 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust-Aware Decision Making for Human-Robot Collaboration: Model Learning and Planning
Nov 22, 2018
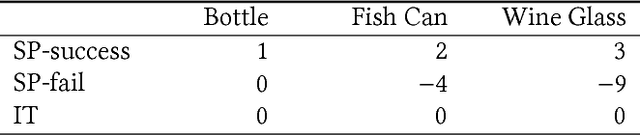
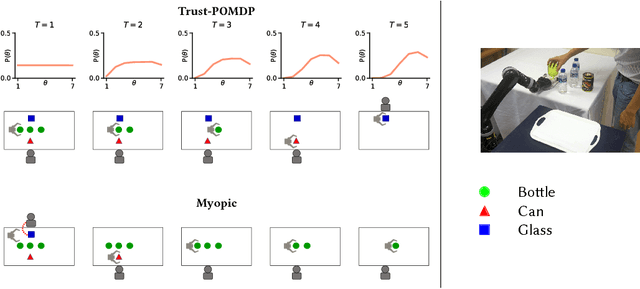

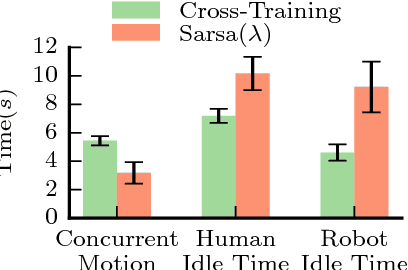
Trust in autonomy is essential for effective human-robot collaboration and user adoption of autonomous systems such as robot assistants. This paper introduces a computational model which integrates trust into robot decision-making. Specifically, we learn from data a partially observable Markov decision process (POMDP) with human trust as a latent variable. The trust-POMDP model provides a principled approach for the robot to (i) infer the trust of a human teammate through interaction, (ii) reason about the effect of its own actions on human trust, and (iii) choose actions that maximize team performance over the long term. We validated the model through human subject experiments on a table-clearing task in simulation (201 participants) and with a real robot (20 participants). In our studies, the robot builds human trust by manipulating low-risk objects first. Interestingly, the robot sometimes fails intentionally in order to modulate human trust and achieve the best team performance. These results show that the trust-POMDP calibrates trust to improve human-robot team performance over the long term. Further, they highlight that maximizing trust alone does not always lead to the best performance.
Sample-Efficient Learning of Nonprehensile Manipulation Policies via Physics-Based Informed State Distributions
Oct 24, 2018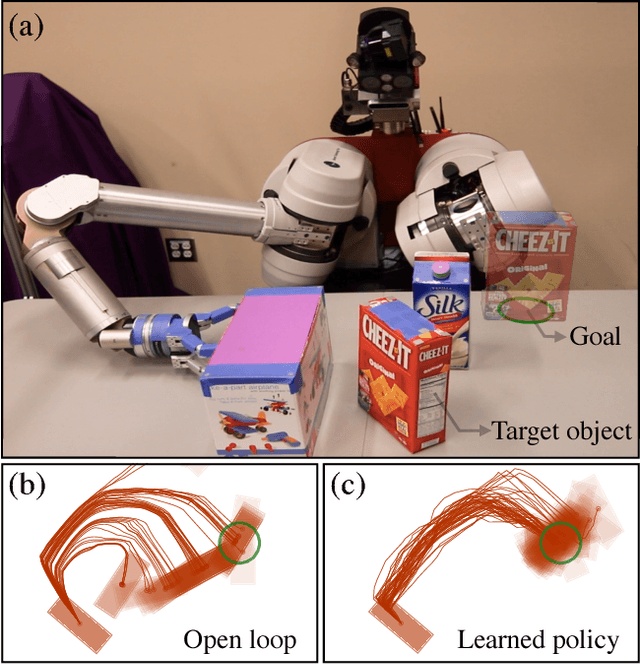
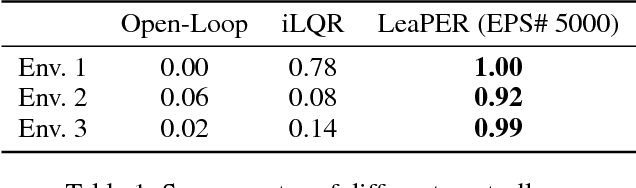


This paper proposes a sample-efficient yet simple approach to learning closed-loop policies for nonprehensile manipulation. Although reinforcement learning (RL) can learn closed-loop policies without requiring access to underlying physics models, it suffers from poor sample complexity on challenging tasks. To overcome this problem, we leverage rearrangement planning to provide an informative physics-based prior on the environment's optimal state-visitation distribution. Specifically, we present a new technique, Learning with Planned Episodic Resets (LeaPER), that resets the environment's state to one informed by the prior during the learning phase. We experimentally show that LeaPER significantly outperforms traditional RL approaches by a factor of up to 5X on simulated rearrangement. Further, we relax dynamics from quasi-static to welded contacts to illustrate that LeaPER is robust to the use of simpler physics models. Finally, LeaPER's closed-loop policies significantly improve task success rates relative to both open-loop controls with a planned path or simple feedback controllers that track open-loop trajectories. We demonstrate the performance and behavior of LeaPER on a physical 7-DOF manipulator in https://youtu.be/feS-zFq6J1c.
Minimizing Task Space Frechet Error via Efficient Incremental Graph Search
Sep 10, 2018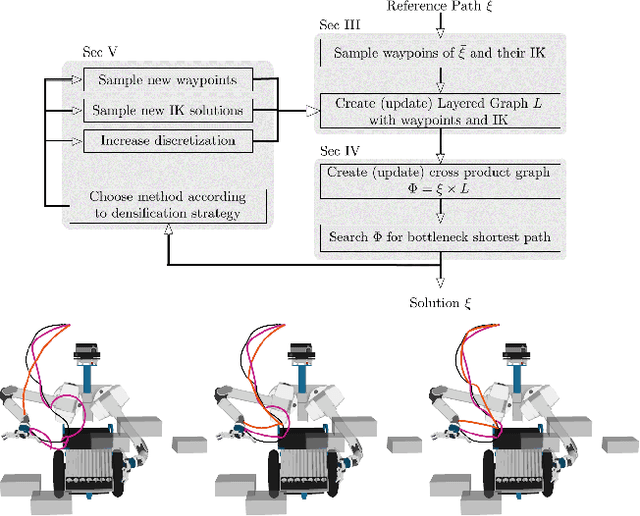

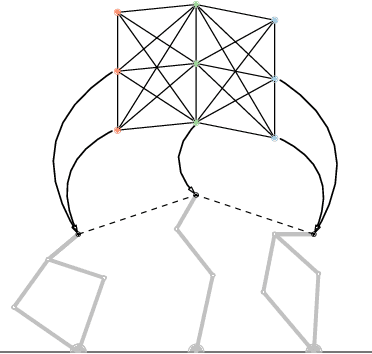
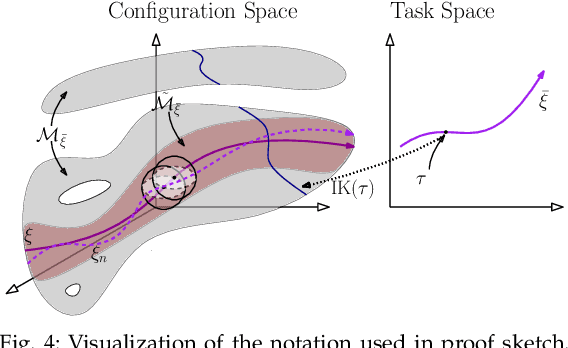
We present an anytime algorithm that generates a collision-free configuration-space path that closely follows a desired path in task space, according to the discrete Frechet distance. By leveraging tools from computational geometry, we approximate the search space using a cross-product graph. We use a variant of Dijkstra's graph-search algorithm to efficiently search for and iteratively improve the solution. We compare multiple proposed densification strategies and empirically show that our algorithm outperforms a set of state-of-the-art planners on a range of manipulation problems. Finally, we offer a proof sketch of the asymptotic optimality of our algorithm.
Balancing Shared Autonomy with Human-Robot Communication
May 20, 2018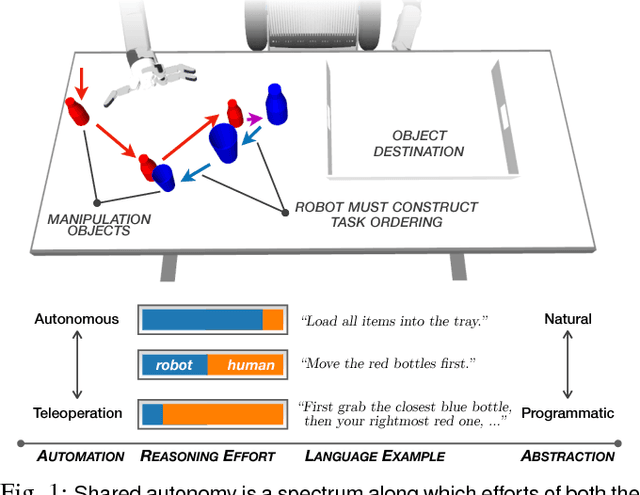
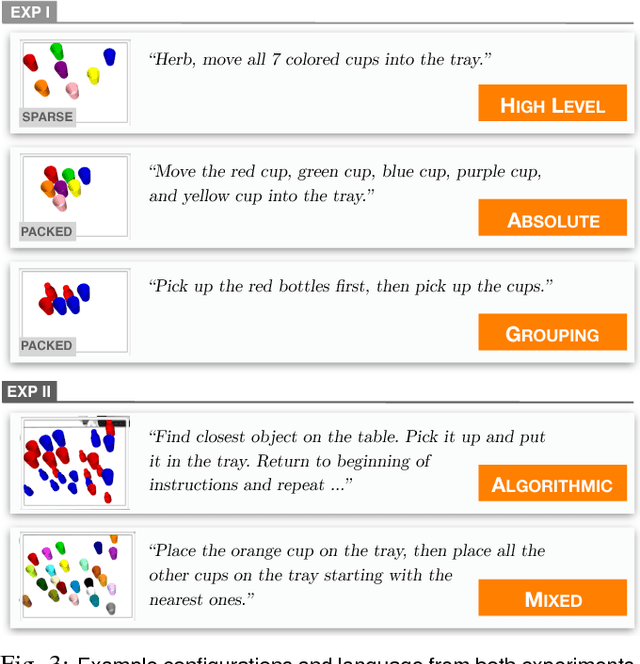
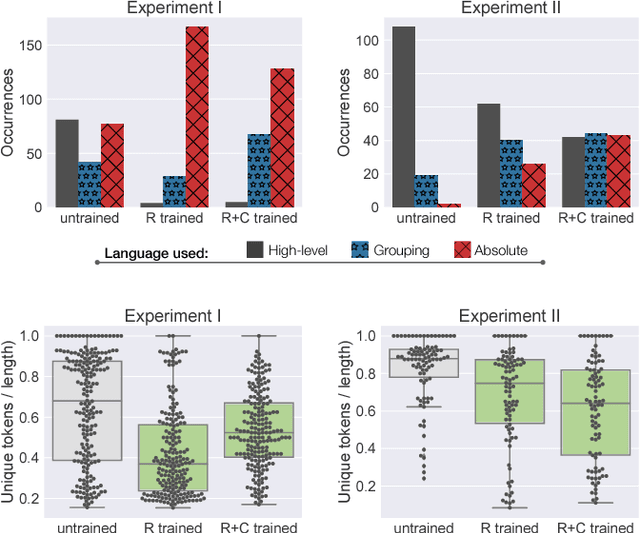
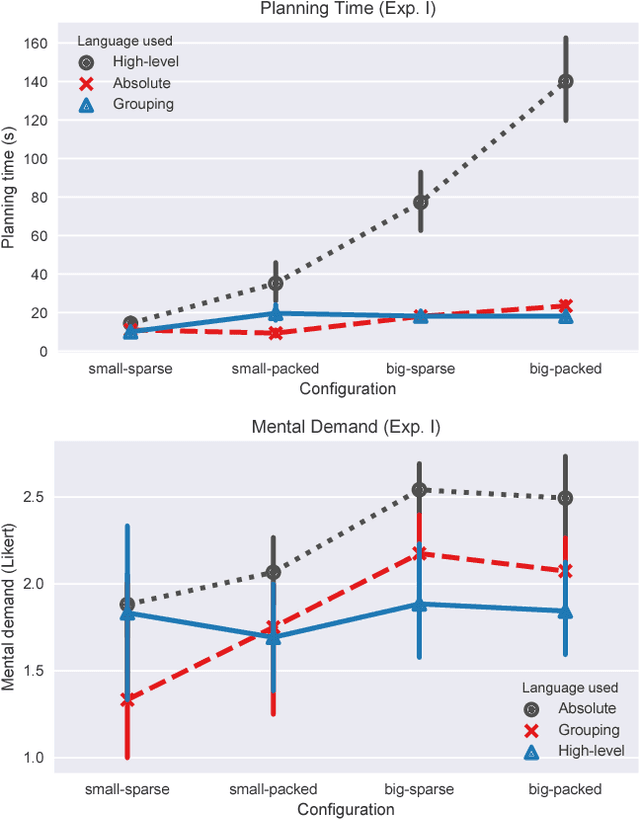
Robotic agents that share autonomy with a human should leverage human domain knowledge and account for their preferences when completing a task. This extra knowledge can dramatically improve plan efficiency and user-satisfaction, but these gains are lost if communicating with a robot is taxing and unnatural. In this paper, we show how viewing humanrobot language through the lens of shared autonomy explains the efficiency versus cognitive load trade-offs humans make when deciding how cooperative and explicit to make their instructions.
Lazy Receding Horizon A* for Efficient Path Planning in Graphs with Expensive-to-Evaluate Edges
Mar 15, 2018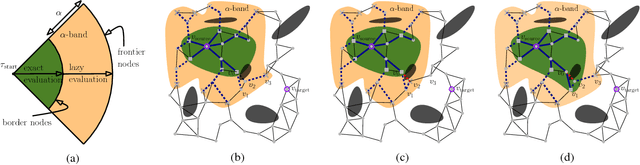
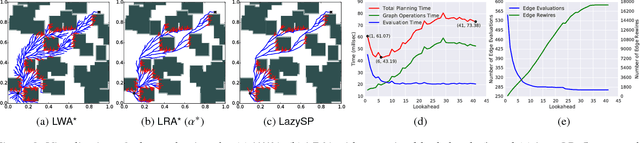
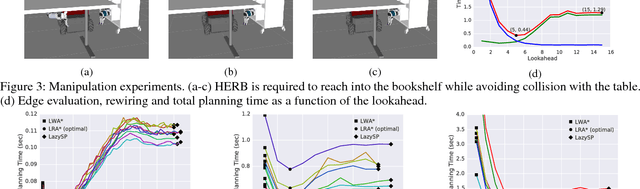
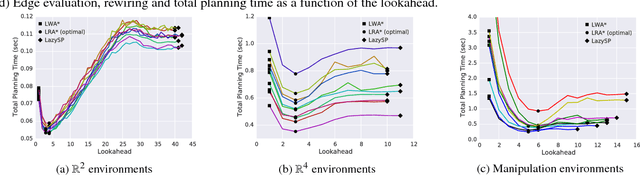
Motion-planning problems, such as manipulation in cluttered environments, often require a collision-free shortest path to be computed quickly given a roadmap graph. Typically, the computational cost of evaluating whether an edge of the roadmap graph is collision-free dominates the running time of search algorithms. Algorithms such as Lazy Weighted A* (LWA*) and LazySP have been proposed to reduce the number of edge evaluations by employing a lazy lookahead (one-step lookahead and infinite-step lookahead, respectively). However, this comes at the expense of additional graph operations: the larger the lookahead, the more the graph operations that are typically required. We propose Lazy Receding-Horizon A* (LRA*) to minimize the total planning time by balancing edge evaluations and graph operations. Endowed with a lazy lookahead, LRA* represents a family of lazy shortest-path graph-search algorithms that generalizes LWA* and LazySP. We analyze the theoretic properties of LRA* and demonstrate empirically that, in many cases, to minimize the total planning time, the algorithm requires an intermediate lazy lookahead. Namely, using an intermediate lazy lookahead, our algorithm outperforms both LWA* and LazySP. These experiments span simulated random worlds in $\mathbb{R}^2$ and $\mathbb{R}^4$, and manipulation problems using a 7-DOF manipulator.
Recurrent Predictive State Policy Networks
Mar 05, 2018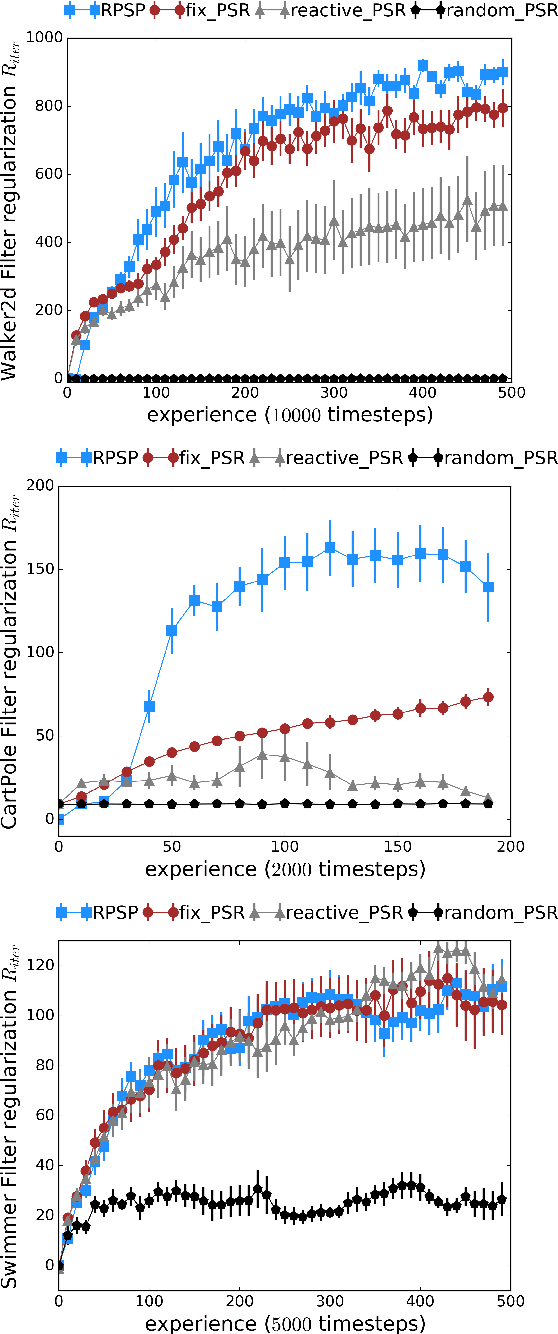
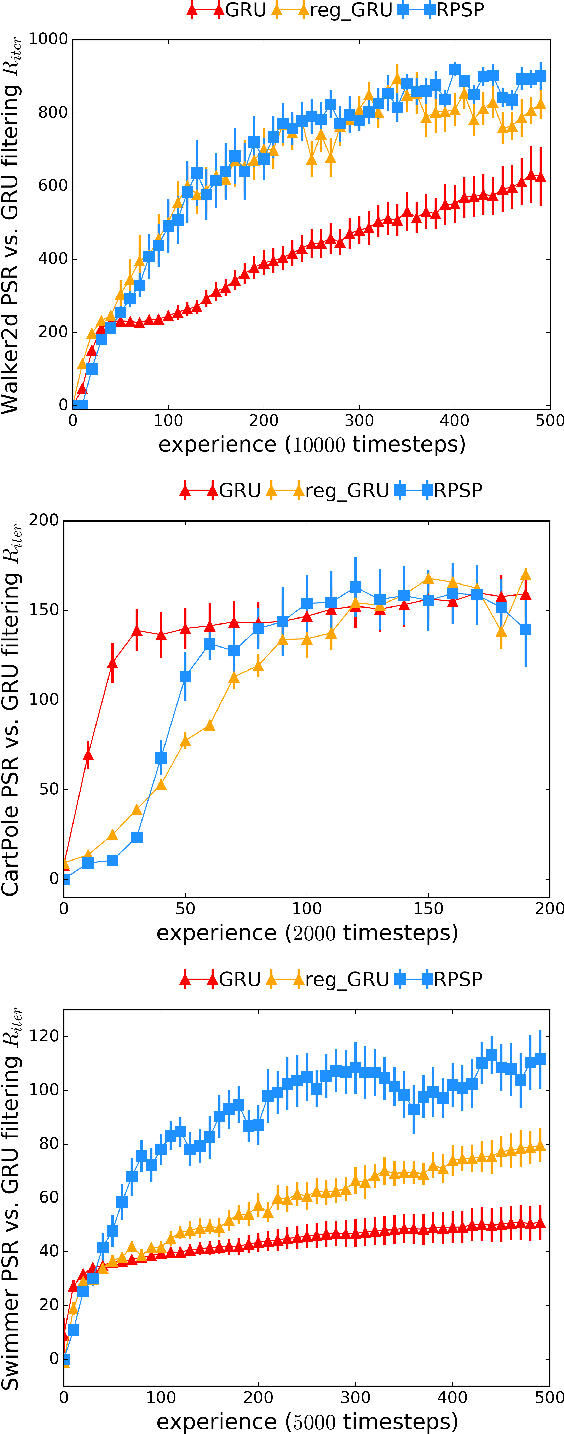
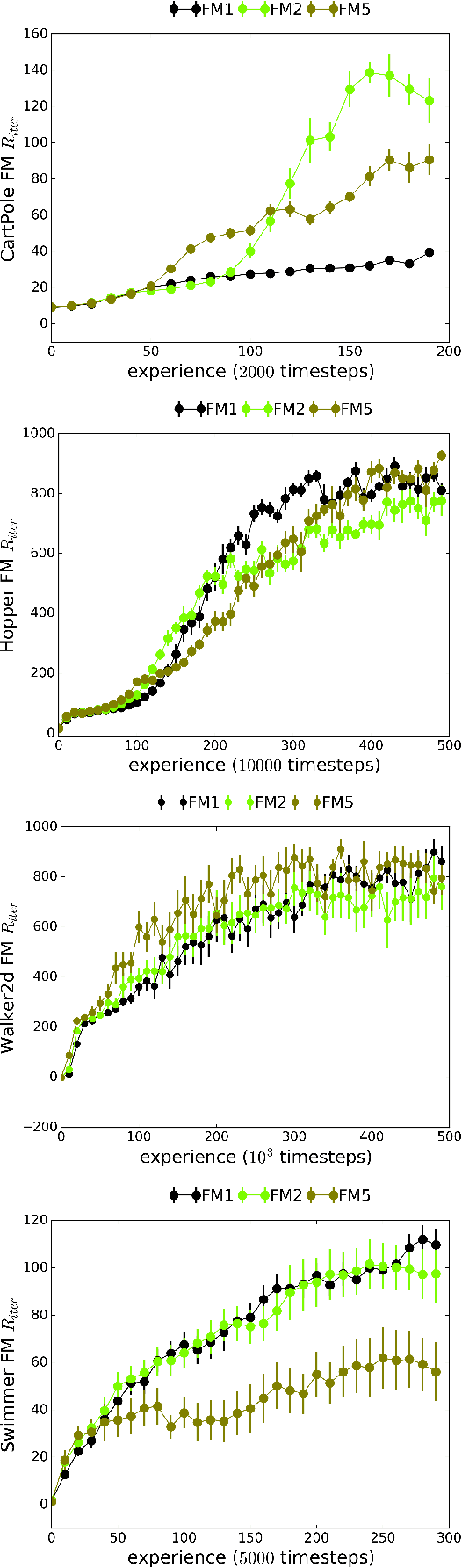
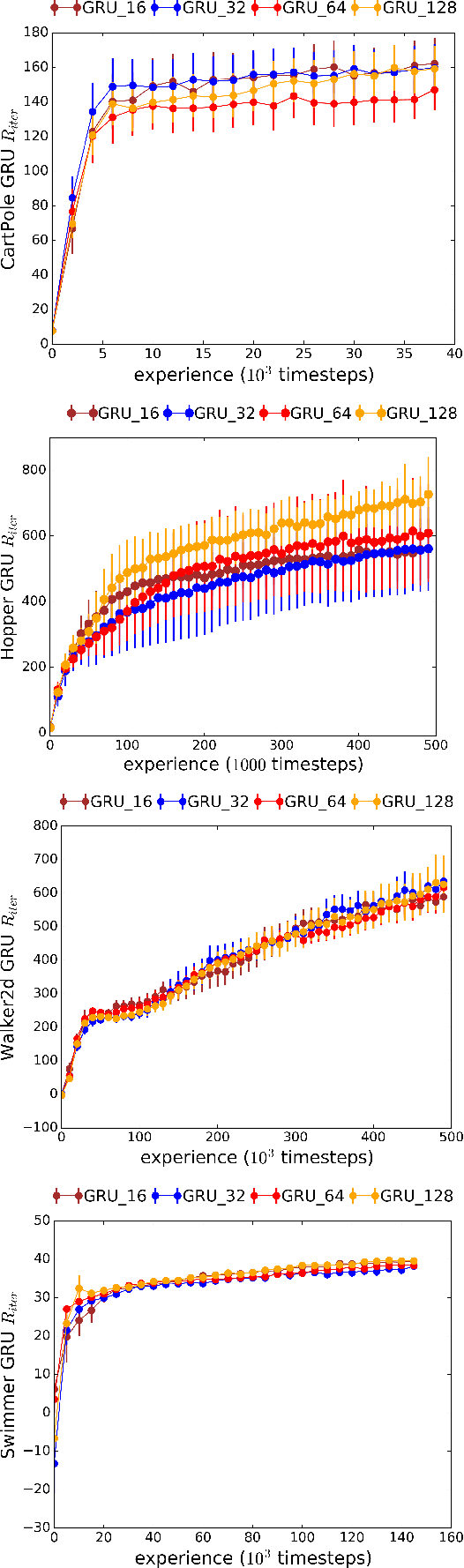
We introduce Recurrent Predictive State Policy (RPSP) networks, a recurrent architecture that brings insights from predictive state representations to reinforcement learning in partially observable environments. Predictive state policy networks consist of a recursive filter, which keeps track of a belief about the state of the environment, and a reactive policy that directly maps beliefs to actions, to maximize the cumulative reward. The recursive filter leverages predictive state representations (PSRs) (Rosencrantz and Gordon, 2004; Sun et al., 2016) by modeling predictive state-- a prediction of the distribution of future observations conditioned on history and future actions. This representation gives rise to a rich class of statistically consistent algorithms (Hefny et al., 2018) to initialize the recursive filter. Predictive state serves as an equivalent representation of a belief state. Therefore, the policy component of the RPSP-network can be purely reactive, simplifying training while still allowing optimal behaviour. Moreover, we use the PSR interpretation during training as well, by incorporating prediction error in the loss function. The entire network (recursive filter and reactive policy) is still differentiable and can be trained using gradient based methods. We optimize our policy using a combination of policy gradient based on rewards (Williams, 1992) and gradient descent based on prediction error. We show the efficacy of RPSP-networks under partial observability on a set of robotic control tasks from OpenAI Gym. We empirically show that RPSP-networks perform well compared with memory-preserving networks such as GRUs, as well as finite memory models, being the overall best performing method.
Bayesian Active Edge Evaluation on Expensive Graphs
Nov 20, 2017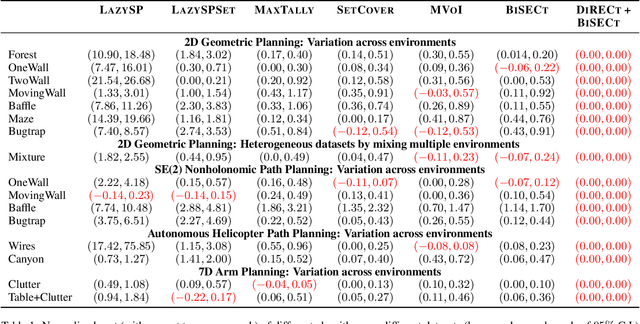
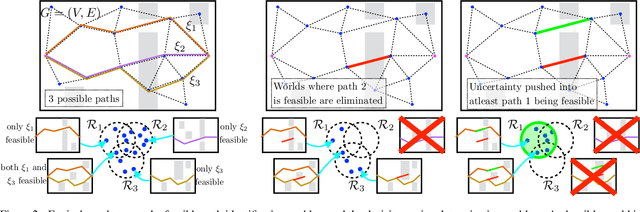
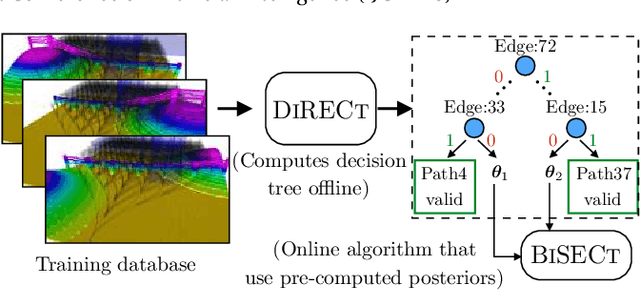
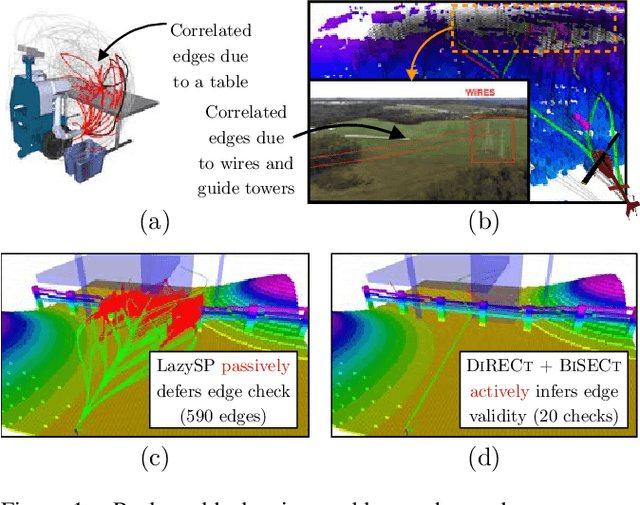
Robots operate in environments with varying implicit structure. For instance, a helicopter flying over terrain encounters a very different arrangement of obstacles than a robotic arm manipulating objects on a cluttered table top. State-of-the-art motion planning systems do not exploit this structure, thereby expending valuable planning effort searching for implausible solutions. We are interested in planning algorithms that actively infer the underlying structure of the valid configuration space during planning in order to find solutions with minimal effort. Consider the problem of evaluating edges on a graph to quickly discover collision-free paths. Evaluating edges is expensive, both for robots with complex geometries like robot arms, and for robots with limited onboard computation like UAVs. Until now, this challenge has been addressed via laziness i.e. deferring edge evaluation until absolutely necessary, with the hope that edges turn out to be valid. However, all edges are not alike in value - some have a lot of potentially good paths flowing through them, and some others encode the likelihood of neighbouring edges being valid. This leads to our key insight - instead of passive laziness, we can actively choose edges that reduce the uncertainty about the validity of paths. We show that this is equivalent to the Bayesian active learning paradigm of decision region determination (DRD). However, the DRD problem is not only combinatorially hard, but also requires explicit enumeration of all possible worlds. We propose a novel framework that combines two DRD algorithms, DIRECT and BISECT, to overcome both issues. We show that our approach outperforms several state-of-the-art algorithms on a spectrum of planning problems for mobile robots, manipulators and autonomous helicopters.
Generalizing Informed Sampling for Asymptotically Optimal Sampling-based Kinodynamic Planning via Markov Chain Monte Carlo
Oct 17, 2017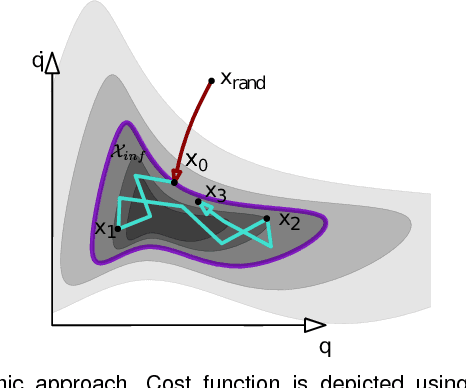
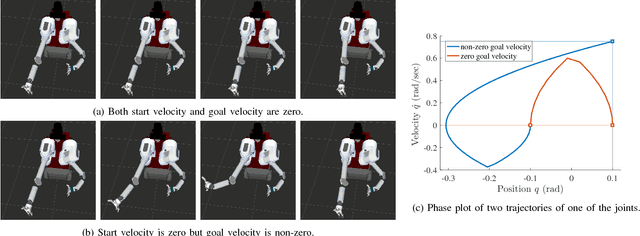
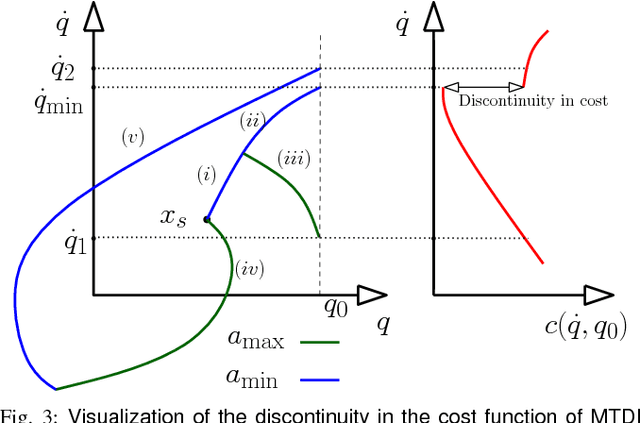
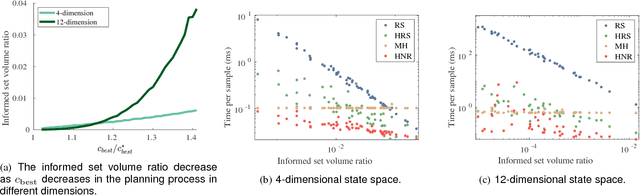
Asymptotically-optimal motion planners such as RRT* have been shown to incrementally approximate the shortest path between start and goal states. Once an initial solution is found, their performance can be dramatically improved by restricting subsequent samples to regions of the state space that can potentially improve the current solution. When the motion planning problem lies in a Euclidean space, this region $X_{inf}$, called the informed set, can be sampled directly. However, when planning with differential constraints in non-Euclidean state spaces, no analytic solutions exists to sampling $X_{inf}$ directly. State-of-the-art approaches to sampling $X_{inf}$ in such domains such as Hierarchical Rejection Sampling (HRS) may still be slow in high-dimensional state space. This may cause the planning algorithm to spend most of its time trying to produces samples in $X_{inf}$ rather than explore it. In this paper, we suggest an alternative approach to produce samples in the informed set $X_{inf}$ for a wide range of settings. Our main insight is to recast this problem as one of sampling uniformly within the sub-level-set of an implicit non-convex function. This recasting enables us to apply Monte Carlo sampling methods, used very effectively in the Machine Learning and Optimization communities, to solve our problem. We show for a wide range of scenarios that using our sampler can accelerate the convergence rate to high-quality solutions in high-dimensional problems.
Mathematical Models of Adaptation in Human-Robot Collaboration
Aug 04, 2017


A robot operating in isolation needs to reason over the uncertainty in its model of the world and adapt its own actions to account for this uncertainty. Similarly, a robot interacting with people needs to reason over its uncertainty over the human internal state, as well as over how this state may change, as humans adapt to the robot. This paper summarizes our own work in this area, which depicts the different ways that probabilistic planning and game-theoretic algorithms can enable such reasoning in robotic systems that collaborate with people. We start with a general formulation of the problem as a two-player game with incomplete information. We then articulate the different assumptions within this general formulation, and we explain how these lead to exciting and diverse robot behaviors in real-time interactions with actual human subjects, in a variety of manufacturing, personal robotics and assistive care settings.
Near-Optimal Edge Evaluation in Explicit Generalized Binomial Graphs
Jun 28, 2017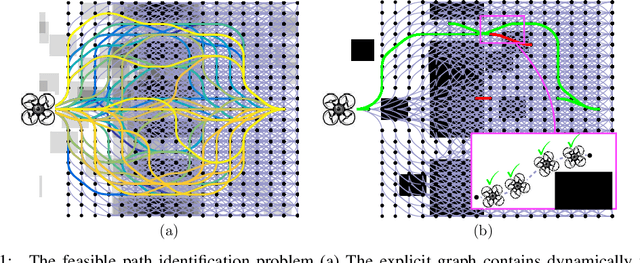
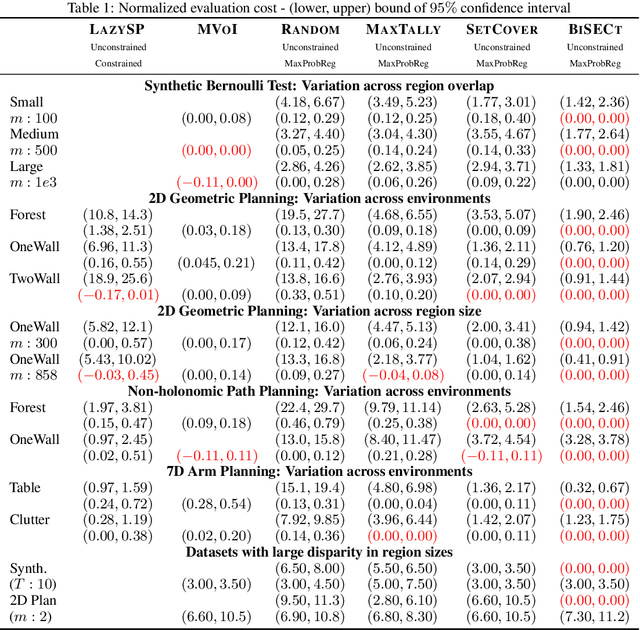
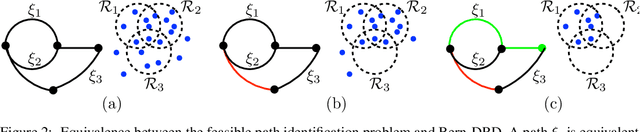
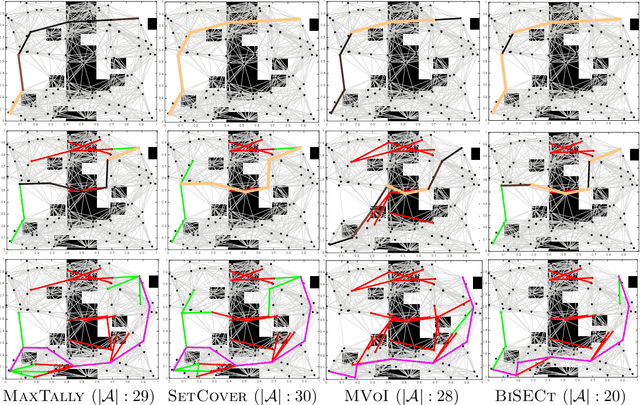
Robotic motion-planning problems, such as a UAV flying fast in a partially-known environment or a robot arm moving around cluttered objects, require finding collision-free paths quickly. Typically, this is solved by constructing a graph, where vertices represent robot configurations and edges represent potentially valid movements of the robot between these configurations. The main computational bottlenecks are expensive edge evaluations to check for collisions. State of the art planning methods do not reason about the optimal sequence of edges to evaluate in order to find a collision free path quickly. In this paper, we do so by drawing a novel equivalence between motion planning and the Bayesian active learning paradigm of decision region determination (DRD). Unfortunately, a straight application of existing methods requires computation exponential in the number of edges in a graph. We present BISECT, an efficient and near-optimal algorithm to solve the DRD problem when edges are independent Bernoulli random variables. By leveraging this property, we are able to significantly reduce computational complexity from exponential to linear in the number of edges. We show that BISECT outperforms several state of the art algorithms on a spectrum of planning problems for mobile robots, manipulators, and real flight data collected from a full scale helicopter.