 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Non-Local Neural Networks
Jun 11, 2020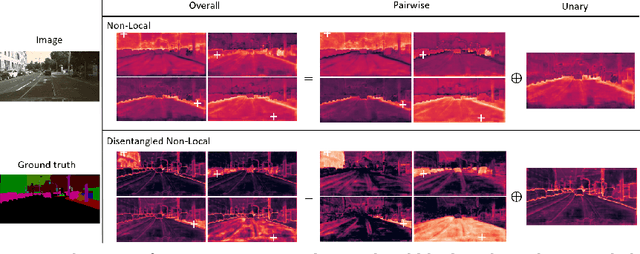
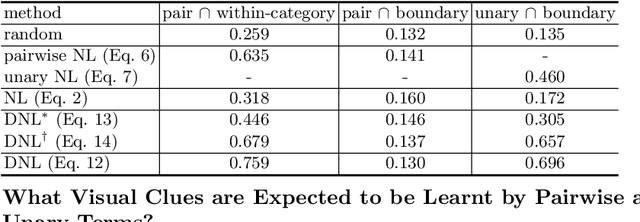
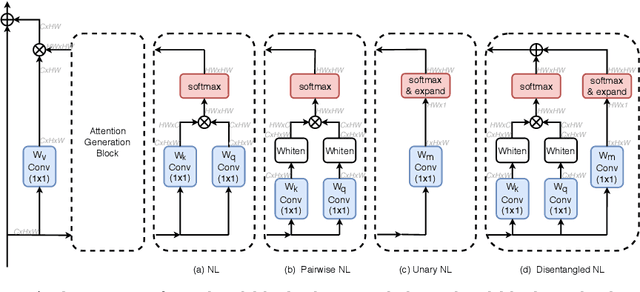
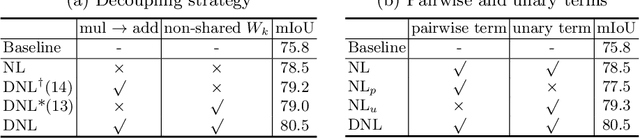
The non-local block is a popular module for strengthening the context modeling ability of a regular convolutional neural network. This paper first studies the non-local block in depth, where we find that its attention computation can be split into two terms, a whitened pairwise term accounting for the relationship between two pixels and a unary term representing the saliency of every pixel. We also observe that the two terms trained alone tend to model different visual clues, e.g. the whitened pairwise term learns within-region relationships while the unary term learns salient boundaries. However, the two terms are tightly coupled in the non-local block, which hinders the learning of each. Based on these findings, we present the disentangled non-local block, where the two terms are decoupled to facilitate learning for both terms. We demonstrate the effectiveness of the decoupled design on various tasks, such as semantic segmentation on Cityscapes, ADE20K and PASCAL Context, object detection on COCO, and action recognition on Kinetics.
What makes instance discrimination good for transfer learning?
Jun 11, 2020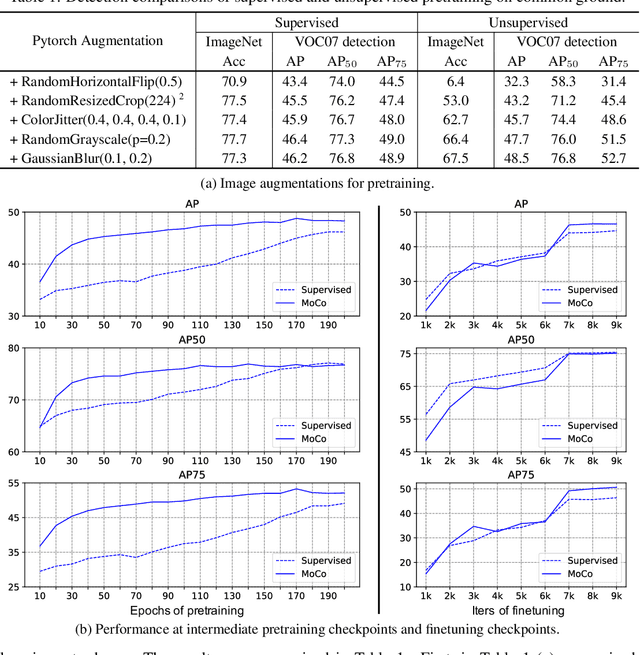
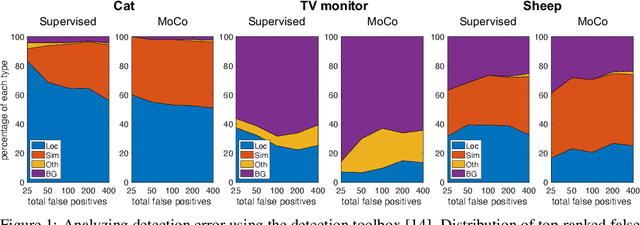
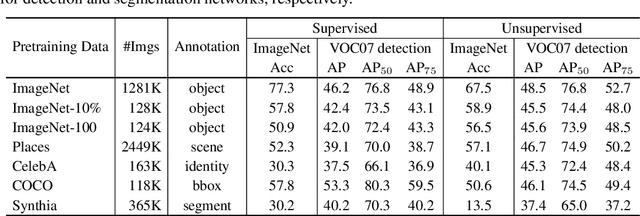

Unsupervised visual pretraining based on the instance discrimination pretext task has shown significant progress. Notably, in the recent work of MoCo, unsupervised pretraining has shown to surpass the supervised counterpart for finetuning downstream applications such as object detection on PASCAL VOC. It comes as a surprise that image annotations would be better left unused for transfer learning. In this work, we investigate the following problems: What makes instance discrimination pretraining good for transfer learning? What knowledge is actually learned and transferred from unsupervised pretraining? From this understanding of unsupervised pretraining, can we make supervised pretraining great again? Our findings are threefold. First, what truly matters for this detection transfer is low-level and mid-level representations, not high-level representations. Second, the intra-category invariance enforced by the traditional supervised model weakens transferability by increasing task misalignment. Finally, supervised pretraining can be strengthened by following an exemplar-based approach without explicit constraints among the instances within the same category.
A Transductive Approach for Video Object Segmentation
Apr 16, 2020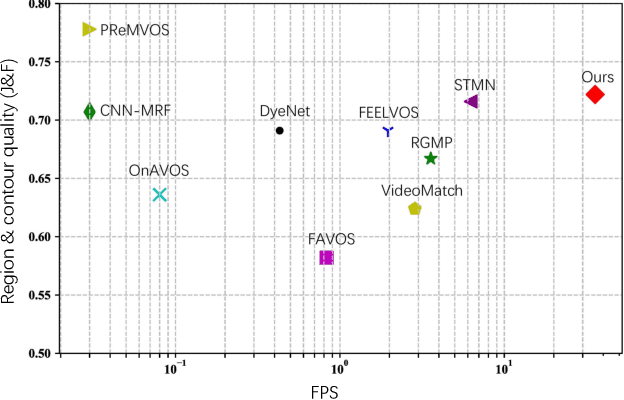

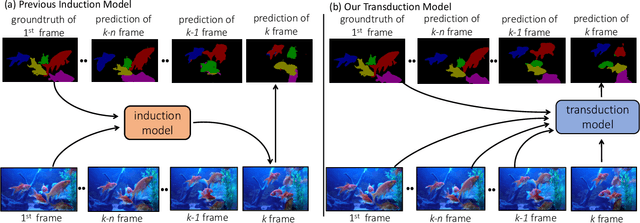
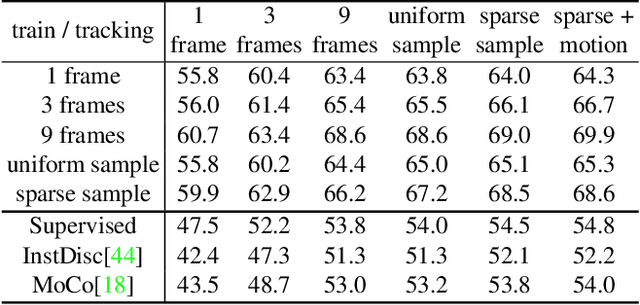
Semi-supervised video object segmentation aims to separate a target object from a video sequence, given the mask in the first frame. Most of current prevailing methods utilize information from additional modules trained in other domains like optical flow and instance segmentation, and as a result they do not compete with other methods on common ground. To address this issue, we propose a simple yet strong transductive method, in which additional modules, datasets, and dedicated architectural designs are not needed. Our method takes a label propagation approach where pixel labels are passed forward based on feature similarity in an embedding space. Different from other propagation methods, ours diffuses temporal information in a holistic manner which take accounts of long-term object appearance. In addition, our method requires few additional computational overhead, and runs at a fast $\sim$37 fps speed. Our single model with a vanilla ResNet50 backbone achieves an overall score of 72.3 on the DAVIS 2017 validation set and 63.1 on the test set. This simple yet high performing and efficient method can serve as a solid baseline that facilitates future research. Code and models are available at \url{https://github.com/microsoft/transductive-vos.pytorch}.
Distilling Localization for Self-Supervised Representation Learning
Apr 14, 2020
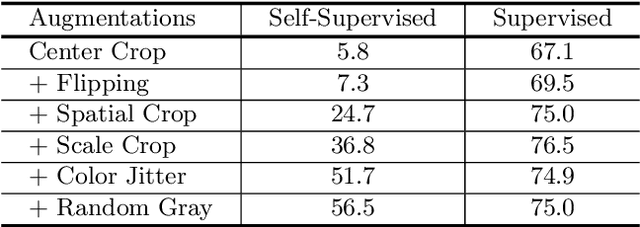

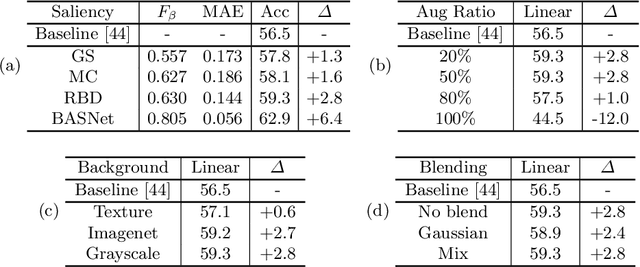
For high-level visual recognition, self-supervised learning defines and makes use of proxy tasks such as colorization and visual tracking to learn a semantic representation useful for distinguishing objects. In this paper, through visualizing and diagnosing classification errors, we observe that current self-supervised models are ineffective at localizing the foreground object, limiting their ability to extract discriminative high-level features. To address this problem, we propose a data-driven approach for learning invariance to backgrounds. It first estimates foreground saliency in images and then creates augmentations by copy-and-pasting the foreground onto a variety of backgrounds. The learning follows an instance discrimination approach which encourages the features of augmentations from the same image to be similar. In this way, the representation is trained to disregard background content and focus on the foreground. We study a variety of saliency estimation methods, and find that most methods lead to improvements for self-supervised learning. With this approach, strong performance is achieved for self-supervised learning on ImageNet classification, and also for transfer learning to object detection on PASCAL VOC 2007.
Spatially Adaptive Inference with Stochastic Feature Sampling and Interpolation
Mar 19, 2020
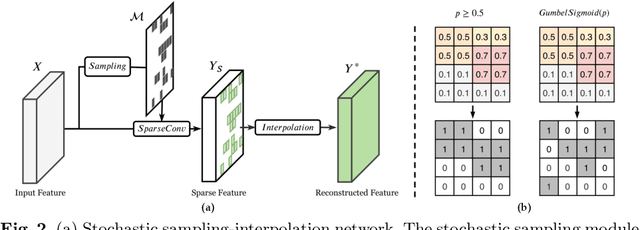
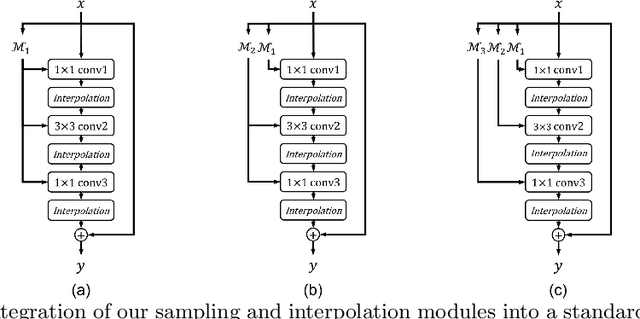
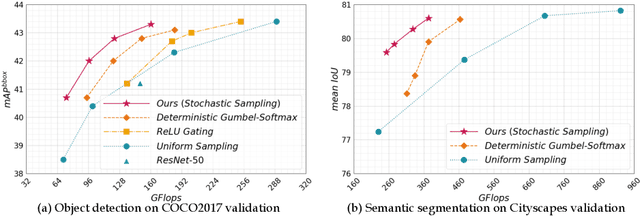
In the feature maps of CNNs, there commonly exists considerable spatial redundancy that leads to much repetitive processing. Towards reducing this superfluous computation, we propose to compute features only at sparsely sampled locations, which are probabilistically chosen according to activation responses, and then densely reconstruct the feature map with an efficient interpolation procedure. With this sampling-interpolation scheme, our network avoids expending computation on spatial locations that can be effectively interpolated, while being robust to activation prediction errors through broadly distributed sampling. A technical challenge of this sampling-based approach is that the binary decision variables for representing discrete sampling locations are non-differentiable, making them incompatible with backpropagation. To circumvent this issue, we make use of a reparameterization trick based on the Gumbel-Softmax distribution, with which backpropagation can iterate these variables towards binary values. The presented network is experimentally shown to save substantial computation while maintaining accuracy over a variety of computer vision tasks.
Cross-Iteration Batch Normalization
Feb 14, 2020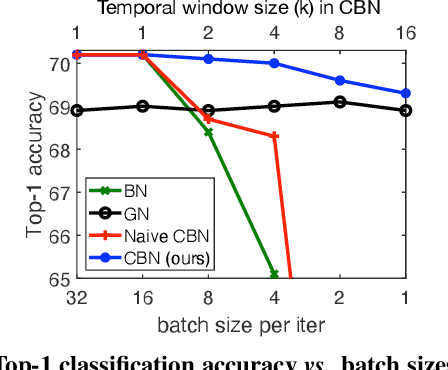

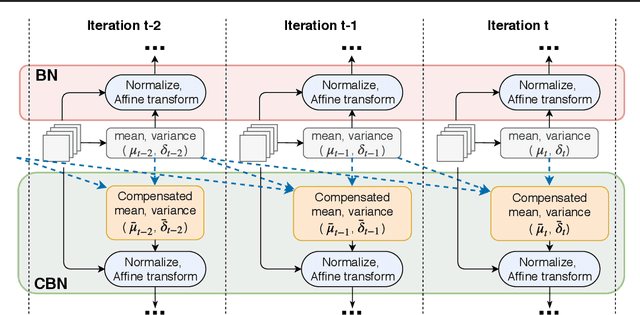

A well-known issue of Batch Normalization is its significantly reduced effectiveness in the case of small mini-batch sizes. When a mini-batch contains few examples, the statistics upon which the normalization is defined cannot be reliably estimated from it during a training iteration. To address this problem, we present Cross-Iteration Batch Normalization (CBN), in which examples from multiple recent iterations are jointly utilized to enhance estimation quality. A challenge of computing statistics over multiple iterations is that the network activations from different iterations are not comparable to each other due to changes in network weights. We thus compensate for the network weight changes via a proposed technique based on Taylor polynomials, so that the statistics can be accurately estimated and batch normalization can be effectively applied. On object detection and image classification with small mini-batch sizes, CBN is found to outperform the original batch normalization and a direct calculation of statistics over previous iterations without the proposed compensation technique.
Dense RepPoints: Representing Visual Objects with Dense Point Sets
Dec 24, 2019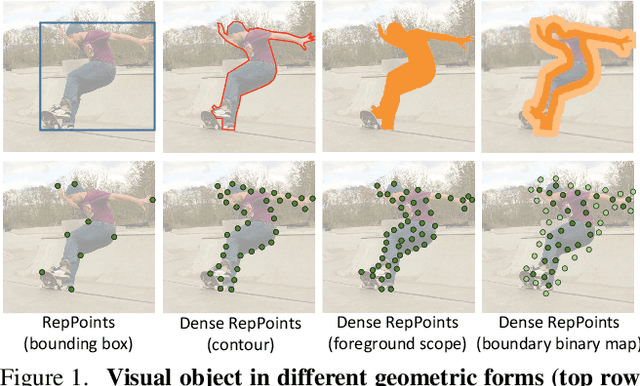
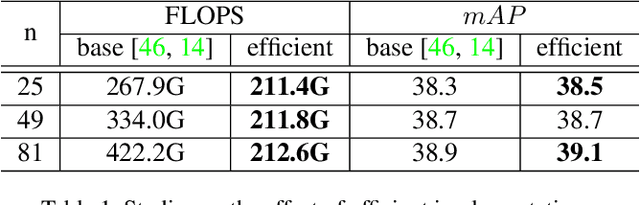
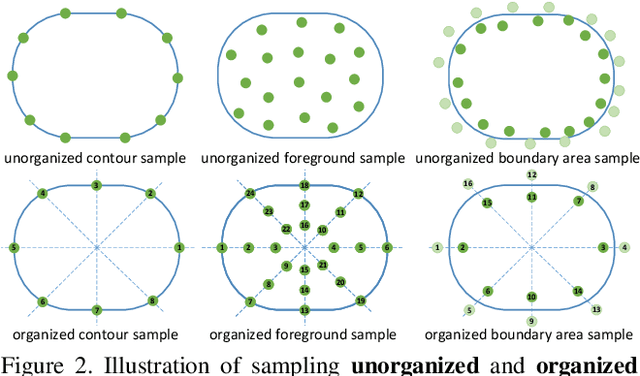
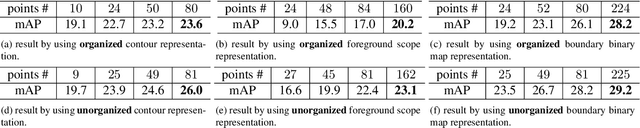
We present an object representation, called \textbf{Dense RepPoints}, for flexible and detailed modeling of object appearance and geometry. In contrast to the coarse geometric localization and feature extraction of bounding boxes, Dense RepPoints adaptively distributes a dense set of points to semantically and geometrically significant positions on an object, providing informative cues for object analysis. Techniques are developed to address challenges related to supervised training for dense point sets from image segments annotations and making this extensive representation computationally practical. In addition, the versatility of this representation is exploited to model object structure over multiple levels of granularity. Dense RepPoints significantly improves performance on geometrically-oriented visual understanding tasks, including a $1.6$ AP gain in object detection on the challenging COCO benchmark.
Instance-wise Depth and Motion Learning from Monocular Videos
Dec 19, 2019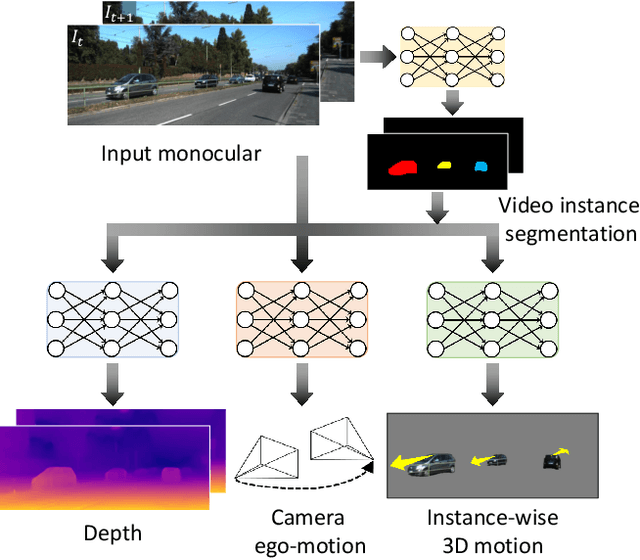
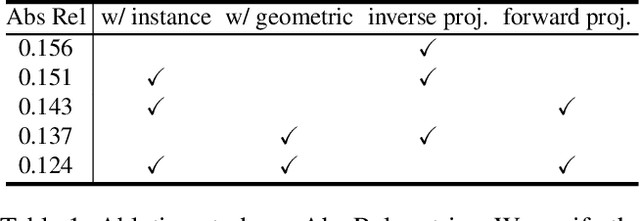
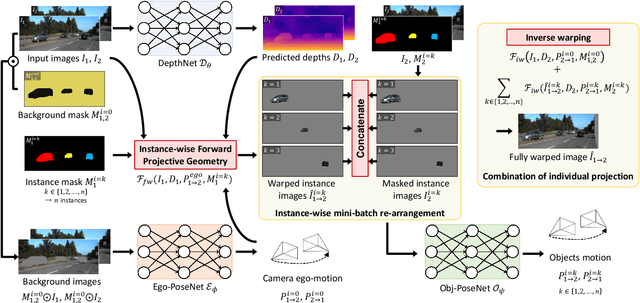
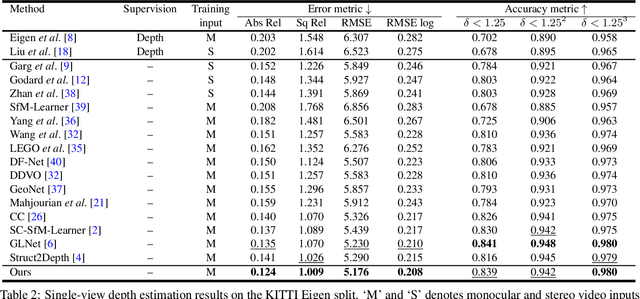
We present an end-to-end joint training framework that explicitly models 6-DoF motion of multiple dynamic objects, ego-motion and depth in a monocular camera setup without supervision. The only annotation used in our pipeline is a video instance segmentation map that can be predicted by our new auto-annotation scheme. Our technical contributions are three-fold. First, we propose a differentiable forward rigid projection module that plays a key role in our instance-wise depth and motion learning. Second, we design an instance-wise photometric and geometric consistency loss that effectively decomposes background and moving object regions. Lastly, we introduce an instance-wise mini-batch re-arrangement scheme that does not require additional iterations in training. These proposed elements are validated in a detailed ablation study. Through extensive experiments conducted on the KITTI dataset, our framework is shown to outperform the state-of-the-art depth and motion estimation methods.
Leveraging Multi-view Image Sets for Unsupervised Intrinsic Image Decomposition and Highlight Separation
Nov 17, 2019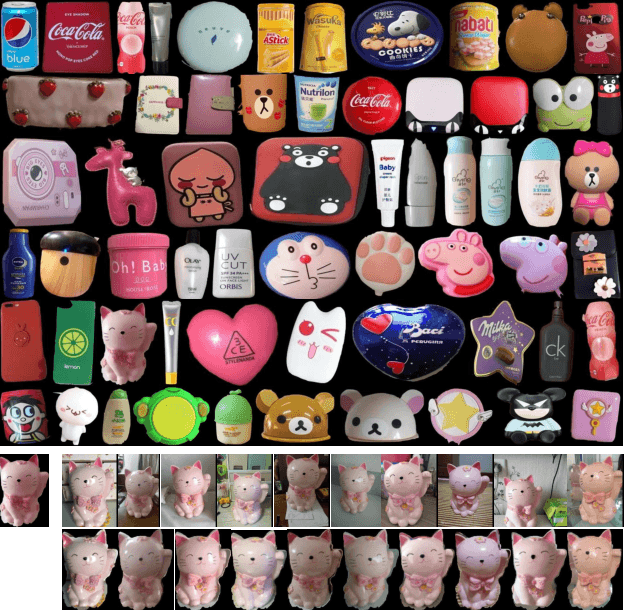
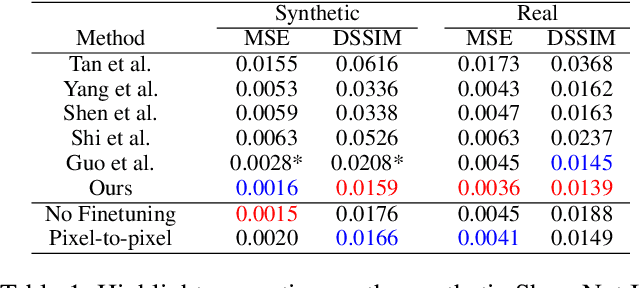
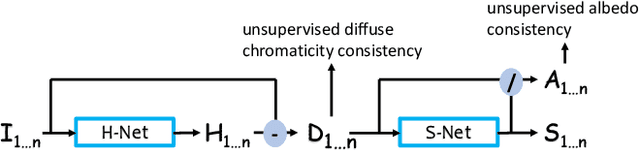
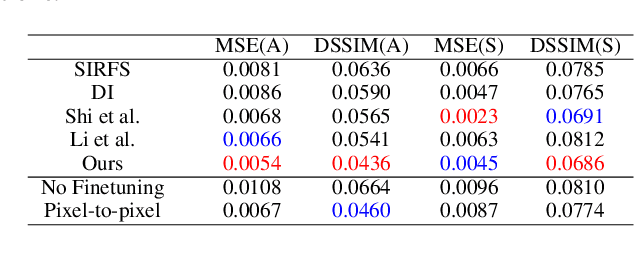
We present an unsupervised approach for factorizing object appearance into highlight, shading, and albedo layers, trained by multi-view real images. To do so, we construct a multi-view dataset by collecting numerous customer product photos online, which exhibit large illumination variations that make them suitable for training of reflectance separation and can facilitate object-level decomposition. The main contribution of our approach is a proposed image representation based on local color distributions that allows training to be insensitive to the local misalignments of multi-view images. In addition, we present a new guidance cue for unsupervised training that exploits synergy between highlight separation and intrinsic image decomposition. Over a broad range of objects, our technique is shown to yield state-of-the-art results for both of these tasks.
Single Image Reflection Removal through Cascaded Refinement
Nov 15, 2019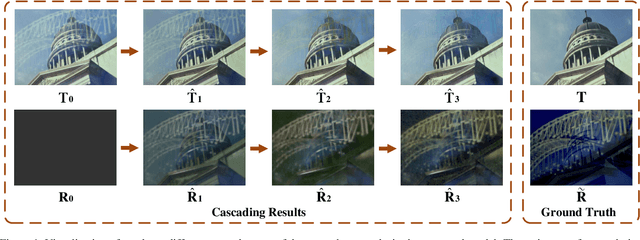
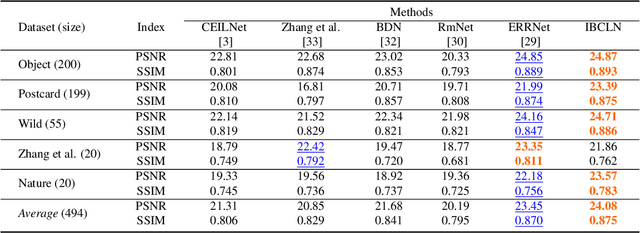
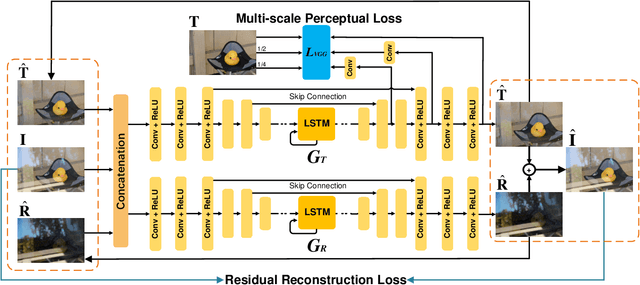
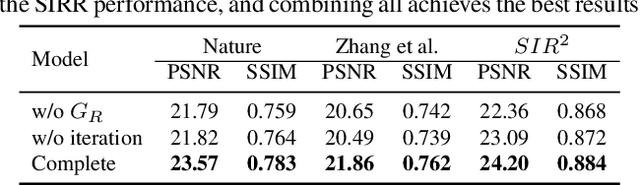
We address the problem of removing undesirable reflections from a single image captured through a glass surface, which is an ill-posed, challenging but practically important problem for photo enhancement. Inspired by iterative structure reduction for hidden community detection in social networks, we propose an Iterative Boost Convolutional LSTM Network (IBCLN) that enables cascaded prediction for reflection removal. IBCLN iteratively refines estimates of the transmission and reflection layers at each step in a manner that they can boost the prediction quality for each other. The intuition is that progressive refinement of the transmission or reflection layer is aided by increasingly better estimates of these quantities as input, and that transmission and reflection are complementary to each other in a single image and thus provide helpful auxiliary information for each other's prediction. To facilitate training over multiple cascade steps, we employ LSTM to address the vanishing gradient problem, and incorporate a reconstruction loss as further training guidance at each step. In addition, we create a dataset of real-world images with reflection and ground-truth transmission layers to mitigate the problem of insufficient data. Through comprehensive experiments, IBCLN demonstrates performance that surpasses state-of-the-art reflection removal methods.