 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransFollower: Long-Sequence Car-Following Trajectory Prediction through Transformer
Feb 04, 2022Car-following refers to a control process in which the following vehicle (FV) tries to keep a safe distance between itself and the lead vehicle (LV) by adjusting its acceleration in response to the actions of the vehicle ahead. The corresponding car-following models, which describe how one vehicle follows another vehicle in the traffic flow, form the cornerstone for microscopic traffic simulation and intelligent vehicle development. One major motivation of car-following models is to replicate human drivers' longitudinal driving trajectories. To model the long-term dependency of future actions on historical driving situations, we developed a long-sequence car-following trajectory prediction model based on the attention-based Transformer model. The model follows a general format of encoder-decoder architecture. The encoder takes historical speed and spacing data as inputs and forms a mixed representation of historical driving context using multi-head self-attention. The decoder takes the future LV speed profile as input and outputs the predicted future FV speed profile in a generative way (instead of an auto-regressive way, avoiding compounding errors). Through cross-attention between encoder and decoder, the decoder learns to build a connection between historical driving and future LV speed, based on which a prediction of future FV speed can be obtained. We train and test our model with 112,597 real-world car-following events extracted from the Shanghai Naturalistic Driving Study (SH-NDS). Results show that the model outperforms the traditional intelligent driver model (IDM), a fully connected neural network model, and a long short-term memory (LSTM) based model in terms of long-sequence trajectory prediction accuracy. We also visualized the self-attention and cross-attention heatmaps to explain how the model derives its predictions.
Active Multi-Task Representation Learning
Feb 02, 2022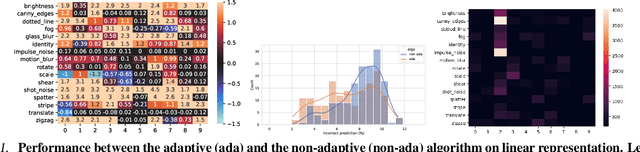
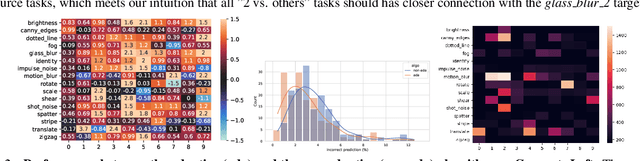
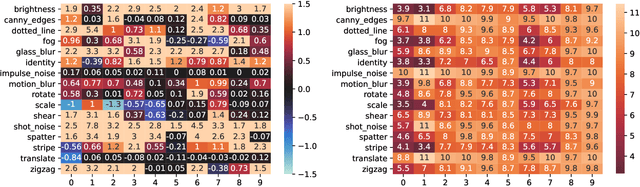
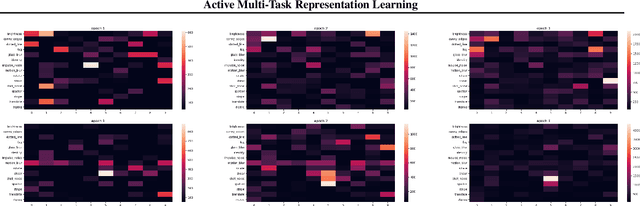
To leverage the power of big data from source tasks and overcome the scarcity of the target task samples, representation learning based on multi-task pretraining has become a standard approach in many applications. However, up until now, choosing which source tasks to include in the multi-task learning has been more art than science. In this paper, we give the first formal study on resource task sampling by leveraging the techniques from active learning. We propose an algorithm that iteratively estimates the relevance of each source task to the target task and samples from each source task based on the estimated relevance. Theoretically, we show that for the linear representation class, to achieve the same error rate, our algorithm can save up to a \textit{number of source tasks} factor in the source task sample complexity, compared with the naive uniform sampling from all source tasks. We also provide experiments on real-world computer vision datasets to illustrate the effectiveness of our proposed method on both linear and convolutional neural network representation classes. We believe our paper serves as an important initial step to bring techniques from active learning to representation learning.
Reward-Free RL is No Harder Than Reward-Aware RL in Linear Markov Decision Processes
Jan 26, 2022Reward-free reinforcement learning (RL) considers the setting where the agent does not have access to a reward function during exploration, but must propose a near-optimal policy for an arbitrary reward function revealed only after exploring. In the the tabular setting, it is well known that this is a more difficult problem than PAC RL -- where the agent has access to the reward function during exploration -- with optimal sample complexities in the two settings differing by a factor of $|\mathcal{S}|$, the size of the state space. We show that this separation does not exist in the setting of linear MDPs. We first develop a computationally efficient algorithm for reward-free RL in a $d$-dimensional linear MDP with sample complexity scaling as $\mathcal{O}(d^2/\epsilon^2)$. We then show a matching lower bound of $\Omega(d^2/\epsilon^2)$ on PAC RL. To our knowledge, our approach is the first computationally efficient algorithm to achieve optimal $d$ dependence in linear MDPs, even in the single-reward PAC setting. Our algorithm relies on a novel procedure which efficiently traverses a linear MDP, collecting samples in any given "feature direction", and enjoys a sample complexity scaling optimally in the (linear MDP equivalent of the) maximal state visitation probability. We show that this exploration procedure can also be applied to solve the problem of obtaining "well-conditioned" covariates in linear MDPs.
When is Offline Two-Player Zero-Sum Markov Game Solvable?
Jan 10, 2022We study what dataset assumption permits solving offline two-player zero-sum Markov game. In stark contrast to the offline single-agent Markov decision process, we show that the single strategy concentration assumption is insufficient for learning the Nash equilibrium (NE) strategy in offline two-player zero-sum Markov games. On the other hand, we propose a new assumption named unilateral concentration and design a pessimism-type algorithm that is provably efficient under this assumption. In addition, we show that the unilateral concentration assumption is necessary for learning an NE strategy. Furthermore, our algorithm can achieve minimax sample complexity without any modification for two widely studied settings: dataset with uniform concentration assumption and turn-based Markov game. Our work serves as an important initial step towards understanding offline multi-agent reinforcement learning.
Nearly Optimal Policy Optimization with Stable at Any Time Guarantee
Dec 22, 2021
Policy optimization methods are one of the most widely used classes of Reinforcement Learning (RL) algorithms. However, theoretical understanding of these methods remains insufficient. Even in the episodic (time-inhomogeneous) tabular setting, the state-of-the-art theoretical result of policy-based method in \citet{shani2020optimistic} is only $\tilde{O}(\sqrt{S^2AH^4K})$ where $S$ is the number of states, $A$ is the number of actions, $H$ is the horizon, and $K$ is the number of episodes, and there is a $\sqrt{SH}$ gap compared with the information theoretic lower bound $\tilde{\Omega}(\sqrt{SAH^3K})$. To bridge such a gap, we propose a novel algorithm Reference-based Policy Optimization with Stable at Any Time guarantee (\algnameacro), which features the property "Stable at Any Time". We prove that our algorithm achieves $\tilde{O}(\sqrt{SAH^3K} + \sqrt{AH^4K})$ regret. When $S > H$, our algorithm is minimax optimal when ignoring logarithmic factors. To our best knowledge, RPO-SAT is the first computationally efficient, nearly minimax optimal policy-based algorithm for tabular RL.
First-Order Regret in Reinforcement Learning with Linear Function Approximation: A Robust Estimation Approach
Dec 07, 2021Obtaining first-order regret bounds -- regret bounds scaling not as the worst-case but with some measure of the performance of the optimal policy on a given instance -- is a core question in sequential decision-making. While such bounds exist in many settings, they have proven elusive in reinforcement learning with large state spaces. In this work we address this gap, and show that it is possible to obtain regret scaling as $\mathcal{O}(\sqrt{V_1^\star K})$ in reinforcement learning with large state spaces, namely the linear MDP setting. Here $V_1^\star$ is the value of the optimal policy and $K$ is the number of episodes. We demonstrate that existing techniques based on least squares estimation are insufficient to obtain this result, and instead develop a novel robust self-normalized concentration bound based on the robust Catoni mean estimator, which may be of independent interest.
Towards Demystifying Representation Learning with Non-contrastive Self-supervision
Oct 11, 2021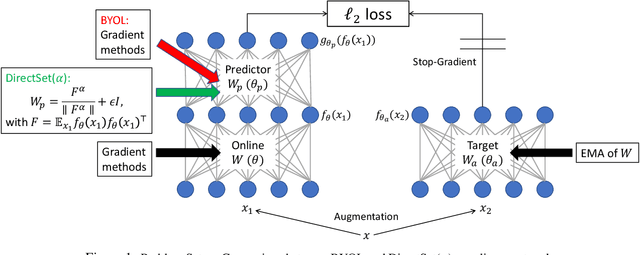
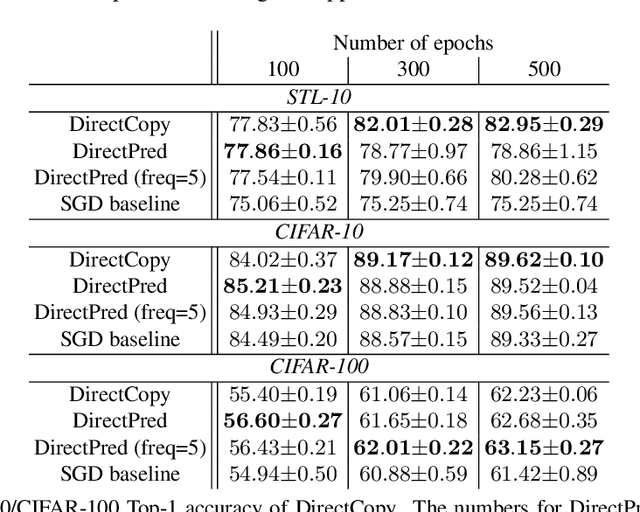
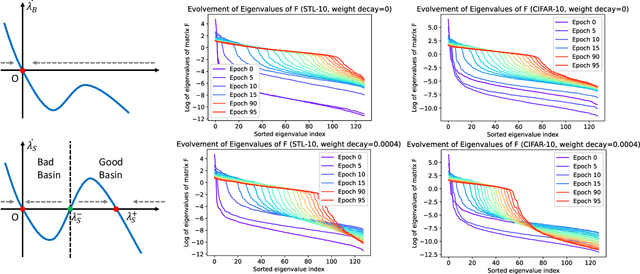
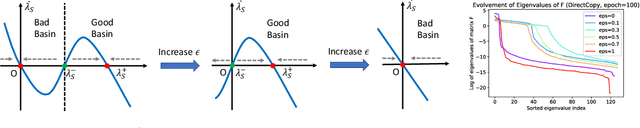
Non-contrastive methods of self-supervised learning (such as BYOL and SimSiam) learn representations by minimizing the distance between two views of the same image. These approaches have achieved remarkable performance in practice, but it is not well understood 1) why these methods do not collapse to the trivial solutions and 2) how the representation is learned. Tian el al. (2021) made an initial attempt on the first question and proposed DirectPred that sets the predictor directly. In our work, we analyze a generalized version of DirectPred, called DirectSet($\alpha$). We show that in a simple linear network, DirectSet($\alpha$) provably learns a desirable projection matrix and also reduces the sample complexity on downstream tasks. Our analysis suggests that weight decay acts as an implicit threshold that discard the features with high variance under augmentation, and keep the features with low variance. Inspired by our theory, we simplify DirectPred by removing the expensive eigen-decomposition step. On CIFAR-10, CIFAR-100, STL-10 and ImageNet, DirectCopy, our simpler and more computationally efficient algorithm, rivals or even outperforms DirectPred.
Gap-Dependent Bounds for Two-Player Markov Games
Jul 01, 2021As one of the most popular methods in the field of reinforcement learning, Q-learning has received increasing attention. Recently, there have been more theoretical works on the regret bound of algorithms that belong to the Q-learning class in different settings. In this paper, we analyze the cumulative regret when conducting Nash Q-learning algorithm on 2-player turn-based stochastic Markov games (2-TBSG), and propose the very first gap dependent logarithmic upper bounds in the episodic tabular setting. This bound matches the theoretical lower bound only up to a logarithmic term. Furthermore, we extend the conclusion to the discounted game setting with infinite horizon and propose a similar gap dependent logarithmic regret bound. Also, under the linear MDP assumption, we obtain another logarithmic regret for 2-TBSG, in both centralized and independent settings.
Global Convergence of Gradient Descent for Asymmetric Low-Rank Matrix Factorization
Jun 27, 2021We study the asymmetric low-rank factorization problem: \[\min_{\mathbf{U} \in \mathbb{R}^{m \times d}, \mathbf{V} \in \mathbb{R}^{n \times d}} \frac{1}{2}\|\mathbf{U}\mathbf{V}^\top -\mathbf{\Sigma}\|_F^2\] where $\mathbf{\Sigma}$ is a given matrix of size $m \times n$ and rank $d$. This is a canonical problem that admits two difficulties in optimization: 1) non-convexity and 2) non-smoothness (due to unbalancedness of $\mathbf{U}$ and $\mathbf{V}$). This is also a prototype for more complex problems such as asymmetric matrix sensing and matrix completion. Despite being non-convex and non-smooth, it has been observed empirically that the randomly initialized gradient descent algorithm can solve this problem in polynomial time. Existing theories to explain this phenomenon all require artificial modifications of the algorithm, such as adding noise in each iteration and adding a balancing regularizer to balance the $\mathbf{U}$ and $\mathbf{V}$. This paper presents the first proof that shows randomly initialized gradient descent converges to a global minimum of the asymmetric low-rank factorization problem with a polynomial rate. For the proof, we develop 1) a new symmetrization technique to capture the magnitudes of the symmetry and asymmetry, and 2) a quantitative perturbation analysis to approximate matrix derivatives. We believe both are useful for other related non-convex problems.
A Unified Framework for Conservative Exploration
Jun 22, 2021
We study bandits and reinforcement learning (RL) subject to a conservative constraint where the agent is asked to perform at least as well as a given baseline policy. This setting is particular relevant in real-world domains including digital marketing, healthcare, production, finance, etc. For multi-armed bandits, linear bandits and tabular RL, specialized algorithms and theoretical analyses were proposed in previous work. In this paper, we present a unified framework for conservative bandits and RL, in which our core technique is to calculate the necessary and sufficient budget obtained from running the baseline policy. For lower bounds, our framework gives a black-box reduction that turns a certain lower bound in the nonconservative setting into a new lower bound in the conservative setting. We strengthen the existing lower bound for conservative multi-armed bandits and obtain new lower bounds for conservative linear bandits, tabular RL and low-rank MDP. For upper bounds, our framework turns a certain nonconservative upper-confidence-bound (UCB) algorithm into a conservative algorithm with a simple analysis. For multi-armed bandits, linear bandits and tabular RL, our new upper bounds tighten or match existing ones with significantly simpler analyses. We also obtain a new upper bound for conservative low-rank MDP.