 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Learning Non-Convergent Non-Persistent Short-Run MCMC Toward Energy-Based Model
May 27, 2019
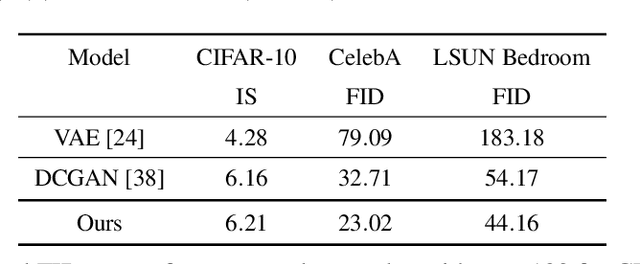

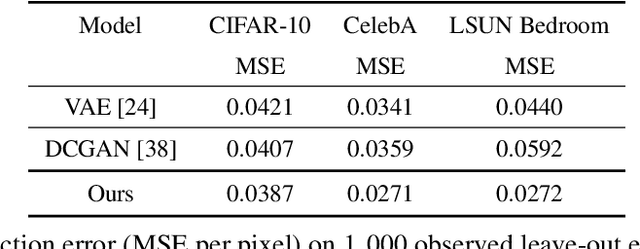
This paper studies a curious phenomenon in learning energy-based model (EBM) using MCMC. In each learning iteration, we generate synthesized examples by running a non-convergent, non-mixing, and non-persistent short-run MCMC toward the current model, always starting from the same initial distribution such as uniform noise distribution, and always running a fixed number of MCMC steps. After generating synthesized examples, we then update the model parameters according to the maximum likelihood learning gradient, as if the synthesized examples are fair samples from the current model. We treat this non-convergent short-run MCMC as a learned generator model or a flow model. We provide arguments for treating the learned non-convergent short-run MCMC as a valid model. We show that the learned short-run MCMC is capable of generating realistic images. More interestingly, unlike traditional EBM or MCMC, the learned short-run MCMC is capable of reconstructing observed images and interpolating between images, like generator or flow models. The code can be found in the Appendix.
On the Anatomy of MCMC-based Maximum Likelihood Learning of Energy-Based Models
Apr 11, 2019

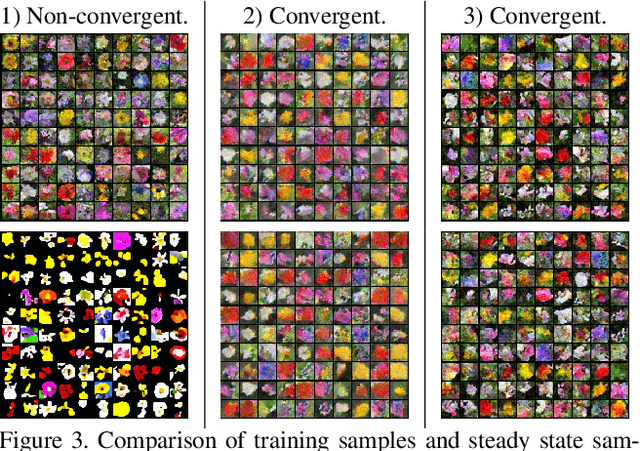
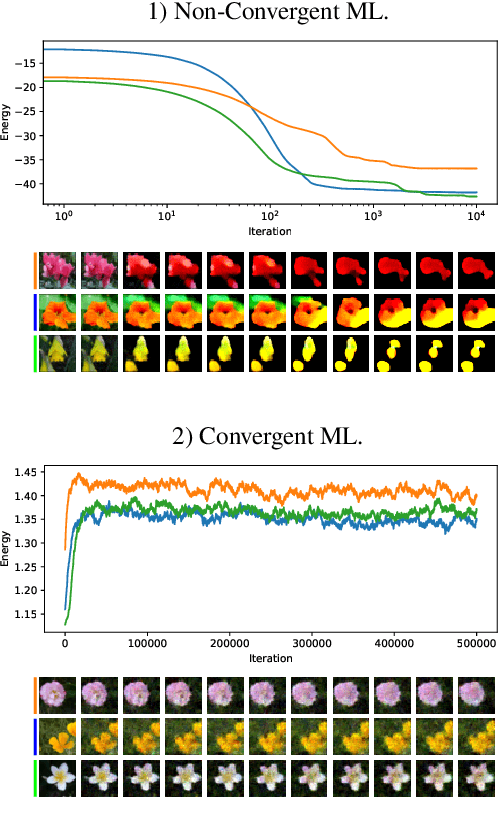
This study investigates the effects of Markov Chain Monte Carlo (MCMC) sampling in unsupervised Maximum Likelihood (ML) learning. Our attention is restricted to the family of unnormalized probability densities for which the negative log density (or energy function) is a ConvNet. In general, we find that many of the techniques used to stabilize training in previous studies can have the opposite effect. Stable ML learning with a ConvNet potential can be achieved with only a few hyper-parameters and no regularization. Using this minimal framework, we identify a variety of ML learning outcomes that depend on the implementation of MCMC sampling. On one hand, we show that it is easy to train an energy-based model which can sample realistic images with short-run Langevin. ML can be effective and stable even when MCMC samples have much higher energy than true steady-state samples throughout training. Based on this insight, we introduce an ML method with purely noise-initialized MCMC, high-quality short-run synthesis, and the same budget as ML with informative MCMC initialization such as CD or PCD. Unlike previous models, our model can obtain realistic high-diversity samples from a noise signal after training with no auxiliary networks. On the other hand, ConvNet potentials learned with highly non-convergent MCMC do not have a valid steady-state and cannot be considered approximate unnormalized densities of the training data because long-run MCMC samples differ greatly from observed images. We show that it is much harder to train a ConvNet potential to learn a steady-state over realistic images. To our knowledge, long-run MCMC samples of all previous models lose the realism of short-run samples. With correct tuning of Langevin noise, we train the first ConvNet potentials for which long-run and steady-state MCMC samples are realistic images.
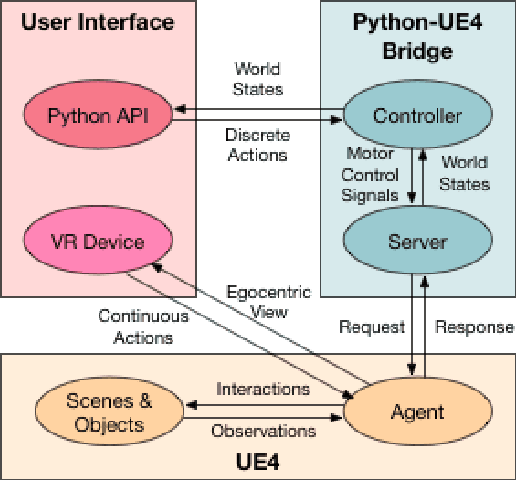
VRGym: A Virtual Testbed for Physical and Interactive AI
Apr 02, 2019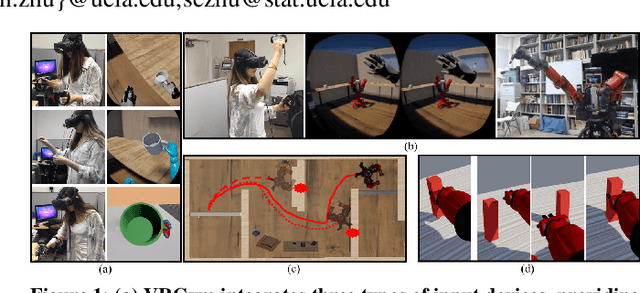



We propose VRGym, a virtual reality testbed for realistic human-robot interaction. Different from existing toolkits and virtual reality environments, the VRGym emphasizes on building and training both physical and interactive agents for robotics, machine learning, and cognitive science. VRGym leverages mechanisms that can generate diverse 3D scenes with high realism through physics-based simulation. We demonstrate that VRGym is able to (i) collect human interactions and fine manipulations, (ii) accommodate various robots with a ROS bridge, (iii) support experiments for human-robot interaction, and (iv) provide toolkits for training the state-of-the-art machine learning algorithms. We hope VRGym can help to advance general-purpose robotics and machine learning agents, as well as assisting human studies in the field of cognitive science.
VRKitchen: an Interactive 3D Virtual Environment for Task-oriented Learning
Mar 13, 2019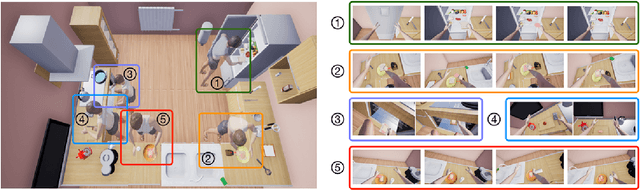
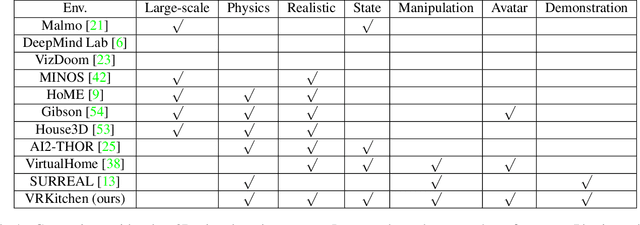
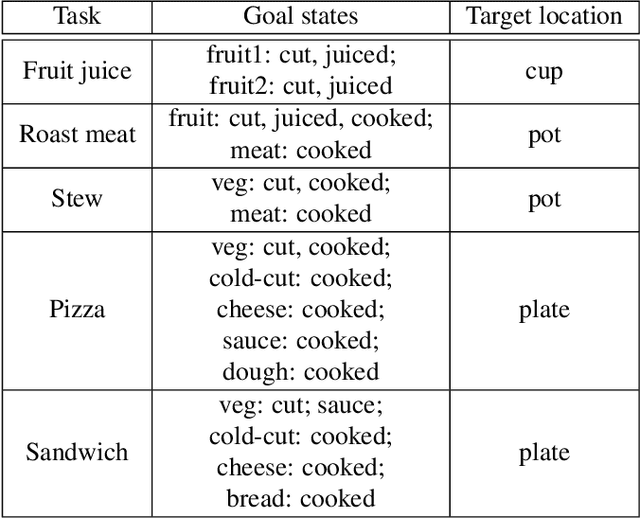
One of the main challenges of advancing task-oriented learning such as visual task planning and reinforcement learning is the lack of realistic and standardized environments for training and testing AI agents. Previously, researchers often relied on ad-hoc lab environments. There have been recent advances in virtual systems built with 3D physics engines and photo-realistic rendering for indoor and outdoor environments, but the embodied agents in those systems can only conduct simple interactions with the world (e.g., walking around, moving objects, etc.). Most of the existing systems also do not allow human participation in their simulated environments. In this work, we design and implement a virtual reality (VR) system, VRKitchen, with integrated functions which i) enable embodied agents powered by modern AI methods (e.g., planning, reinforcement learning, etc.) to perform complex tasks involving a wide range of fine-grained object manipulations in a realistic environment, and ii) allow human teachers to perform demonstrations to train agents (i.e., learning from demonstration). We also provide standardized evaluation benchmarks and data collection tools to facilitate a broad use in research on task-oriented learning and beyond.
Visual Discourse Parsing
Mar 13, 2019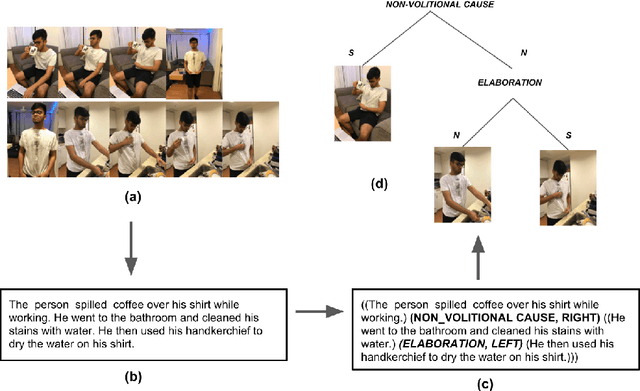

Text-level discourse parsing aims to unmask how two segments (or sentences) in the text are related to each other. We propose the task of Visual Discourse Parsing, which requires understanding discourse relations among scenes in a video. Here we use the term scene to refer to a subset of video frames that can better summarize the video. In order to collect a dataset for learning discourse cues from videos, one needs to manually identify the scenes from a large pool of video frames and then annotate the discourse relations between them. This is clearly a time consuming, expensive and tedious task. In this work, we propose an approach to identify discourse cues from the videos without the need to explicitly identify and annotate the scenes. We also present a novel dataset containing 310 videos and the corresponding discourse cues to evaluate our approach. We believe that many of the multi-discipline Artificial Intelligence problems such as Visual Dialog and Visual Storytelling would greatly benefit from the use of visual discourse cues.
Natural Language Interaction with Explainable AI Models
Mar 13, 2019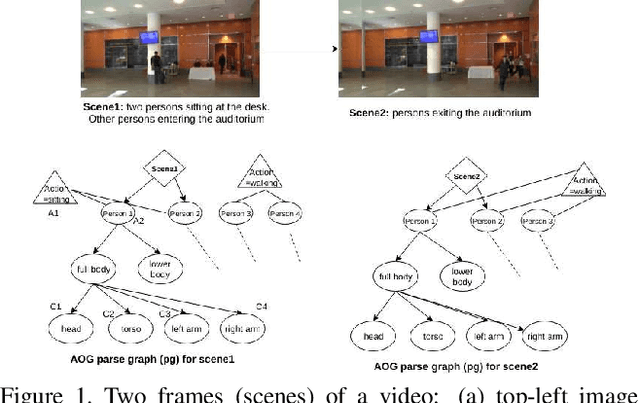
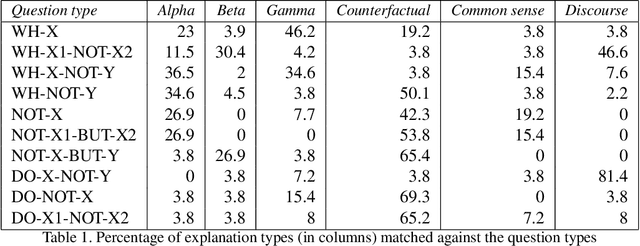
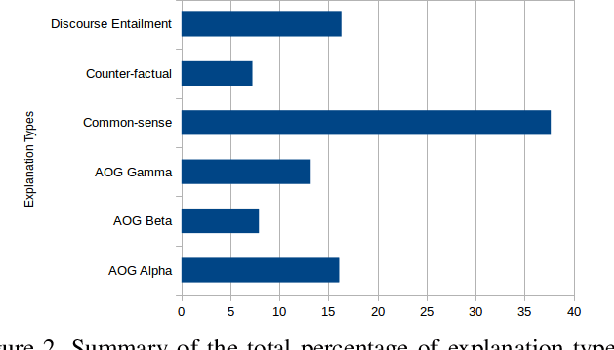
This paper presents an explainable AI (XAI) system that provides explanations for its predictions. The system consists of two key components -- namely, the prediction And-Or graph (AOG) model for recognizing and localizing concepts of interest in input data, and the XAI model for providing explanations to the user about the AOG's predictions. In this work, we focus on the XAI model specified to interact with the user in natural language, whereas the AOG's predictions are considered given and represented by the corresponding parse graphs (pg's) of the AOG. Our XAI model takes pg's as input and provides answers to the user's questions using the following types of reasoning: direct evidence (e.g., detection scores), part-based inference (e.g., detected parts provide evidence for the concept asked), and other evidences from spatio-temporal context (e.g., constraints from the spatio-temporal surround). We identify several correlations between user's questions and the XAI answers using Youtube Action dataset.
RAVEN: A Dataset for Relational and Analogical Visual rEasoNing
Mar 07, 2019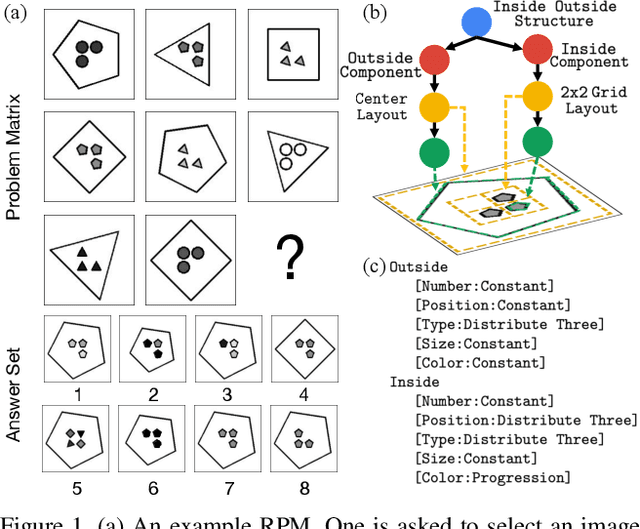
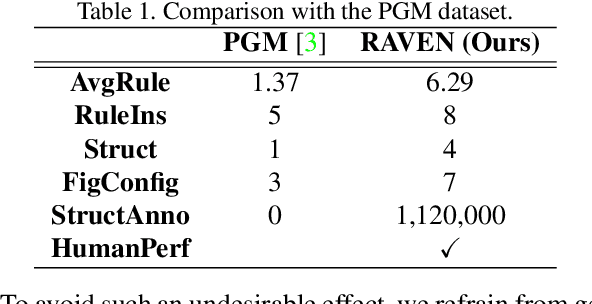
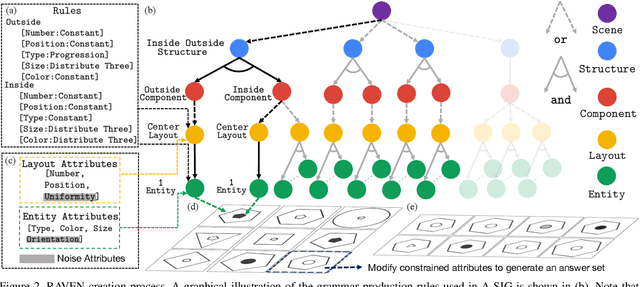
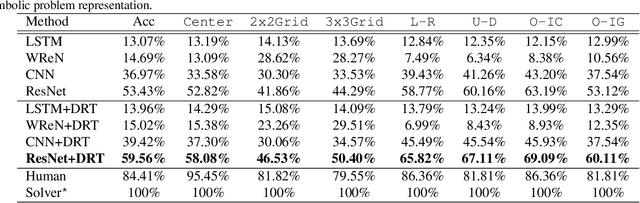
Dramatic progress has been witnessed in basic vision tasks involving low-level perception, such as object recognition, detection, and tracking. Unfortunately, there is still an enormous performance gap between artificial vision systems and human intelligence in terms of higher-level vision problems, especially ones involving reasoning. Earlier attempts in equipping machines with high-level reasoning have hovered around Visual Question Answering (VQA), one typical task associating vision and language understanding. In this work, we propose a new dataset, built in the context of Raven's Progressive Matrices (RPM) and aimed at lifting machine intelligence by associating vision with structural, relational, and analogical reasoning in a hierarchical representation. Unlike previous works in measuring abstract reasoning using RPM, we establish a semantic link between vision and reasoning by providing structure representation. This addition enables a new type of abstract reasoning by jointly operating on the structure representation. Machine reasoning ability using modern computer vision is evaluated in this newly proposed dataset. Additionally, we also provide human performance as a reference. Finally, we show consistent improvement across all models by incorporating a simple neural module that combines visual understanding and structure reasoning.
Multimodal Conditional Learning with Fast Thinking Policy-like Model and Slow Thinking Planner-like Model
Feb 07, 2019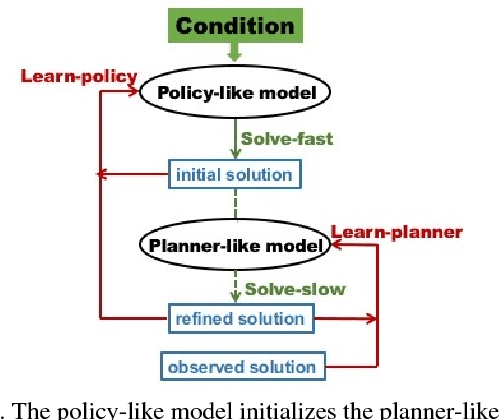
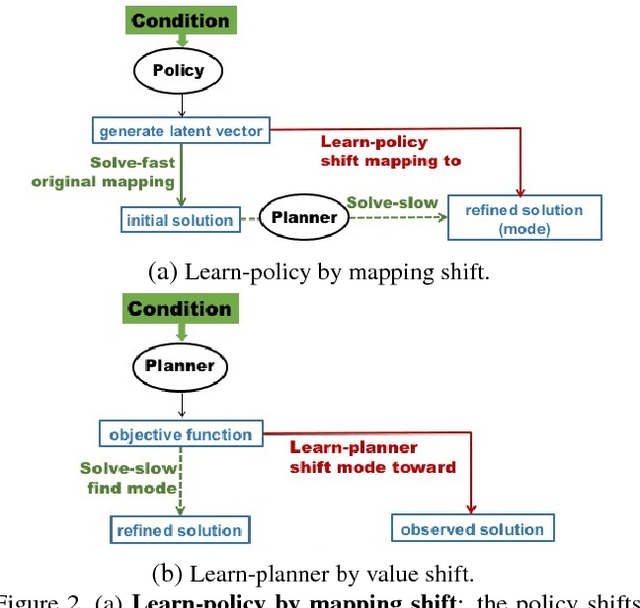


This paper studies the supervised learning of the conditional distribution of a high-dimensional output given an input, where the output and input belong to two different modalities, e.g., the output is an image and the input is a sketch. We solve this problem by learning two models that bear similarities to those in reinforcement learning and optimal control. One model is policy-like. It generates the output directly by a non-linear transformation of the input and a noise vector. This amounts to fast thinking because the conditional generation is accomplished by direct sampling. The other model is planner-like. It learns an objective function in the form of a conditional energy function, so that the output can be generated by optimizing the objective function, or more rigorously by sampling from the conditional energy-based model. This amounts to slow thinking because the sampling process is accomplished by an iterative algorithm such as Langevin dynamics. We propose to learn the two models jointly, where the fast thinking policy-like model serves to initialize the sampling of the slow thinking planner-like model, and the planner-like model refines the initial output by an iterative algorithm. The planner-like model learns from the difference between the refined output and the observed output, while the policy-like model learns from how the planner-like model refines its initial output. We demonstrate the effectiveness of the proposed method on various image generation tasks.
Interpretable CNNs
Jan 08, 2019
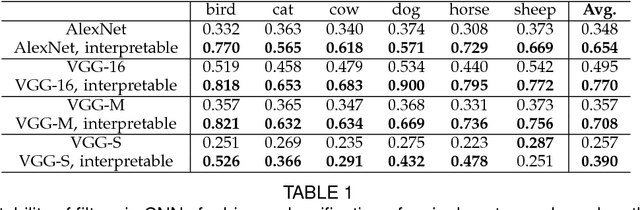
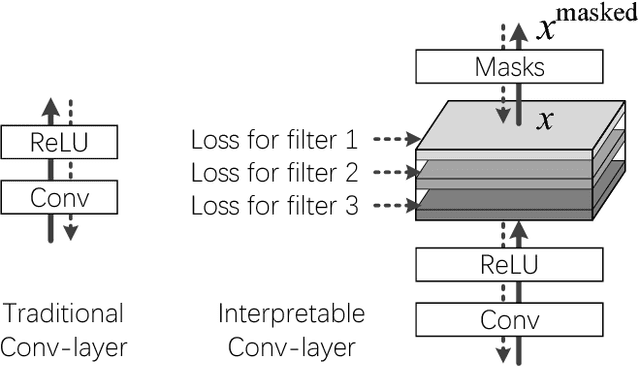

This paper proposes a generic method to learn interpretable convolutional filters in a deep convolutional neural network (CNN), where each interpretable filter encodes features of a specific object part. Our method does not require additional annotations of object parts or textures for supervision. Instead, we use the same training data as traditional CNNs. Our method automatically assigns each interpretable filter in a high conv-layer with an object part of a certain category during the learning process. Such explicit knowledge representations in conv-layers of CNN help people clarify the logic encoded in the CNN, i.e., answering what patterns the CNN extracts from an input image and uses for prediction. We have tested our method using different benchmark CNNs with various structures to demonstrate the broad applicability of our method. Experiments have shown that our interpretable filters are much more semantically meaningful than traditional filters.
Explaining AlphaGo: Interpreting Contextual Effects in Neural Networks
Jan 08, 2019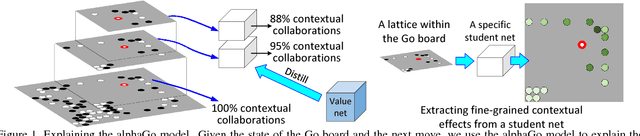
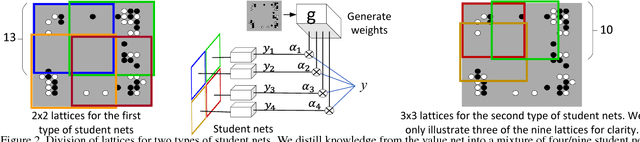
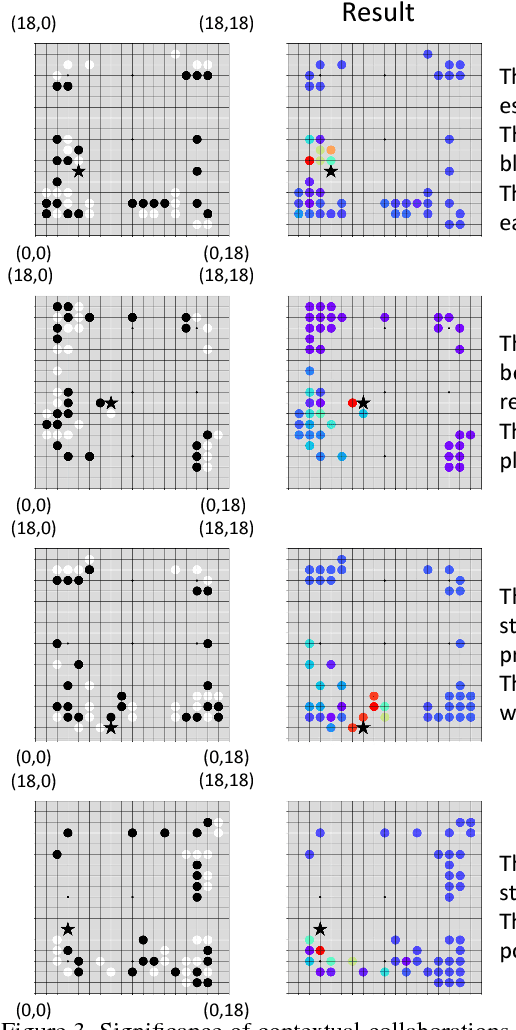
In this paper, we propose to disentangle and interpret contextual effects that are encoded in a pre-trained deep neural network. We use our method to explain the gaming strategy of the alphaGo Zero model. Unlike previous studies that visualized image appearances corresponding to the network output or a neural activation only from a global perspective, our research aims to clarify how a certain input unit (dimension) collaborates with other units (dimensions) to constitute inference patterns of the neural network and thus contribute to the network output. The analysis of local contextual effects w.r.t. certain input units is of special values in real applications. Explaining the logic of the alphaGo Zero model is a typical application. In experiments, our method successfully disentangled the rationale of each move during the Go game.