 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoForest: Automatically Generating Forest Plots from Biomedical Studies with End-to-End Evidence Extraction and Synthesis
Jun 01, 2026Systematic reviews rely on forest plots to synthesise quantitative evidence across biomedical studies, but generating them remains a fragmented and labour-intensive process. Researchers must interpret complex clinical texts, manually extract outcome data from trials, define appropriate interventions and comparators, harmonise inconsistent study designs, and carry out meta-analytic computations-typically using specialised software that demands structured inputs and domain expertise. While recent work has demonstrated that large language models can extract study-level data from unstructured text, no existing system automates the complete pipeline from raw documents to synthesised forest plots. To address this gap, we introduce AutoForest, the first end-to-end system that generates publication-ready forest plots directly from biomedical papers. Given one or more study papers, AutoForest automatically suggests ICO (Intervention, Comparator, Outcome) elements, extracts outcome data, performs statistical synthesis, and renders the final forest plot. We describe the system architecture, user interface and demonstrate its effectiveness on real-world examples through a user study involving clinicians, showing how AutoForest can accelerate evidence synthesis and substantially lower the barrier to conducting meta-analyses.
Output Composability of QLoRA PEFT Modules for Plug-and-Play Attribute-Controlled Text Generation
May 12, 2026Parameter-efficient fine-tuning (PEFT) techniques offer task-specific fine-tuning at a fraction of the cost of full fine-tuning, but require separate fine-tuning for every new task (combination). In this paper, we explore three ways of generalising beyond single-task training/inference: (i) training on combinations of multiple, related datasets; (ii) at inference, composing the weight matrices of separately trained PEFT modules; and (iii) at inference, composing the outputs of separately trained PEFT modules. We test these approaches on three different LLMs, QLoRA as the PEFT technique, and three sets of controlled text generation datasets for sentiment control, topic control, and multi-attribute control. We find that summing PEFT module outputs is a particularly strong composition method, which consistently either outperforms or matches the performance of alternative approaches. This is the case even when comparing against single-task specialised modules on the single-task test set, where three-module output composition achieves an average 2% point performance increase across all models for sentiment control.
A Comparative Study of Controlled Text Generation Systems Using Level-Playing-Field Evaluation Principles
May 12, 2026Background: Many different approaches to controlled text generation (CTG) have been proposed over recent years, but it is difficult to get a clear picture of which approach performs best, because different datasets and evaluation methods are used in each case to assess the control achieved. Objectives: Our aim in the work reported in this paper is to develop an approach to evaluation that enables us to comparatively evaluate different CTG systems in a manner that is both informative and fair to the individual systems. Methods: We use a level-playing-field (LPF) approach to comparative evaluation where we (i) generate and process all system outputs in a standardised way, and (ii) apply a shared set of evaluation methods and datasets, selected based on those currently in use, in order to ensure fair evaluation. Results: When re-evaluated in this way, performance results for a representative set of current CTG systems differ substantially from originally reported results, in most cases for the worse. This highlights the importance of a shared standardised way of assessing controlled generation. Conclusions: The discrepancies revealed by LPF evaluation demonstrate the urgent need for standardised, reproducible evaluation practices in CTG. Our results suggest that without such practices, published performance claims may substantially misrepresent true system capabilities.
Budgeted LoRA: Distillation as Structured Compute Allocation for Efficient Inference
May 05, 2026We study distillation for large language models under explicit compute constraints, with the goal of producing student models that are not only cheaper to train, but structurally efficient at inference time. While prior approaches to parameter-efficient distillation, such as LoRA, reduce adaptation cost, they leave the dense backbone unchanged and therefore fail to deliver meaningful inference savings. We propose Budgeted LoRA, a distillation framework that treats model compression as a structured compute allocation problem. Instead of using a fixed student architecture, we introduce a global compute budget that sets the final target fraction of dense computation retained. Under this constraint, the model redistributes capacity across dense and low-rank pathways via (i) module-level dense retention coefficients, (ii) adaptive low-rank allocation, and (iii) post-training compression that selectively removes, approximates, or preserves dense components. This formulation yields a family of students controlled by a single budget dial. Empirically, Budgeted LoRA matches standard LoRA perplexity at a moderate budget with a 1.74x compressed-module speedup; at an aggressive budget it achieves a 4.05x speedup with moderate perplexity degradation, and it preserves higher accuracy on function-style in-context learning probes. These results suggest that, under compute-constrained distillation, retaining behavior is less about matching perplexity or removing more parameters than it is about controlling how dense computation is transferred to low-rank pathways.
Beyond Outcome Verification: Verifiable Process Reward Models for Structured Reasoning
Jan 23, 2026Recent work on reinforcement learning with verifiable rewards (RLVR) has shown that large language models (LLMs) can be substantially improved using outcome-level verification signals, such as unit tests for code or exact-match checks for mathematics. In parallel, process supervision has long been explored as a way to shape the intermediate reasoning behaviour of LLMs, but existing approaches rely on neural judges to score chain-of-thought steps, leaving them vulnerable to opacity, bias, and reward hacking. To address this gap, we introduce Verifiable Process Reward Models (VPRMs), a reinforcement-learning framework in which intermediate reasoning steps are checked by deterministic, rule-based verifiers. We apply VPRMs to risk-of-bias assessment for medical evidence synthesis, a domain where guideline-defined criteria and rule-based decision paths enable programmatic verification of reasoning traces. Across multiple datasets, we find that VPRMs generate reasoning that adheres closely to domain rules and achieve substantially higher coherence between step-level decisions and final labels. Results show that VPRMs achieve up to 20% higher F1 than state-of-the-art models and 6.5% higher than verifiable outcome rewards, with substantial gains in evidence grounding and logical coherence.
The QCET Taxonomy of Standard Quality Criterion Names and Definitions for the Evaluation of NLP Systems
Sep 26, 2025



Prior work has shown that two NLP evaluation experiments that report results for the same quality criterion name (e.g. Fluency) do not necessarily evaluate the same aspect of quality, and the comparability implied by the name can be misleading. Not knowing when two evaluations are comparable in this sense means we currently lack the ability to draw reliable conclusions about system quality on the basis of multiple, independently conducted evaluations. This in turn hampers the ability of the field to progress scientifically as a whole, a pervasive issue in NLP since its beginning (Sparck Jones, 1981). It is hard to see how the issue of unclear comparability can be fully addressed other than by the creation of a standard set of quality criterion names and definitions that the several hundred quality criterion names actually in use in the field can be mapped to, and grounded in. Taking a strictly descriptive approach, the QCET Quality Criteria for Evaluation Taxonomy derives a standard set of quality criterion names and definitions from three surveys of evaluations reported in NLP, and structures them into a hierarchy where each parent node captures common aspects of its child nodes. We present QCET and the resources it consists of, and discuss its three main uses in (i) establishing comparability of existing evaluations, (ii) guiding the design of new evaluations, and (iii) assessing regulatory compliance.
Enhancing Study-Level Inference from Clinical Trial Papers via RL-based Numeric Reasoning
May 28, 2025Systematic reviews in medicine play a critical role in evidence-based decision-making by aggregating findings from multiple studies. A central bottleneck in automating this process is extracting numeric evidence and determining study-level conclusions for specific outcomes and comparisons. Prior work has framed this problem as a textual inference task by retrieving relevant content fragments and inferring conclusions from them. However, such approaches often rely on shallow textual cues and fail to capture the underlying numeric reasoning behind expert assessments. In this work, we conceptualise the problem as one of quantitative reasoning. Rather than inferring conclusions from surface text, we extract structured numerical evidence (e.g., event counts or standard deviations) and apply domain knowledge informed logic to derive outcome-specific conclusions. We develop a numeric reasoning system composed of a numeric data extraction model and an effect estimate component, enabling more accurate and interpretable inference aligned with the domain expert principles. We train the numeric data extraction model using different strategies, including supervised fine-tuning (SFT) and reinforcement learning (RL) with a new value reward model. When evaluated on the CochraneForest benchmark, our best-performing approach -- using RL to train a small-scale number extraction model -- yields up to a 21% absolute improvement in F1 score over retrieval-based systems and outperforms general-purpose LLMs of over 400B parameters by up to 9%. Our results demonstrate the promise of reasoning-driven approaches for automating systematic evidence synthesis.
Query-driven Document-level Scientific Evidence Extraction from Biomedical Studies
May 09, 2025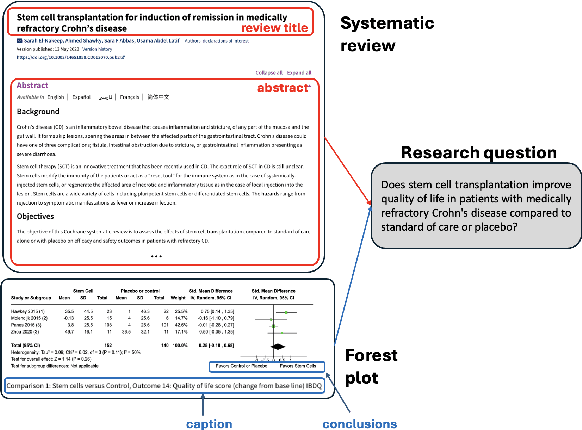
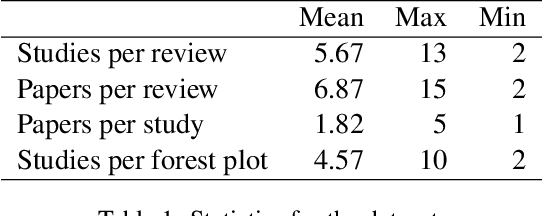
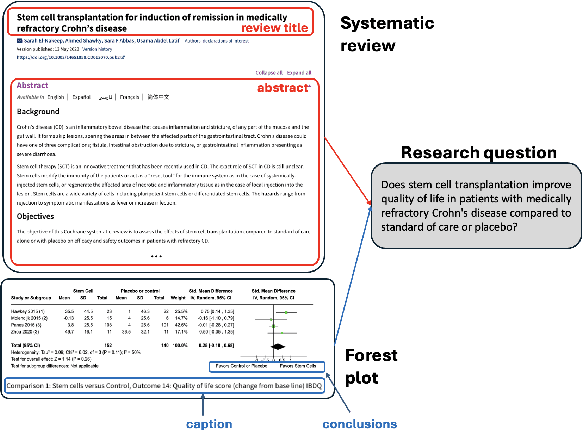
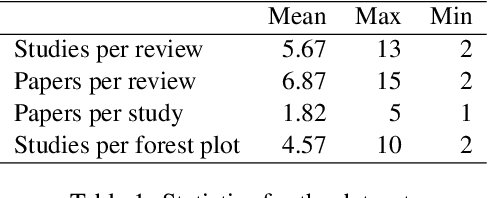
Extracting scientific evidence from biomedical studies for clinical research questions (e.g., Does stem cell transplantation improve quality of life in patients with medically refractory Crohn's disease compared to placebo?) is a crucial step in synthesising biomedical evidence. In this paper, we focus on the task of document-level scientific evidence extraction for clinical questions with conflicting evidence. To support this task, we create a dataset called CochraneForest, leveraging forest plots from Cochrane systematic reviews. It comprises 202 annotated forest plots, associated clinical research questions, full texts of studies, and study-specific conclusions. Building on CochraneForest, we propose URCA (Uniform Retrieval Clustered Augmentation), a retrieval-augmented generation framework designed to tackle the unique challenges of evidence extraction. Our experiments show that URCA outperforms the best existing methods by up to 10.3% in F1 score on this task. However, the results also underscore the complexity of CochraneForest, establishing it as a challenging testbed for advancing automated evidence synthesis systems.
HEDS 3.0: The Human Evaluation Data Sheet Version 3.0
Dec 10, 2024This paper presents version 3.0 of the Human Evaluation Datasheet (HEDS). This update is the result of our experience using HEDS in the context of numerous recent human evaluation experiments, including reproduction studies, and of feedback received. Our main overall goal was to improve clarity, and to enable users to complete the datasheet more consistently and comparably. The HEDS 3.0 package consists of the digital data sheet, documentation, and code for exporting completed data sheets as latex files, all available from the HEDS GitHub.
Reproducing the Metric-Based Evaluation of a Set of Controllable Text Generation Techniques
May 13, 2024



Rerunning a metric-based evaluation should be more straightforward, and results should be closer, than in a human-based evaluation, especially where code and model checkpoints are made available by the original authors. As this report of our efforts to rerun a metric-based evaluation of a set of single-attribute and multiple-attribute controllable text generation (CTG) techniques shows however, such reruns of evaluations do not always produce results that are the same as the original results, and can reveal errors in the reporting of the original work.