 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Induction from Visual Observations for Goal Directed Tasks
Oct 03, 2019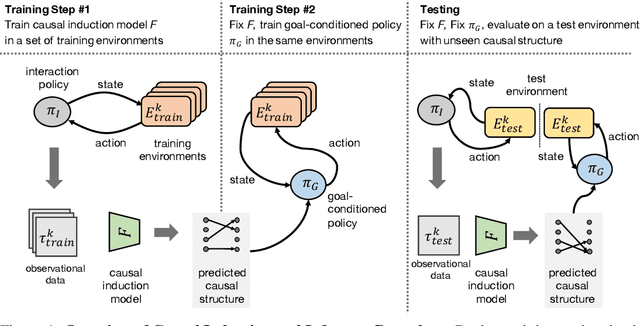
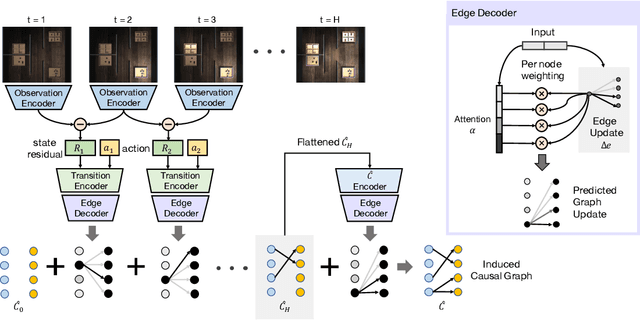
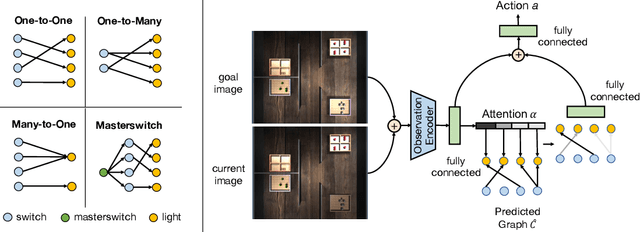
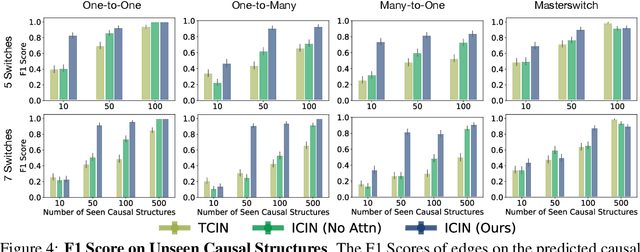
Causal reasoning has been an indispensable capability for humans and other intelligent animals to interact with the physical world. In this work, we propose to endow an artificial agent with the capability of causal reasoning for completing goal-directed tasks. We develop learning-based approaches to inducing causal knowledge in the form of directed acyclic graphs, which can be used to contextualize a learned goal-conditional policy to perform tasks in novel environments with latent causal structures. We leverage attention mechanisms in our causal induction model and goal-conditional policy, enabling us to incrementally generate the causal graph from the agent's visual observations and to selectively use the induced graph for determining actions. Our experiments show that our method effectively generalizes towards completing new tasks in novel environments with previously unseen causal structures.
Regression Planning Networks
Sep 28, 2019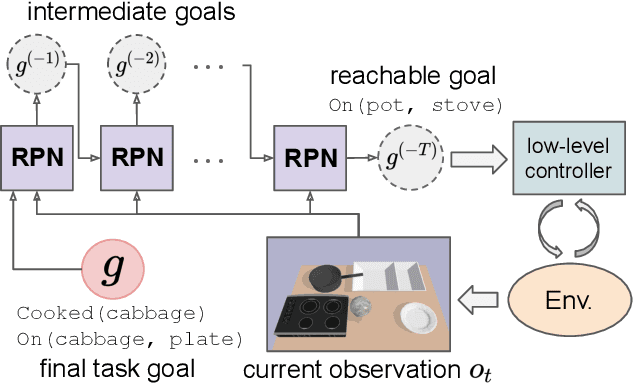
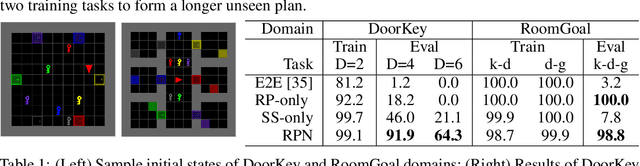
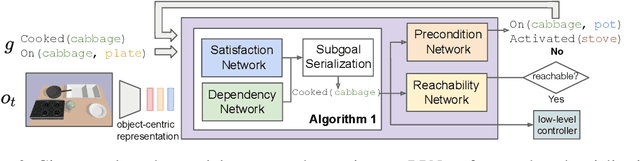
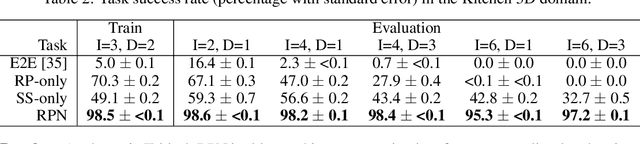
Recent learning-to-plan methods have shown promising results on planning directly from observation space. Yet, their ability to plan for long-horizon tasks is limited by the accuracy of the prediction model. On the other hand, classical symbolic planners show remarkable capabilities in solving long-horizon tasks, but they require predefined symbolic rules and symbolic states, restricting their real-world applicability. In this work, we combine the benefits of these two paradigms and propose a learning-to-plan method that can directly generate a long-term symbolic plan conditioned on high-dimensional observations. We borrow the idea of regression (backward) planning from classical planning literature and introduce Regression Planning Networks (RPN), a neural network architecture that plans backward starting at a task goal and generates a sequence of intermediate goals that reaches the current observation. We show that our model not only inherits many favorable traits from symbolic planning, e.g., the ability to solve previously unseen tasks but also can learn from visual inputs in an end-to-end manner. We evaluate the capabilities of RPN in a grid world environment and a simulated 3D kitchen environment featuring complex visual scenes and long task horizons, and show that it achieves near-optimal performance in completely new task instances.
AC-Teach: A Bayesian Actor-Critic Method for Policy Learning with an Ensemble of Suboptimal Teachers
Sep 12, 2019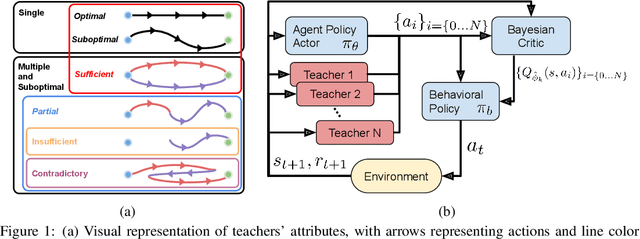

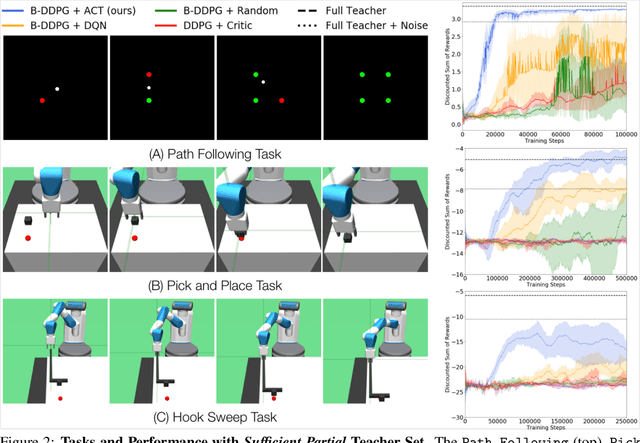
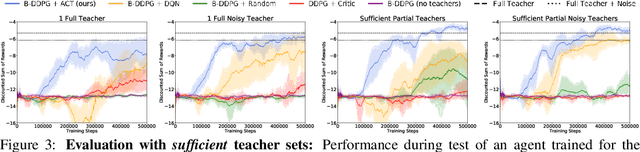
The exploration mechanism used by a Deep Reinforcement Learning (RL) agent plays a key role in determining its sample efficiency. Thus, improving over random exploration is crucial to solve long-horizon tasks with sparse rewards. We propose to leverage an ensemble of partial solutions as teachers that guide the agent's exploration with action suggestions throughout training. While the setup of learning with teachers has been previously studied, our proposed approach - Actor-Critic with Teacher Ensembles (AC-Teach) - is the first to work with an ensemble of suboptimal teachers that may solve only part of the problem or contradict other each other, forming a unified algorithmic solution that is compatible with a broad range of teacher ensembles. AC-Teach leverages a probabilistic representation of the expected outcome of the teachers' and student's actions to direct exploration, reduce dithering, and adapt to the dynamically changing quality of the learner. We evaluate a variant of AC-Teach that guides the learning of a Bayesian DDPG agent on three tasks - path following, robotic pick and place, and robotic cube sweeping using a hook - and show that it improves largely on sampling efficiency over a set of baselines, both for our target scenario of unconstrained suboptimal teachers and for easier setups with optimal or single teachers. Additional results and videos at https://sites.google.com/view/acteach/home.
Situational Fusion of Visual Representation for Visual Navigation
Aug 24, 2019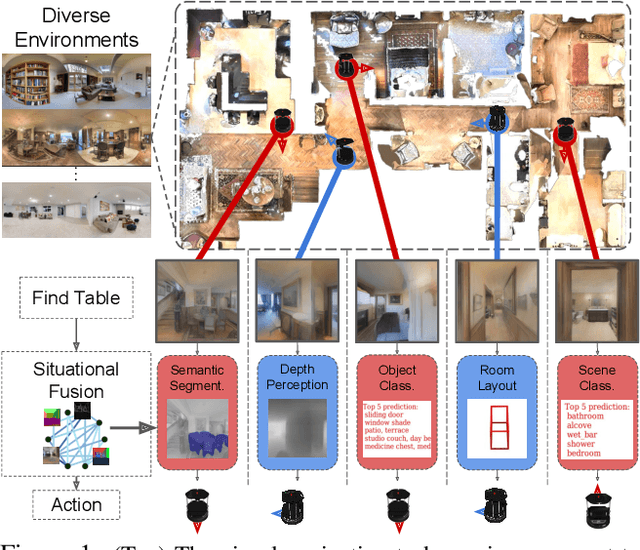

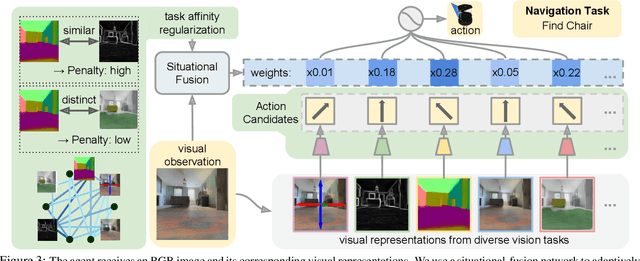
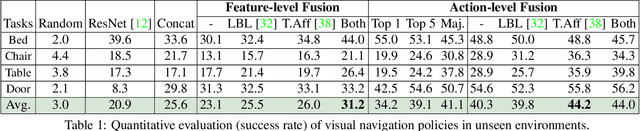
A complex visual navigation task puts an agent in different situations which call for a diverse range of visual perception abilities. For example, to "go to the nearest chair'', the agent might need to identify a chair in a living room using semantics, follow along a hallway using vanishing point cues, and avoid obstacles using depth. Therefore, utilizing the appropriate visual perception abilities based on a situational understanding of the visual environment can empower these navigation models in unseen visual environments. We propose to train an agent to fuse a large set of visual representations that correspond to diverse visual perception abilities. To fully utilize each representation, we develop an action-level representation fusion scheme, which predicts an action candidate from each representation and adaptively consolidate these action candidates into the final action. Furthermore, we employ a data-driven inter-task affinity regularization to reduce redundancies and improve generalization. Our approach leads to a significantly improved performance in novel environments over ImageNet-pretrained baseline and other fusion methods.
Continuous Relaxation of Symbolic Planner for One-Shot Imitation Learning
Aug 16, 2019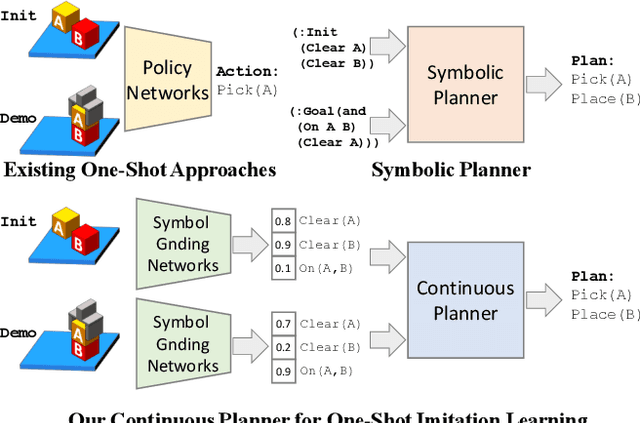
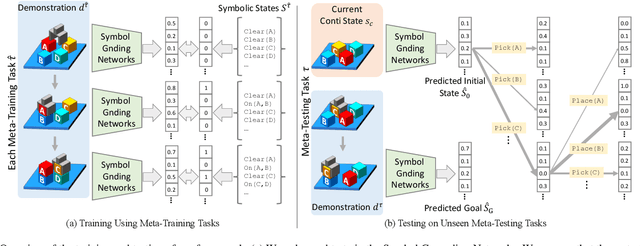
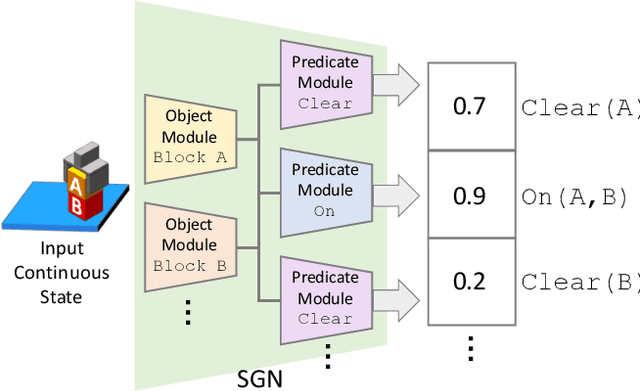
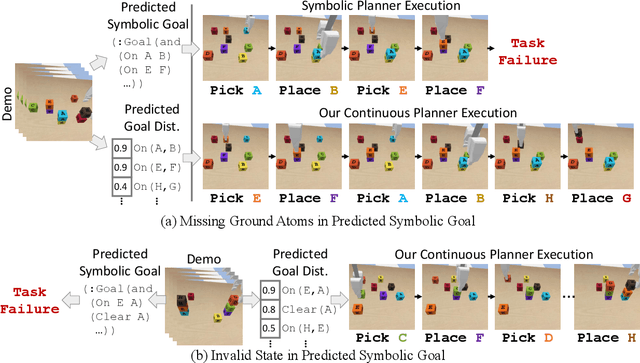
We address one-shot imitation learning, where the goal is to execute a previously unseen task based on a single demonstration. While there has been exciting progress in this direction, most of the approaches still require a few hundred tasks for meta-training, which limits the scalability of the approaches. Our main contribution is to formulate one-shot imitation learning as a symbolic planning problem along with the symbol grounding problem. This formulation disentangles the policy execution from the inter-task generalization and leads to better data efficiency. The key technical challenge is that the symbol grounding is prone to error with limited training data and leads to subsequent symbolic planning failures. We address this challenge by proposing a continuous relaxation of the discrete symbolic planner that directly plans on the probabilistic outputs of the symbol grounding model. Our continuous relaxation of the planner can still leverage the information contained in the probabilistic symbol grounding and significantly improve over the baseline planner for the one-shot imitation learning tasks without using large training data.
Variable Impedance Control in End-Effector Space: An Action Space for Reinforcement Learning in Contact-Rich Tasks
Aug 02, 2019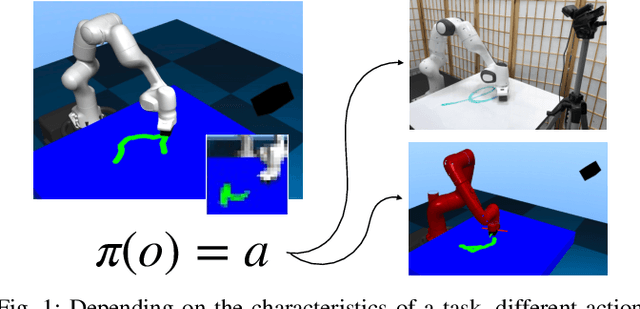
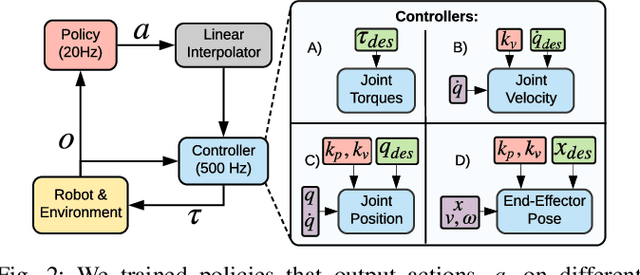
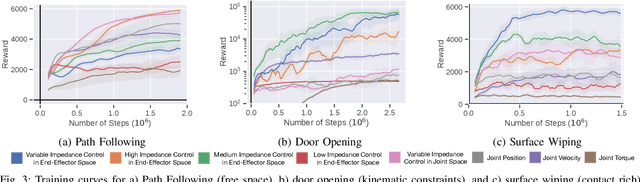
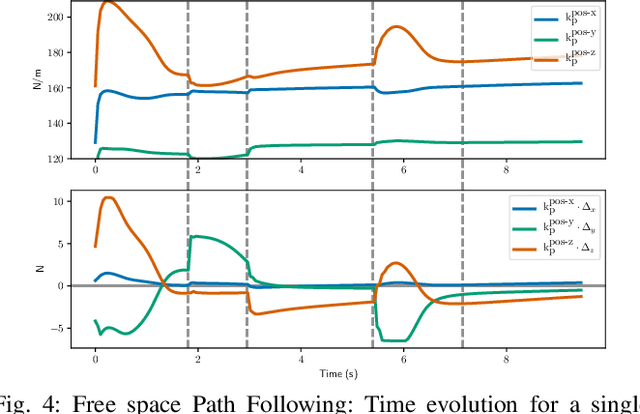
Reinforcement Learning (RL) of contact-rich manipulation tasks has yielded impressive results in recent years. While many studies in RL focus on varying the observation space or reward model, few efforts focused on the choice of action space (e.g. joint or end-effector space, position, velocity, etc.). However, studies in robot motion control indicate that choosing an action space that conforms to the characteristics of the task can simplify exploration and improve robustness to disturbances. This paper studies the effect of different action spaces in deep RL and advocates for Variable Impedance Control in End-effector Space (VICES) as an advantageous action space for constrained and contact-rich tasks. We evaluate multiple action spaces on three prototypical manipulation tasks: Path Following (task with no contact), Door Opening (task with kinematic constraints), and Surface Wiping (task with continuous contact). We show that VICES improves sample efficiency, maintains low energy consumption, and ensures safety across all three experimental setups. Further, RL policies learned with VICES can transfer across different robot models in simulation, and from simulation to real for the same robot. Further information is available at https://stanfordvl.github.io/vices.
Making Sense of Vision and Touch: Learning Multimodal Representations for Contact-Rich Tasks
Jul 28, 2019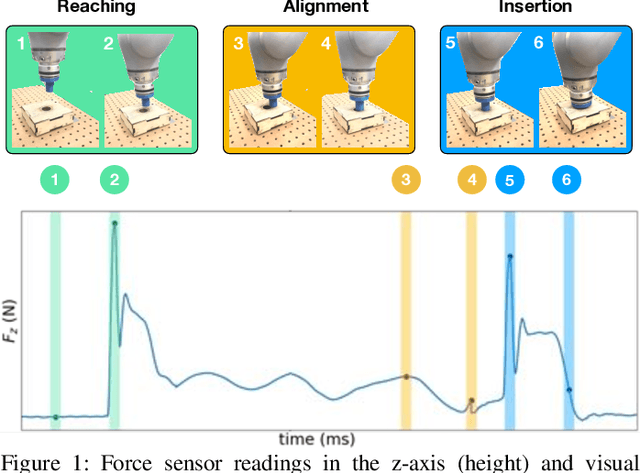
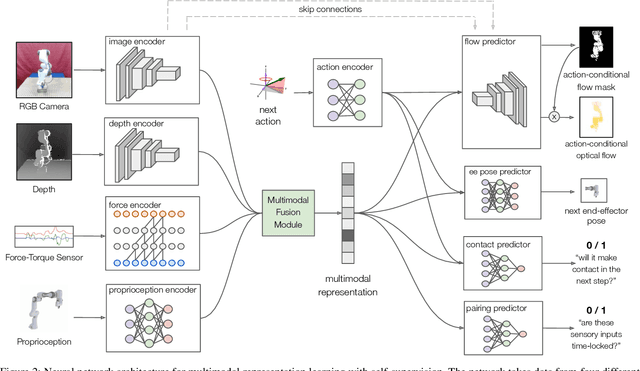
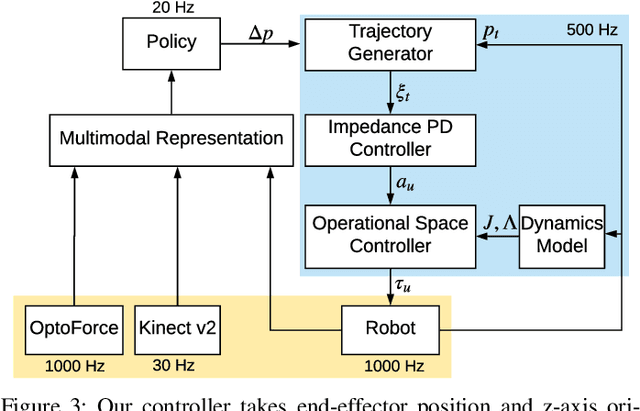

Contact-rich manipulation tasks in unstructured environments often require both haptic and visual feedback. It is non-trivial to manually design a robot controller that combines these modalities which have very different characteristics. While deep reinforcement learning has shown success in learning control policies for high-dimensional inputs, these algorithms are generally intractable to deploy on real robots due to sample complexity. In this work, we use self-supervision to learn a compact and multimodal representation of our sensory inputs, which can then be used to improve the sample efficiency of our policy learning. Evaluating our method on a peg insertion task, we show that it generalizes over varying geometries, configurations, and clearances, while being robust to external perturbations. We also systematically study different self-supervised learning objectives and representation learning architectures. Results are presented in simulation and on a physical robot.
DANTE: Deep Affinity Network for Clustering Conversational Interactants
Jul 24, 2019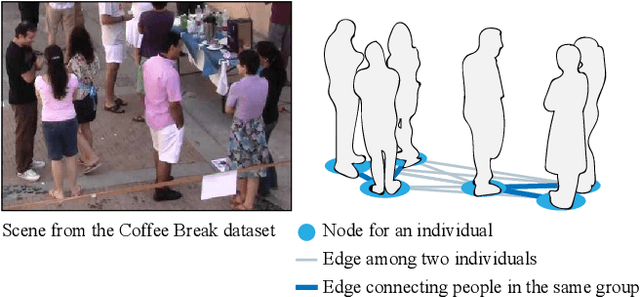
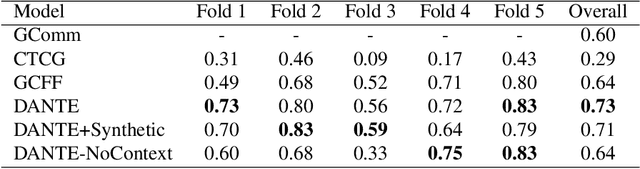

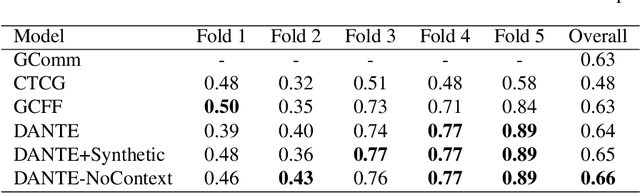
We propose a data-driven approach to visually detect conversational groups by identifying spatial arrangements typical of these focused social encounters. Our approach uses a novel Deep Affinity Network (DANTE) to predict the likelihood that two individuals in a scene are part of the same conversational group, considering contextual information like the position and orientation of other nearby individuals. The predicted pair-wise affinities are then used in a graph clustering framework to identify both small (e.g., dyads) and bigger groups. The results from our evaluation on two standard benchmarks suggest that the combination of powerful deep learning methods with classical clustering techniques can improve the detection of conversational groups in comparison to prior approaches. Our technique has a wide range of applications from visual scene understanding, e.g., for surveillance, to social robotics.
Social-BiGAT: Multimodal Trajectory Forecasting using Bicycle-GAN and Graph Attention Networks
Jul 17, 2019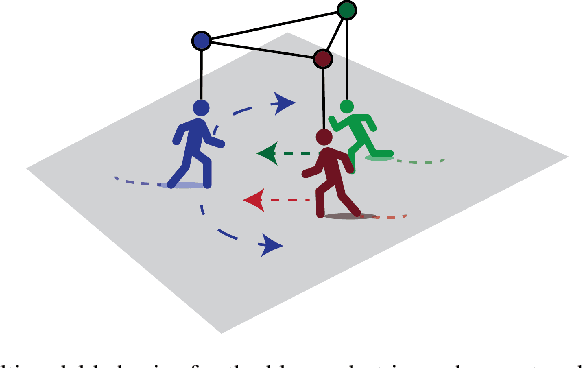
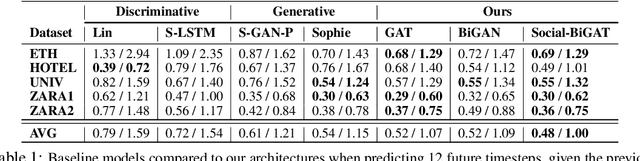
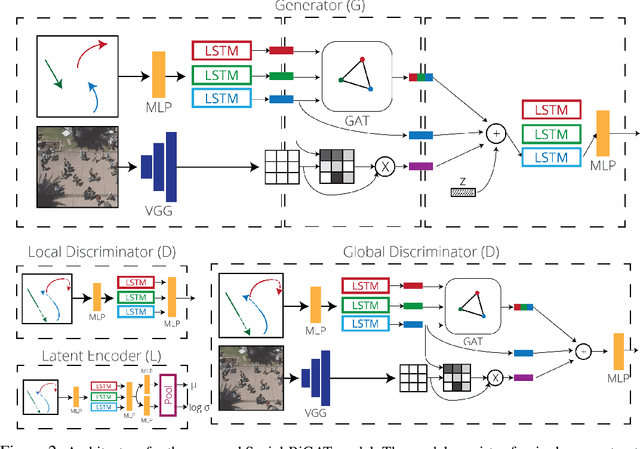
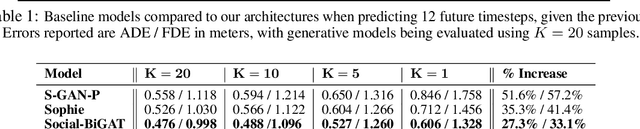
Predicting the future trajectories of multiple interacting agents in a scene has become an increasingly important problem for many different applications ranging from control of autonomous vehicles and social robots to security and surveillance. This problem is compounded by the presence of social interactions between humans and their physical interactions with the scene. While the existing literature has explored some of these cues, they mainly ignored the multimodal nature of each human's future trajectory. In this paper, we present Social-BiGAT, a graph-based generative adversarial network that generates realistic, multimodal trajectory predictions by better modelling the social interactions of pedestrians in a scene. Our method is based on a graph attention network (GAT) that learns reliable feature representations that encode the social interactions between humans in the scene, and a recurrent encoder-decoder architecture that is trained adversarially to predict, based on the features, the humans' paths. We explicitly account for the multimodal nature of the prediction problem by forming a reversible transformation between each scene and its latent noise vector, as in Bicycle-GAN. We show that our framework achieves state-of-the-art performance comparing it to several baselines on existing trajectory forecasting benchmarks.
Time-Varying Interaction Estimation Using Ensemble Methods
Jun 25, 2019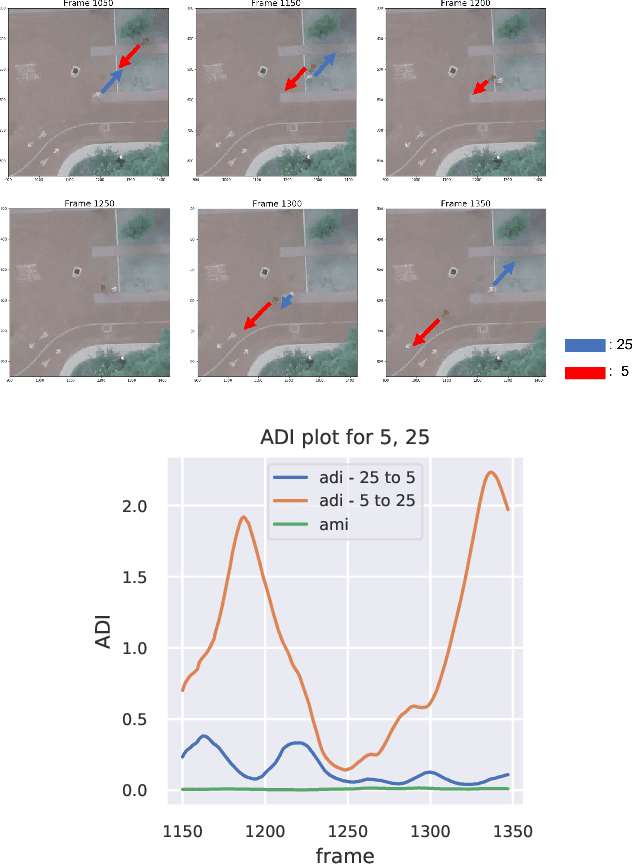
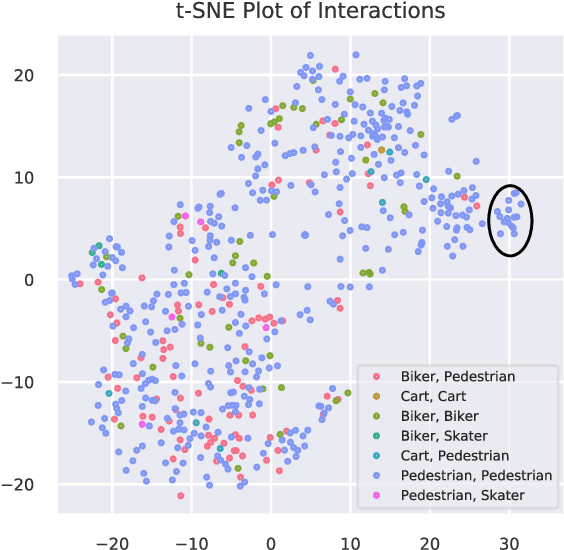
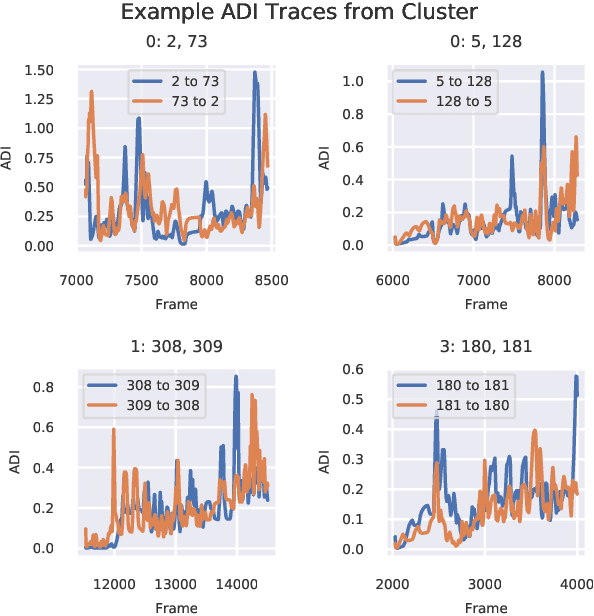
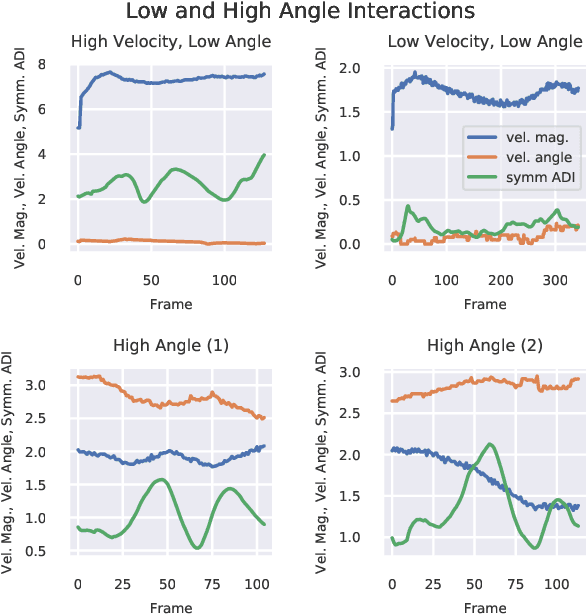
Directed information (DI) is a useful tool to explore time-directed interactions in multivariate data. However, as originally formulated DI is not well suited to interactions that change over time. In previous work, adaptive directed information was introduced to accommodate non-stationarity, while still preserving the utility of DI to discover complex dependencies between entities. There are many design decisions and parameters that are crucial to the effectiveness of ADI. Here, we apply ideas from ensemble learning in order to alleviate this issue, allowing for a more robust estimator for exploratory data analysis. We apply these techniques to interaction estimation in a crowded scene, utilizing the Stanford drone dataset as an example.