 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
Aug 06, 2019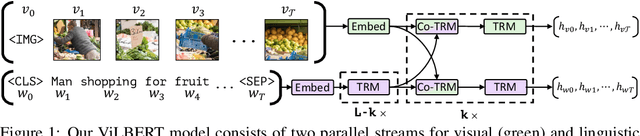
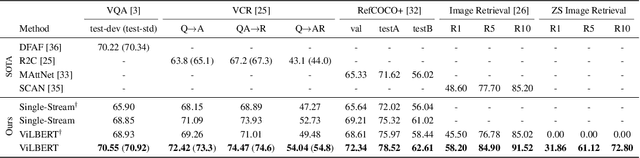
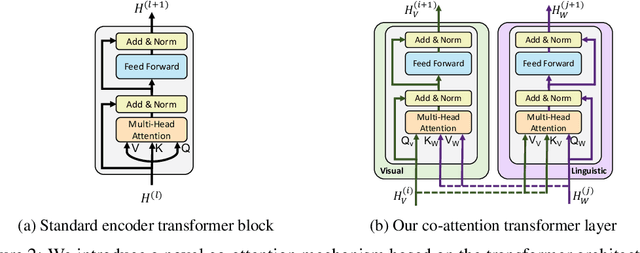

We present ViLBERT (short for Vision-and-Language BERT), a model for learning task-agnostic joint representations of image content and natural language. We extend the popular BERT architecture to a multi-modal two-stream model, pro-cessing both visual and textual inputs in separate streams that interact through co-attentional transformer layers. We pretrain our model through two proxy tasks on the large, automatically collected Conceptual Captions dataset and then transfer it to multiple established vision-and-language tasks -- visual question answering, visual commonsense reasoning, referring expressions, and caption-based image retrieval -- by making only minor additions to the base architecture. We observe significant improvements across tasks compared to existing task-specific models -- achieving state-of-the-art on all four tasks. Our work represents a shift away from learning groundings between vision and language only as part of task training and towards treating visual grounding as a pretrainable and transferable capability.
Chasing Ghosts: Instruction Following as Bayesian State Tracking
Jul 03, 2019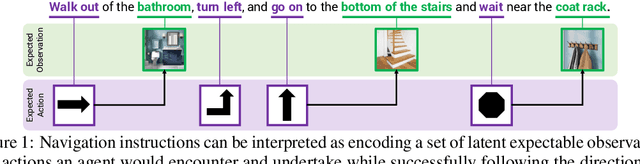
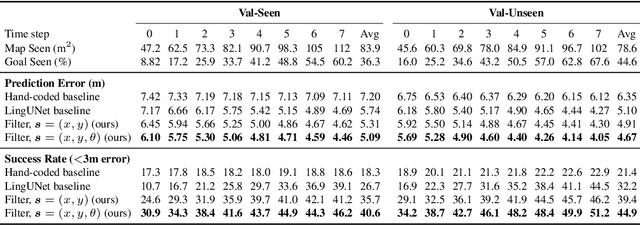
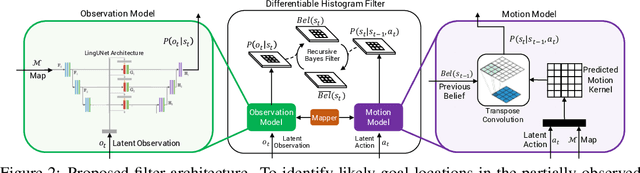
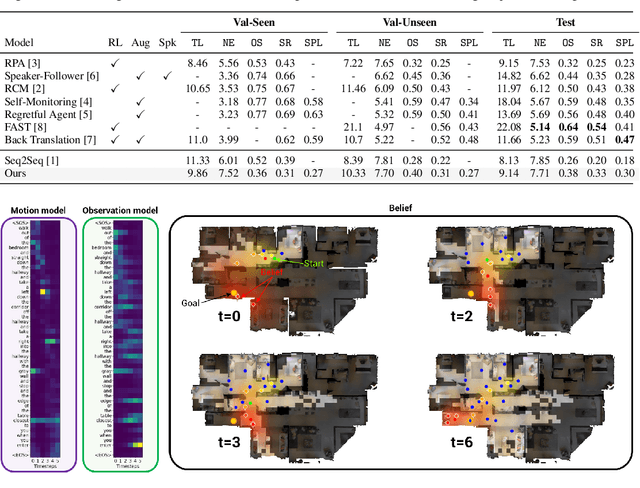
A visually-grounded navigation instruction can be interpreted as a sequence of expected observations and actions an agent following the correct trajectory would encounter and perform. Based on this intuition, we formulate the problem of finding the goal location in Vision-And-Language Navigation (VLN) within the framework of Bayesian state tracking - learning observation and motion models conditioned on these expectable events. Together with a mapper that constructs a semantic spatial map on-the-fly during navigation, we formulate an end-to-end differentiable Bayes filter and train it to identify the goal by predicting the most likely trajectory through the map according to the instructions. The resulting navigation policy constitutes a new approach to instruction following that explicitly models a probability distribution over states, encoding strong geometric and algorithmic priors while enabling greater explainability. Our experiments show that our approach outperforms strong baselines when predicting the goal location in VLN.
Emergence of Compositional Language with Deep Generational Transmission
Apr 19, 2019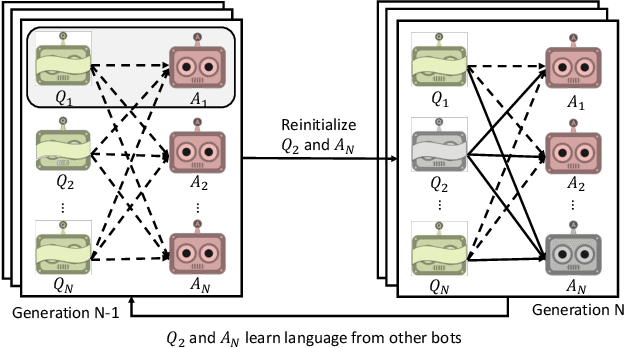
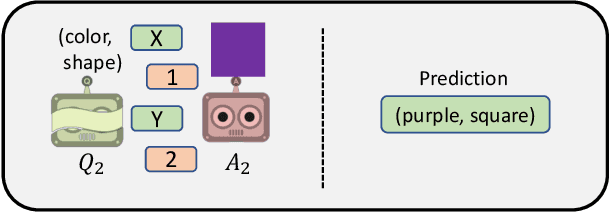
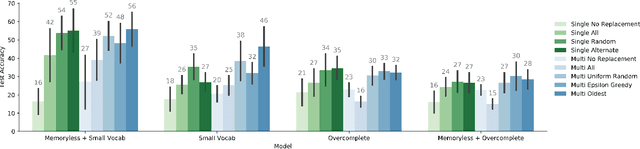
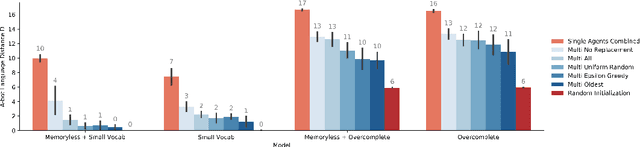
Consider a collaborative task that requires communication. Two agents are placed in an environment and must create a language from scratch in order to coordinate. Recent work has been interested in what kinds of languages emerge when deep reinforcement learning agents are put in such a situation, and in particular in the factors that cause language to be compositional-i.e. meaning is expressed by combining words which themselves have meaning. Evolutionary linguists have also studied the emergence of compositional language for decades, and they find that in addition to structural priors like those already studied in deep learning, the dynamics of transmitting language from generation to generation contribute significantly to the emergence of compositionality. In this paper, we introduce these cultural evolutionary dynamics into language emergence by periodically replacing agents in a population to create a knowledge gap, implicitly inducing cultural transmission of language. We show that this implicit cultural transmission encourages the resulting languages to exhibit better compositional generalization and suggest how elements of cultural dynamics can be further integrated into populations of deep agents.
Counterfactual Visual Explanations
Apr 16, 2019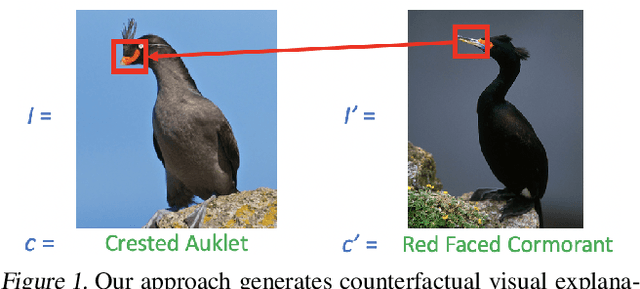
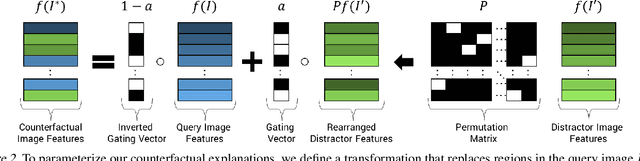
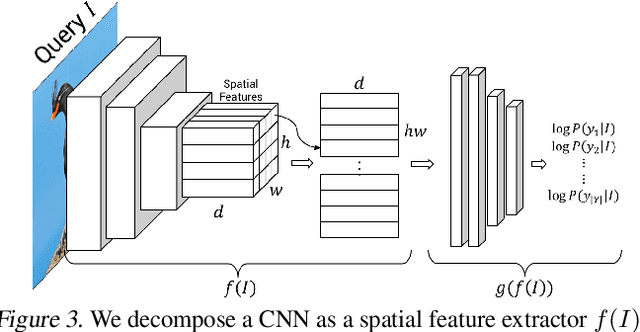
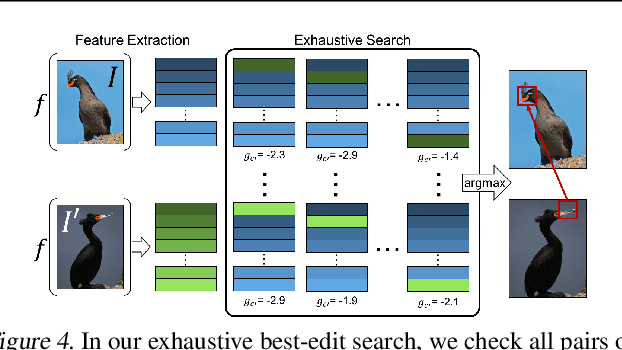
A counterfactual query is typically of the form 'For situation X, why was the outcome Y and not Z?'. A counterfactual explanation (or response to such a query) is of the form "If X was X*, then the outcome would have been Z rather than Y." In this work, we develop a technique to produce counterfactual visual explanations. Given a 'query' image $I$ for which a vision system predicts class $c$, a counterfactual visual explanation identifies how $I$ could change such that the system would output a different specified class $c'$. To do this, we select a 'distractor' image $I'$ that the system predicts as class $c'$ and identify spatial regions in $I$ and $I'$ such that replacing the identified region in $I$ with the identified region in $I'$ would push the system towards classifying $I$ as $c'$. We apply our approach to multiple image classification datasets generating qualitative results showcasing the interpretability and discriminativeness of our counterfactual explanations. To explore the effectiveness of our explanations in teaching humans, we present machine teaching experiments for the task of fine-grained bird classification. We find that users trained to distinguish bird species fare better when given access to counterfactual explanations in addition to training examples.
Embodied Question Answering in Photorealistic Environments with Point Cloud Perception
Apr 06, 2019
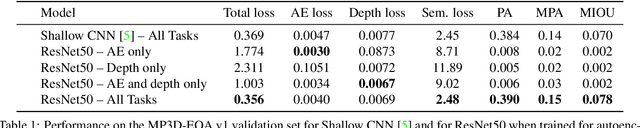
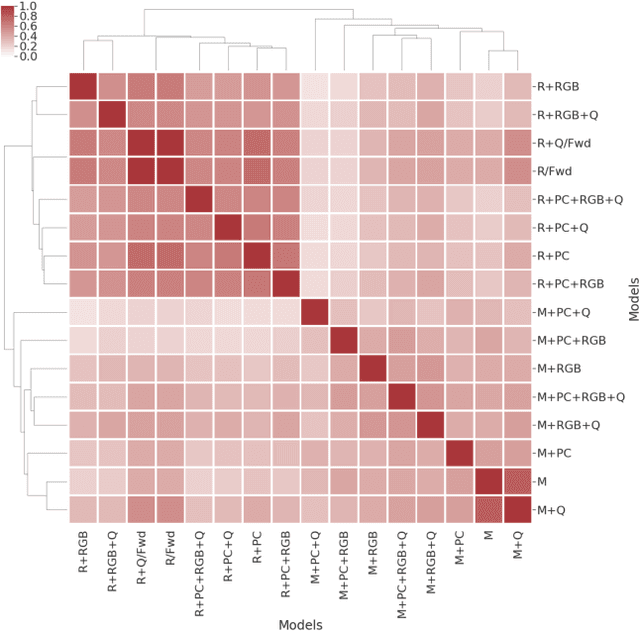
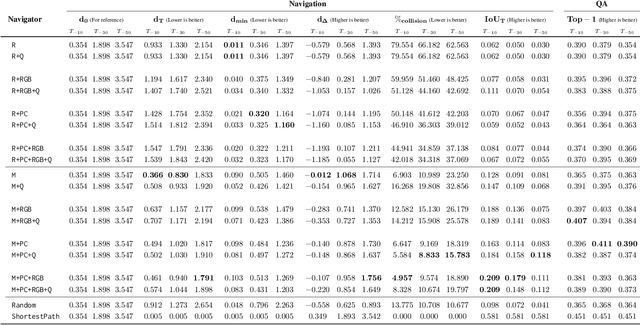
To help bridge the gap between internet vision-style problems and the goal of vision for embodied perception we instantiate a large-scale navigation task -- Embodied Question Answering [1] in photo-realistic environments (Matterport 3D). We thoroughly study navigation policies that utilize 3D point clouds, RGB images, or their combination. Our analysis of these models reveals several key findings. We find that two seemingly naive navigation baselines, forward-only and random, are strong navigators and challenging to outperform, due to the specific choice of the evaluation setting presented by [1]. We find a novel loss-weighting scheme we call Inflection Weighting to be important when training recurrent models for navigation with behavior cloning and are able to out perform the baselines with this technique. We find that point clouds provide a richer signal than RGB images for learning obstacle avoidance, motivating the use (and continued study) of 3D deep learning models for embodied navigation.
Probabilistic Neural-symbolic Models for Interpretable Visual Question Answering
Feb 21, 2019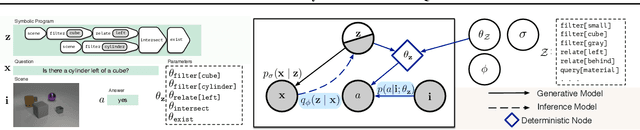
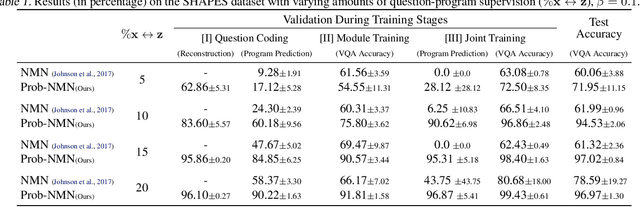
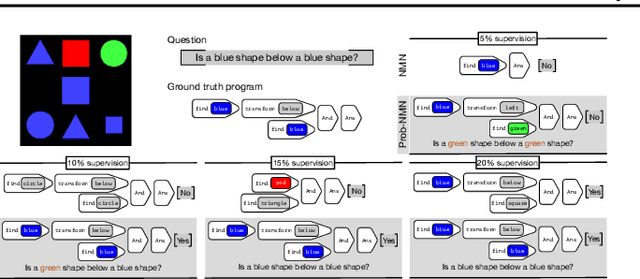

We propose a new class of probabilistic neural-symbolic models, that have symbolic functional programs as a latent, stochastic variable. Instantiated in the context of visual question answering, our probabilistic formulation offers two key conceptual advantages over prior neural-symbolic models for VQA. Firstly, the programs generated by our model are more understandable while requiring lesser number of teaching examples. Secondly, we show that one can pose counterfactual scenarios to the model, to probe its beliefs on the programs that could lead to a specified answer given an image. Our results on the CLEVR and SHAPES datasets verify our hypotheses, showing that the model gets better program (and answer) prediction accuracy even in the low data regime, and allows one to probe the coherence and consistency of reasoning performed.
Taking a HINT: Leveraging Explanations to Make Vision and Language Models More Grounded
Feb 11, 2019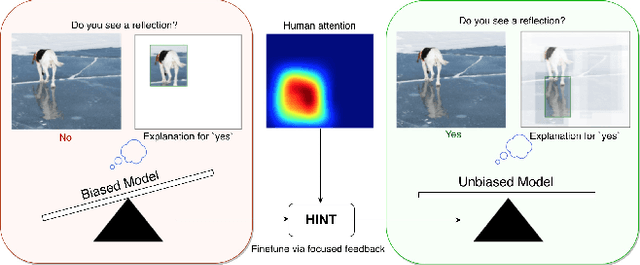
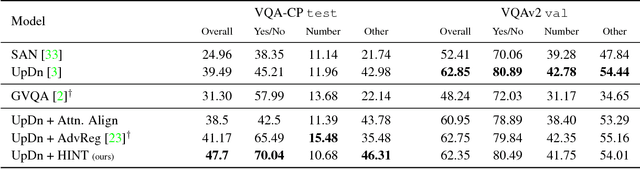
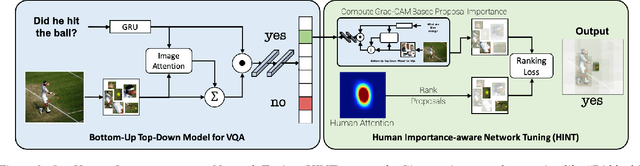

Many vision and language models suffer from poor visual grounding - often falling back on easy-to-learn language priors rather than associating language with visual concepts. In this work, we propose a generic framework which we call Human Importance-aware Network Tuning (HINT) that effectively leverages human supervision to improve visual grounding. HINT constrains deep networks to be sensitive to the same input regions as humans. Crucially, our approach optimizes the alignment between human attention maps and gradient-based network importances - ensuring that models learn not just to look at but rather rely on visual concepts that humans found relevant for a task when making predictions. We demonstrate our approach on Visual Question Answering and Image Captioning tasks, achieving state of-the-art for the VQA-CP dataset which penalizes over-reliance on language priors.
EvalAI: Towards Better Evaluation Systems for AI Agents
Feb 10, 2019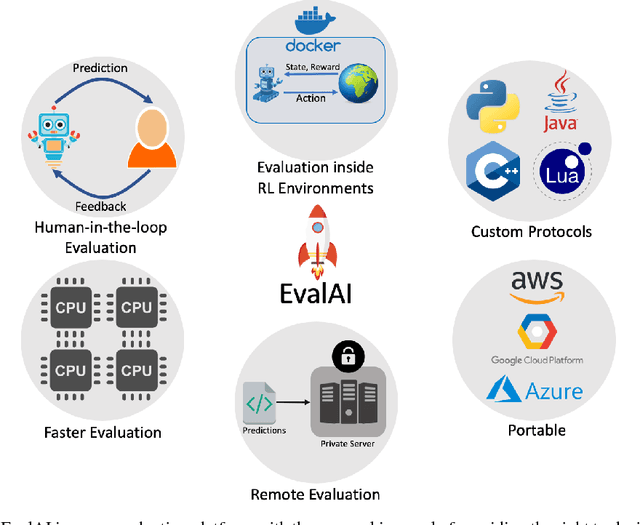

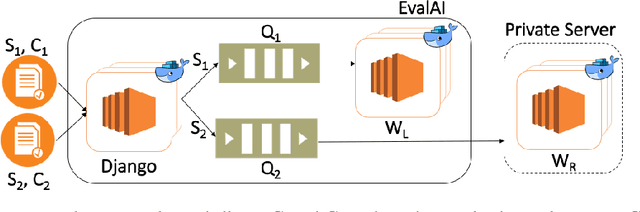
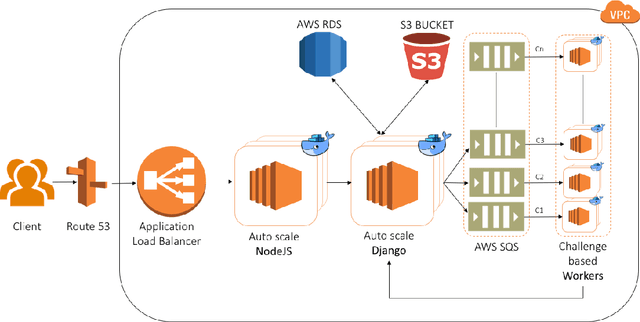
We introduce EvalAI, an open source platform for evaluating and comparing machine learning (ML) and artificial intelligence algorithms (AI) at scale. EvalAI is built to provide a scalable solution to the research community to fulfill the critical need of evaluating machine learning models and agents acting in an environment against annotations or with a human-in-the-loop. This will help researchers, students, and data scientists to create, collaborate, and participate in AI challenges organized around the globe. By simplifying and standardizing the process of benchmarking these models, EvalAI seeks to lower the barrier to entry for participating in the global scientific effort to push the frontiers of machine learning and artificial intelligence, thereby increasing the rate of measurable progress in this domain.
Audio-Visual Scene-Aware Dialog
Jan 25, 2019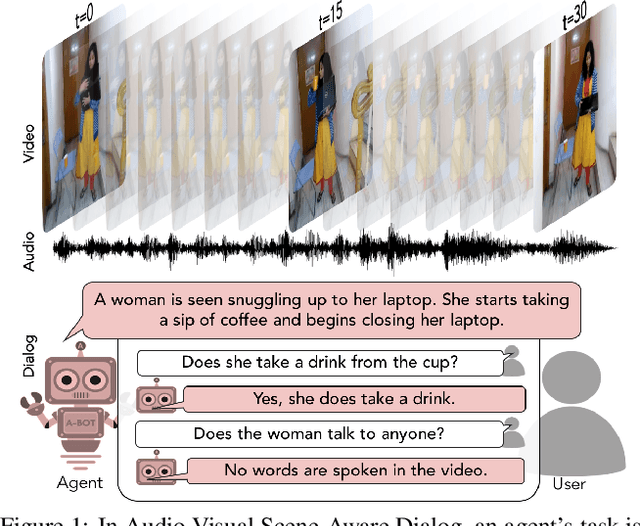
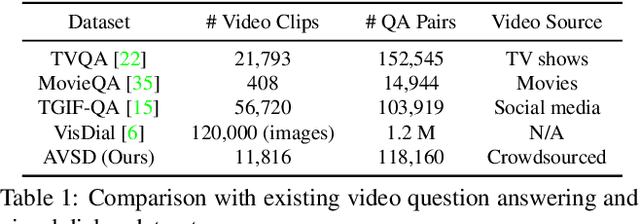


We introduce the task of scene-aware dialog. Given a follow-up question in an ongoing dialog about a video, our goal is to generate a complete and natural response to a question given (a) an input video, and (b) the history of previous turns in the dialog. To succeed, agents must ground the semantics in the video and leverage contextual cues from the history of the dialog to answer the question. To benchmark this task, we introduce the Audio Visual Scene-Aware Dialog (AVSD) dataset. For each of more than 11,000 videos of human actions for the Charades dataset. Our dataset contains a dialog about the video, plus a final summary of the video by one of the dialog participants. We train several baseline systems for this task and evaluate the performance of the trained models using several qualitative and quantitative metrics. Our results indicate that the models must comprehend all the available inputs (video, audio, question and dialog history) to perform well on this dataset.
nocaps: novel object captioning at scale
Dec 20, 2018
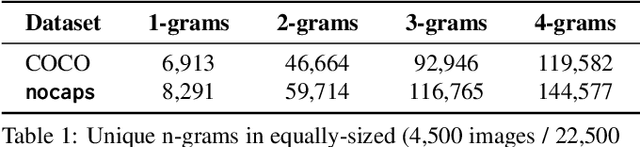
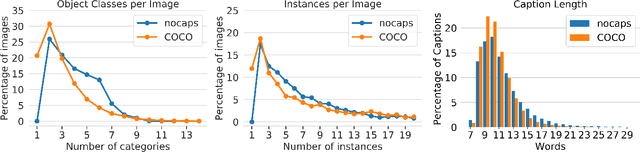
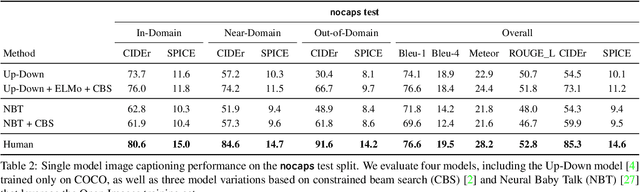
Image captioning models have achieved impressive results on datasets containing limited visual concepts and large amounts of paired image-caption training data. However, if these models are to ever function in the wild, a much larger variety of visual concepts must be learned, ideally from less supervision. To encourage the development of image captioning models that can learn visual concepts from alternative data sources, such as object detection datasets, we present the first large-scale benchmark for this task. Dubbed 'nocaps', for novel object captioning at scale, our benchmark consists of 166,100 human-generated captions describing 15,100 images from the Open Images validation and test sets. The associated training data consists of COCO image-caption pairs, plus Open Images image-level labels and object bounding boxes. Since Open Images contains many more classes than COCO, more than 500 object classes seen in test images have no training captions (hence, nocaps). We evaluate several existing approaches to novel object captioning on our challenging benchmark. In automatic evaluations these approaches show modest improvements over a strong baseline trained only on image-caption data. However, even when using ground-truth object detections, the results are significantly weaker than our human baseline - indicating substantial room for improvement.