 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Apr 28, 2025



Large Language Models (LLMs) have demonstrated remarkable prowess in generating contextually coherent responses, yet their fixed context windows pose fundamental challenges for maintaining consistency over prolonged multi-session dialogues. We introduce Mem0, a scalable memory-centric architecture that addresses this issue by dynamically extracting, consolidating, and retrieving salient information from ongoing conversations. Building on this foundation, we further propose an enhanced variant that leverages graph-based memory representations to capture complex relational structures among conversational elements. Through comprehensive evaluations on LOCOMO benchmark, we systematically compare our approaches against six baseline categories: (i) established memory-augmented systems, (ii) retrieval-augmented generation (RAG) with varying chunk sizes and k-values, (iii) a full-context approach that processes the entire conversation history, (iv) an open-source memory solution, (v) a proprietary model system, and (vi) a dedicated memory management platform. Empirical results show that our methods consistently outperform all existing memory systems across four question categories: single-hop, temporal, multi-hop, and open-domain. Notably, Mem0 achieves 26% relative improvements in the LLM-as-a-Judge metric over OpenAI, while Mem0 with graph memory achieves around 2% higher overall score than the base configuration. Beyond accuracy gains, we also markedly reduce computational overhead compared to full-context method. In particular, Mem0 attains a 91% lower p95 latency and saves more than 90% token cost, offering a compelling balance between advanced reasoning capabilities and practical deployment constraints. Our findings highlight critical role of structured, persistent memory mechanisms for long-term conversational coherence, paving the way for more reliable and efficient LLM-driven AI agents.
EvalAI: Towards Better Evaluation Systems for AI Agents
Feb 10, 2019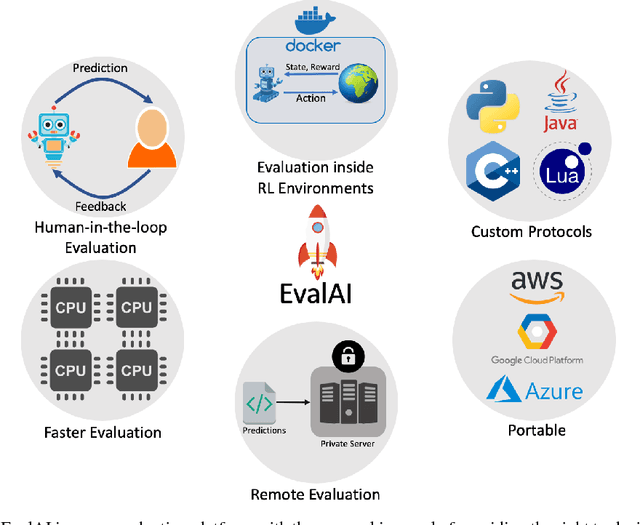

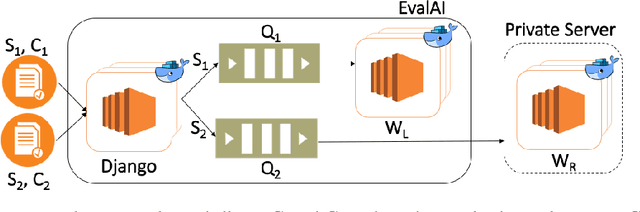
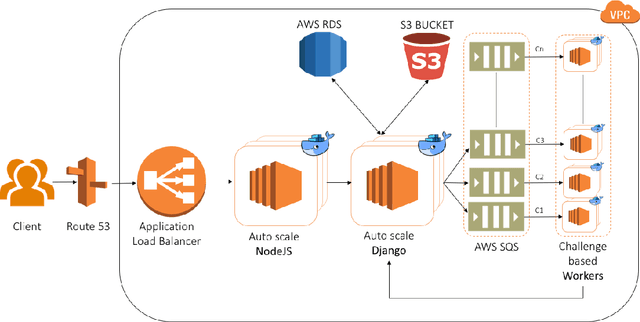
We introduce EvalAI, an open source platform for evaluating and comparing machine learning (ML) and artificial intelligence algorithms (AI) at scale. EvalAI is built to provide a scalable solution to the research community to fulfill the critical need of evaluating machine learning models and agents acting in an environment against annotations or with a human-in-the-loop. This will help researchers, students, and data scientists to create, collaborate, and participate in AI challenges organized around the globe. By simplifying and standardizing the process of benchmarking these models, EvalAI seeks to lower the barrier to entry for participating in the global scientific effort to push the frontiers of machine learning and artificial intelligence, thereby increasing the rate of measurable progress in this domain.
Do Explanations make VQA Models more Predictable to a Human?
Oct 29, 2018

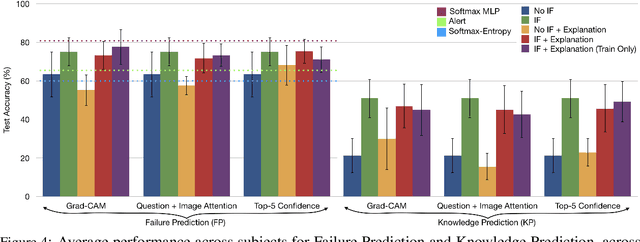
A rich line of research attempts to make deep neural networks more transparent by generating human-interpretable 'explanations' of their decision process, especially for interactive tasks like Visual Question Answering (VQA). In this work, we analyze if existing explanations indeed make a VQA model -- its responses as well as failures -- more predictable to a human. Surprisingly, we find that they do not. On the other hand, we find that human-in-the-loop approaches that treat the model as a black-box do.
Fabrik: An Online Collaborative Neural Network Editor
Oct 27, 2018
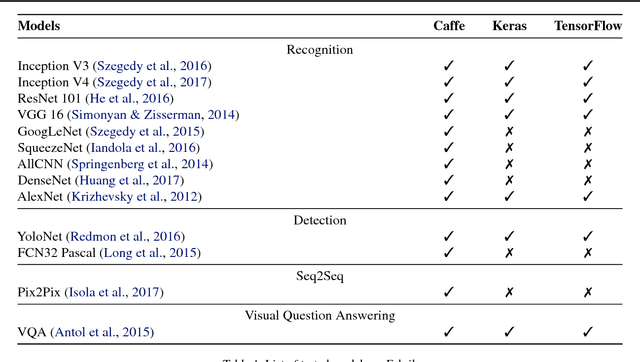
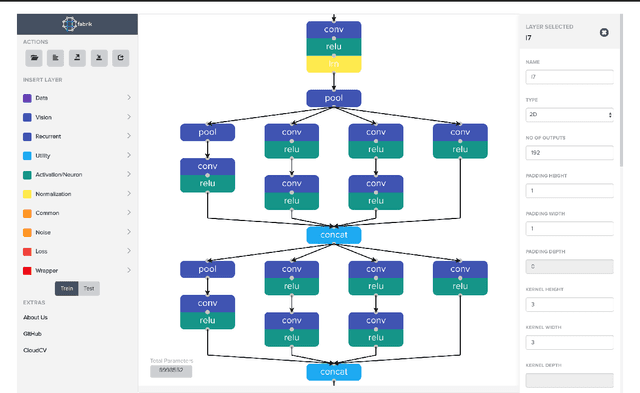

We present Fabrik, an online neural network editor that provides tools to visualize, edit, and share neural networks from within a browser. Fabrik provides a simple and intuitive GUI to import neural networks written in popular deep learning frameworks such as Caffe, Keras, and TensorFlow, and allows users to interact with, build, and edit models via simple drag and drop. Fabrik is designed to be framework agnostic and support high interoperability, and can be used to export models back to any supported framework. Finally, it provides powerful collaborative features to enable users to iterate over model design remotely and at scale.
It Takes Two to Tango: Towards Theory of AI's Mind
Oct 02, 2017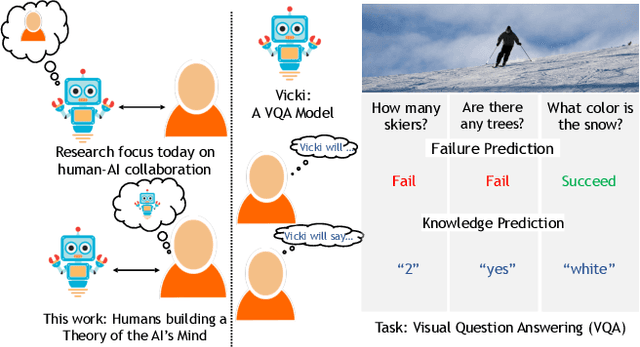

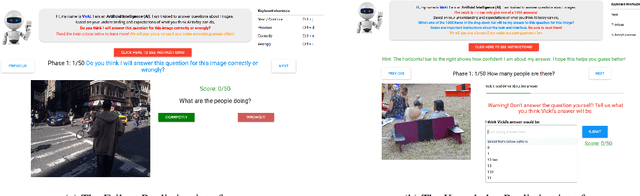
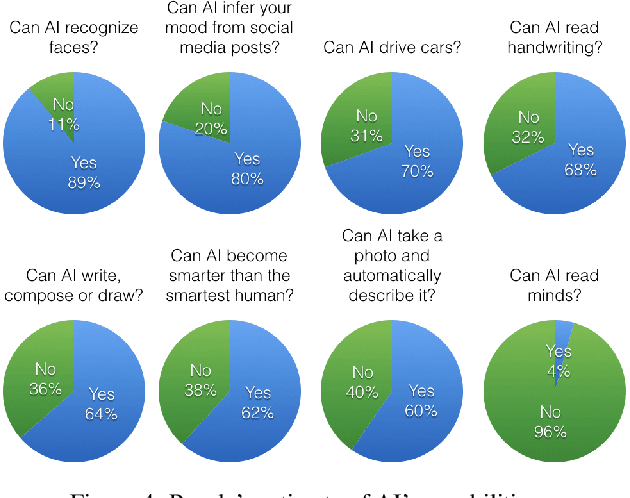
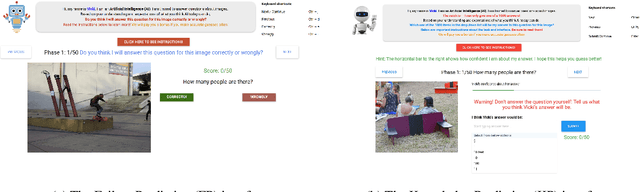
Theory of Mind is the ability to attribute mental states (beliefs, intents, knowledge, perspectives, etc.) to others and recognize that these mental states may differ from one's own. Theory of Mind is critical to effective communication and to teams demonstrating higher collective performance. To effectively leverage the progress in Artificial Intelligence (AI) to make our lives more productive, it is important for humans and AI to work well together in a team. Traditionally, there has been much emphasis on research to make AI more accurate, and (to a lesser extent) on having it better understand human intentions, tendencies, beliefs, and contexts. The latter involves making AI more human-like and having it develop a theory of our minds. In this work, we argue that for human-AI teams to be effective, humans must also develop a theory of AI's mind (ToAIM) - get to know its strengths, weaknesses, beliefs, and quirks. We instantiate these ideas within the domain of Visual Question Answering (VQA). We find that using just a few examples (50), lay people can be trained to better predict responses and oncoming failures of a complex VQA model. We further evaluate the role existing explanation (or interpretability) modalities play in helping humans build ToAIM. Explainable AI has received considerable scientific and popular attention in recent times. Surprisingly, we find that having access to the model's internal states - its confidence in its top-k predictions, explicit or implicit attention maps which highlight regions in the image (and words in the question) the model is looking at (and listening to) while answering a question about an image - do not help people better predict its behavior.
Evaluating Visual Conversational Agents via Cooperative Human-AI Games
Aug 17, 2017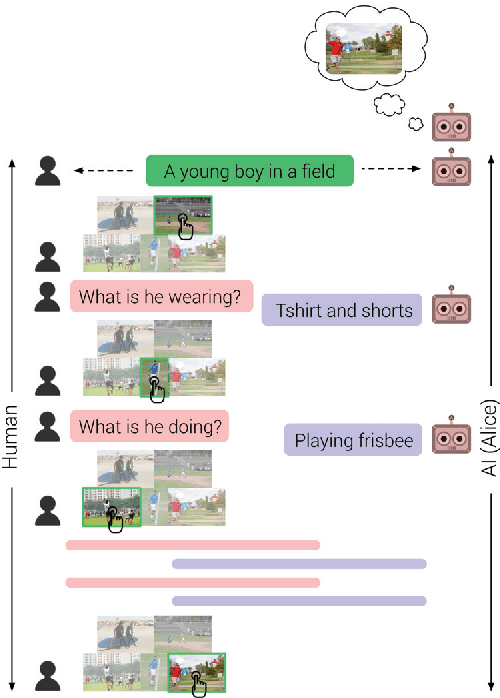


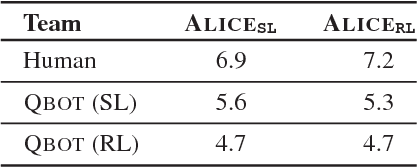
As AI continues to advance, human-AI teams are inevitable. However, progress in AI is routinely measured in isolation, without a human in the loop. It is crucial to benchmark progress in AI, not just in isolation, but also in terms of how it translates to helping humans perform certain tasks, i.e., the performance of human-AI teams. In this work, we design a cooperative game - GuessWhich - to measure human-AI team performance in the specific context of the AI being a visual conversational agent. GuessWhich involves live interaction between the human and the AI. The AI, which we call ALICE, is provided an image which is unseen by the human. Following a brief description of the image, the human questions ALICE about this secret image to identify it from a fixed pool of images. We measure performance of the human-ALICE team by the number of guesses it takes the human to correctly identify the secret image after a fixed number of dialog rounds with ALICE. We compare performance of the human-ALICE teams for two versions of ALICE. Our human studies suggest a counterintuitive trend - that while AI literature shows that one version outperforms the other when paired with an AI questioner bot, we find that this improvement in AI-AI performance does not translate to improved human-AI performance. This suggests a mismatch between benchmarking of AI in isolation and in the context of human-AI teams.
Visual Dialog
Aug 01, 2017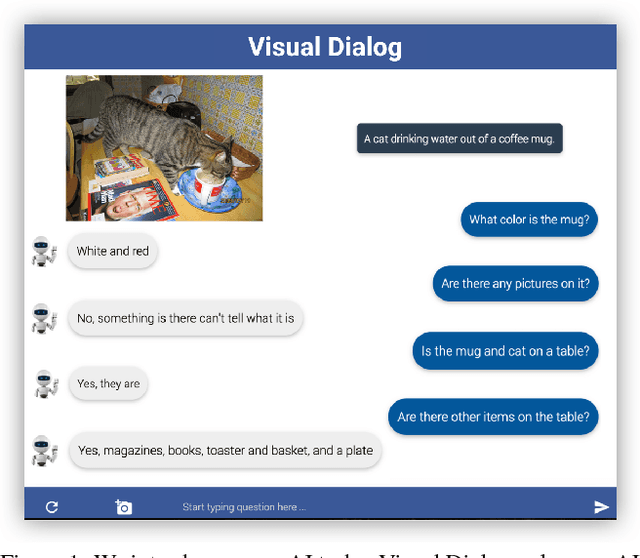
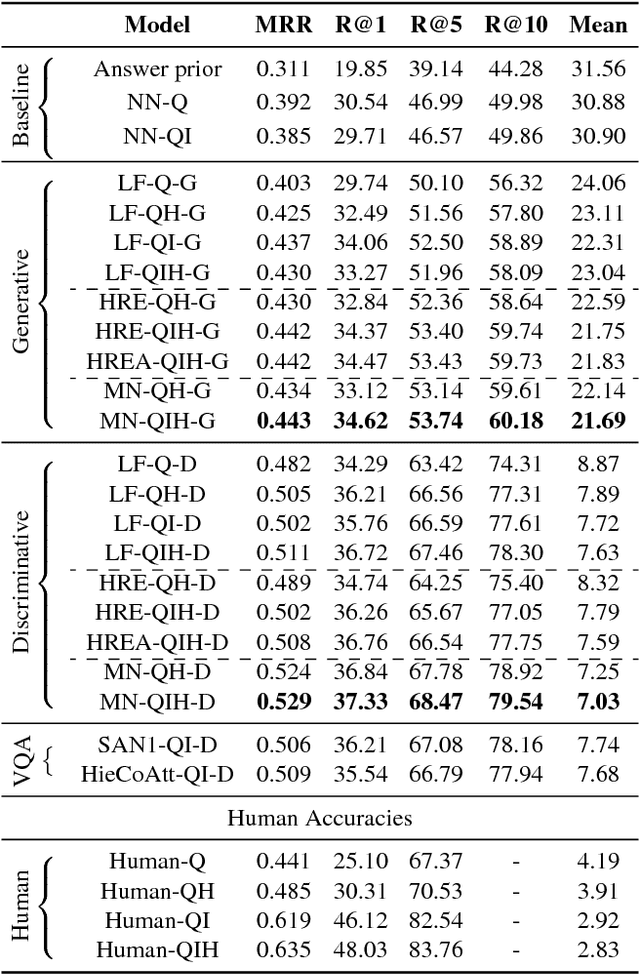


We introduce the task of Visual Dialog, which requires an AI agent to hold a meaningful dialog with humans in natural, conversational language about visual content. Specifically, given an image, a dialog history, and a question about the image, the agent has to ground the question in image, infer context from history, and answer the question accurately. Visual Dialog is disentangled enough from a specific downstream task so as to serve as a general test of machine intelligence, while being grounded in vision enough to allow objective evaluation of individual responses and benchmark progress. We develop a novel two-person chat data-collection protocol to curate a large-scale Visual Dialog dataset (VisDial). VisDial v0.9 has been released and contains 1 dialog with 10 question-answer pairs on ~120k images from COCO, with a total of ~1.2M dialog question-answer pairs. We introduce a family of neural encoder-decoder models for Visual Dialog with 3 encoders -- Late Fusion, Hierarchical Recurrent Encoder and Memory Network -- and 2 decoders (generative and discriminative), which outperform a number of sophisticated baselines. We propose a retrieval-based evaluation protocol for Visual Dialog where the AI agent is asked to sort a set of candidate answers and evaluated on metrics such as mean-reciprocal-rank of human response. We quantify gap between machine and human performance on the Visual Dialog task via human studies. Putting it all together, we demonstrate the first 'visual chatbot'! Our dataset, code, trained models and visual chatbot are available on https://visualdialog.org