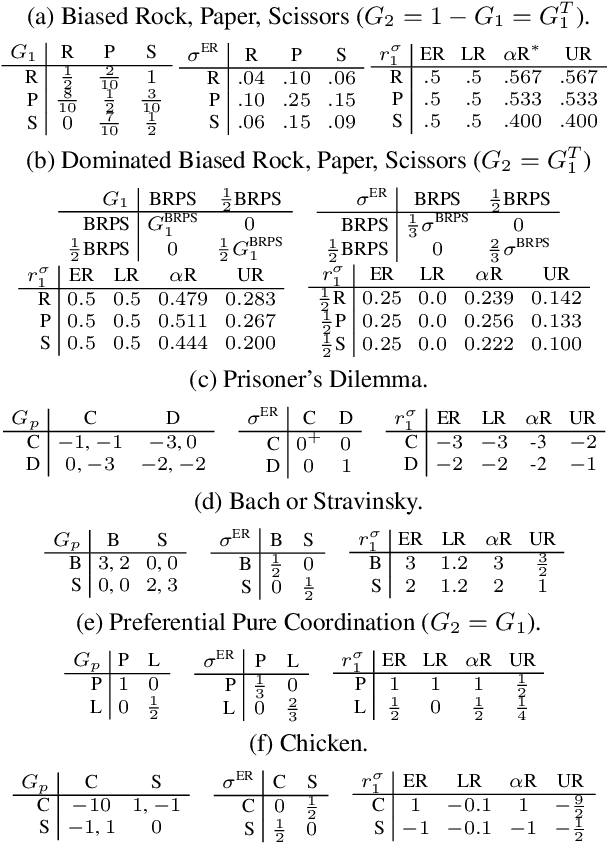
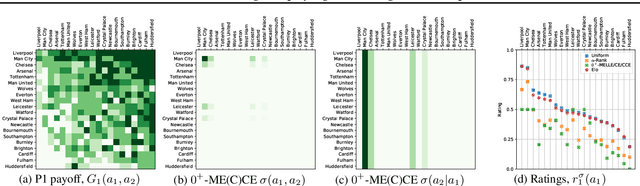
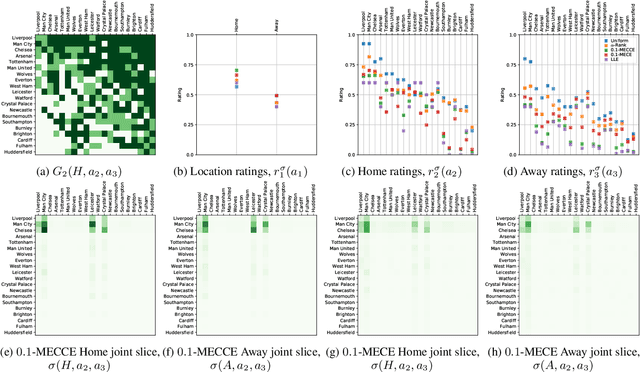
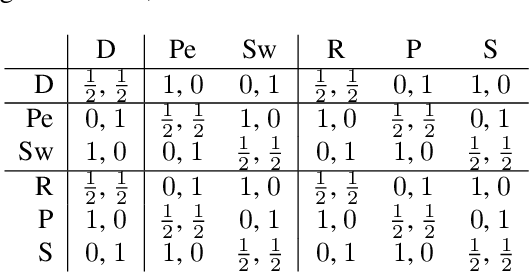
Rating strategies in a game is an important area of research in game theory and artificial intelligence, and can be applied to any real-world competitive or cooperative setting. Traditionally, only transitive dependencies between strategies have been used to rate strategies (e.g. Elo), however recent work has expanded ratings to utilize game theoretic solutions to better rate strategies in non-transitive games. This work generalizes these ideas and proposes novel algorithms suitable for N-player, general-sum rating of strategies in normal-form games according to the payoff rating system. This enables well-established solution concepts, such as equilibria, to be leveraged to efficiently rate strategies in games with complex strategic interactions, which arise in multiagent training and real-world interactions between many agents. We empirically validate our methods on real world normal-form data (Premier League) and multiagent reinforcement learning agent evaluation.
Reducing Variance in Temporal-Difference Value Estimation via Ensemble of Deep Networks
Sep 16, 2022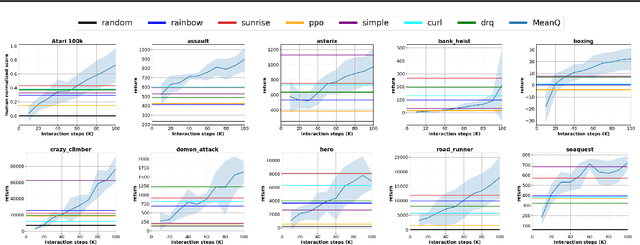

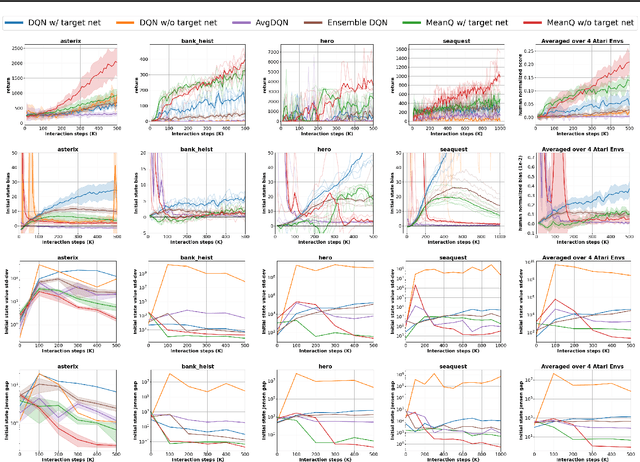
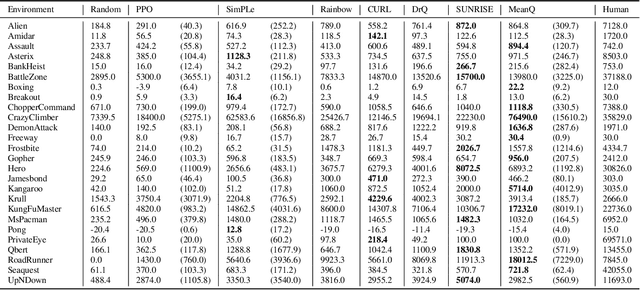
In temporal-difference reinforcement learning algorithms, variance in value estimation can cause instability and overestimation of the maximal target value. Many algorithms have been proposed to reduce overestimation, including several recent ensemble methods, however none have shown success in sample-efficient learning through addressing estimation variance as the root cause of overestimation. In this paper, we propose MeanQ, a simple ensemble method that estimates target values as ensemble means. Despite its simplicity, MeanQ shows remarkable sample efficiency in experiments on the Atari Learning Environment benchmark. Importantly, we find that an ensemble of size 5 sufficiently reduces estimation variance to obviate the lagging target network, eliminating it as a source of bias and further gaining sample efficiency. We justify intuitively and empirically the design choices in MeanQ, including the necessity of independent experience sampling. On a set of 26 benchmark Atari environments, MeanQ outperforms all tested baselines, including the best available baseline, SUNRISE, at 100K interaction steps in 16/26 environments, and by 68% on average. MeanQ also outperforms Rainbow DQN at 500K steps in 21/26 environments, and by 49% on average, and achieves average human-level performance using 200K ($\pm$100K) interaction steps. Our implementation is available at https://github.com/indylab/MeanQ.
Feasible Adversarial Robust Reinforcement Learning for Underspecified Environments
Jul 19, 2022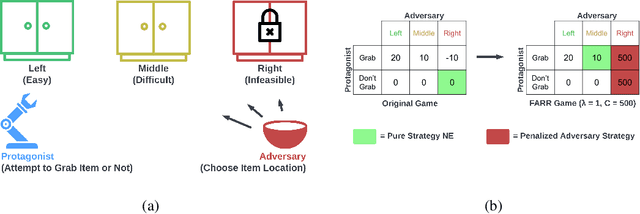

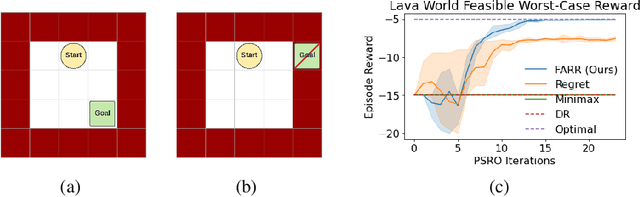

Robust reinforcement learning (RL) considers the problem of learning policies that perform well in the worst case among a set of possible environment parameter values. In real-world environments, choosing the set of possible values for robust RL can be a difficult task. When that set is specified too narrowly, the agent will be left vulnerable to reasonable parameter values unaccounted for. When specified too broadly, the agent will be too cautious. In this paper, we propose Feasible Adversarial Robust RL (FARR), a method for automatically determining the set of environment parameter values over which to be robust. FARR implicitly defines the set of feasible parameter values as those on which an agent could achieve a benchmark reward given enough training resources. By formulating this problem as a two-player zero-sum game, FARR jointly learns an adversarial distribution over parameter values with feasible support and a policy robust over this feasible parameter set. Using the PSRO algorithm to find an approximate Nash equilibrium in this FARR game, we show that an agent trained with FARR is more robust to feasible adversarial parameter selection than with existing minimax, domain-randomization, and regret objectives in a parameterized gridworld and three MuJoCo control environments.
Self-Play PSRO: Toward Optimal Populations in Two-Player Zero-Sum Games
Jul 13, 2022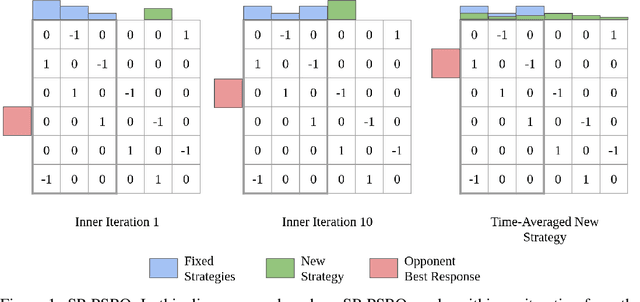
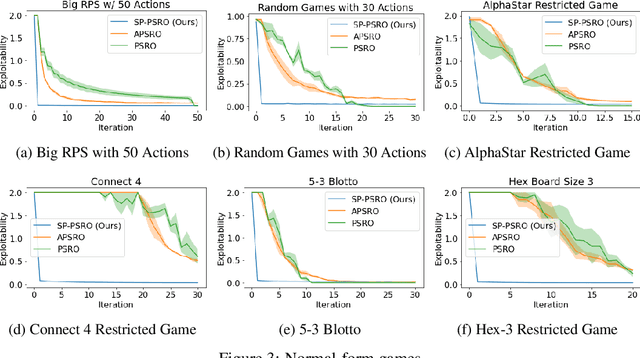

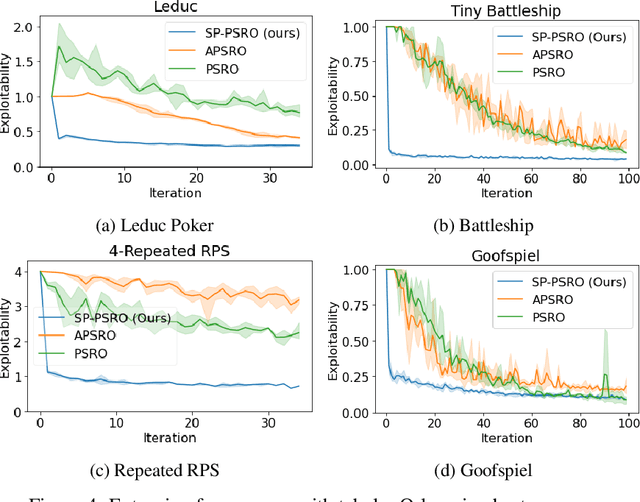
In competitive two-agent environments, deep reinforcement learning (RL) methods based on the \emph{Double Oracle (DO)} algorithm, such as \emph{Policy Space Response Oracles (PSRO)} and \emph{Anytime PSRO (APSRO)}, iteratively add RL best response policies to a population. Eventually, an optimal mixture of these population policies will approximate a Nash equilibrium. However, these methods might need to add all deterministic policies before converging. In this work, we introduce \emph{Self-Play PSRO (SP-PSRO)}, a method that adds an approximately optimal stochastic policy to the population in each iteration. Instead of adding only deterministic best responses to the opponent's least exploitable population mixture, SP-PSRO also learns an approximately optimal stochastic policy and adds it to the population as well. As a result, SP-PSRO empirically tends to converge much faster than APSRO and in many games converges in just a few iterations.
Mastering the Game of Stratego with Model-Free Multiagent Reinforcement Learning
Jun 30, 2022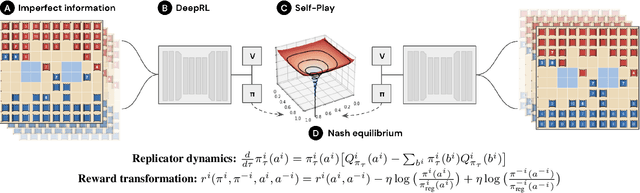
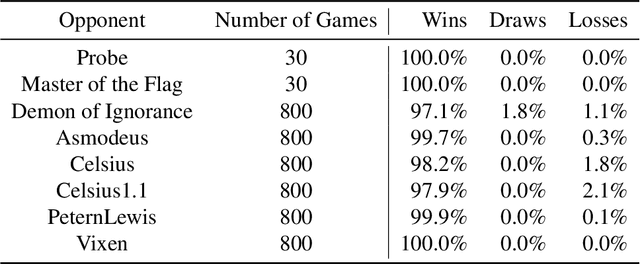
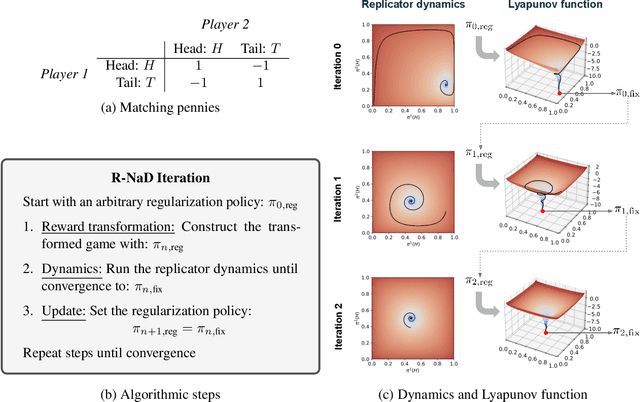

We introduce DeepNash, an autonomous agent capable of learning to play the imperfect information game Stratego from scratch, up to a human expert level. Stratego is one of the few iconic board games that Artificial Intelligence (AI) has not yet mastered. This popular game has an enormous game tree on the order of $10^{535}$ nodes, i.e., $10^{175}$ times larger than that of Go. It has the additional complexity of requiring decision-making under imperfect information, similar to Texas hold'em poker, which has a significantly smaller game tree (on the order of $10^{164}$ nodes). Decisions in Stratego are made over a large number of discrete actions with no obvious link between action and outcome. Episodes are long, with often hundreds of moves before a player wins, and situations in Stratego can not easily be broken down into manageably-sized sub-problems as in poker. For these reasons, Stratego has been a grand challenge for the field of AI for decades, and existing AI methods barely reach an amateur level of play. DeepNash uses a game-theoretic, model-free deep reinforcement learning method, without search, that learns to master Stratego via self-play. The Regularised Nash Dynamics (R-NaD) algorithm, a key component of DeepNash, converges to an approximate Nash equilibrium, instead of 'cycling' around it, by directly modifying the underlying multi-agent learning dynamics. DeepNash beats existing state-of-the-art AI methods in Stratego and achieved a yearly (2022) and all-time top-3 rank on the Gravon games platform, competing with human expert players.
ESCHER: Eschewing Importance Sampling in Games by Computing a History Value Function to Estimate Regret
Jun 08, 2022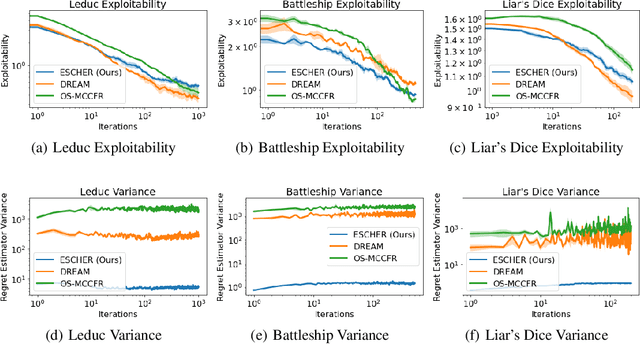

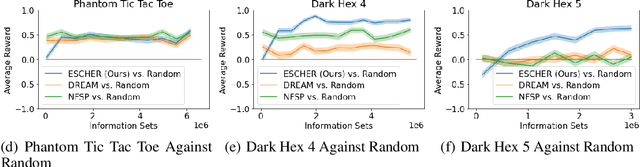

Recent techniques for approximating Nash equilibria in very large games leverage neural networks to learn approximately optimal policies (strategies). One promising line of research uses neural networks to approximate counterfactual regret minimization (CFR) or its modern variants. DREAM, the only current CFR-based neural method that is model free and therefore scalable to very large games, trains a neural network on an estimated regret target that can have extremely high variance due to an importance sampling term inherited from Monte Carlo CFR (MCCFR). In this paper we propose an unbiased model-free method that does not require any importance sampling. Our method, ESCHER, is principled and is guaranteed to converge to an approximate Nash equilibrium with high probability in the tabular case. We show that the variance of the estimated regret of a tabular version of ESCHER with an oracle value function is significantly lower than that of outcome sampling MCCFR and tabular DREAM with an oracle value function. We then show that a deep learning version of ESCHER outperforms the prior state of the art -- DREAM and neural fictitious self play (NFSP) -- and the difference becomes dramatic as game size increases.
Learning Risk-Averse Equilibria in Multi-Agent Systems
May 30, 2022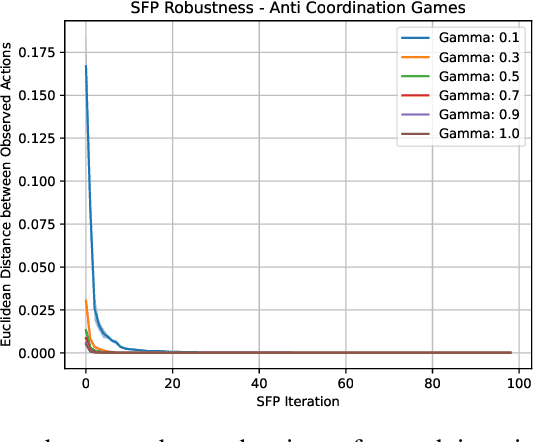
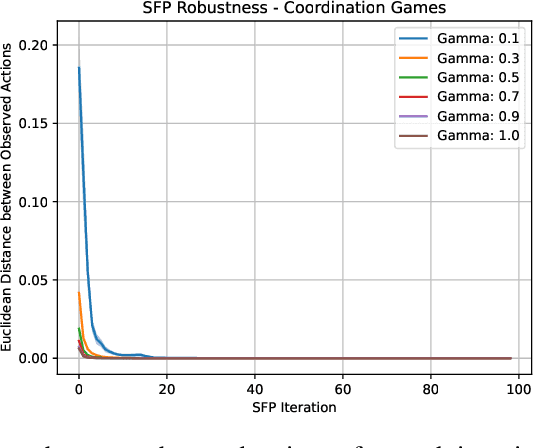
In multi-agent systems, intelligent agents are tasked with making decisions that have optimal outcomes when the actions of the other agents are as expected, whilst also being prepared for unexpected behaviour. In this work, we introduce a new risk-averse solution concept that allows the learner to accommodate unexpected actions by finding the minimum variance strategy given any level of expected return. We prove the existence of such a risk-averse equilibrium, and propose one fictitious-play type learning algorithm for smaller games that enjoys provable convergence guarantees in certain games classes (e.g., zero-sum or potential). Furthermore, we propose an approximation method for larger games based on iterative population-based training that generates a population of risk-averse agents. Empirically, our equilibrium is shown to be able to reduce the reward variance, specifically in the sense that off-equilibrium behaviour has a far smaller impact on our risk-averse agents in comparison to playing other equilibrium solutions. Importantly, we show that our population of agents that approximate a risk-averse equilibrium is particularly effective in the presence of unseen opposing populations, especially in the case of guaranteeing a minimal level of performance which is critical to safety-aware multi-agent systems.