 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncentivize Contribution and Learn Parameters Too: Federated Learning with Strategic Data Owners
May 17, 2025Classical federated learning (FL) assumes that the clients have a limited amount of noisy data with which they voluntarily participate and contribute towards learning a global, more accurate model in a principled manner. The learning happens in a distributed fashion without sharing the data with the center. However, these methods do not consider the incentive of an agent for participating and contributing to the process, given that data collection and running a distributed algorithm is costly for the clients. The question of rationality of contribution has been asked recently in the literature and some results exist that consider this problem. This paper addresses the question of simultaneous parameter learning and incentivizing contribution, which distinguishes it from the extant literature. Our first mechanism incentivizes each client to contribute to the FL process at a Nash equilibrium and simultaneously learn the model parameters. However, this equilibrium outcome can be away from the optimal, where clients contribute with their full data and the algorithm learns the optimal parameters. We propose a second mechanism with monetary transfers that is budget balanced and enables the full data contribution along with optimal parameter learning. Large scale experiments with real (federated) datasets (CIFAR-10, FeMNIST, and Twitter) show that these algorithms converge quite fast in practice, yield good welfare guarantees, and better model performance for all agents.
Distilling Opinions at Scale: Incremental Opinion Summarization using XL-OPSUMM
Jun 16, 2024



Opinion summarization in e-commerce encapsulates the collective views of numerous users about a product based on their reviews. Typically, a product on an e-commerce platform has thousands of reviews, each review comprising around 10-15 words. While Large Language Models (LLMs) have shown proficiency in summarization tasks, they struggle to handle such a large volume of reviews due to context limitations. To mitigate, we propose a scalable framework called Xl-OpSumm that generates summaries incrementally. However, the existing test set, AMASUM has only 560 reviews per product on average. Due to the lack of a test set with thousands of reviews, we created a new test set called Xl-Flipkart by gathering data from the Flipkart website and generating summaries using GPT-4. Through various automatic evaluations and extensive analysis, we evaluated the framework's efficiency on two datasets, AMASUM and Xl-Flipkart. Experimental results show that our framework, Xl-OpSumm powered by Llama-3-8B-8k, achieves an average ROUGE-1 F1 gain of 4.38% and a ROUGE-L F1 gain of 3.70% over the next best-performing model.
Product Description and QA Assisted Self-Supervised Opinion Summarization
Apr 08, 2024



In e-commerce, opinion summarization is the process of summarizing the consensus opinions found in product reviews. However, the potential of additional sources such as product description and question-answers (QA) has been considered less often. Moreover, the absence of any supervised training data makes this task challenging. To address this, we propose a novel synthetic dataset creation (SDC) strategy that leverages information from reviews as well as additional sources for selecting one of the reviews as a pseudo-summary to enable supervised training. Our Multi-Encoder Decoder framework for Opinion Summarization (MEDOS) employs a separate encoder for each source, enabling effective selection of information while generating the summary. For evaluation, due to the unavailability of test sets with additional sources, we extend the Amazon, Oposum+, and Flipkart test sets and leverage ChatGPT to annotate summaries. Experiments across nine test sets demonstrate that the combination of our SDC approach and MEDOS model achieves on average a 14.5% improvement in ROUGE-1 F1 over the SOTA. Moreover, comparative analysis underlines the significance of incorporating additional sources for generating more informative summaries. Human evaluations further indicate that MEDOS scores relatively higher in coherence and fluency with 0.41 and 0.5 (-1 to 1) respectively, compared to existing models. To the best of our knowledge, we are the first to generate opinion summaries leveraging additional sources in a self-supervised setting.
One Prompt To Rule Them All: LLMs for Opinion Summary Evaluation
Feb 18, 2024



Evaluation of opinion summaries using conventional reference-based metrics rarely provides a holistic evaluation and has been shown to have a relatively low correlation with human judgments. Recent studies suggest using Large Language Models (LLMs) as reference-free metrics for NLG evaluation, however, they remain unexplored for opinion summary evaluation. Moreover, limited opinion summary evaluation datasets inhibit progress. To address this, we release the SUMMEVAL-OP dataset covering 7 dimensions related to the evaluation of opinion summaries: fluency, coherence, relevance, faithfulness, aspect coverage, sentiment consistency, and specificity. We investigate Op-I-Prompt a dimension-independent prompt, and Op-Prompts, a dimension-dependent set of prompts for opinion summary evaluation. Experiments indicate that Op-I-Prompt emerges as a good alternative for evaluating opinion summaries achieving an average Spearman correlation of 0.70 with humans, outperforming all previous approaches. To the best of our knowledge, we are the first to investigate LLMs as evaluators on both closed-source and open-source models in the opinion summarization domain.
Disentangling Societal Inequality from Model Biases: Gender Inequality in Divorce Court Proceedings
Jul 09, 2023



Divorce is the legal dissolution of a marriage by a court. Since this is usually an unpleasant outcome of a marital union, each party may have reasons to call the decision to quit which is generally documented in detail in the court proceedings. Via a substantial corpus of 17,306 court proceedings, this paper investigates gender inequality through the lens of divorce court proceedings. While emerging data sources (e.g., public court records) on sensitive societal issues hold promise in aiding social science research, biases present in cutting-edge natural language processing (NLP) methods may interfere with or affect such studies. We thus require a thorough analysis of potential gaps and limitations present in extant NLP resources. In this paper, on the methodological side, we demonstrate that existing NLP resources required several non-trivial modifications to quantify societal inequalities. On the substantive side, we find that while a large number of court cases perhaps suggest changing norms in India where women are increasingly challenging patriarchy, AI-powered analyses of these court proceedings indicate striking gender inequality with women often subjected to domestic violence.
TruthBot: An Automated Conversational Tool for Intent Learning, Curated Information Presenting, and Fake News Alerting
Jan 31, 2021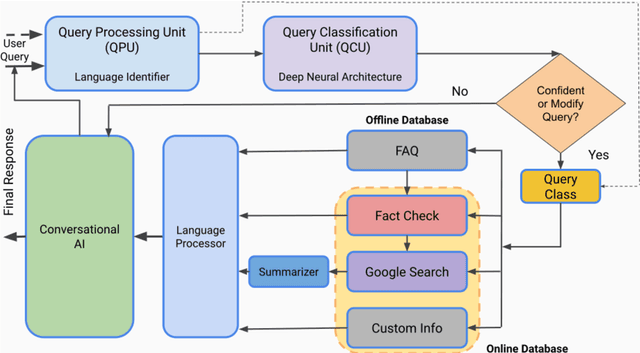
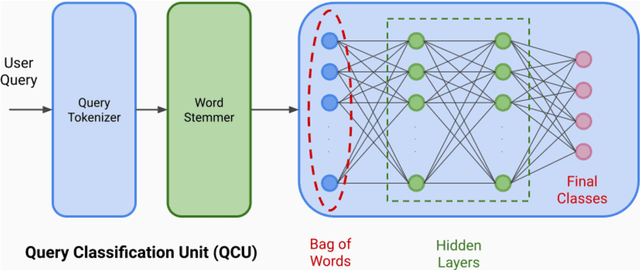
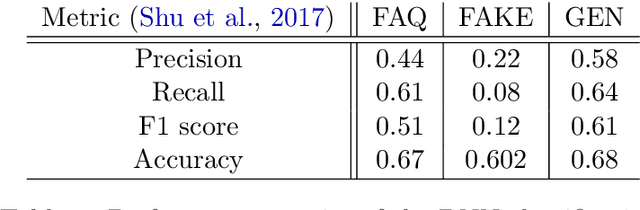

We present TruthBot, an all-in-one multilingual conversational chatbot designed for seeking truth (trustworthy and verified information) on specific topics. It helps users to obtain information specific to certain topics, fact-check information, and get recent news. The chatbot learns the intent of a query by training a deep neural network from the data of the previous intents and responds appropriately when it classifies the intent in one of the classes above. Each class is implemented as a separate module that uses either its own curated knowledge-base or searches the web to obtain the correct information. The topic of the chatbot is currently set to COVID-19. However, the bot can be easily customized to any topic-specific responses. Our experimental results show that each module performs significantly better than its closest competitor, which is verified both quantitatively and through several user-based surveys in multiple languages. TruthBot has been deployed in June 2020 and is currently running.
SPARCAS: A Decentralized, Truthful Multi-Agent Collision-free Path Finding Mechanism
Sep 18, 2019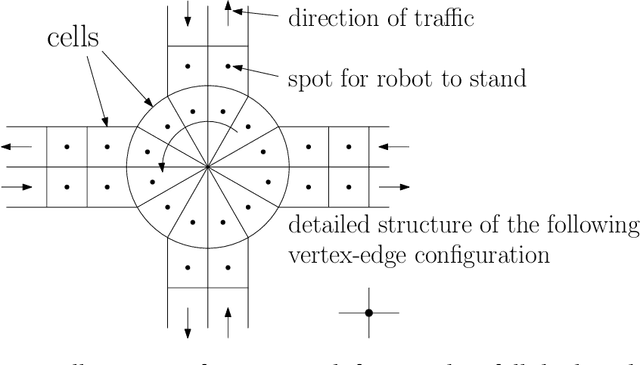
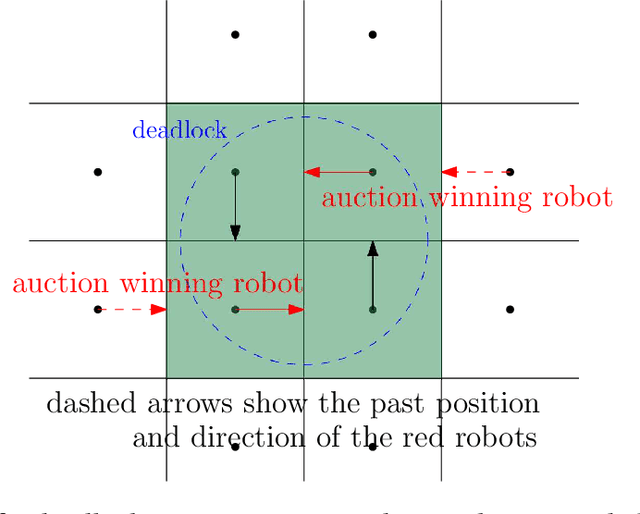
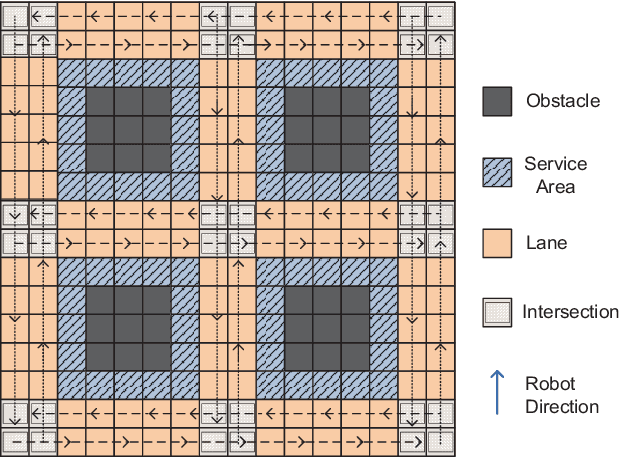
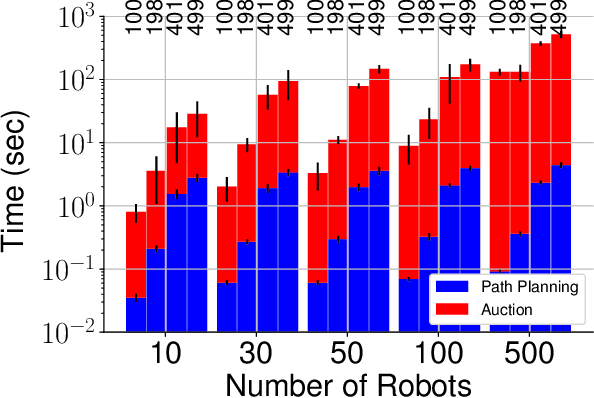
We propose a decentralized collision-avoidance mechanism for a group of independently controlled robots moving on a shared workspace. Existing algorithms achieve multi-robot collision avoidance either (a) in a centralized setting, or (b) in a decentralized setting with collaborative robots. We focus on the setting with competitive robots in a decentralized environment, where robots may strategically reveal their information to get prioritized. We propose the mechanism SPARCAS in this setting that, using principles of mechanism design, ensures truthful revelation of the robots' private information and provides locally efficient movement of the robots. It is free from collisions and deadlocks, and handles a dynamic arrival of robots. In practice, this mechanism scales well for a large number of robots where the optimal collision-avoiding path-finding algorithm (M*) does not scale. Yet, SPARCAS does not compromise the path optimality too much. Our mechanism prioritizes the robots in the order of their `true' higher needs, but for a higher payment. It uses monetary transfers which is small enough compared to the value received by the robots.
A Parameterized Perspective on Protecting Elections
May 28, 2019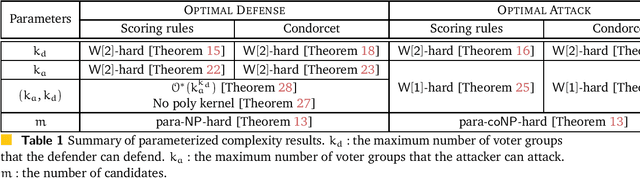
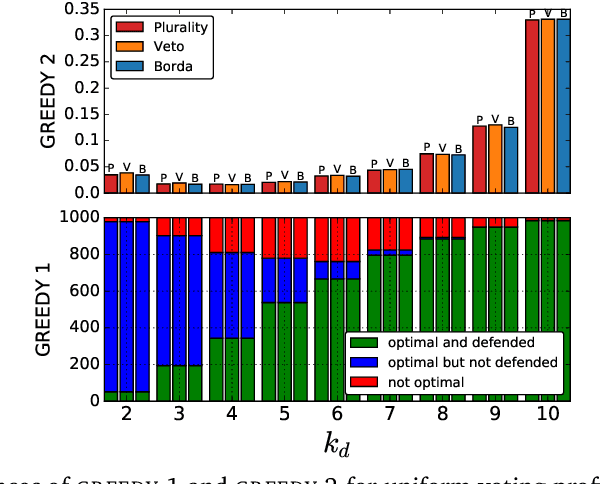
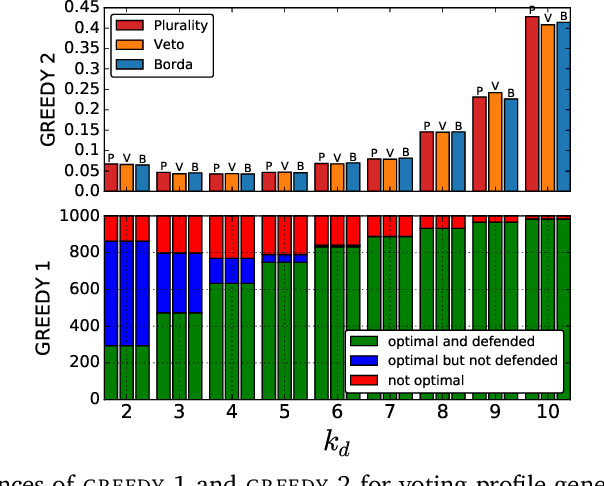
We study the parameterized complexity of the optimal defense and optimal attack problems in voting. In both the problems, the input is a set of voter groups (every voter group is a set of votes) and two integers $k_a$ and $k_d$ corresponding to respectively the number of voter groups the attacker can attack and the number of voter groups the defender can defend. A voter group gets removed from the election if it is attacked but not defended. In the optimal defense problem, we want to know if it is possible for the defender to commit to a strategy of defending at most $k_d$ voter groups such that, no matter which $k_a$ voter groups the attacker attacks, the outcome of the election does not change. In the optimal attack problem, we want to know if it is possible for the attacker to commit to a strategy of attacking $k_a$ voter groups such that, no matter which $k_d$ voter groups the defender defends, the outcome of the election is always different from the original (without any attack) one.
Testing Preferential Domains Using Sampling
Feb 24, 2019
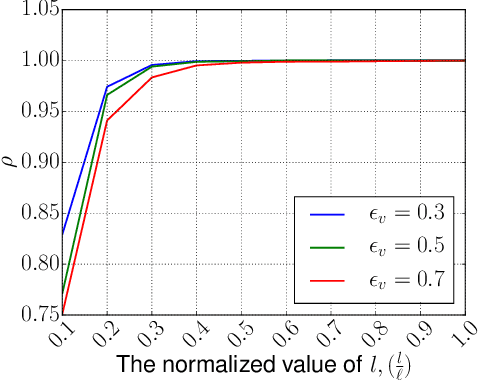
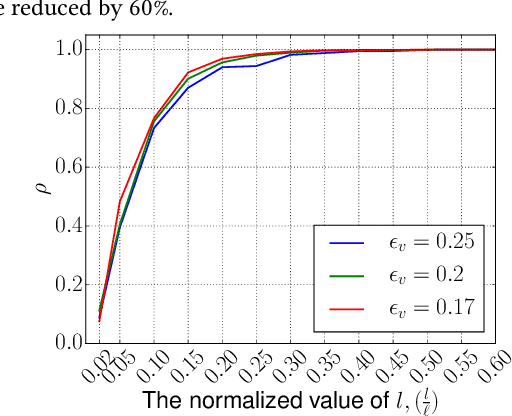
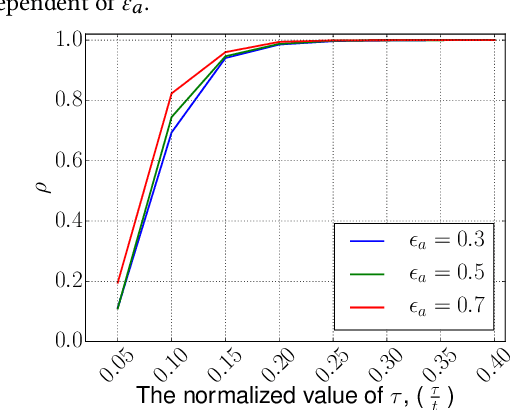
A preferential domain is a collection of sets of preferences which are linear orders over a set of alternatives. These domains have been studied extensively in social choice theory due to both its practical importance and theoretical elegance. Examples of some extensively studied preferential domains include single peaked, single crossing, Euclidean, etc. In this paper, we study the sample complexity of testing whether a given preference profile is close to some specific domain. We consider two notions of closeness: (a) closeness via preferences, and (b) closeness via alternatives. We further explore the effect of assuming that the {\em outlier} preferences/alternatives to be random (instead of arbitrary) on the sample complexity of the testing problem. In most cases, we show that the above testing problem can be solved with high probability for all commonly used domains by observing only a small number of samples (independent of the number of preferences, $n$, and often the number of alternatives, $m$). In the remaining few cases, we prove either impossibility results or $\Omega(n)$ lower bound on the sample complexity. We complement our theoretical findings with extensive simulations to figure out the actual constant factors of our asymptotic sample complexity bounds.
Game-Theoretic Modeling of Human Adaptation in Human-Robot Collaboration
Apr 06, 2017

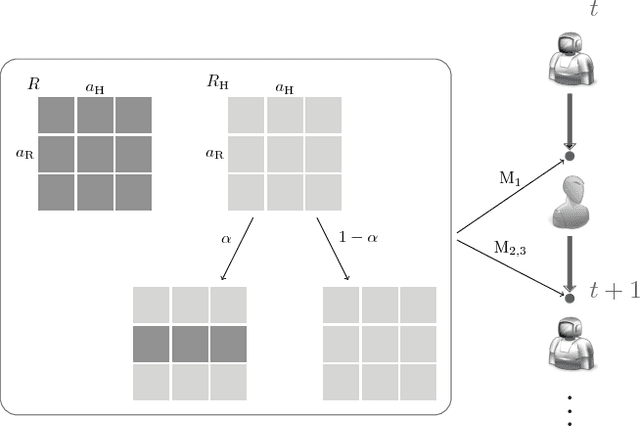
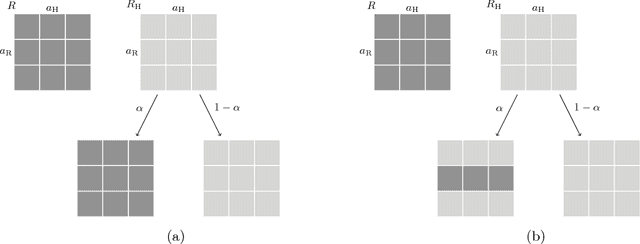
In human-robot teams, humans often start with an inaccurate model of the robot capabilities. As they interact with the robot, they infer the robot's capabilities and partially adapt to the robot, i.e., they might change their actions based on the observed outcomes and the robot's actions, without replicating the robot's policy. We present a game-theoretic model of human partial adaptation to the robot, where the human responds to the robot's actions by maximizing a reward function that changes stochastically over time, capturing the evolution of their expectations of the robot's capabilities. The robot can then use this model to decide optimally between taking actions that reveal its capabilities to the human and taking the best action given the information that the human currently has. We prove that under certain observability assumptions, the optimal policy can be computed efficiently. We demonstrate through a human subject experiment that the proposed model significantly improves human-robot team performance, compared to policies that assume complete adaptation of the human to the robot.